全网最全的神经网络数学原理(代码和公式)直观解释 ,全网最全,没有之一
📖阅读时长:120分钟🕙全网首发时间:2025-01-11本文字符数超3W,共计37张图,每张图均配有python代码和公式解释欢迎关注知乎和公众号的专栏内容知乎LLM专栏知乎【公众号【】【人工神经网络是最强大的机器学习模型,同时也是最复杂的机器学习模型。它们对于传统机器学习算法无法完成的复杂任务特别有用。神经网络的主要优势在于它们能够学习数据中复杂的模式和关系,即使数据是高度维的或非结构化的
神经网络背后的数学原理直观解释
📖阅读时长:120分钟
🕙全网首发时间:2025-01-11
本文字符数超3W,共计37张图,每张图均配有python代码和公式解释
欢迎关注知乎和公众号的专栏内容
LLM架构专栏
知乎LLM专栏
知乎【柏企】
公众号【柏企科技说】【柏企阅文】
人工神经网络是最强大的机器学习模型,同时也是最复杂的机器学习模型。它们对于传统机器学习算法无法完成的复杂任务特别有用。神经网络的主要优势在于它们能够学习数据中复杂的模式和关系,即使数据是高度维的或非结构化的。
许多文章都讨论了神经网络背后的数学。详细讨论了不同的激活函数、前向和反向传播算法、梯度下降和优化方法等主题。在本文中,我们采用不同的方法,逐层呈现对神经网络的可视化理解。我们将首先关注分类和回归问题中单层神经网络的可视化解释,以及它们与其他机器学习模型的相似之处。然后我们将讨论隐藏层和非线性激活函数的重要性。所有可视化效果都是使用Python创建的。
用于分类的神经网络
我们从分类问题开始。最简单的分类问题是二元分类,其中目标只有两个类别或标签。如果目标具有两个以上的标签,则存在多类分类问题。
单层网络:感知器
单层神经网络是人工神经网络的最简单形式。这里我们只有一个接收输入数据的输入层和一个产生网络输出的输出层。输入层在此网络中不被视为真正的层,因为它仅传递输入数据。这就是为什么这种架构被称为单层网络。Perceptron是有史以来创建的第一个神经网络,是单层神经网络的最简单示例。
感知器由Frank Rosenblatt于1957年创建。他认为感知器可以模拟大脑原理,具有学习和决策的能力。最初的感知器旨在解决二元分类问题。
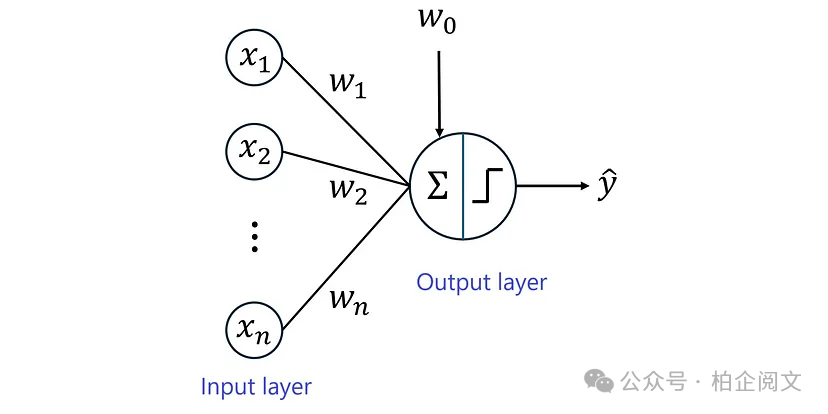
图1
图1显示了感知器的架构。输入数据具有n个特征,用到表示。目标y只有两个标签(y = 0和y = 1)。
输入层接收特征并将其传递到输出层。输出层中的neuron计算输入特征的加权和。每个输入特征都与权重相关联。神经元将每个输入乘以相应的权重,并对结果求和。偏差项也被添加到此总和中。如果我们用z表示和,则得到:
激活函数是一个阶跃函数,定义为:
该激活函数如图2所示。
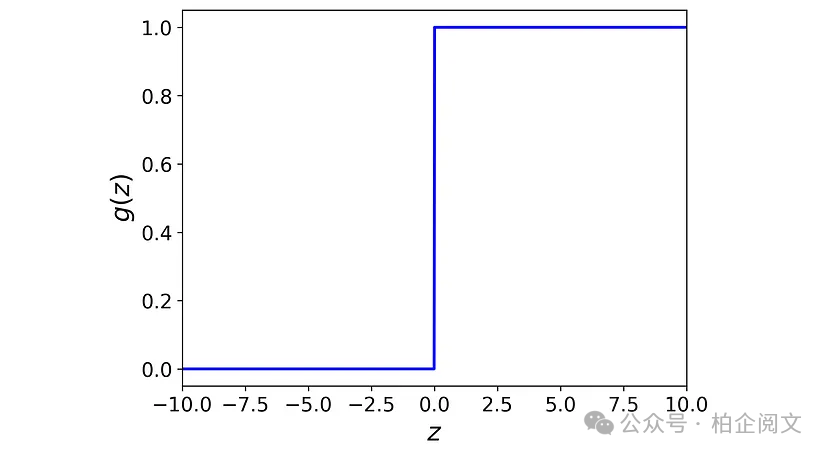
图2
由表示的感知器的输出计算如下:
为了直观地了解感知器的工作原理,我们使用了一个简单的训练数据集,其中只有两个特征和。此数据集在清单1中创建。它是随机定义的,目标y只有两个标签(y = 0和y = 1)。我们还在此列表的开头导入了本文所需的所有Python库。数据集如图3所示。
import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression import random import tensorflow as tf from tensorflow.keras.models import Sequential, Model from tensorflow.keras.layers import Dense, Input from tensorflow.keras.utils import to_categorical from tensorflow.keras import backend np.random.seed(3) n = 30 X1 = np.random.randn(n,2) y1 = np.random.choice((0, 1),size=n) X1[y1>0,0] -= 4 X1[y1>0,1] += 4 scaler = StandardScaler() X1 = scaler.fit_transform(X1) plt.figure(figsize=(5, 5)) marker_colors = ['red', 'blue'] target_labels = np.unique(y1) n = len(target_labels) for i, label in enumerate(target_labels): plt.scatter(X1[y1==label, 0], X1[y1==label,1], label="y="+str(label), edgecolor="white", color=marker_colors[i]) plt.xlabel('$x_1$', fontsize=16) plt.ylabel('$x_2$', fontsize=16) plt.legend(loc='best', fontsize=11) ax = plt.gca() ax.set_aspect('equal') plt.xlim([-2.3, 1.8]) plt.ylim([-1.9, 2.2]) plt.show()
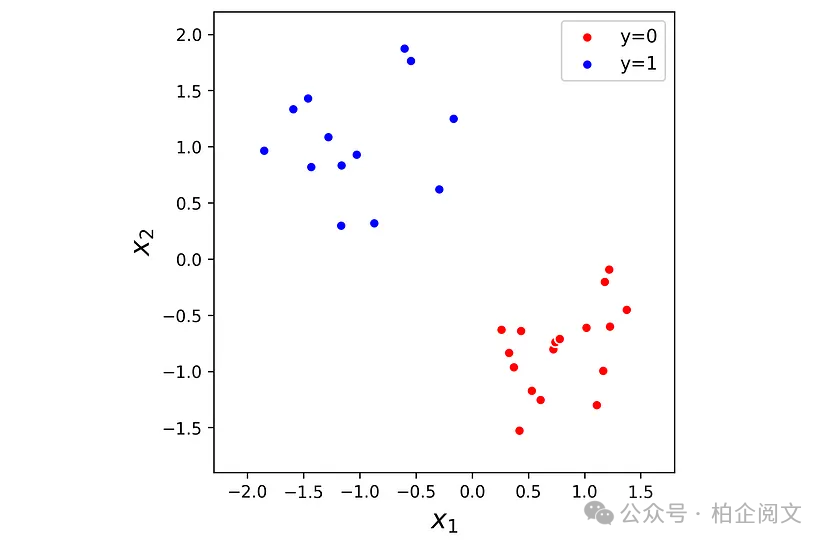
图3
本文不详细介绍神经网络训练过程。相反,我们专注于已经训练过的神经网络的行为。在清单2中,我们使用前面的数据集定义和训练一个感知器。
class Perceptron(object): def __init__(self, eta=0.01, epochs=50): self.eta = eta self.epochs = epochs def fit(self, X, y): self.w = np.zeros(1 + X.shape[1]) for epoch in range(self.epochs): for xi, target in zip(X, y): error = target - self.predict(xi) self.w[1:] += self.eta * error * xi self.w[0] += self.eta * error return self def net_input(self, X): return np.dot(X, self.w[1:]) + self.w[0] def predict(self, X): return np.where(self.net_input(X) >= 0.0, 1, 0) perc = Perceptron(epochs=150, eta=0.05) perc.fit(X1, y1)
现在我们想看看这个模型如何对我们的训练数据集进行分类。因此,我们定义了一个函数来绘制经过训练的神经网络的决策边界。清单3中定义的这个函数在2D空间上创建一个网格网格,然后使用一个经过训练的模型来预测该网格上所有点的目标。具有不同标签的点的颜色不同。因此,可以使用此函数可视化模型的决策边界。
