从零到一:构建基于 openGauss 向量数据库的 RAG 应用(超详细填坑指南)------(2)
本文介绍了如何基于SpringBoot集成openGauss数据库实现RAG(检索增强生成)知识问答系统。文章首先讲解了RAG技术原理,即通过检索私有知识库相关内容来增强大语言模型的回答准确性。然后详细展示了项目实现过程:从环境配置(SpringBoot 3.X、Ollama服务、openGauss数据库)、代码架构(Controller、Service、Repository三层设计),到核心功能
在上一篇文章中介绍了openGauss数据库环境的构建以及利用DBeaver进行连接,如果已经成功连接上了数据库,那么接下来我们进行demo程序的讲解。具体的demo是参照官方的该篇贴子进行实现,不过官方只搭了架子,作者在这里将其扩展成可运行的完整代码。Spring Boot集成openGauss DataVec实现高效RAG知识问答![]() https://blog.csdn.net/weixin_49727236/article/details/147642407?ops_request_misc=%257B%2522request%255Fid%2522%253A%252254e269ff4d500ff031cf14ad1c379351%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=54e269ff4d500ff031cf14ad1c379351&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-4-147642407-null-null.142^v102^pc_search_result_base2&utm_term=springboot%E9%9B%86%E6%88%90opengauss&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_49727236/article/details/147642407?ops_request_misc=%257B%2522request%255Fid%2522%253A%252254e269ff4d500ff031cf14ad1c379351%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=54e269ff4d500ff031cf14ad1c379351&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-4-147642407-null-null.142^v102^pc_search_result_base2&utm_term=springboot%E9%9B%86%E6%88%90opengauss&spm=1018.2226.3001.4187
首先简单介绍一下关于RAG的相关知识。我们常见的大型语言模型虽然强大,但它们存在两个主要问题:知识截止(它们的知识不是实时的)和无法访问私有数据(它们不知道你公司的内部文档或最新的产品手册)。RAG技术优雅地解决了这个问题,其核心思想非常直观:
-
检索 (Retrieve): 当用户提问时,先不去问LLM,而是从你的私有知识库中检索出最相关的几段信息。
-
增强 (Augment): 将这些检索到的信息作为上下文,和用户的原始问题一起“打包”。
-
生成 (Generate): 将这个增强后的、信息量更丰富的提示(Prompt)发送给LLM,让它基于你提供的上下文来生成答案。
这样,LLM就变成了一个基于“开卷考试”的推理引擎,其回答的准确性和时效性得到了极大的保证。好的接下来进入具体的项目demo讲解!
一.环境配置
Spring Boot 3.X及以上版本
Ollama服务安装部署
openGauss数据库安装部署
Maven的pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.7</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.gt.rag</groupId>
<artifactId>springboot-rag</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot-rag</name>
<description>springboot-rag</description>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- OpenGauss JDBC 驱动 -->
<dependency>
<groupId>org.opengauss</groupId>
<artifactId>opengauss-jdbc</artifactId>
<version>6.0.0</version>
</dependency>
<!-- PostgreSQL 驱动 (兼容 OpenGauss) -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.5.4</version>
</dependency>
<!-- Spring AI Ollama 集成 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>1.0.0-M5</version>
</dependency>
