大白话讲透一个大模型知识点——过拟合(overfitting)
大模型(如GPT、BERT等)参数量巨大(数十亿甚至万亿参数),理论上可以记住海量数据中的细节,但这也让过拟合的风险更高。小朋友只记住了你给的训练图片中的细节(比如某张图里的小狗狗戴了红色项圈),导致他认为“所有小狗都必须戴红色项圈”,遇到没戴项圈的小狗就无法识别。可能表现为训练损失(loss)很低,但实际应用中生成的内容不合理(例如胡言乱语),或者对数据中的噪声(比如标点错误、拼写错误)过于敏感
01
什么是过拟合?
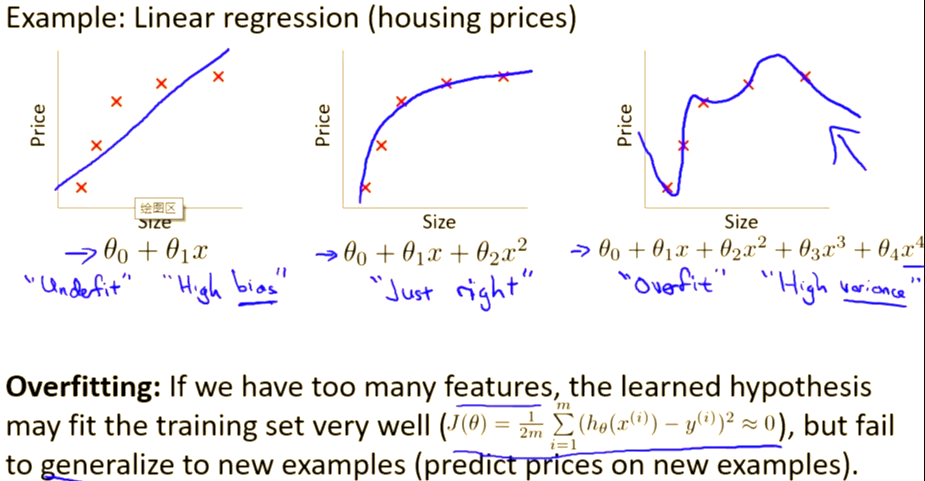
过拟合是指机器学习模型在训练数据上表现很好(比如准确率极高)但在新数据(测试集或实际应用场景)上表现明显下降的现象。
简单来说,模型“死记硬背”了训练数据的细节(甚至噪声),而不是真正理解数据的规律,导致泛化能力差。
举2个生活化的例子:
1.假设你为了考试,只背了课本上的例题答案,而没有理解解题思路。如果考试题目稍微改几个数字,你就不会做了–这就是“过拟合”的后果。
2.假设你要教一个小朋友识别“小狗”:
理想情况: 小朋友学会小狗的共同特征(耳朵形状、眼睛、鼻0子等),能认出任何猫。