def plot_boundary(X, y, clf, lims, alpha=1): gx1, gx2 = np.meshgrid(np.arange(lims[0], lims[1], (lims[1]-lims[0])/500.0), np.arange(lims[2], lims[3], (lims[3]-lims[2])/500.0)) backgd_colors = ['lightsalmon', 'aqua', 'lightgreen', 'yellow'] marker_colors = ['red', 'blue', 'green', 'orange'] gx1l = gx1.flatten() gx2l = gx2.flatten() gx = np.vstack((gx1l,gx2l)).T gyhat = clf.predict(gx) if len(gyhat.shape)==1: gyhat = gyhat.reshape(len(gyhat), 1) if gyhat.shape[1] > 1: gyhat = gyhat.argmax(axis=1) gyhat = gyhat.reshape(gx1.shape) target_labels = np.unique(y) n = len(target_labels) plt.pcolormesh(gx1, gx2, gyhat, cmap=ListedColormap(backgd_colors[:n])) for i, label in enumerate(target_labels): plt.scatter(X[y==label, 0], X[y==label,1], label="y="+str(label), alpha=alpha, edgecolor="white", color=marker_colors[i])
现在,我们使用此函数为训练数据集绘制感知器的决策边界。结果如图4所示。
plt.figure(figsize=(5, 5)) plt.quiver([0], [0], perc.w[1], perc.w[2], color=['black'], width=0.008, angles='xy', scale_units='xy', scale=0.4, zorder=5) plot_boundary(X1, y1, perc, lims=[-2.3, 1.8, -1.9, 2.2]) ax = plt.gca() ax.set_aspect('equal') plt.xlabel('$x_1$', fontsize=16) plt.ylabel('$x_2$', fontsize=16) plt.legend(loc='best', fontsize=11) plt.xlim([-2.3, 1.8]) plt.ylim([-1.9, 2.2]) plt.show()
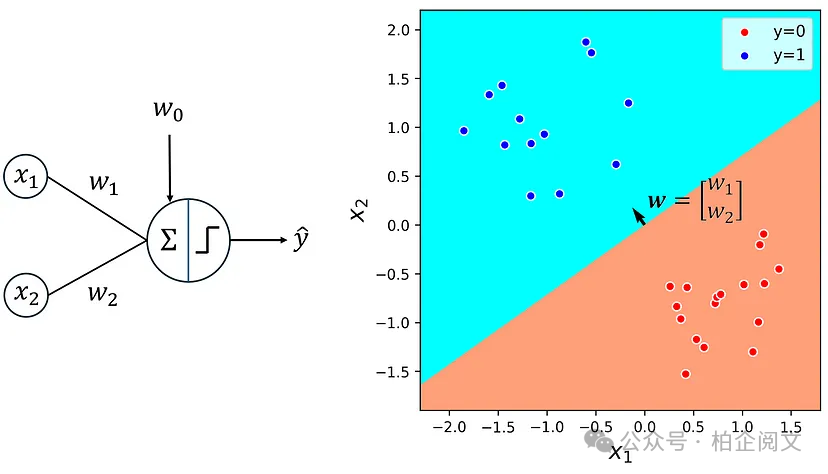
图4
该图清楚地表明,决策边界是一条直线。我们使用感知器的权重定义向量w:
图4中也绘制了这个向量,它显示它垂直于感知器的决策边界(向量很小,因此我们在图中缩放了它)。我们现在可以解释这些结果背后的数学原因。
对于具有两个特征的数据集,我们有:
根据公式1,我们知道的所有数据点的预测标签为1。另一方面,任何的数据点的预测标签都将为0。因此,决策边界是的数据点的位置,它由以下等式定义:
这是一条直线的方程,这条线的法向量(垂直于这条线的向量)是:
这解释了为什么决策边界垂直于向量w。
单层网络:Sigmoid神经元
感知器可以预测数据点的标签,但不能提供预测概率。事实上,这个网络无法告诉你它对预测的信心有多大。我们需要一个名为sigmoid的不同激活函数来获得预测概率。sigmoid激活函数定义如下:
图5给出了该函数的曲线图。
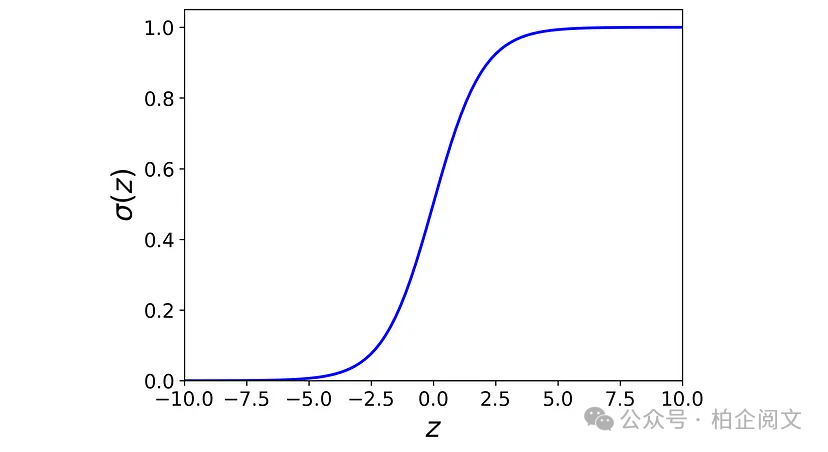
图5
我们知道事件的概率是一个介于0和1之间的数字。由于该图显示sigmoid函数的范围是(0, 1),因此它可以用来表示结果的概率。现在,我们将感知器的激活函数替换为sigmoid函数,以获得图6所示的网络。
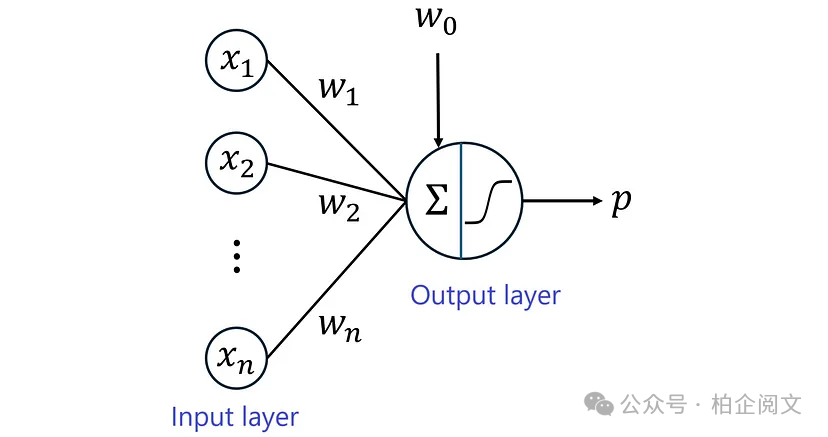
图6
在这个网络中,我们用p表示网络的输出,因此我们可以写成:
其中p是预测标签为1 ( = 1) 的概率。为了获得预测的目标,我们必须将此概率与默认为0.5的阈值进行比较:
为了可视化这个网络,我们使用清单1中定义的数据集来训练它。清单5使用keras库创建此网络。
np.random.seed(0) random.seed(0) tf.random.set_seed(0) model1 = Sequential() model1.add(Dense(1, activation='sigmoid', input_shape=(2,))) model1.compile(loss = 'binary_crossentropy', optimizer='adam', metrics=['accuracy']) model1.summary()
此神经网络的成本函数称为交叉熵。接下来,我们使用清单1中定义的数据集来训练这个模型。
history1 = model1.fit(X1, y1, epochs=1500, verbose=0, batch_size=X1.shape[0]) plt.plot(history1.history['accuracy']) plt.title('Accuracy vs Epochs') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.show()
图7显示了该模型的准确率与纪元的关系图。
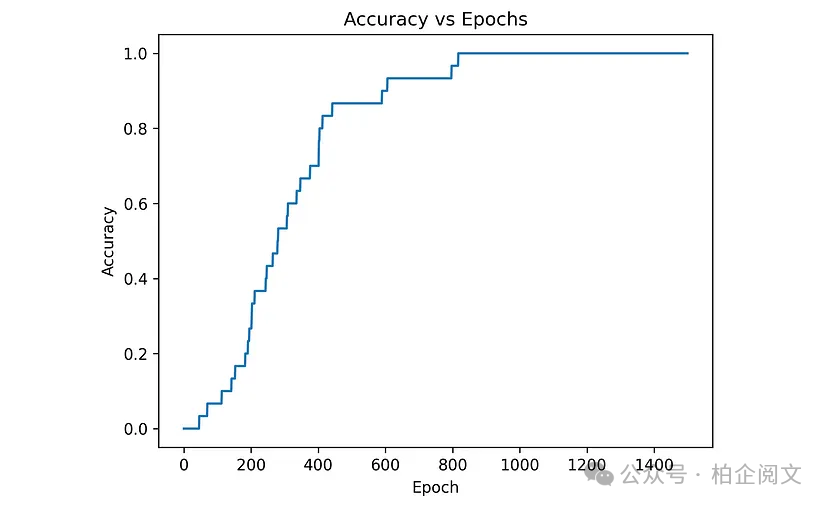
图7
训练模型后,我们可以检索输出层的权重(和)。
output_layer_weights = model1.layers[0].get_weights()[0] model1_w1, model1_w2 = output_layer_weights[0, 0], output_layer_weights[1, 0]
最后,我们绘制了这个网络的决策边界。结果如图8所示。
plt.figure(figsize=(5, 5)) output_layer_weights = model1.layers[0].get_weights()[0] plt.quiver([0], [0], model1_w1, model1_w2, color=['black'], width=0.008, angles='xy', scale_units='xy', scale=1, zorder=5) plot_boundary(X1, y1, model1, lims=[-2.3, 1.8, -1.9, 2.2]) ax = plt.gca() ax.set_aspect('equal') plt.xlabel('$x_1$', fontsize=16) plt.ylabel('$x_2$', fontsize=16) plt.legend(loc='best', fontsize=11) plt.xlim([-2.3, 1.8]) plt.ylim([-1.9, 2.2]) plt.show()
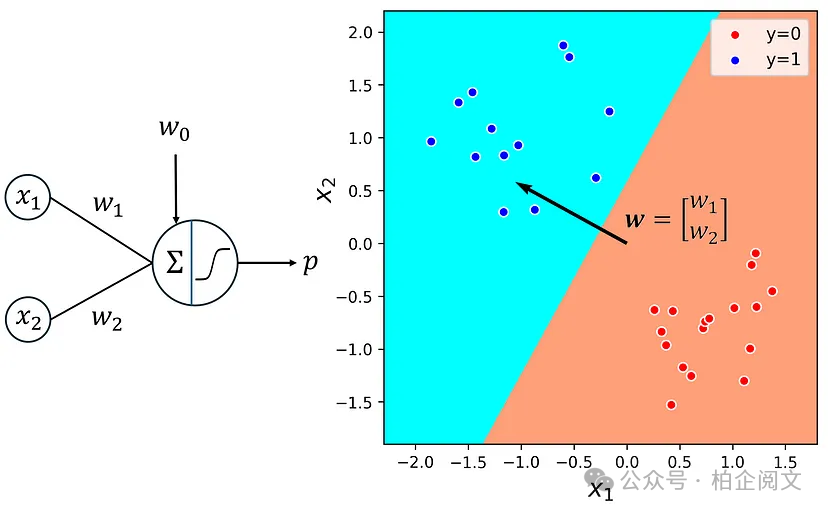
图8
我们再次看到决策边界是一条直线。我们使用输出层的权重定义向量w:
向量w垂直于决策边界,就像我们在感知器中看到的那样。让我们解释一下这些结果背后的数学原因。根据公式2,为1的所有数据点的预测标签。另一方面,任何的数据点的预测标签都将为0。因此,决策边界是的所有数据点的位置:
因此,决策边界是由以下公式定义的所有数据点的位置:
如前所述,这是一条直线的方程,这条线的法向量(垂直于这条线的向量)是:
添加更多功能
到目前为止,我们只考虑了一个只有两个特征的玩具数据集。让我们看看当我们有三个特征时会发生什么。清单9定义了另一个具有3个特征的数据集。该数据集如图9所示。
fig = plt.figure(figsize=(7, 7)) ax = fig.add_subplot(111, projection='3d') ax.scatter(X2[y2==0, 0], X2[y2==0,1], X2[y2==0,2], label="y=0", alpha=0.8, color="red") ax.scatter(X2[y2==1, 0], X2[y2==1,1], X2[y2==1,2], label="y=1", alpha=0.8, color="blue") ax.legend(loc="upper left", fontsize=12) ax.set_xlabel("$x_1$", fontsize=18) ax.set_ylabel("$x_2$", fontsize=18) ax.set_zlabel("$x_3$", fontsize=15, labelpad=-0.5) ax.view_init(5, -50) plt.show()
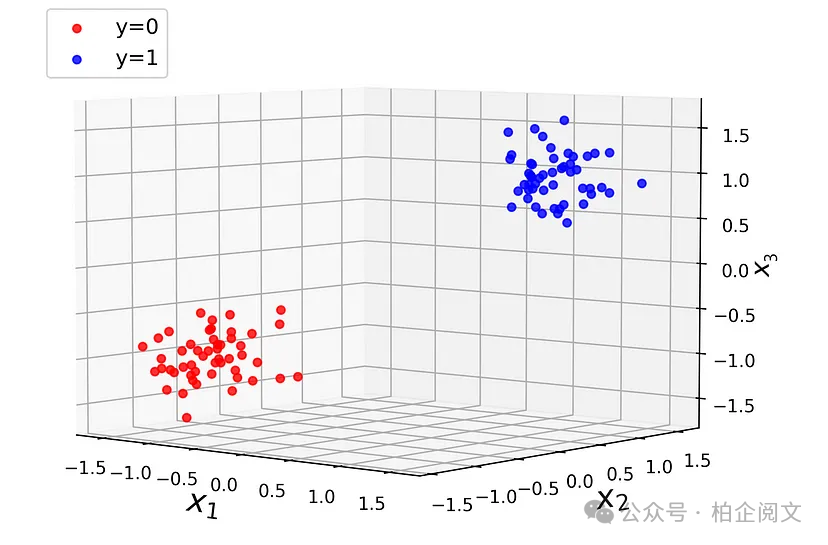
图9
现在,我们创建一个具有Sigmoid神经元的新网络,并使用此数据集对其进行训练。
backend.clear_session() np.random.seed(0) random.seed(0) tf.random.set_seed(0) model2 = Sequential() model2.add(Dense(1, activation='sigmoid', input_shape=(3,))) model2.compile(loss = 'binary_crossentropy', optimizer='adam', metrics=['accuracy']) history2 = model2.fit(X2, y2, epochs=1500, verbose=0, batch_size=X2.shape[0])
接下来,我们在经过训练的模型中检索输出层的权重,并在图10中绘制数据点和模型决策边界。
model2_w0 = output_layer_biases[0] model2_w1, model2_w2, model2_w3 = output_layer_weights[0, 0], \ output_layer_weights[1, 0], output_layer_weights[2, 0] fig = plt.figure(figsize=(7, 7)) ax = fig.add_subplot(111, projection='3d') lims=[-2, 2, -2, 2] ga1, ga2 = np.meshgrid(np.arange(lims[0], lims[1], (lims[1]-lims[0])/500.0), np.arange(lims[2], lims[3], (lims[3]-lims[2])/500.0)) ga1l = ga1.flatten() ga2l = ga2.flatten() ga3 = -(model2_w0 + model2_w1*ga1l + model2_w2*ga2l) / model2_w3 ga3 = ga3.reshape(500, 500) ax.plot_surface(ga1, ga2, ga3, alpha=0.5) ax.quiver([0], [0], [0], model2_w1, model2_w2, model2_w3, color=['black'], length=0.5, zorder=5) ax.scatter(X2[y2==0, 0], X2[y2==0,1], X2[y2==0,2], label="y=0", alpha=0.8, color="red") ax.scatter(X2[y2==1, 0], X2[y2==1,1], X2[y2==1,2], label="y=1", alpha=0.8, color="blue") ax.legend(loc="upper left", fontsize=12) ax.set_xlabel("$x_1$", fontsize=16) ax.set_ylabel("$x_2$", fontsize=16) ax.set_zlabel("$x_3$", fontsize=15, labelpad=-0.5) ax.view_init(5, -50) plt.show()
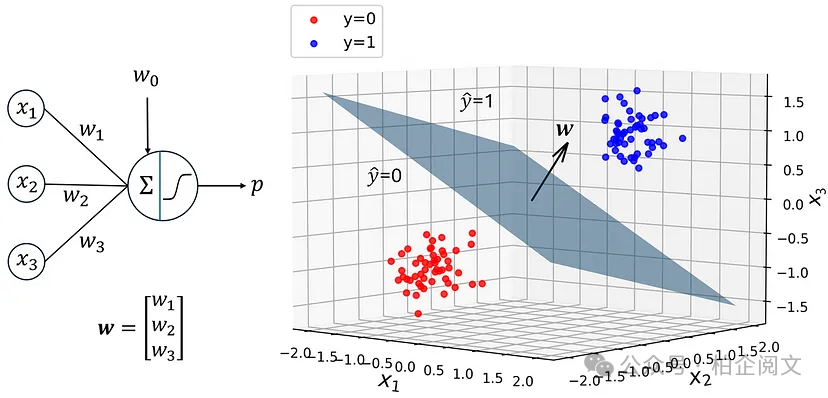
图10
如图所示,决策边界是垂直于向量
它是使用输出层的权重形成的。此处的决策边界计算如下:
所以,决策边界是这个方程的解
这是一个平面的方程,向量(在方程中定义)是该平面的法向量。
线性分类器
如果输入数据中有3个以上的特征,会发生什么情况?我们可以很容易地扩展相同的想法,找到一个感知器或一个Sigmoid神经元具有个特征的网络的决策边界。在这两种情况下,决策边界都是以下方程的解:
该方程描述了维空间中垂直于向量
的超平面。在2D空间中,超平面变为1维线,而在3D空间中,它变为2D平面。线或平面没有曲率,尽管我们无法在更高维度上可视化超平面,但概念保持不变。在维空间中,超平面是维子空间,它是平坦的,没有曲率。
在机器学习中,线性分类器是一种分类模型,它根据输入特征的线性组合做出决策。因此,线性分类器的决策边界是超平面。感知器和Sigmoid神经元是线性分类器的两个示例。
值得一提的是,具有交叉熵成本函数的Sigmoid神经元相当于逻辑回归模型。下一个清单在清单1中定义的2D数据集上训练一个逻辑回归模型(来自scikit - learn库)。该模型的决策边界如图11所示。虽然它是一条直线,但它与图8中用Sigmoid神经元获得的线并不完全相同。
lr_model = LogisticRegression().fit(X1, y1) plt.figure(figsize=(5, 5)) plot_boundary(X1, y1, lr_model, lims=[-2.3, 1.8, -1.9, 2.2]) ax = plt.gca() ax.set_aspect('equal') plt.xlabel('$x_1$', fontsize=16) plt.ylabel('$x_2$', fontsize=16) plt.legend(loc='best', fontsize=11) plt.xlim([-2.3, 1.8]) plt.ylim([-1.9, 2.2]) plt.show()
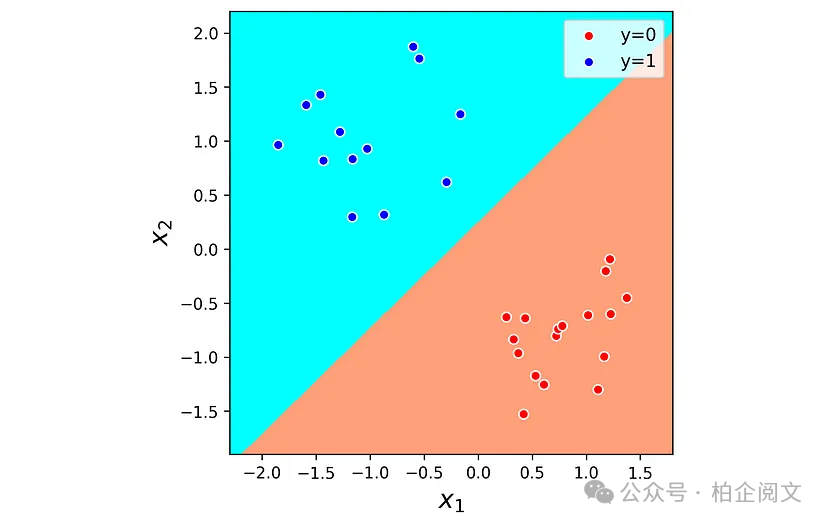
图11
尽管逻辑回归和Sigmoid神经元(具有交叉熵成本函数)是等效模型,但在训练过程中使用不同的方法来查找它们的参数。在神经网络中,使用随机初始化的梯度下降算法进行训练,但是,逻辑回归模型使用称为lbfgs(有限内存Broyden - Fletcher - Goldfarb - Shanno)的确定性求解器来实现此目的。因此,这两个模型中参数的最终值可能会有所不同,从而改变决策边界线的位置。