<!-- Jackson 用于 JSON 处理 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
</dependencies>
<repositories>
<!-- OpenGauss Maven 仓库 -->
<repository>
<id>opengauss</id>
<name>openGauss Maven Repository</name>
<url>https://repo.opengauss.org/repository/maven-public/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
相关的环境配置文件application.yml
# Spring Boot服务相关配置
server:
port: 8088
spring:
application:
name: springboot-rag
# openGauss向量数据库相关配置
datasource:
url: jdbc:postgresql://localhost:8888/mydb
username: dbeaver_user // 数据库用户名,这里根据自己起的名字来上一节中讲的是app_user
password: YourPassword
driver-class-name: org.postgresql.Driver
# ollama chat服务相关配置
ai:
ollama:
base-url: http://localhost:11434
chat:
model: llama3
# ollama embedding服务相关配置
ollama:
model: nomic-embed-text:latest
modelDim: 768
embeddingURL: http://localhost:11434
这里Embedding模型采用nomic-embed-text回答模型采用llama3,数据库驱动采用PostgreSQL驱动,由于我这里openGauss驱动配置出错故采用其兼容的PostgreSQL驱动。
二.代码解读
Controller层代码
首先讲一下TestController层,本层用于测试IDEA中是否成功连接数据库,相关代码如下:
package com.gt.rag.controller;
import com.gt.rag.config.OpgsConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.sql.Connection;
import java.sql.DatabaseMetaData;
/**
* @RestController 这是一个组合注解,相当于 @Controller 和 @ResponseBody。
* 它告诉Spring,这个类是一个Web控制器,并且其中所有方法的返回值都应直接作为HTTP响应体,
* 通常是JSON或XML格式(在这里,由于方法返回String,它将是纯文本)。
*/
@RestController
public class TestController {
/**
* @Autowired 是Spring框架的核心注解,用于实现依赖注入(DI)。
* 当Spring容器创建TestController的实例时,它会自动查找一个已经创建好的OpgsConfig类型的Bean,
* 并将其注入到这个字段中。这样,TestController就可以直接使用OpgsConfig对象了。
*/
@Autowired
private OpgsConfig opgsConfig;
/**
* @GetMapping("/test-db") 将HTTP GET请求的路径 "/test-db" 映射到这个方法。
* 当用户通过浏览器或工具访问 "http://your-server/test-db" 时,这个方法就会被调用。
* @return 该方法返回一个字符串,这个字符串将直接作为HTTP响应的内容发送给客户端。
*/
@GetMapping("/test-db")
public String testDatabaseConnection() {
// 使用try-catch块来捕获在数据库连接过程中可能发生的任何异常(如SQLException)。
try {
// 1. 获取数据库连接
// 调用我们自定义的OpgsConfig类中的getConnection()方法。
// 这个方法封装了加载JDBC驱动和通过DriverManager建立连接的逻辑。
Connection conn = opgsConfig.getConnection();
// 2. 验证连接是否有效
// conn.isValid(5) 是一个检查数据库连接是否仍然活动的标准方法。
// 参数5表示等待响应的超时时间(秒)。如果连接有效,它会返回true。
boolean valid = conn.isValid(5);
// 3. 获取数据库元数据信息(用于展示)
// DatabaseMetaData对象包含了关于数据库本身的大量信息,如产品名称、版本、驱动信息等。
// 这对于调试和确认连接到了正确的数据库非常有用。
DatabaseMetaData metaData = conn.getMetaData();
// 拼接一条包含数据库产品和驱动信息的字符串,用于返回给用户。
String dbInfo = "数据库: " + metaData.getDatabaseProductName() +
