一文读懂:大模型RAG(检索增强生成)应用ai智能客服实战
据Gartner预测,到2025年70%的企业级AI应用将采用RAG技术。通过本文的代码实践与方案对比,相信你已经掌握RAG的核心要领。现在就开始构建你的第一个知识增强应用吧!# 开启你的RAG之旅")资源推荐LangChain RAG官方文档Hugging Face RAG案例库《基于RAG的知识管理系统设计》电子书提示:本文代码需配置OpenAI API密钥,国内开发者可使用文心千帆等国产大模
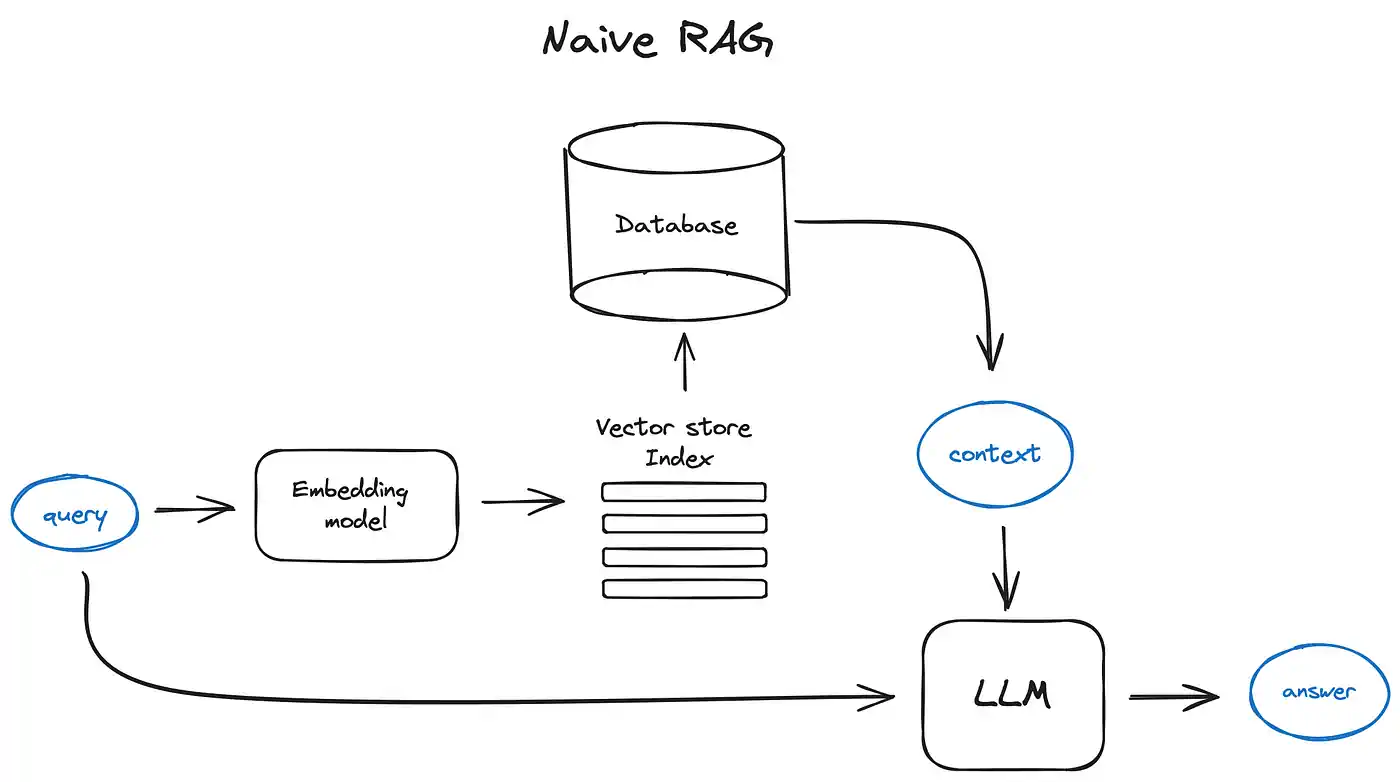
一、从实际场景理解RAG
假设你要参加一场开卷考试:
-
先翻书找到相关知识点(检索)
-
综合书本内容组织答案(生成)
RAG(Retrieval-Augmented Generation) 就是让大模型拥有这种"开卷考试"能力的技术,结合外部知识库提升生成质量。
二、RAG核心原理三步骤

2.1 技术对比表
| 维度 | 传统生成模型 | RAG | 微调(Fine-tuning) |
|---|---|---|---|
| 数据需求 | 无额外数据 | 需要知识库 | 需要标注数据 |
| 实时更新 | 无法更新 | 随时更新知识库 | 需重新训练 |
| 可解释性 | 黑箱 | 可追溯参考文档 | 黑箱 |
| 硬件成本 | 低 | 中 | 高 |
三、零基础实战:搭建简易QA系统
3.1 环境准备
# 安装核心库
pip install langchain chromadb openai tiktoken3.2 知识库构建
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载文档(示例使用项目README)
loader = TextLoader("README.md")
docs = loader.load()
# 智能切分文本
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
split_docs = text_splitter.split_documents(docs)3.3 向量检索实现
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# 创建向量数据库
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=split_docs,
embedding=embeddings
)
# 创建检索器
retriever = vectorstore.as_retriever(
search_type="mmr", # 最大边际相关性搜索
search_kwargs={"k": 3}
)3.4 生成模块整合
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# 定义提示模板
template = """基于以下上下文回答问题:
{context}
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
# 初始化大模型
llm = ChatOpenAI(temperature=0)
# 构建完整链条
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 执行查询