多类分类和softmax层
到目前为止,我们的注意力一直放在二元分类问题上。如果数据集的目标有两个以上的标签,那么我们就有一个多类分类问题,这样的问题需要一个softmax层。假设一个数据集有个特征,其目标有个标签。该数据集可用于训练具有softmax层的单层神经网络,如图12所示。
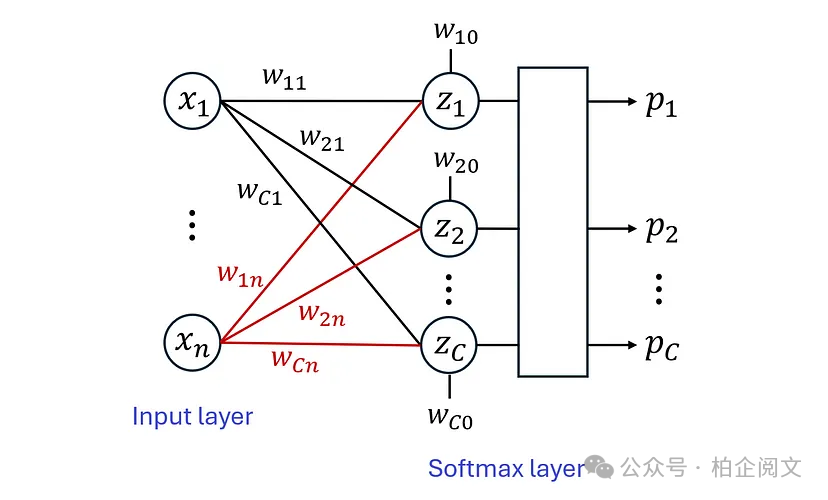
图12
softmax函数是Sigmoid函数对多类分类问题的泛化,其中目标具有2个以上的标签。输出层中的神经元给出了输入特征的线性组合:
softmax层的每个输出计算如下:
在这个方程中,表示预测目标等于第个标签的概率。最后,预测的标签是概率最高的标签:
现在我们创建另一个玩具数据集来可视化softmax层。在这个数据集中,我们有两个特征,目标有3个标签。如图13所示。
np.random.seed(0) xt1 = np.random.randn(50, 2) * 0.4 + np.array([2, 1]) xt2 = np.random.randn(50, 2) * 0.7 + np.array([6, 4]) xt3 = np.random.randn(50, 2) * 0.5 + np.array([2, 6]) y3 = np.array(50*[1]+50*[2]+50*[3]) X3 = np.vstack((xt1, xt2, xt3)) scaler = StandardScaler() X3 = scaler.fit_transform(X3) plt.figure(figsize=(6, 6)) plt.scatter(X3[y3==1, 0], X3[y3==1,1], label="y=1", alpha=0.7, color="red") plt.scatter(X3[y3==2, 0], X3[y3==2,1], label="y=2", alpha=0.7, color="blue") plt.scatter(X3[y3==3, 0], X3[y3==3,1], label="y=3", alpha=0.7, color="green") plt.legend(loc="best", fontsize=11) plt.xlabel("$x_1$", fontsize=16) plt.ylabel("$x_2$", fontsize=16) ax = plt.gca() ax.set_aspect('equal') plt.show()
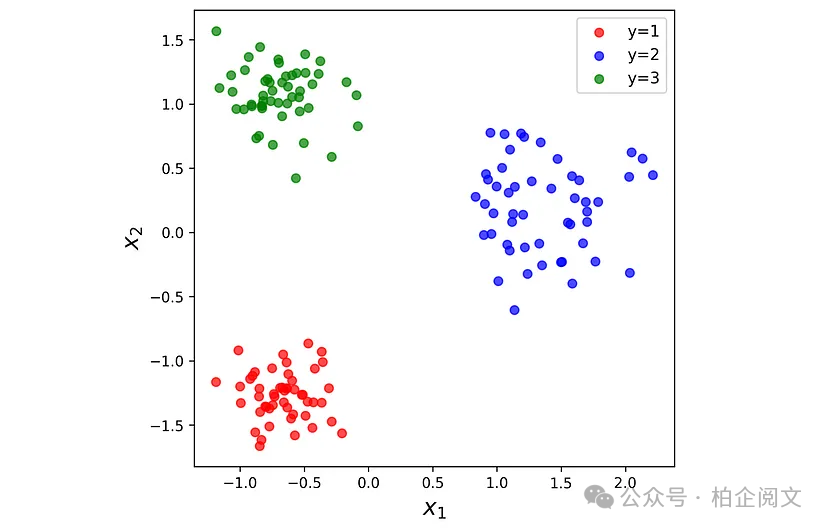
图13
接下来,我们创建一个单层神经网络并使用此数据集对其进行训练。该网络有一个softmax层。
backend.clear_session() np.random.seed(0) random.seed(0) tf.random.set_seed(0) y3_categorical = to_categorical(y3-1, num_classes=3) model3 = Sequential() model3.add(Dense(3, activation='softmax', input_shape=(2,))) model3.compile(loss = 'categorical_crossentropy', optimizer='adam', metrics=['accuracy']) history3 = model3.fit(X3, y3_categorical, epochs=2200, verbose=0, batch_size=X3.shape[0])
接下来,我们检索此网络的权重和偏差:
output_layer_weights = model3.layers[-1].get_weights()[0] output_layer_biases = model3.layers[-1].get_weights()[1] model3_w10, model3_w20, model3_w30 = output_layer_biases[0], \ output_layer_biases[1], output_layer_biases[2] model3_w1 = output_layer_weights[:, 0] model3_w2 = output_layer_weights[:, 1] model3_w3 = output_layer_weights[:, 2]
最后,我们可以使用清单16绘制该模型的决策边界。
plt.figure(figsize=(5, 5)) plt.quiver([1.7], [0.7], model3_w3[0]-model3_w2[0], model3_w3[1]-model3_w2[1], color=['black'], width=0.008, angles='xy', scale_units='xy', scale=1, zorder=5) plt.quiver([-0.5], [-2.2], model3_w2[0]-model3_w1[0], model3_w2[1]-model3_w1[1], color=['black'], width=0.008, angles='xy', scale_units='xy', scale=1, zorder=5) plt.quiver([-1.8], [-1.7], model3_w3[0]-model3_w1[0], model3_w3[1]-model3_w1[1], color=['black'], width=0.008, angles='xy', scale_units='xy', scale=1, zorder=5) plt.text(0.25, 1.85, "$\mathregular{w_3-w_2}$", color="black", fontsize=12, weight="bold", style="italic") plt.text(1.2, -1.1, "$\mathregular{w_2-w_1}$", color="black", fontsize=12, weight="bold", style="italic") plt.text(-1.5, -0.5, "$\mathregular{w_3-w_1}$", color="black", fontsize=12, weight="bold", style="italic") plot_boundary(X3, y3, model3,lims=[-2.2, 2.4, -2.5, 2.1], alpha= 0.7) ax = plt.gca() ax.set_aspect('equal') plt.xlabel('$x_1$', fontsize=16) plt.ylabel('$x_2$', fontsize=16) plt.legend(loc='best', fontsize=11) plt.xlim([-2.2, 2.4]) plt.ylim([-2.5, 2.1]) plt.show()
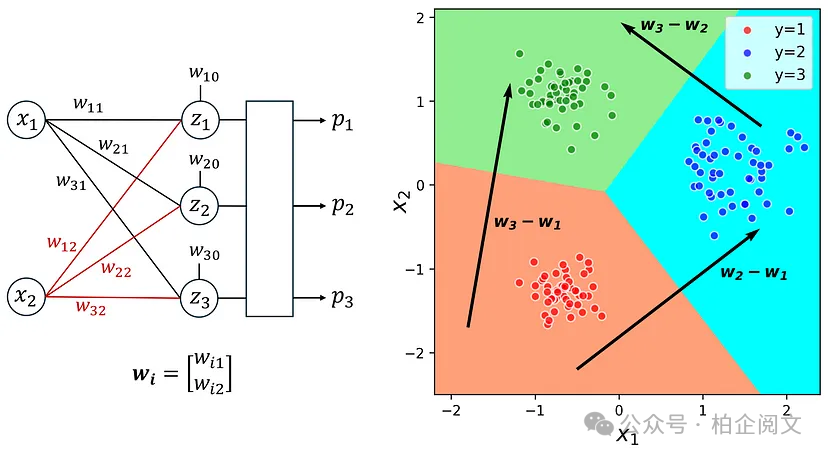
图14
如图14所示,softmax创建了3个决策边界,每个边界都是一条直线。例如,标签1和2之间的决策边界是标签1和2的预测概率相等的点的位置。因此我们可以写:
通过简化最后一个方程,我们得到:
这又是一条直线的方程。如果我们将向量定义为:
这条线的法向量可以写成:
因此,决策边界垂直于。同样,可以证明其他决策边界都是直线,并且标签和之间的线垂直于向量。
更一般地说,如果我们在训练数据集中有个特征,则决策边界将是维空间中的超平面。其中,标签和的超平面垂直于向量,其中
具有softmax激活的单层神经网络是线性分类向更高维度的推广。它继续使用超平面来预测目标的标签,但预测所有标签需要多个超平面。
到目前为止显示的所有数据集都是线性可分的,这意味着我们可以使用超平面来分离具有不同标签的数据点。实际上,数据集很少是线性可分的。在下一节中,我们将研究对非线性可分数据集进行分类的困难。
多层网络
清单17创建了一个不可线性可分的玩具数据集,该数据集如图15所示。
np.random.seed(0) n = 1550 Xt1 = np.random.uniform(low=[0, 0], high=[4, 4], size=(n,2)) drop = (Xt1[:, 0] < 3) & (Xt1[:, 1] < 3) Xt1 = Xt1[~drop] yt1= np.ones(len(Xt1)) Xt2 = np.random.uniform(low=[0, 0], high=[4, 4], size=(n,2)) drop = (Xt2[:, 0] > 2.3) | (Xt2[:, 1] > 2.3) Xt2 = Xt2[~drop] yt2= np.zeros(len(Xt2)) X4 = np.concatenate([Xt1, Xt2]) y4 = np.concatenate([yt1, yt2]) scaler = StandardScaler() X4 = scaler.fit_transform(X4) colors = ['red', 'blue'] plt.figure(figsize=(6, 6)) for i in np.unique(y4): plt.scatter(X4[y4==i, 0], X4[y4==i, 1], label = "y="+str(i), color=colors[int(i)], edgecolor="white", s=50) plt.xlim([-1.9, 1.9]) plt.ylim([-1.9, 1.9]) ax = plt.gca() ax.set_aspect('equal') plt.xlabel('$x_1$', fontsize=16) plt.ylabel('$x_2$', fontsize=16) plt.legend(loc='upper right', fontsize=11, framealpha=1) plt.show()
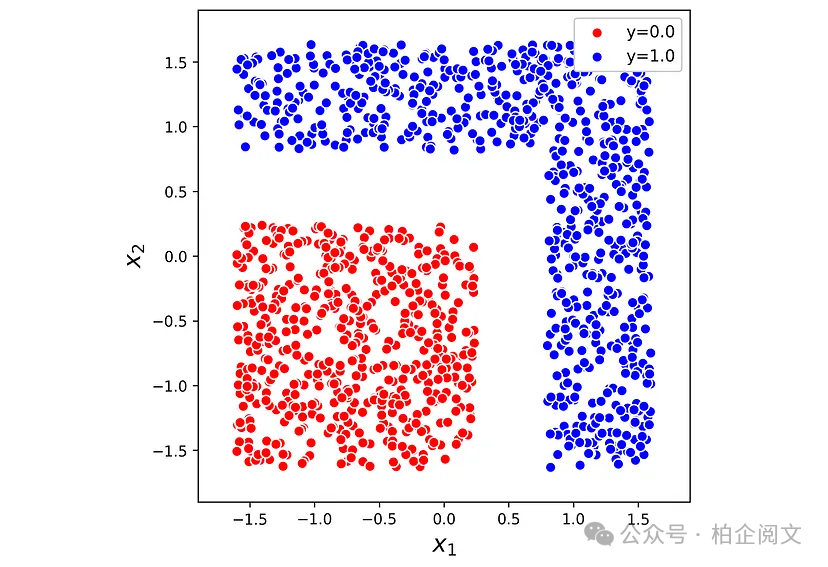
图15
该数据集有两个特征和一个二分类目标。首先,我们尝试用它来训练一个Sigmoid神经元。
backend.clear_session() np.random.seed(2) random.seed(2) tf.random.set_seed(2) model4 = Sequential() model4.add(Dense(1, activation='sigmoid', input_shape=(2,))) model4.compile(loss = 'binary_crossentropy', optimizer='adam', metrics=['accuracy']) history4 = model4.fit(X4, y4, epochs=4000, verbose=0, batch_size=X4.shape[0])
训练网络后,我们可以使用清单19绘制决策边界,图16展示了该图。
plt.figure(figsize=(5,5)) plot_boundary(X4, y4, model5, lims=[-2, 2, -2, 2]) ax = plt.gca() ax.set_aspect('equal') plt.xlabel('$x_1$', fontsize=16) plt.ylabel('$x_2$', fontsize=16) plt.legend(loc='upper right', fontsize=11, framealpha=1) plt.xlim([-1.9, 1.9]) plt.ylim([-1.9, 1.9]) plt.show()
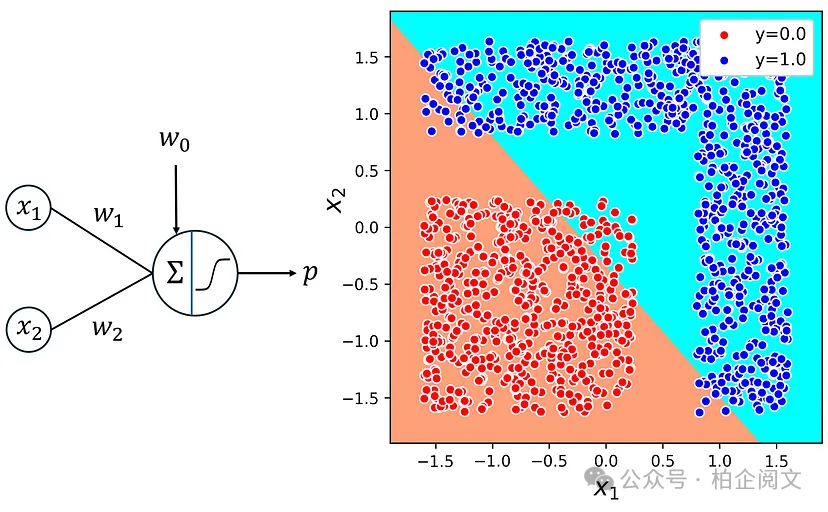
图16
正如预期,决策边界是一条直线。然而,在这个数据集中,由于数据集不是线性可分的,直线无法将不同标签的数据点分开。使用这个模型,我们只能分离出一部分数据点,导致预测准确率较低。
隐藏层
我们了解到单层神经网络相当于一个线性分类器。所以,在进入输出层之前,我们必须先将原始数据集转换为线性可分的数据集。这正是多层网络中隐藏层的作用。输入层从原始数据集接收特征,这些特征随后被传递到一个或多个隐藏层,隐藏层试图将它们转化为线性可分的特征。最后,新的特征被传输到输出层,输出层充当线性分类器。
多层网络的性能取决于隐藏层将输入数据集线性化的能力。如果隐藏层无法将原始数据集转化为线性可分的数据集(或至少接近线性可分),输出层就无法提供准确的分类。
让我们创建一个可以用上述数据集进行训练的多层网络。清单20定义了一个有一个隐藏层的神经网络,如图17所示。
backend.clear_session() np.random.seed(2) random.seed(2) tf.random.set_seed(2) input_layer = Input(shape=(2,)) hidden_layer = Dense(3, activation='relu')(input_layer) output_layer = Dense(1, activation='sigmoid')(hidden_layer) model5 = Model(inputs=input_layer, outputs=output_layer) model5.compile(loss = 'binary_crossentropy', optimizer='adam', metrics=['accuracy'])
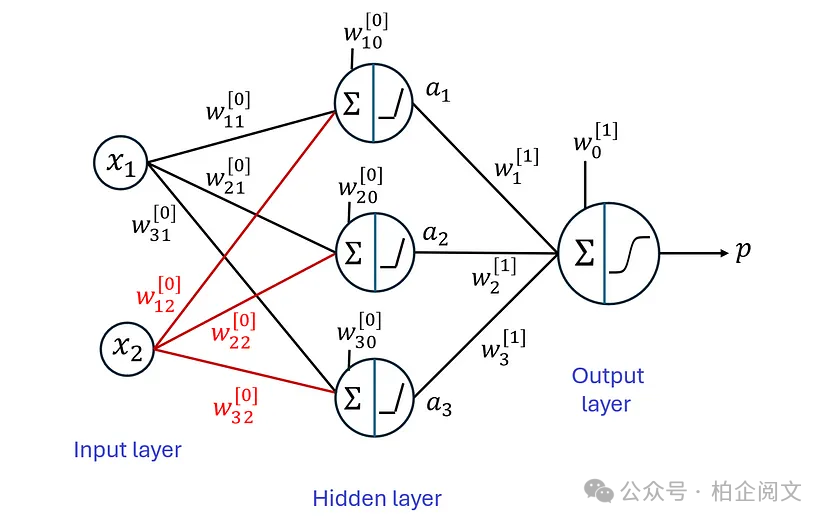
图17
因为数据集只有两个特征,所以输入层有2个神经元。隐藏层有3个神经元,每个神经元都有一个ReLU(修正线性单元)激活函数。这个非线性激活函数定义如下:
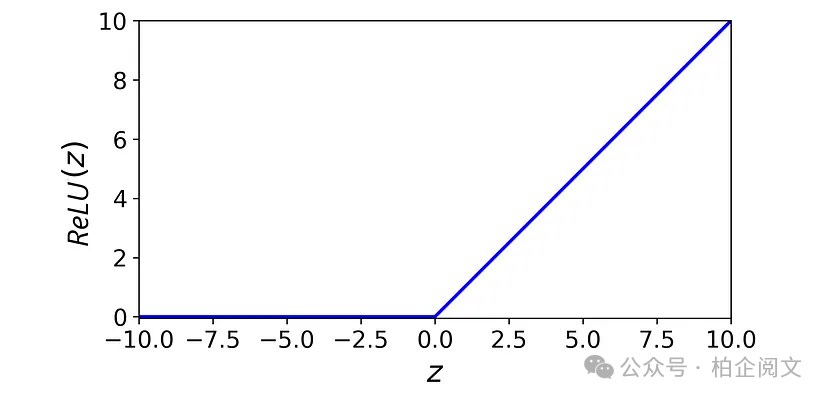
图18
最后,输出层有一个Sigmoid神经元。现在,我们用数据集训练这个模型并绘制决策边界。
history5 = model5.fit(X4, y4, epochs=2200, verbose=0, batch_size=X4.shape[0]) plt.figure(figsize=(5,5)) plot_boundary(X4, y4, model5, lims=[-2, 2, -2, 2]) ax = plt.gca() ax.set_aspect('equal') plt.xlabel('$x_1$', fontsize=16) plt.ylabel('$x_2$', fontsize=16) plt.legend(loc='upper right', fontsize=11, framealpha=1) plt.xlim([-1.9, 1.9]) plt.ylim([-1.9, 1.9]) plt.show()