" " + metaData.getDatabaseProductVersion() +
", 驱动: " + metaData.getDriverName() +
" " + metaData.getDriverVersion();
// 4. 关闭数据库连接
// 这是一个至关重要的步骤!每次获取连接后,在使用完毕时都必须关闭它,以释放数据库资源。
// 如果不关闭,会导致连接泄漏,最终耗尽数据库的连接数,使应用无法正常工作。
conn.close();
// 5. 返回成功信息
// 将连接验证结果和数据库信息拼接成一个最终的成功消息。
return "数据库连接测试: " + (valid ? "成功" : "失败") + ", " + dbInfo;
} catch (Exception e) {
// 如果在try块中的任何一步(获取连接、验证、关闭)发生异常,都会被这里捕获。
// e.printStackTrace() 会在服务器的控制台打印出完整的异常堆栈信息,这对于定位问题根源至关重要。
e.printStackTrace();
// 向客户端返回一个清晰的错误信息,包含了异常的具体消息。
return "数据库连接测试失败: " + e.getMessage();
}
}
}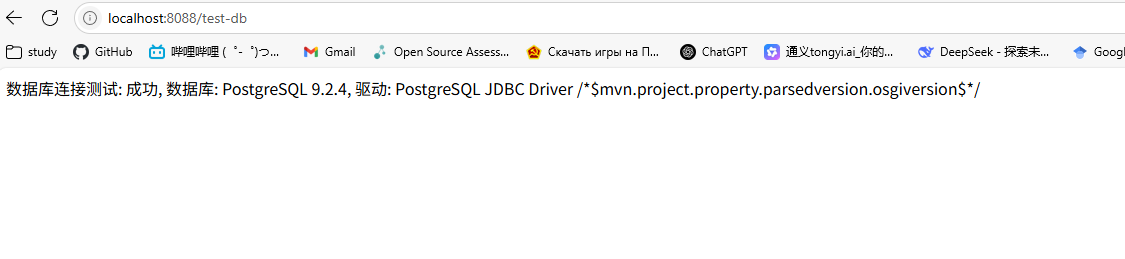 启动程序在浏览器的localhost:8088端口访问tst-db可以发现数据库连接成功,由于我这里使用的是openGauss数据库但是用的PostgreSQL的驱动导致显示的是PostgreSQL数据库,实际上数据确实最后存放在了Docker容器中的openGauss数据库中。
启动程序在浏览器的localhost:8088端口访问tst-db可以发现数据库连接成功,由于我这里使用的是openGauss数据库但是用的PostgreSQL的驱动导致显示的是PostgreSQL数据库,实际上数据确实最后存放在了Docker容器中的openGauss数据库中。
接着讲一下主体部分的RagController的代码,这里由/index和/chat两部分组成,首先是/index部分的代码。该部分实现了将代码中的几条硬编码的语句嵌入到向量数据库中并生成相应的索引,他们作为知识库的组成成分。
在实际生产环境中,这个过程可能会更复杂,比如:
-
从一个指定的文件夹读取所有.txt或.pdf文件。
-
使用更复杂的文档切分策略(Chunking)将长文档切分成小块。
-
将索引过程设计成一个异步的后台任务,而不是一个同步的API调用。
/**
* @GetMapping("/index") 将HTTP GET请求的路径 "/index" 映射到这个方法。
* 这个API端点的核心作用是【数据初始化和索引构建】。
* 它通常在系统首次启动或需要重建知识库时被调用一次。
* 它将一系列预定义的文本文档处理成向量,并构建一个可供快速检索的索引。
*
* @return 返回一个简单的字符串,告知调用者索引过程已成功完成。
*/
@GetMapping("/index")
public String IndexDoc()
{
// 第一步:准备数据库表结构
// 调用业务层(RagService)的方法来创建一个用于存储文本和向量的表。
// 这个方法内部会执行 "CREATE TABLE IF NOT EXISTS ..." SQL语句,
// 确保我们的知识库表(例如 txt_table)存在且结构正确。
// 为了保证每次索引都是全新的,这个方法通常也会清空表中的旧数据(TRUNCATE TABLE)。
ragService.CreateTxtTable();
// 第二步:插入并向量化文档
// 这里我们硬编码了几条示例文本作为我们的知识库源数据。
// 在实际应用中,这些数据可能来自文件(PDF, TXT)、数据库或其他数据源。
// 每次调用`InsertTuples`方法,都会执行以下子流程:
// 1. 将文本(如 "大规模预训练语言模型...")发送给Ollama的Embedding API。
// 2. Ollama返回一个代表该文本语义的向量(一个浮点数数组)。
// 3. 将原始文本和其对应的向量一起存入数据库的同一行中。
ragService.InsertTuples(0, "大规模预训练语言模型 高效并行训练 支持多种NLP任务");
ragService.InsertTuples(1, "多模态融合模型 结合文本、图像和音频输入 提供全面的数据理解能力");
ragService.InsertTuples(2, "分布式深度学习框架 易于扩展 支持大规模数据处理");
ragService.InsertTuples(3, "视频理解与生成模型 先进的时间序列分析技术 适用于监控和娱乐");
ragService.InsertTuples(4, "超高分辨率图像生成模型 GAN架构 强大的细节捕捉能力");
// 第三步:创建向量索引
// 当所有数据都插入到数据库后,这是至关重要的一步。
// 调用`IndexTxt`方法,它会在存储向量的列上创建一个专门的索引(如HNSW或IVFFlat索引)。
// 如果没有这个索引,后续的相似度搜索将需要进行全表扫描,性能会极其低下。
// 有了索引,即使在百万级的数据量下,也能实现毫秒级的快速检索。
ragService.IndexTxt();
// 第四步:返回成功响应
// 向调用者确认所有步骤——建表、数据嵌入、建立索引——都已成功完成。
return "embedding and index succeed!";