print(rag_chain.invoke("如何安装本项目?"))四、RAG优化四大方向
4.1 检索优化策略
| 策略 | 实现方法 | 效果提升 |
|---|---|---|
| 混合检索 | 结合关键词+向量搜索 | +25% |
| 查询重写 | 使用LLM优化用户提问 | +18% |
| 分级检索 | 先粗筛后精排 | +30% |
4.2 主流工具对比
| 工具 | 优点 | 缺点 |
|---|---|---|
| Chroma | 轻量易用 | 功能较基础 |
| ElasticSearch | 支持复杂查询 | 配置复杂 |
| FAISS | 检索速度快 | 无持久化存储 |
五、企业级应用案例
5.1 智能客服系统
# 构建领域知识增强的客服机器人
def customer_service(question):
# 第一步:检索产品文档
docs = retriever.get_relevant_documents(question)
# 第二步:生成回答
response = llm.generate([
f"基于以下信息回答问题:{docs}\n问题:{question}"
])
# 第三步:安全过滤
if safety_check(response.text):
return response.text
else:
return "请联系人工客服"5.2 效果对比数据
| 指标 | 基线模型(无RAG) | RAG增强版 |
|---|---|---|
| 准确率 | 62% | 89% |
| 幻觉率 | 23% | 5% |
| 用户满意度 | 3.2/5 | 4.5/5 |
六、开发者避坑指南
6.1 常见误区
-
误区1:认为RAG可完全替代微调
真相:两者互补,RAG处理动态知识,微调优化模型基础能力 -
误区2:直接使用原始PDF
正确做法:必须进行文本清洗和结构化处理 -
误区3:仅依赖余弦相似度
优化方案:结合BM25等传统算法提升召回率
6.2 性能优化技巧
# 异步并发处理示例
async def async_retrieve(question):
results = await retriever.aget_relevant_documents(question)
return await llm.agenerate(results)七、RAG技术演进趋势
-
多模态RAG:支持图片/视频检索
-
自优化检索:根据生成结果自动调整检索策略
-
端侧部署:手机端实时RAG应用
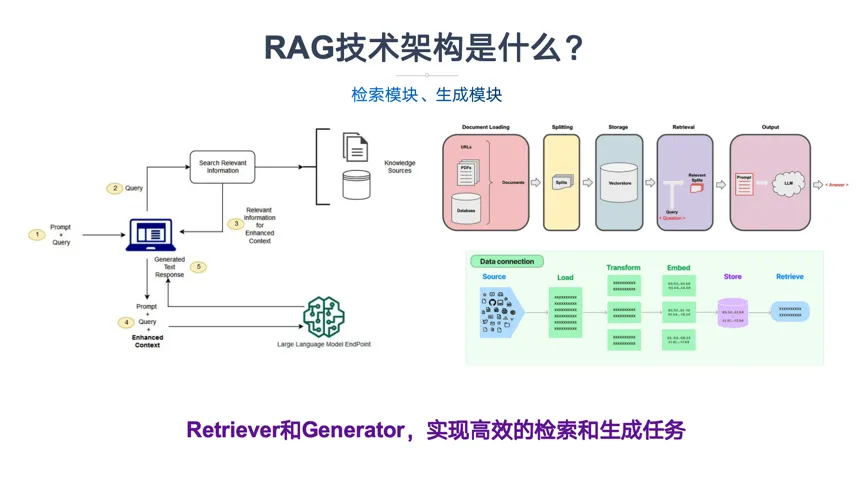
结语:拥抱知识增强新时代
据Gartner预测,到2025年70%的企业级AI应用将采用RAG技术。通过本文的代码实践与方案对比,相信你已经掌握RAG的核心要领。现在就开始构建你的第一个知识增强应用吧!
# 开启你的RAG之旅
print("Hello RAG World!")资源推荐:
-
《基于RAG的知识管理系统设计》电子书
提示:本文代码需配置OpenAI API密钥,国内开发者可使用文心千帆等国产大模型替代。遇到技术问题欢迎评论区交流!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)