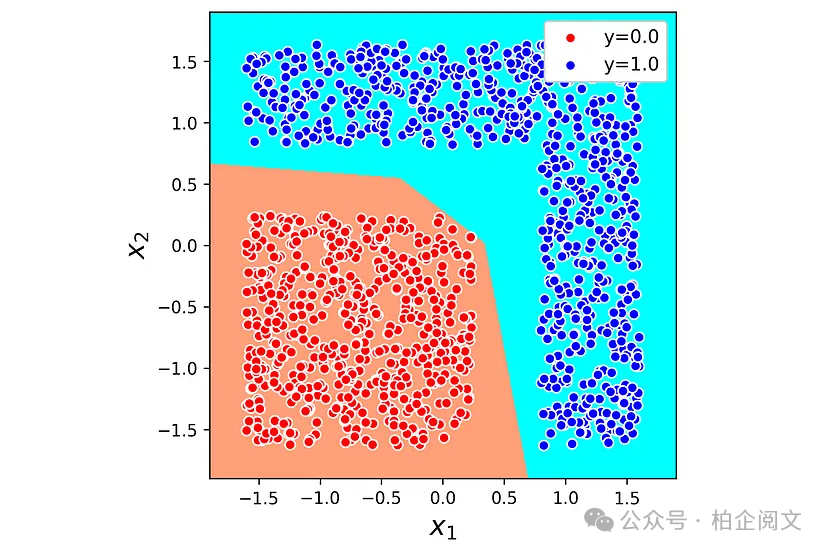
图19
该模型能够正确分离标签为0和1的数据点,但决策边界不再是直线。模型是如何做到的呢?让我们看看隐藏层和输出层的输出。清单22绘制了隐藏层的输出(图20)。请注意,隐藏层中有三个神经元,它们的输出用、和表示。因此,我们需要在三维空间中绘制它们。在这种情况下,输出层的决策边界是一个平面,将隐藏空间中的数据点分开。
hidden_layer_model = Model(inputs=model5.input, outputs=model5.layers[1].output) hidden_layer_output = hidden_layer_model.predict(X4) output_layer_weights = model5.layers[-1].get_weights()[0] output_layer_biases = model5.layers[-1].get_weights()[1] w0 = output_layer_biases[0] w1, w2, w3= output_layer_weights[0, 0], \ output_layer_weights[1, 0], output_layer_weights[2, 0] fig = plt.figure(figsize=(7, 7)) ax = fig.add_subplot(111, projection='3d') lims=[0, 4, 0, 4] ga1, ga2 = np.meshgrid(np.arange(lims[0], lims[1], (lims[1]-lims[0])/500.0), np.arange(lims[2], lims[3], (lims[3]-lims[2])/500.0)) ga1l = ga1.flatten() ga2l = ga2.flatten() ga3 = (0.5 - (w0 + w1*ga1l + w2*ga2l)) / w3 ga3 = ga3.reshape(500, 500) ax.plot_surface(ga1, ga2, ga3, alpha=0.5) marker_colors = ['red', 'blue'] target_labels = np.unique(y4) n = len(target_labels) for i, label in enumerate(target_labels): ax.scatter(hidden_layer_output[y4==label, 0], hidden_layer_output[y4==label, 1], hidden_layer_output[y4==label, 2], label="y="+str(label), color=marker_colors[i]) ax.view_init(0, 25) ax.set_xlabel('$a_1$', fontsize=14) ax.set_ylabel('$a_2$', fontsize=14) ax.set_zlabel('$a_3$', fontsize=14) ax.legend(loc="best") plt.show()
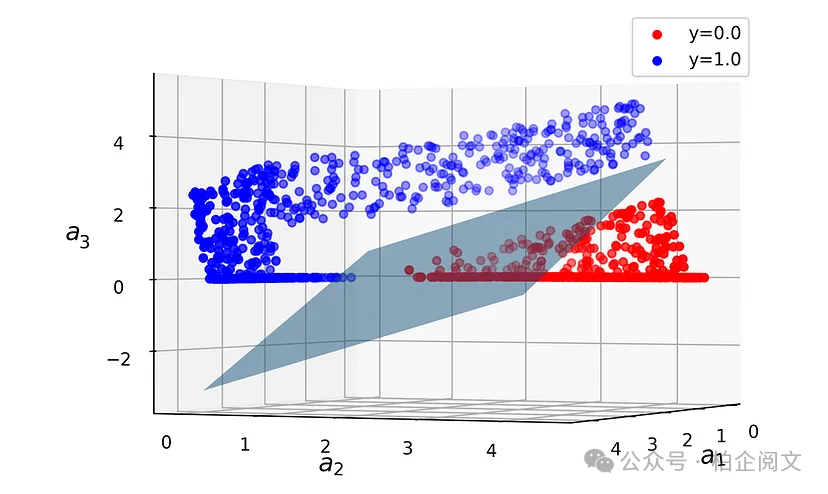
图20
原始数据集是二维且非线性可分的。因此,隐藏层将其转化为一个三维数据集,现在这个数据集是线性可分的。然后,输出层创建的平面可以轻松对其进行分类。
所以我们得出结论,图19中所示的非线性决策边界就像是一种错觉,我们在输出层仍然有一个线性分类器。然而,当这个平面映射回原始的二维数据集时,它就呈现为非线性决策边界(图21)。
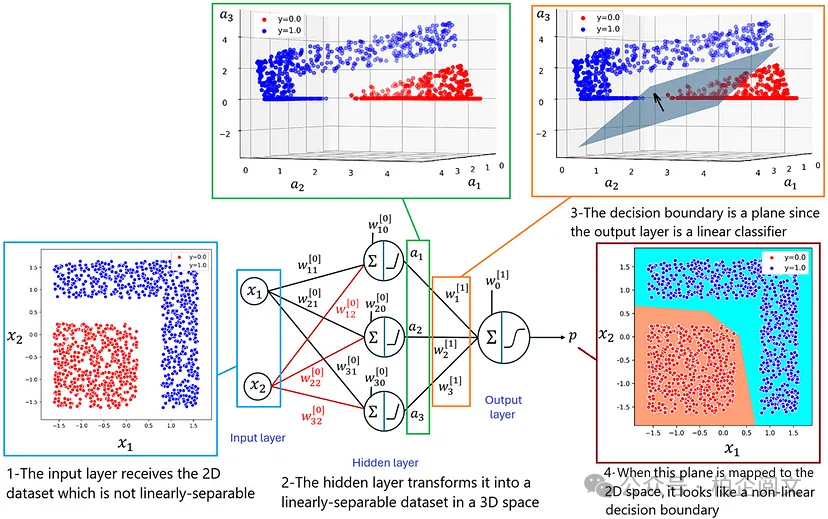
图21
维度游戏
当数据点通过神经网络的每一层时,该层中神经元的数量决定了数据点的维度。这里每个神经元编码一个维度。由于原始数据集是二维的,我们在输入层需要两个神经元。隐藏层有三个神经元,所以它将二维数据点转化为三维数据点。额外的维度在某种程度上展开了输入数据集,并有助于将其转化为线性可分的数据集。最后,输出层只是三维空间中的一个线性分类器。
多层网络的性能取决于隐藏层将输入数据集线性化的能力。本例中定义的神经网络的隐藏层能够将原始数据集转化为线性可分的数据集。然而在现实中,这并不总是可行的。隐藏层有时能得到的最好结果是将数据集转化为大致线性可分。因此,输出层可能会将某些数据点错误分类。不过,只要模型的整体准确率在实际应用中足够高,这是可以接受的。
此外,具有多个隐藏层的神经网络很常见。在这种情况下,隐藏层共同作用,最终创建出一个线性可分的数据集。
对非线性激活函数的需求
在隐藏层中使用非线性激活函数(如ReLU)至关重要。我们可以通过一个例子来解释非线性激活函数的重要性。让我们用线性激活函数替换前面神经网络中的ReLU激活函数。线性激活函数定义如下:
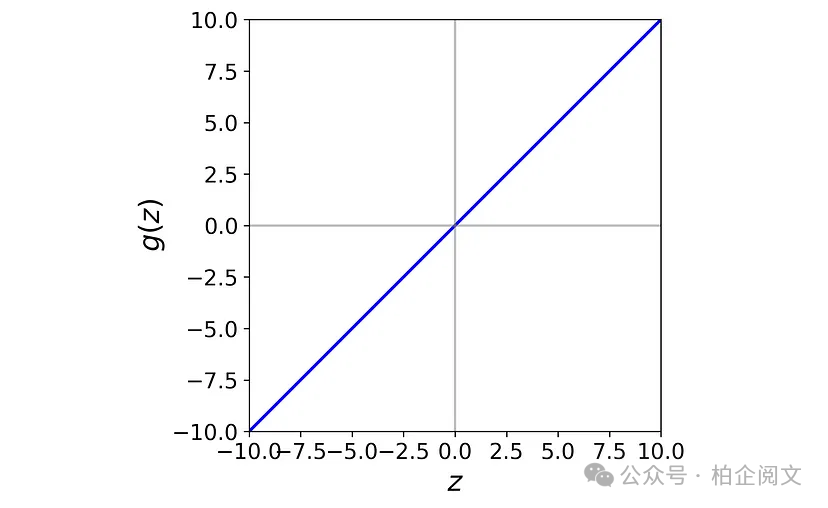
图22
图22展示了这个激活函数的图像。 现在,让我们对图17中之前的神经网络的隐藏层使用线性激活函数。重新设计的神经网络如图23所示。
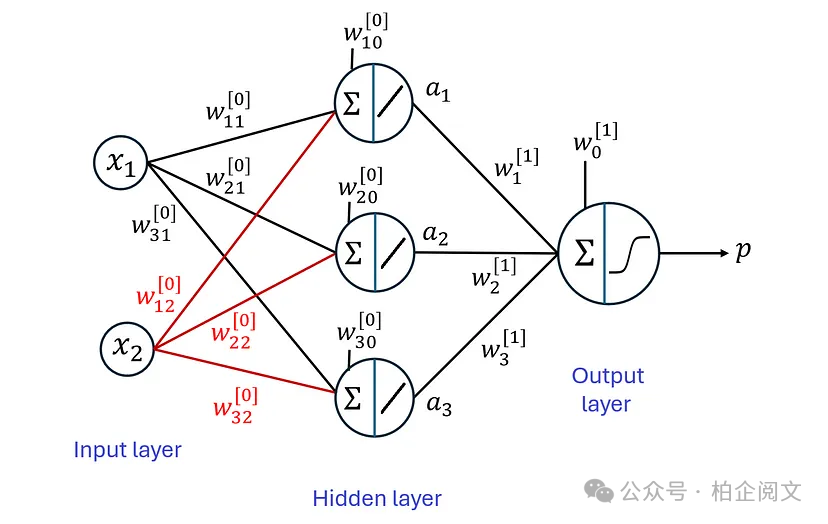
图23
清单23定义了这个神经网络,并用之前的数据集对其进行训练,决策边界如图24所示。
backend.clear_session() np.random.seed(2) random.seed(2) tf.random.set_seed(2) input_layer = Input(shape=(2,)) hidden_layer_linear = Dense(3, activation='linear')(input_layer) output_layer = Dense(1, activation='sigmoid')(hidden_layer_linear) model6 = Model(inputs=input_layer, outputs=output_layer) model6.compile(loss = 'binary_crossentropy', optimizer='adam', metrics=['accuracy']) history6 = model6.fit(X4, y4, epochs=1000, verbose=0, batch_size=X4.shape[0]) plt.figure(figsize=(5,5)) plot_boundary(X4, y4, model6, lims=[-2, 2, -2, 2]) ax = plt.gca() ax.set_aspect('equal') plt.xlabel('$x_1$', fontsize=16) plt.ylabel('$x_2$', fontsize=16) plt.legend(loc='upper right', fontsize=11, framealpha=1) plt.xlim([-1.9, 1.9]) plt.ylim([-1.9, 1.9]) plt.show()
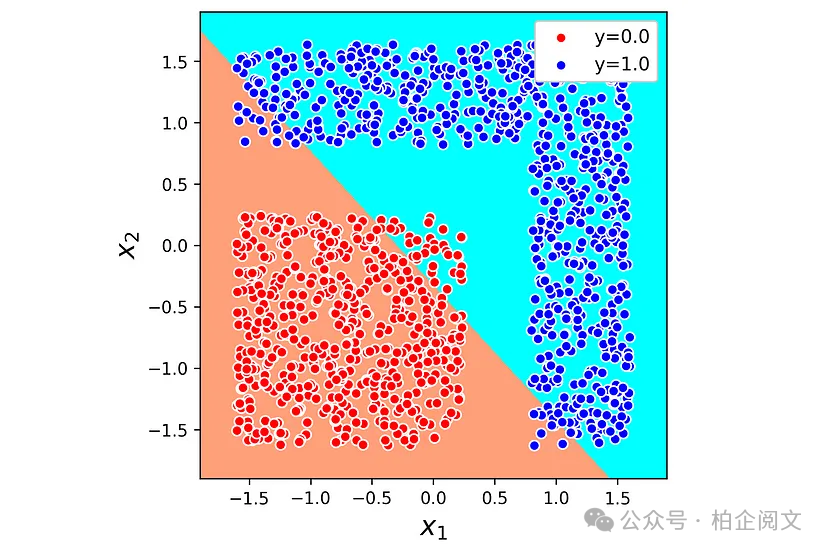