}接下来是/chat部分,该部分实现了RAG(检索 -> 增强 -> 生成)的简单的全流程。
这个 queryVector 方法是整个RAG应用的“工作引擎”,它按顺序执行了以下操作:
-
接收问题: 从用户请求中获取问题字符串。
-
信息检索: 将问题向量化,并在向量数据库中找到最相关的k条上下文信息。
-
信息增强: 将检索到的上下文和原始问题组合成一个精心设计的、给LLM的“考试卷”(Prompt)。
-
答案生成: 将“考试卷”交给LLM这个“考生”,让它根据提供的材料写出答案。
-
结果呈现: 将找到的“参考资料”和最终的“答案”一起清晰地展示给用户。
/**
* @GetMapping 将HTTP GET请求的路径 "/chat" 映射到此方法。
* 这是RAG应用的核心问答接口。
*
* @param query @RequestParam注解用于从URL的查询参数中获取值。
* 例如,请求 "http://.../chat?message=你好" 时,'query'变量的值将是 "你好"。
* `defaultValue` 提供了一个默认值,如果请求中没有'message'参数,'query'将是 "简单介绍一下openGauss"。
*
* @return 返回一个包含检索到的上下文和LLM最终回答的、格式化好的纯文本字符串。
* `produces = "text/plain;charset=UTF-8"` 确保了响应是纯文本且中文不会乱码。
*/
@GetMapping(value = "/chat", produces = "text/plain;charset=UTF-8")
public String queryVector(@RequestParam(value = "message", defaultValue = "简单介绍一下openGauss") String query)
{
// 使用 try-catch 块来捕获整个处理流程中可能出现的任何异常,保证程序的健壮性。
try {
// --- 准备阶段:设置参数 ---
int topK = 2; // 定义要从知识库中检索出的最相关文档的数量。
int maxPromptLen = 1000; // 定义最终构建给大语言模型的Prompt的最大长度,防止超长。
// --- RAG第一步:检索 (Retrieve) ---
// 调用业务层(RagService)的方法,执行向量相似度搜索。
// 1. `QueryContent`方法内部会将用户的'query'文本转换成一个查询向量。
// 2. 然后使用这个向量去数据库中,利用HNSW索引查找最相似的'topK'条记录。
// 3. 返回这些记录的原始内容,由换行符'\n'拼接。
String contentResult = ragService.QueryContent(2, query, topK); // '2'可能是表ID或其他标识符
// 将返回的字符串按换行符分割,转换成一个列表,方便后续处理。
List<String> contentList = Arrays.asList(contentResult.split("\n"));
// --- RAG第二步:增强 (Augment) ---
// 调用业务层的方法,将检索到的上下文信息和用户的原始问题组合成一个结构化的Prompt。
// 一个好的Prompt能极大地提升LLM回答的准确性和相关性。
String generatePrompt = ragService.BuildRagPrompt(query, contentList, maxPromptLen);
// 在服务器控制台打印出最终生成的Prompt,这是非常关键的调试步骤。
// 通过观察这个Prompt,可以判断检索到的内容是否相关,以及Prompt的指令是否清晰。
System.out.println("prompt:");
System.out.println(generatePrompt);
// --- RAG第三步:生成 (Generate) ---
// 调用一个私有辅助方法,该方法负责与Ollama的大语言模型(Chat Model)进行交互。
// 它将上面构建好的`generatePrompt`发送给LLM。
String modelResponse = getModelResponse(generatePrompt);
// --- 结果整合与返回 ---
// 使用StringBuilder高效地构建最终要返回给用户的字符串。
StringBuilder response = new StringBuilder();
// 首先,展示我们找到了哪些相关内容作为回答的依据,增加透明度和可信度。
response.append("已找到相关内容:\n\n");
for (String content : contentList) {
response.append("- ").append(content).append("\n");
}
// 然后,用一段引导语,清晰地将上下文和最终答案联系起来。
response.append("\n根据以上信息,您的问题\"").append(query).append("\"的回答是:\n");
// 最后,附上LLM生成的最终答案。
response.append(modelResponse);
// 将StringBuilder的内容转换成字符串并返回。
return response.toString();
} catch (Exception e) {
// 如果在上述任何步骤中发生异常,在此处捕获。