过拟合情况: 小朋友只记住了你给的训练图片中的细节(比如某张图里的小狗狗戴了红色项圈),导致他认为“所有小狗都必须戴红色项圈”,遇到没戴项圈的小狗就无法识别。
知识点: 过拟合=模型对训练数据“细节/噪音”过度敏感,导致泛化能力差!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
02
大模型中的过拟合有什么特殊性
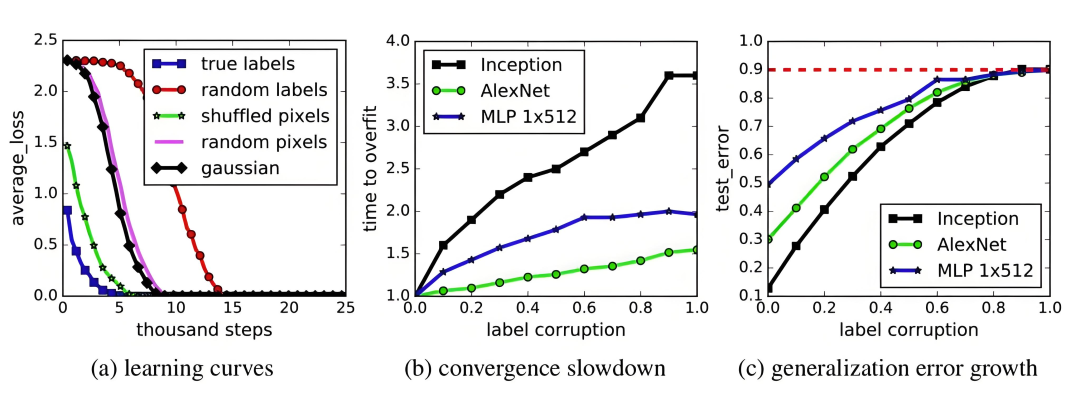
大模型(如GPT、BERT等)参数量巨大(数十亿甚至万亿参数),理论上可以记住海量数据中的细节,但这也让过拟合的风险更高。不过,大模型的过拟合可能更隐蔽:
传统模型过拟合: 训练集表现好,测试集表现差。
大模型过拟合: 可能表现为训练损失(loss)很低,但实际应用中生成的内容不合理(例如胡言乱语),或者对数据中的噪声(比如标点错误、拼写错误)过于敏感。
大模型的典型过拟合场景:
过度依赖训练数据中的局部模式(例如重复出现的特定短语);在低质量数据上训练时,模型记住了噪声而非语义;在小规模下游任务微调(Fine-tuning)时,如果微调数据量不足,大模型容易过拟合到微调数据。
03