图24
我们看到决策边界仍然是一条直线,这意味着隐藏层无法将数据集线性化。让我们解释一下原因。由于我们使用的是线性激活函数,隐藏层的输出如下:
这些方程可以用向量形式表示为:
这意味着在空间中的每个数据点都位于一个与向量
平行的平面上。 清单24绘制了包含向量和的隐藏层的输出,该图显示在图25的右侧。
fig = plt.figure(figsize=(7, 7)) ax = fig.add_subplot(111, projection='3d') lims=[-3, 4, -3, 4] ga1, ga2 = np.meshgrid(np.arange(lims[0], lims[1], (lims[1]-lims[0])/500.0), np.arange(lims[2], lims[3], (lims[3]-lims[2])/500.0)) ga1l = ga1.flatten() ga2l = ga2.flatten() ga3 = (0.5 - (w0 + w1*ga1l + w2*ga2l)) / w3 ga3 = ga3.reshape(500, 500) ax.plot_surface(ga1, ga2, ga3, alpha=0) marker_colors = ['red', 'blue'] target_labels = np.unique(y4) n = len(target_labels) for i, label in enumerate(target_labels): ax.scatter(hidden_layer_output[y4==label, 0], hidden_layer_output[y4==label, 1], hidden_layer_output[y4==label, 2], label="y="+str(label), color=marker_colors[i], alpha=0.15) ax.quiver([0], [0], [0], hidden_layer_weights[0,0], hidden_layer_weights[0,1], hidden_layer_weights[0,2], color=['black'], length=1.1, zorder=15) ax.quiver([0], [0], [0], hidden_layer_weights[1,0], hidden_layer_weights[1,1], hidden_layer_weights[1,2], color=['black'], length=1.1, zorder=15) ax.view_init(30, 100) ax.set_xlabel('$a_1$', fontsize=14) ax.set_ylabel('$a_2$', fontsize=14) ax.set_zlabel('$a_3$', fontsize=14) ax.legend(loc="best") plt.show()
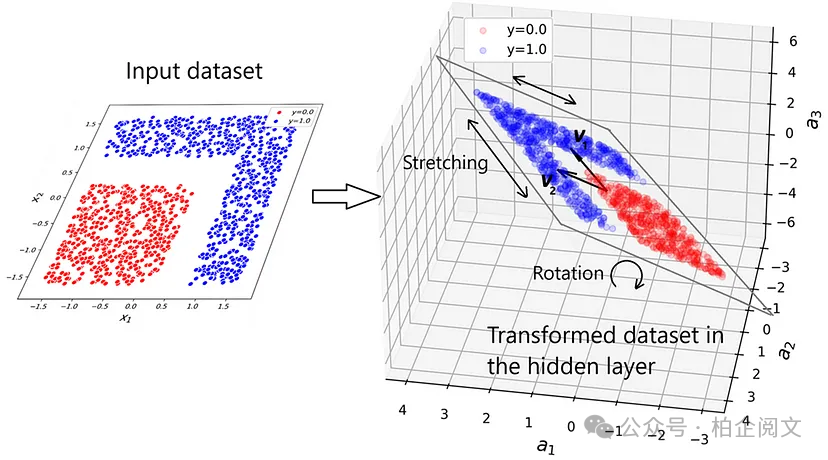
图25
在空间中的数据点看似是三维的,然而它们的数学维度是二维,因为它们都位于一个二维平面上。虽然隐藏层有3个神经元,但它无法生成真正的三维数据集。它只能在三维空间中旋转原始数据集,并沿着向量和拉伸它。然而,这些操作并没有破坏原始数据集的结构,转换后的数据集仍然是非线性可分的。因此,输出层创建的平面无法正确分类数据点。当这个平面映射回二维空间时,它呈现为一条直线(图26)。
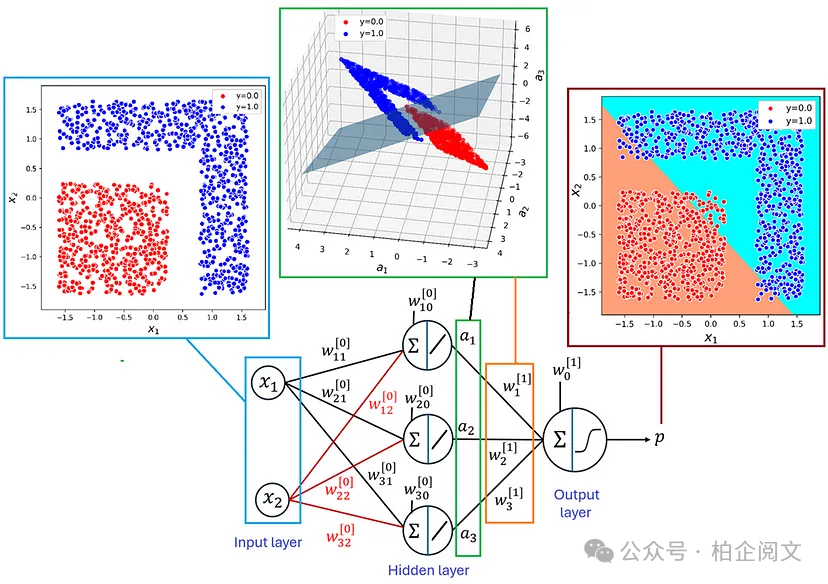
图26
总之,隐藏层中神经元的数量并不是定义转换后数据集数学维度的唯一因素。没有非线性激活函数,原始数据集的数学维度不会改变,隐藏层也无法实现其目的。
用于回归的神经网络
在本节中,我们将了解神经网络如何解决回归问题。在回归问题里,数据集的目标是一个连续变量。我们首先在清单25中创建这样一个数据集的示例,并将其绘制在图27中。
np.random.seed(0) num_points = 100 X5 = np.linspace(0,1, num_points) y5 = -(X5-0.5)**2 + 0.25 fig = plt.figure(figsize=(5, 5)) plt.scatter(X5, y5) plt.xlabel('x', fontsize=14) plt.ylabel('y', fontsize=14) plt.show()
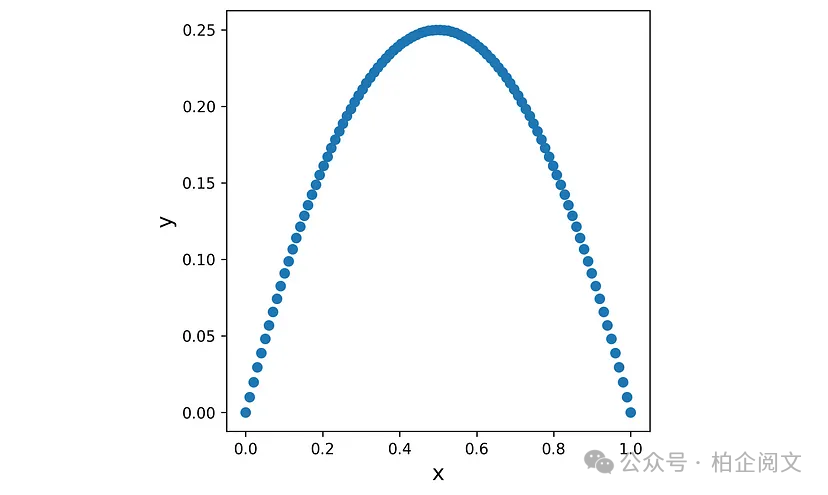
图27
单层网络
我们先尝试单层神经网络。这里,输出层有一个具有线性激活函数的神经元,该神经网络如图28所示。
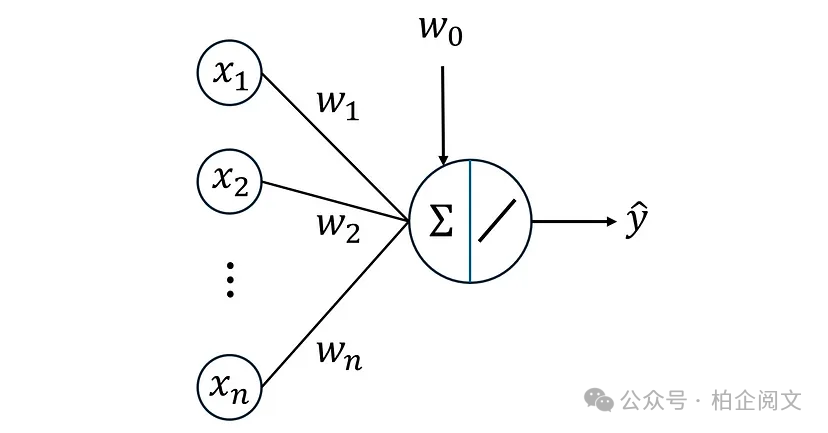
图28
其输出可以写为:
现在,如果我们为此使用均方误差(MSE)成本函数,它就会变得像一个线性回归模型。清单26使用前面的数据集来训练这样的网络。由于数据集只有一个特征,因此神经网络最终只有一个神经元(图29)。
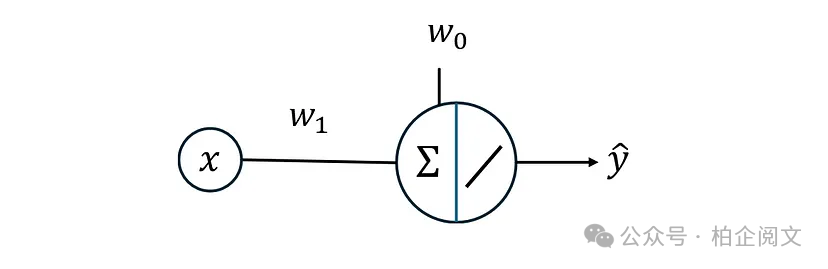
图29
backend.clear_session() np.random.seed(0) random.seed(0) tf.random.set_seed(0) model6 = Sequential() model6.add(Dense(1, activation='linear', input_shape=(1,))) model6.compile(optimizer='adam', loss='mse', metrics=['mse']) history7 = model6.fit(X5, y5, epochs=500, verbose=0, batch_size=X5.shape[0])
训练模型后,我们可以绘制其预测与原始数据点的对比图。
X5_test = np.linspace(0,1, 1000) yhat1 = model6.predict(X5_test) fig = plt.figure(figsize=(5, 5)) plt.scatter(X5, y5, label="Train data") plt.plot(X5_test, yhat1, color="red", label="Prediction") plt.xlabel('x', fontsize=14) plt.ylabel('y', fontsize=14) plt.legend(loc="best", fontsize=11) plt.show()
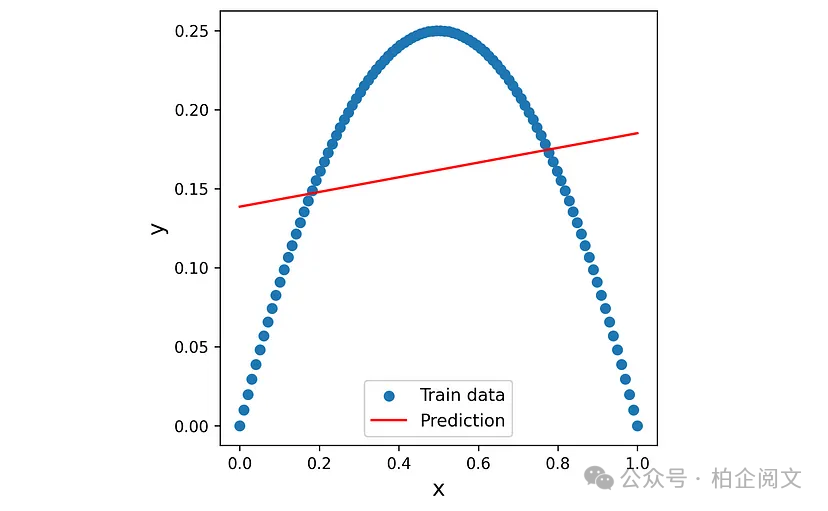
图30
因此,我们得出结论,具有线性激活函数和MSE成本函数的单层神经网络的行为类似于线性回归模型。
多层网络
要学习非线性数据集,我们需要添加隐藏层。图31展示了这样一个网络的示例,这里我们有一个带有线性激活函数的隐藏层。
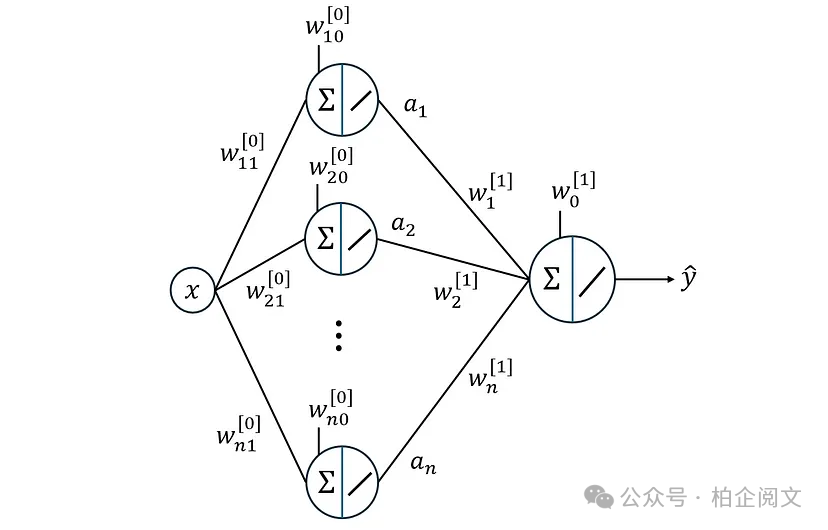
图31
然而,这个神经网络的表现也类似于线性回归模型。为了解释原因,我们先写出隐藏层的输出:
现在,我们可以计算神经网络的输出:
这意味着,使用MSE成本函数时,神经网络的行为仍然类似于线性模型。为了避免这个问题,我们需要在隐藏层中使用非线性激活函数。