e.printStackTrace(); // 在服务器控制台打印详细的错误堆栈,用于开发者调试。
return "处理查询时出现错误: " + e.getMessage(); // 向用户返回一个友好的错误提示。
}
}Service层代码
RagServiceImpl 类实现了一系列方法,用于驱动一个完整的RAG(检索增强生成)流程。RagServiceImpl 类通过一系列方法驱动了整个RAG流程:首先,它定义了一个核心的getEmbedding方法,该方法通过RestTemplate调用Ollama API将任意文本转换为向量;在数据索引时,它依次调用Repository层来创建表、利用getEmbedding向量化文本并插入数据、最后建立向量索引;在处理用户查询时,它再次使用getEmbedding将问题向量化,然后调用Repository进行相似度搜索以检索相关内容,并最终通过BuildRagPrompt方法将这些内容与原始问题组合成一个结构化的、准备喂给大语言模型的最终Prompt。
/**
* @Service 注解告诉Spring容器,这个类是一个业务逻辑组件(Service Bean)。
* Spring会创建这个类的实例,并管理其生命周期。
*
* RagServiceImpl 是 RagService 接口的具体实现,它封装了RAG应用所有的核心业务逻辑,
* 包括与外部AI服务(Ollama)的交互和与数据访问层(Repository)的协作。
*/
@Service
public class RagServiceImpl implements RagService {
// --- 依赖注入 ---
// 使用final关键字确保依赖在构造后不可变,这是一个好习惯。
private final Repository repository; // 数据访问层接口,负责与数据库交互。
private final RestTemplate restTemplate; // Spring提供的HTTP客户端,用于调用外部API。
private final OllamaConfig ollamaConfig; // 自定义的配置类,持有Ollama相关的配置信息。
// ObjectMapper用于JSON的序列化和反序列化。建议也通过@Bean的方式注入以实现共享。
private final ObjectMapper objectMapper = new ObjectMapper();
/**
* @Value 注解从application.properties文件中注入单个配置项的值。
* 这里它将'ollama.modelDim'的值赋给vectorDim字段。
* 这个字段用于在创建数据库表时指定向量的维度。
*/
@Value("${ollama.modelDim}")
private int vectorDim;
/**
* 使用构造函数注入是Spring推荐的最佳实践。
* 它能保证所有必要的依赖在对象创建时都已准备就绪,避免了字段为null的风险。
* @param repository 数据访问仓库
* @param restTemplate HTTP请求工具
* @param ollamaConfig Ollama配置
*/
public RagServiceImpl(Repository repository, RestTemplate restTemplate, OllamaConfig ollamaConfig) {
this.repository = repository;
this.restTemplate = restTemplate;
this.ollamaConfig = ollamaConfig;
}
/**
* 获取文本的嵌入向量。
* 这是一个核心的AI交互方法,负责将任意文本字符串转换为其数学表示(向量)。
* @param message 需要被向量化的文本。
* @return 代表文本语义的浮点数数组。
*/
@Override
public float[] getEmbedding(String message) {
try {
// 1. 准备请求体 (Request Body)
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("model", ollamaConfig.getEmbeddingModel()); // 使用配置中指定的Embedding模型
requestBody.put("prompt", message);
// 2. 设置请求头 (Request Headers)
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON); // 声明我们发送的是JSON数据
// 3. 创建请求实体 (HttpEntity),封装请求头和请求体
HttpEntity<Map<String, Object>> requestEntity = new HttpEntity<>(requestBody, headers);
// 4. 发送HTTP POST请求到Ollama的Embedding API
String response = restTemplate.postForObject(
ollamaConfig.getEmbeddingUrl(),
requestEntity,
String.class
);
// 5. 解析Ollama返回的JSON响应