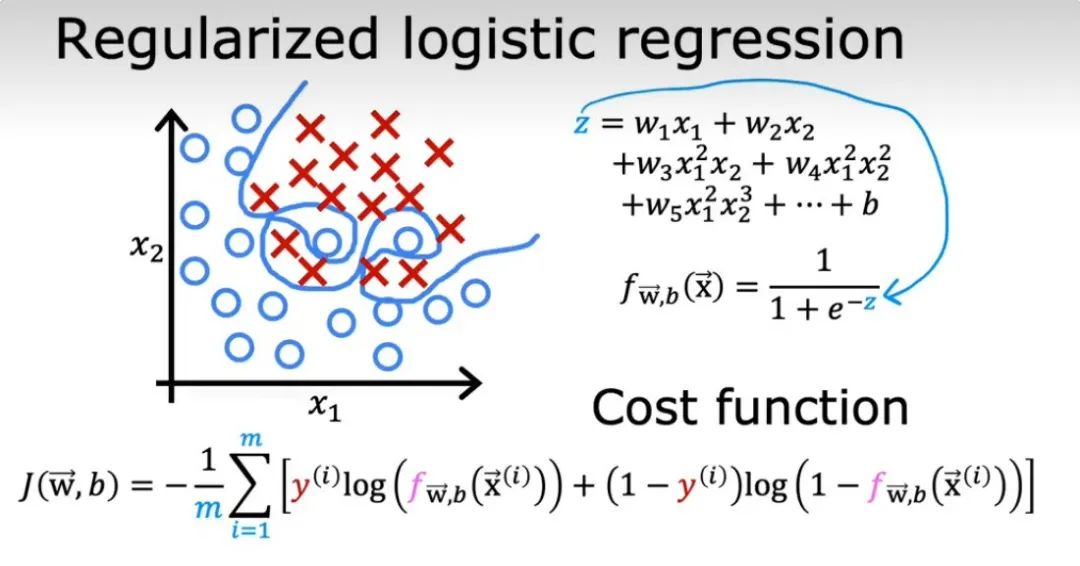
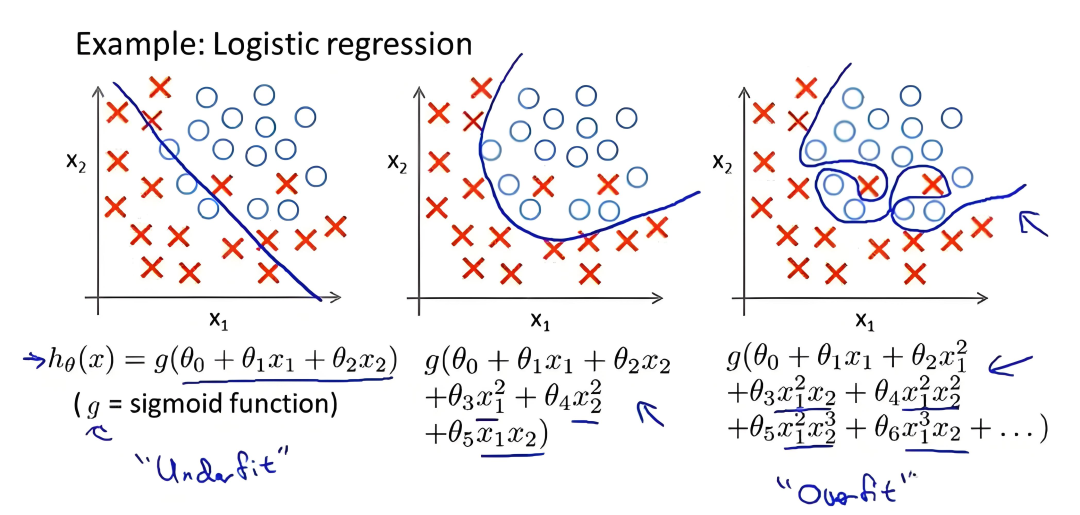
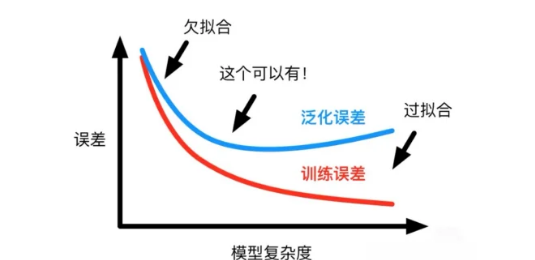
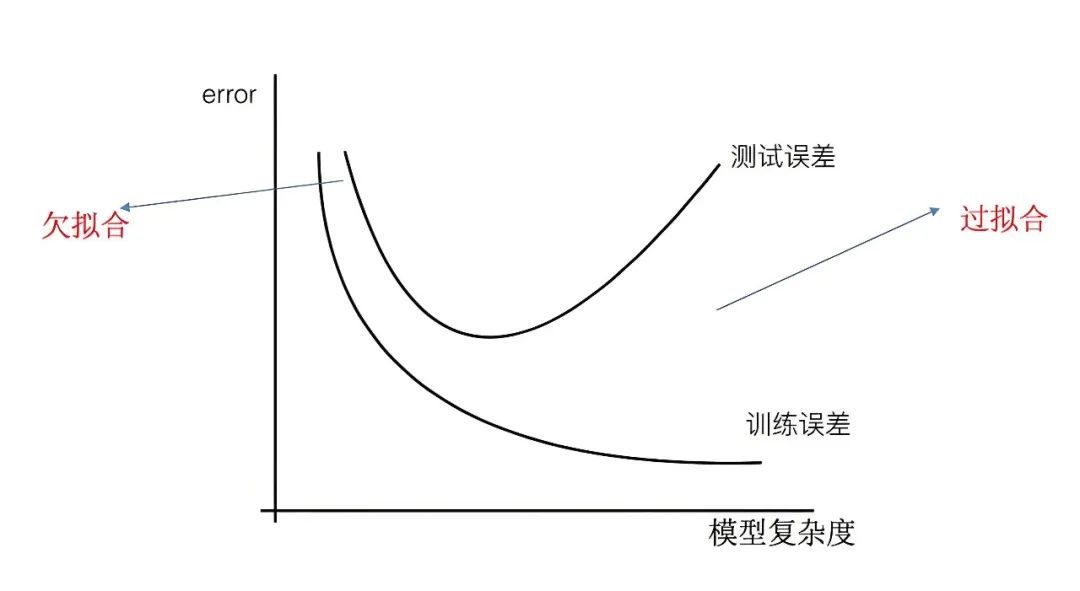
过拟合 VS 欠拟合(Underfitting)
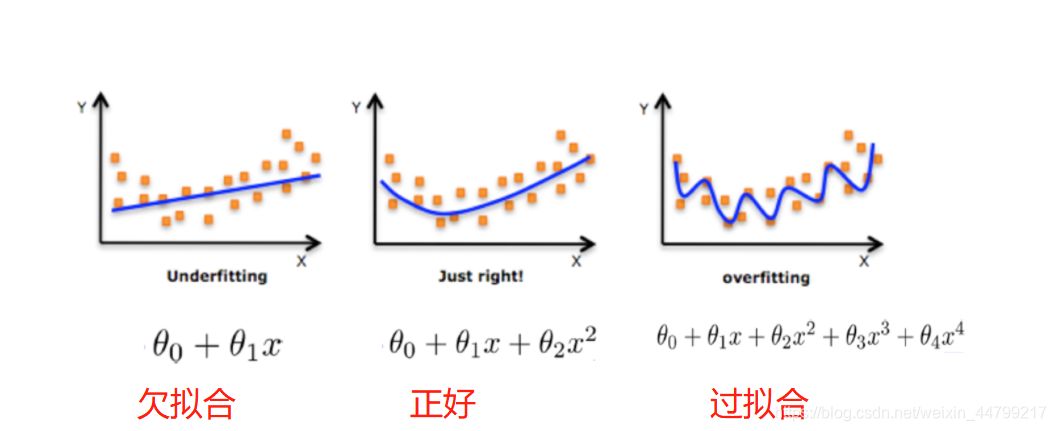
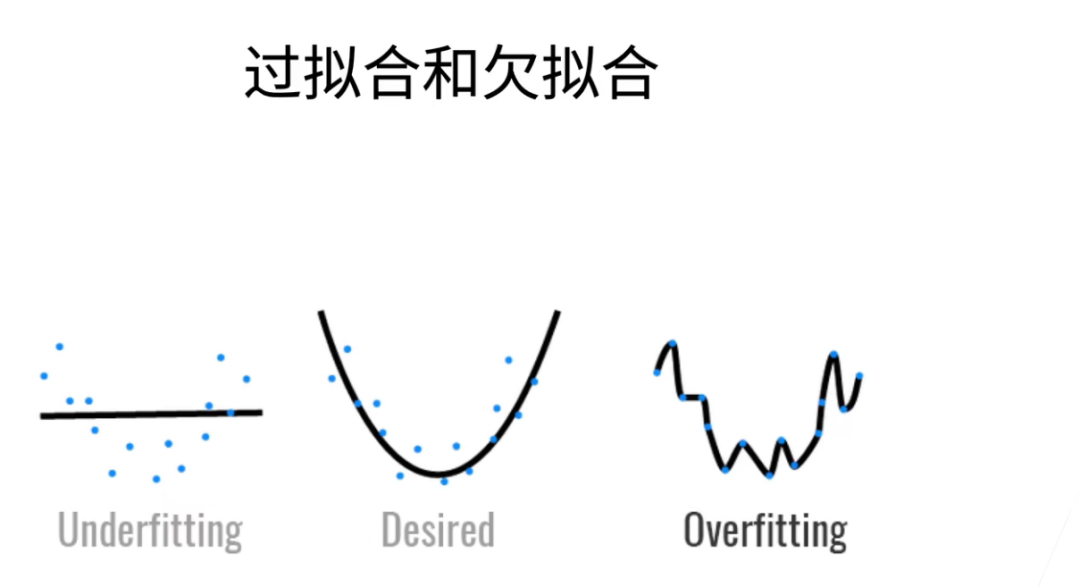
欠拟合: 模型在训练数据和测试数据上都表现差(模型太简单,学不到规律)。
过拟合: 模型在训练数据上表现好,测试数据上差(模型太复杂,学过头了)。
04
大模型过拟合的常见原因
参数过多,数据不足: 模型参数规模远超训练数据量,导致“死记硬背”。
数据质量低: 训练数据中存在重复、噪声或错误标注。训练时间过长:过度迭代(epoch过多)会让模型逐渐拟合训练数据中的噪声。
任务过于简单: 如果任务简单但模型复杂,可能学到无用的细节。
此处举个小例子:
假设训练数据中有一条重复100次的句子: “苹果是一种水果。”,模型可能过度强化“苹果=水果”的关联,而忽略其他含义(比如“苹果公司”)。
数据太少: 模型被迫记住所有细节,连噪点都不放过!
模型太复杂: 学霸脑容量过大,连“老师咳嗽几声”都能当成考点
训练太久: 反复刷同一套题,越练越魔怔…
05
如何判断大模型是否过拟合?
训练损失vs.验证损失: 训练损失持续下降,但验证损失(validation loss)开始上升。
生成内容不合理: 模型输出的文本看似符合语法,但逻辑混乱或包含训练数据中的特定片段。
对微小扰动敏感: 输入稍修改(比如替换同义词),输出差异巨大。
06
如何缓解大模型过拟合?
增加数据量: 收集更多数据,或使用数据增强(如文本中的同义词替换、图像中的旋转裁剪)。
正则化技术:
-
权重衰减(L2正则化): 限制模型参数的大小。
-
Dropout: 随机“关闭”一部分神经元,迫使模型学习冗余特征。
早停(Early stopping): 当验证损失不再下降时,提前终止训练。
简化模型: 减少参数量(但大模型通常依赖规模效应,需谨慎)。
交叉验证: 将数据分成多份,轮流作为训练集和验证集。
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)