在下一个示例中,我们将隐藏层的激活函数替换为ReLU,如图32所示。在这里,隐藏层有10个神经元。
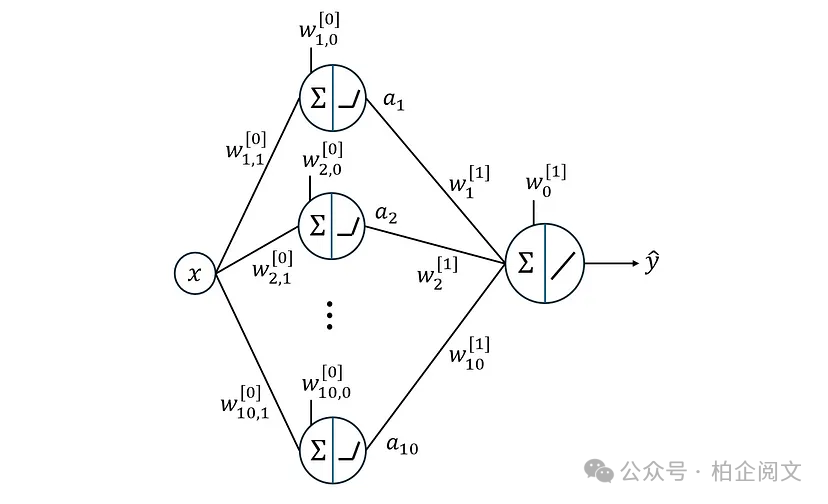
图32
清单28实现并训练了这个神经网络。
backend.clear_session() np.random.seed(15) random.seed(15) tf.random.set_seed(15) input_layer = Input(shape=(1,)) x = Dense(10, activation='relu')(input_layer) output_layer = Dense(1, activation='linear')(x) model7 = Model(inputs=input_layer, outputs=output_layer) model7.compile(optimizer='adam', loss='mse', metrics=['mse']) history8 = model7.fit(X5, y5, epochs=1500, verbose=0, batch_size=X5.shape[0]) hidden_layer_model = Model(inputs=model7.input, outputs=model7.layers[1].output) hidden_layer_output = hidden_layer_model.predict(X5_test) output_layer_weights = model7.layers[-1].get_weights()[0] output_layer_biases = model7.layers[-1].get_weights()[1]
经过训练,我们终于可以绘制出这个神经网络的预测结果。
X5_test = np.linspace(0,1, 1000) yhat2 = model7.predict(X5_test) fig = plt.figure(figsize=(5, 5)) plt.scatter(X5, y5, label="Train data", alpha=0.7) plt.plot(X5_test, yhat2, color="red", label="Prediction") plt.xlabel('x', fontsize=14) plt.ylabel('y', fontsize=14) plt.legend(loc="best", fontsize=11) plt.show()
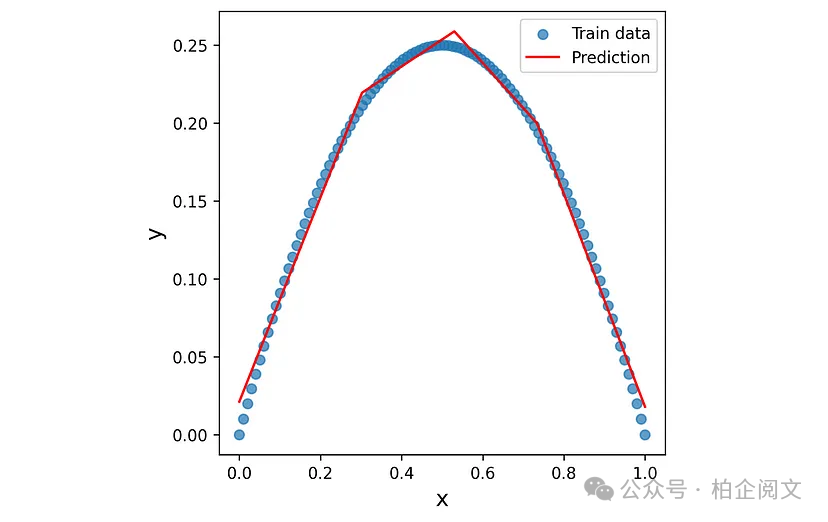
图33
我们看到网络现在可以生成非线性预测。让我们看一下隐藏层。下一个清单绘制了隐藏层 的输出,如图34所示。输出神经元首先将每个 乘以其相应的权重()。最后,它计算以下总和
这是神经网络的预测。所有这些项都绘制在图34中。
fig, axs = plt.subplots(10, 4, figsize=(18, 24)) plt.subplots_adjust(wspace=0.55, hspace=0.2) for i in range(10): axs[i, 0].plot(X5_test, hidden_layer_output[:, i], color="black") axs[i, 1].plot(X5_test, hidden_layer_output[:, i]*output_layer_weights[i], color="black") axs[i, 0].set_ylabel(r'$a_{%d}$' % (i+1), fontsize=21) axs[i, 1].set_ylabel(r'$w^{[1]}_{%d}a_{%d}$' % (i+1, i+1), fontsize=21) axs[i, 2].axis('off') axs[i, 3].axis('off') axs[i, 0].set_xlabel("x", fontsize=21) axs[i, 1].set_xlabel("x", fontsize=21) axs[4, 2].axis('on') axs[6, 2].axis('on') axs[4, 2].plot(X5_test, [output_layer_biases]*len(X5_test)) axs[6, 2].plot(X5_test, (hidden_layer_output*output_layer_weights.T).sum(axis=1)) axs[6, 2].set_xlabel("x", fontsize=21) axs[4, 2].set_ylabel("$w^{[1]}_0$", fontsize=21) axs[4, 2].set_xlabel("x", fontsize=21) axs[6, 2].set_ylabel("Sum", fontsize=21) axs[5, 3].axis('on') axs[5, 3].scatter(X5, y5, alpha=0.3) axs[5, 3].plot(X5_test, yhat2, color="red") axs[5, 3].set_xlabel("x", fontsize=21) axs[5, 3].set_ylabel("$\hat{y}$", fontsize=21) plt.show()
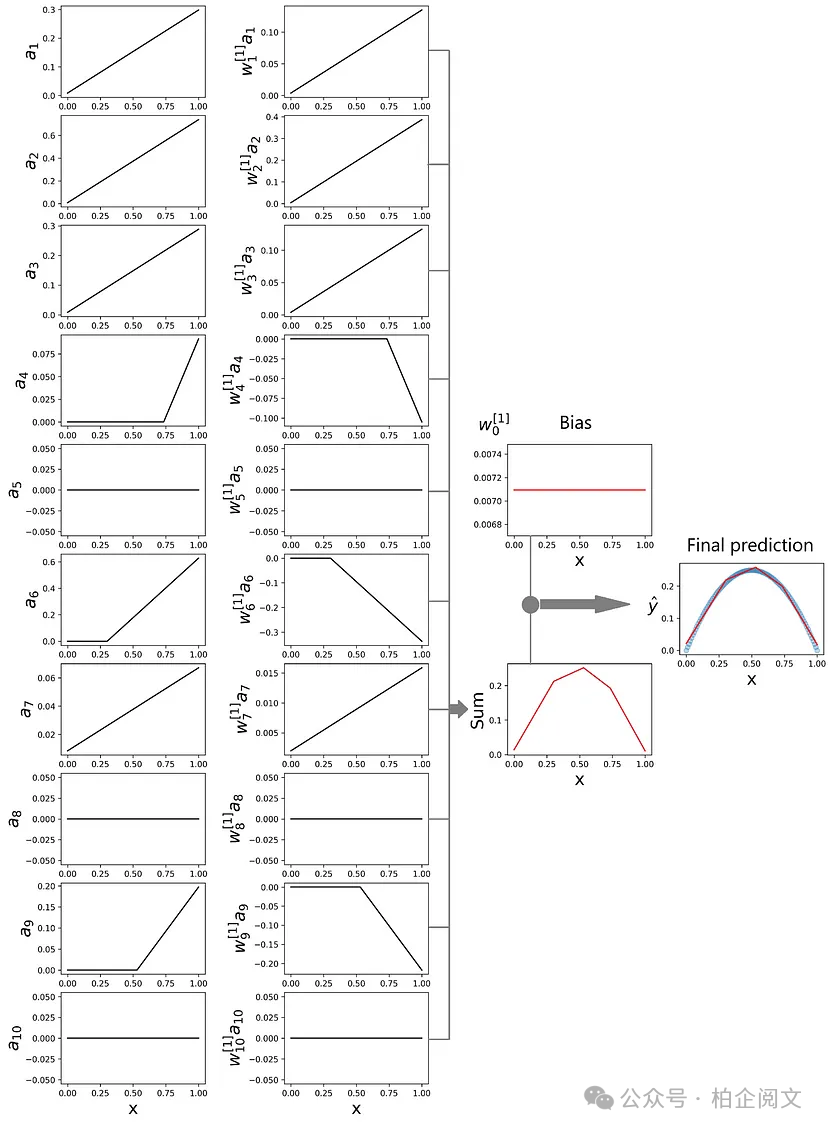
图34
在我们的神经网络中,隐藏层中的每个神经元都有一个ReLU激活函数。我们在图18中展示了ReLU激活函数的图像,它由两条在原点相交的线组成。左边的一条是水平的,而另一条的斜率为1。隐藏层中每个神经元的权重和偏差会改变ReLU的形状,它可以改变交点的位置、这些线的顺序以及非水平线的斜率。之后,输出层的权重也可以改变非水平线的斜率。图35展示了此类变化的一个示例。
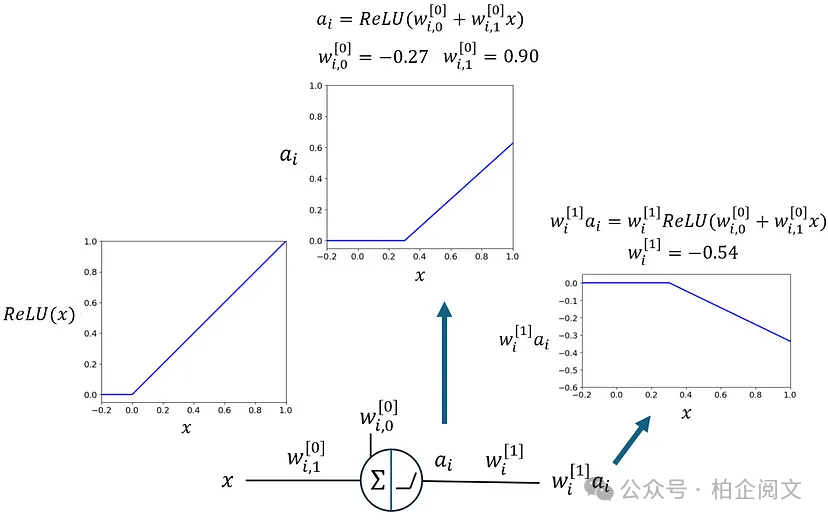
图35
然后,修改后的ReLU函数被组合起来以近似数据集目标的形状,如图36所示。每个修改后的ReLU函数都有一个简单的结构,但大量的它们组合在一起可以近似任何连续函数。最后,将输出层的偏差添加到ReLU函数的总和中,以便在垂直方向上进行调整。
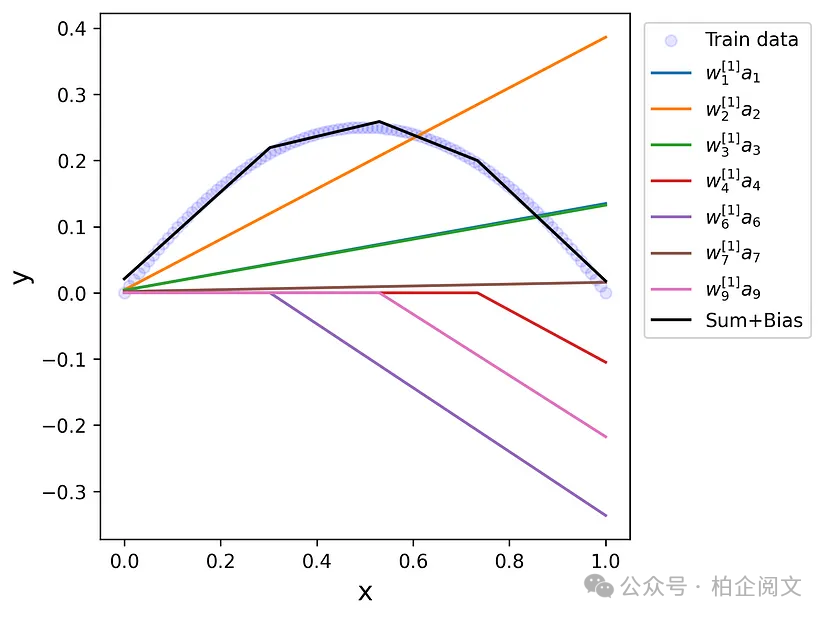
图36
通用近似定理指出,具有一个包含足够多神经元的隐藏层的前馈神经网络,只要激活函数是非常量、有界且连续的,就可以以任何所需的精度逼近输入子集上的任何连续函数。为了在实践中证明这一点,我们使用清单28中的相同神经网络,但这次隐藏层中有400个神经元。图37展示了该神经网络的预测。可以看到,向隐藏层添加更多神经元显著提高了神经网络逼近目标的能力。
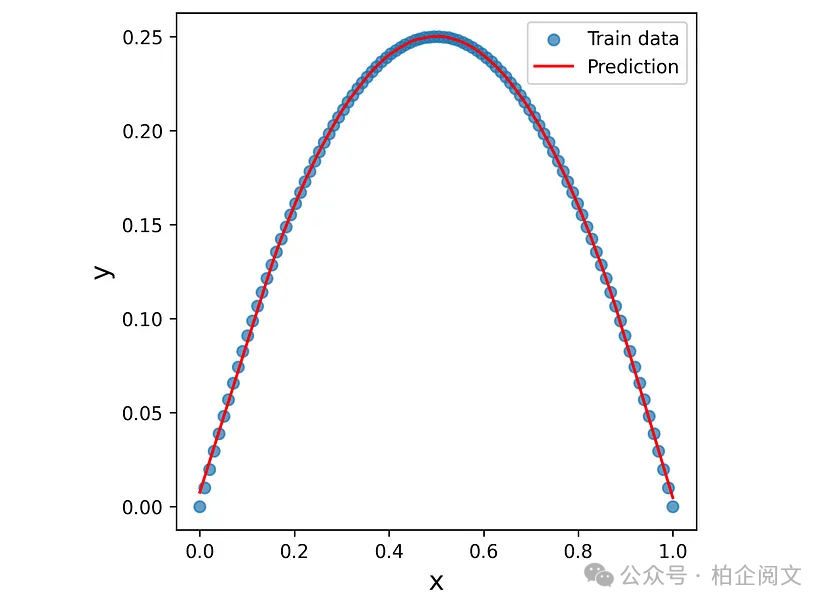
图37
在本文中,我们直观地介绍了神经网络,以及每一层在最终预测中所起的作用。我们从感知器开始,展示了单层网络的局限性。我们发现,在分类问题中,单层神经网络等同于线性分类器;在回归问题中,其行为类似于线性回归模型。我们还解释了隐藏层和非线性激活函数的作用。在分类问题中,隐藏层试图将非线性可分数据集线性化;在回归问题中,隐藏层中神经元的输出就像非线性构建块,它们被组合在一起以进行最终预测。
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)