JsonNode rootNode = objectMapper.readTree(response);
JsonNode embeddingNode = rootNode.path("embedding");
// 健壮性检查,确保响应格式正确
if (embeddingNode == null || !embeddingNode.isArray()) {
throw new RuntimeException("无效的嵌入向量响应格式");
}
// 6. 将JSON数组转换为Java的float[]数组
float[] embedding = new float[embeddingNode.size()];
for (int i = 0; i < embeddingNode.size(); i++) {
embedding[i] = (float) embeddingNode.get(i).asDouble();
}
return embedding;
} catch (JsonProcessingException e) {
// 更具体的异常处理,针对JSON解析失败
throw new RuntimeException("解析嵌入向量响应失败: " + e.getMessage());
} catch (Exception e) {
// 捕获所有其他异常,如网络错误
e.printStackTrace();
throw new RuntimeException("获取嵌入向量失败: " + e.getMessage());
}
}
/**
* 创建用于存储文本和向量的数据库表。
* 这是一个简单的委托调用,将具体实现交给Repository层。
*/
@Override
public void CreateTxtTable() {
// 使用从配置中注入的vectorDim来动态创建表结构
repository.CreateTable(vectorDim);
}
/**
* 将单条文本数据向量化后存入数据库。
* @param id 文本的唯一标识符。
* @param message 待处理的文本内容。
*/
@Override
public void InsertTuples(int id, String message) {
// 1. 调用getEmbedding方法将文本转换为向量
float[] res = getEmbedding(message);
// 2. 将id、原始文本和向量字符串(通过Arrays.toString转换)委托给Repository层进行插入
repository.InsertDataSingle(id, message, Arrays.toString(res));
}
/**
* 在向量列上创建索引以加速查询。
* 同样是一个委托调用。
*/
@Override
public void IndexTxt() {
repository.CreateIndex();
}
/**
* 执行RAG的检索步骤:根据用户查询找到最相关的内容。
* @param efsearch HNSW索引的查询时参数,用于平衡速度和精度。
* @param query 用户的原始查询问题。
* @param topK 需要检索的最相关文档数量。
* @return 一个由换行符拼接的、包含topK个相关内容的字符串。
*/
@Override
public String QueryContent(int efsearch, String query, int topK) {
// 1. 将用户的查询问题向量化
float[] res = getEmbedding(query);
// 2. 将查询向量委托给Repository层,执行向量相似度搜索
return repository.findNearestVectors(efsearch, Arrays.toString(res), topK);
}
/**
* 构建用于喂给大语言模型的、增强后的Prompt。
* @param query 用户的原始问题。
* @param relatedContents 从数据库检索到的相关内容列表。
* @param maxLength Prompt的最大长度限制。
* @return 格式化好的、包含上下文和问题的最终Prompt字符串。
*/
@Override
public String BuildRagPrompt(String query, List<String> relatedContents, int maxLength) {
List<String> selectedTexts = new ArrayList<>();
int totalLen = 0;
// 智能截断逻辑:按相关性顺序添加内容,直到接近最大长度
for (String content : relatedContents) {
if (totalLen + content.length() < maxLength) {
selectedTexts.add(content);
totalLen += content.length();
} else {
break;
}
}
// 使用String.format和预定义的模板构建结构化的Prompt
return String.format("根据以下信息用中文简洁回答:\n%s\n问题:%s\n答案:",
String.join("\n", selectedTexts),
query);
}
}Repository层
本层主要处理和向量数据库交互的部分,用于向量数据库中增删改查等功能,具体实现如下:
/**
* @Component 注解将这个类声明为一个Spring Bean,使其可以被Spring容器管理和注入。
* 对于数据访问层,使用 @Repository 注解是更好的实践,因为它在语义上更清晰,
* 并且能让Spring的异常转换代理生效(将特定的数据库异常转换为Spring统一的数据访问异常)。
*
* 这个类是数据访问层(DAO/Repository),专门负责与数据库进行所有直接的交互。
* 它封装了所有底层的JDBC和SQL代码,为上层(Service层)提供清晰、简单的接口。
*/
@Component
public class Repository {
// Connection对象作为类成员变量。注意:这种设计在多线程环境下不是线程安全的。
// 在Spring应用中,更推荐的做法是在每个方法内部获取和关闭连接,或者使用JdbcTemplate。
private Connection conn;
// 注入自定义的数据库配置和连接获取类。
@Autowired
private OpgsConfig opgsConfig;
/**
* 创建并清空用于存储文本和向量的数据库表。
* 这是一个幂等操作,可以被安全地重复调用。
* @param dim 向量的维度,用于在CREATE TABLE语句中定义VECTOR列的长度。
*/
public void CreateTable(int dim) {
try {
// 从配置类获取一个新的数据库连接。
conn = opgsConfig.getConnection();
// 第一步:创建表(如果它还不存在)。
// "IF NOT EXISTS" 子句可以防止在表已存在时执行此命令报错。
String createTableSql = "CREATE TABLE IF NOT EXISTS txt_table (" +
"id INTEGER PRIMARY KEY, " +
"content TEXT, " +
"vector VECTOR(" + dim + "))"; // 动态指定向量维度
// 使用 try-with-resources 语句确保PreparedStatement在使用后被自动关闭,防止资源泄漏。
try (PreparedStatement statement = conn.prepareStatement(createTableSql)) {
statement.execute(); // 执行DDL(数据定义语言)语句。
}
// 第二步:清空表中的所有旧数据,为本次运行做准备。
// TRUNCATE TABLE 比 DELETE FROM TABLE 速度更快,因为它不记录行删除日志,直接释放数据页。
String truncateTableSql = "TRUNCATE TABLE txt_table";
try (PreparedStatement statement = conn.prepareStatement(truncateTableSql)) {
statement.execute();
System.out.println("数据表已清空,准备插入新数据。");
}
} catch (SQLException e) {
// 捕获所有SQL相关的异常。
e.printStackTrace(); // 在控制台打印详细错误,用于调试。
throw new RuntimeException("创建或清空表失败: " + e.getMessage()); // 向上层抛出运行时异常。
} finally {
// finally块确保无论是否发生异常,这个代码块都会被执行。
closeConnection(); // 调用辅助方法关闭数据库连接,释放资源。
}
}
/**
* 在vector列上创建HNSW索引,以极大地加速向量相似度搜索。
*/
public void CreateIndex() {
try {
conn = opgsConfig.getConnection();
// "vector_l2_ops" 指定了索引使用的距离度量函数为L2距离(欧氏距离)。
String createIndexSql = "CREATE INDEX IF NOT EXISTS vector_index ON txt_table USING HNSW(vector vector_l2_ops)";
try (PreparedStatement statement = conn.prepareStatement(createIndexSql)) {
statement.execute();
System.out.println("向量索引创建成功!");
}
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException("创建索引失败: " + e.getMessage());
} finally {
closeConnection();
}
}
/**
* 向数据库中插入单条记录,包含ID、原始文本和其向量表示。
* @param id 记录的唯一ID。
* @param content 原始文本内容。
* @param vector 文本的向量表示,格式为 "[f1, f2, ...]" 的字符串。
*/
public void InsertDataSingle(int id, String content, String vector) {
try {
conn = opgsConfig.getConnection();
// "?::vector" 是pgvector的特定语法,告诉PostgreSQL将传入的第三个字符串参数显式转换为vector类型。
String insertSql = "INSERT INTO txt_table (id, content, vector) VALUES (?, ?, ?::vector)";
try (PreparedStatement statement = conn.prepareStatement(insertSql)) {
// 使用PreparedStatement的setter方法为占位符'?'安全地设置参数,可以防止SQL注入。
statement.setInt(1, id);
statement.setString(2, content);
statement.setString(3, vector);
statement.executeUpdate(); // 执行DML(数据操作语言)语句,返回受影响的行数。
}
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException("插入数据失败: " + e.getMessage());
} finally {
closeConnection();
}
}
/**
* 在数据库中执行向量相似度搜索,找出与给定向量最相似的topK条记录。
* @param efsearch HNSW索引的查询时参数,用于在速度和精度之间做权衡。
* @param vector 查询向量,格式为 "[f1, f2, ...]" 的字符串。
* @param topK 需要返回的最相似记录的数量。
* @return 一个由换行符拼接的、包含topK个相关文本内容的字符串。
*/
public String findNearestVectors(int efsearch, String vector, int topK) {
try {
conn = opgsConfig.getConnection();
// 第一步:为当前数据库会话设置HNSW索引的查询参数。
// 这个设置只对当前连接(conn)生效,不会影响其他并发的连接。
try (Statement stmt = conn.createStatement()) {
// 注意:这里是直接拼接字符串,因为efsearch是整数,没有SQL注入风险。
// SET命令不支持PreparedStatement的占位符。
stmt.execute("SET hnsw.ef_search = " + efsearch);
}
// 第二步:执行核心的相似度搜索查询。
// "<->" 是pgvector提供的L2距离操作符。ORDER BY ... 会根据距离升序排序。
String querySql = "SELECT content FROM txt_table ORDER BY vector <-> ?::vector LIMIT ?";
try (PreparedStatement queryStatement = conn.prepareStatement(querySql)) {
queryStatement.setString(1, vector);
queryStatement.setInt(2, topK);
// 执行查询并获取结果集。
ResultSet rs = queryStatement.executeQuery();
List<String> contents = new ArrayList<>();
// 遍历结果集,逐行读取'content'列的数据。
while (rs.next()) {
contents.add(rs.getString("content"));
}
// 使用String.join将列表中的所有内容用换行符连接成一个单一的字符串。
return String.join("\n", contents);
}
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException("查询向量失败: " + e.getMessage());
} finally {
closeConnection();
}
}
/**
* 一个私有的辅助方法,用于关闭数据库连接。
* 进行了null检查,确保在连接对象本身为null时不会抛出NullPointerException。
*/
private void closeConnection() {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}三.效果和总结
效果演示
首先请求localhost:8088中的/index,得到如下效果,此时硬编码的几行文字作为知识库嵌入到向量数据库中。
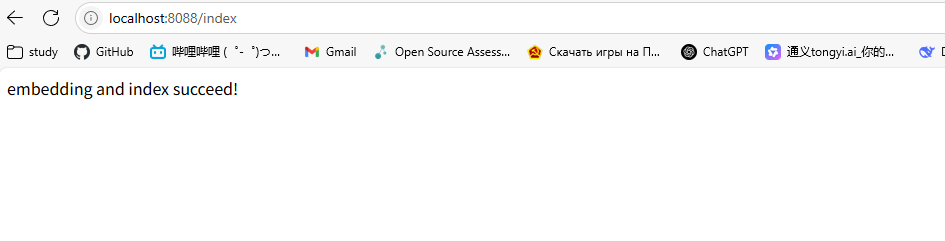
在向量数据库中可以查到对应的数据如下:

之后访问localhost:8088端口的/chat?message=你的问题,可以看到已经成功调用模型根据知识库中查询到的前两条数据进行回答。这里知识库中的数据和问题没关系,故大模型还是根据自己的知识进行回答。至此该demo完成!

总结
本文现阶段只简单地根据官方文档的脚手架进行填充,得到了一个简单的RAG应用Demo。实际的RAG应用中许多细节的地方并没有处理,后续将对项目进行进一步重构和扩充,已实现一个真正的可以应用的项目。欢迎交流!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)