锋哥写一套【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts) 视频教程,帅呆了~~
锋哥写一套【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts) 视频教程,帅呆了~~
·
大家好,我是java1234_小锋老师,最近写了一套【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts)视频教程,持续更新中,计划月底更新完,感谢支持。
视频在线地址:
2026版【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts+爬虫) 视频教程 (火爆连载更新中..)_哔哩哔哩_bilibili
课程简介:
本课程采用主流的Python技术栈实现,Mysql8数据库,Flask后端,Pandas数据分析,前端可视化图表采用echarts,以及requests库,snowNLP进行情感分析,词频统计,包括大量的数据统计及分析技巧。
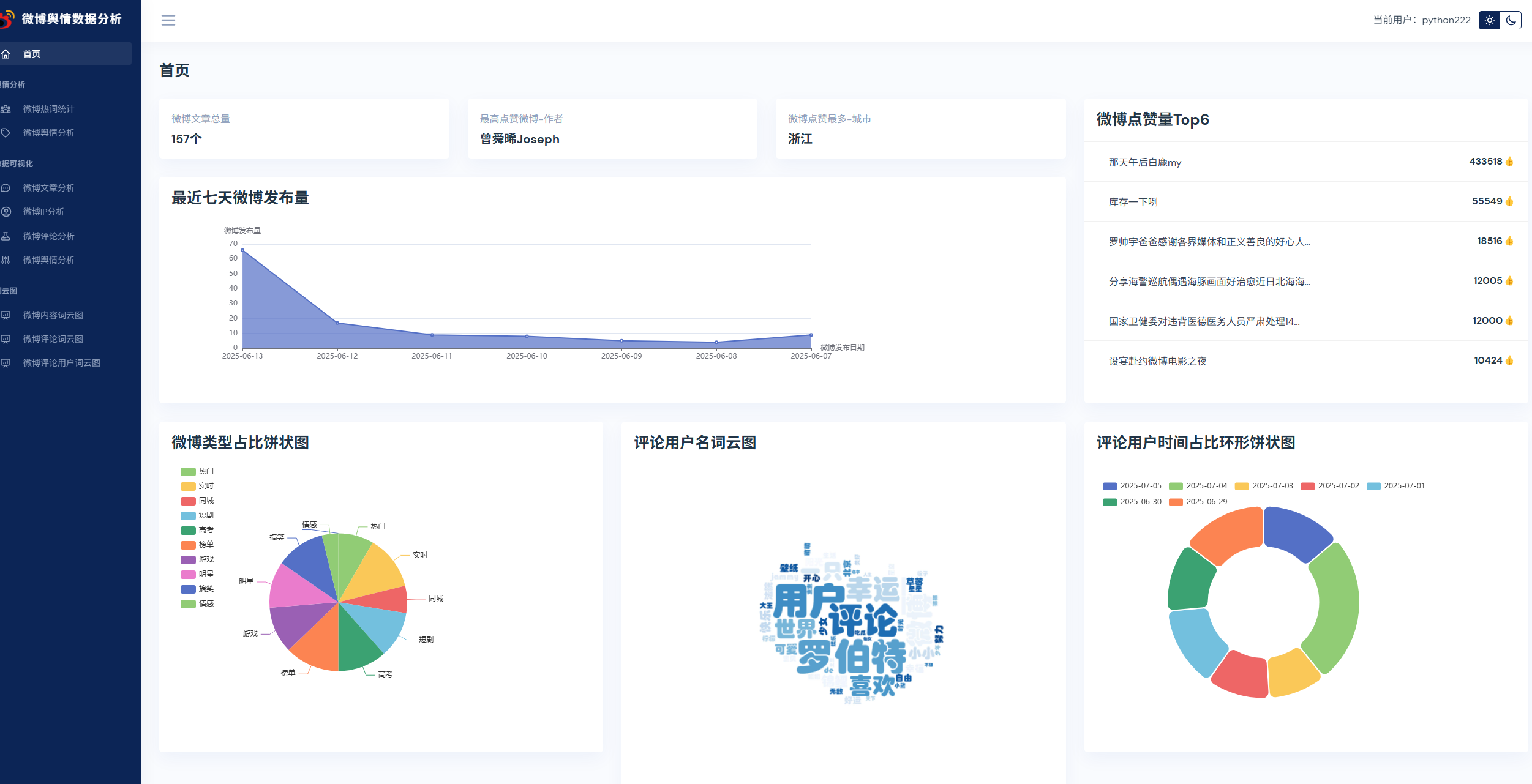
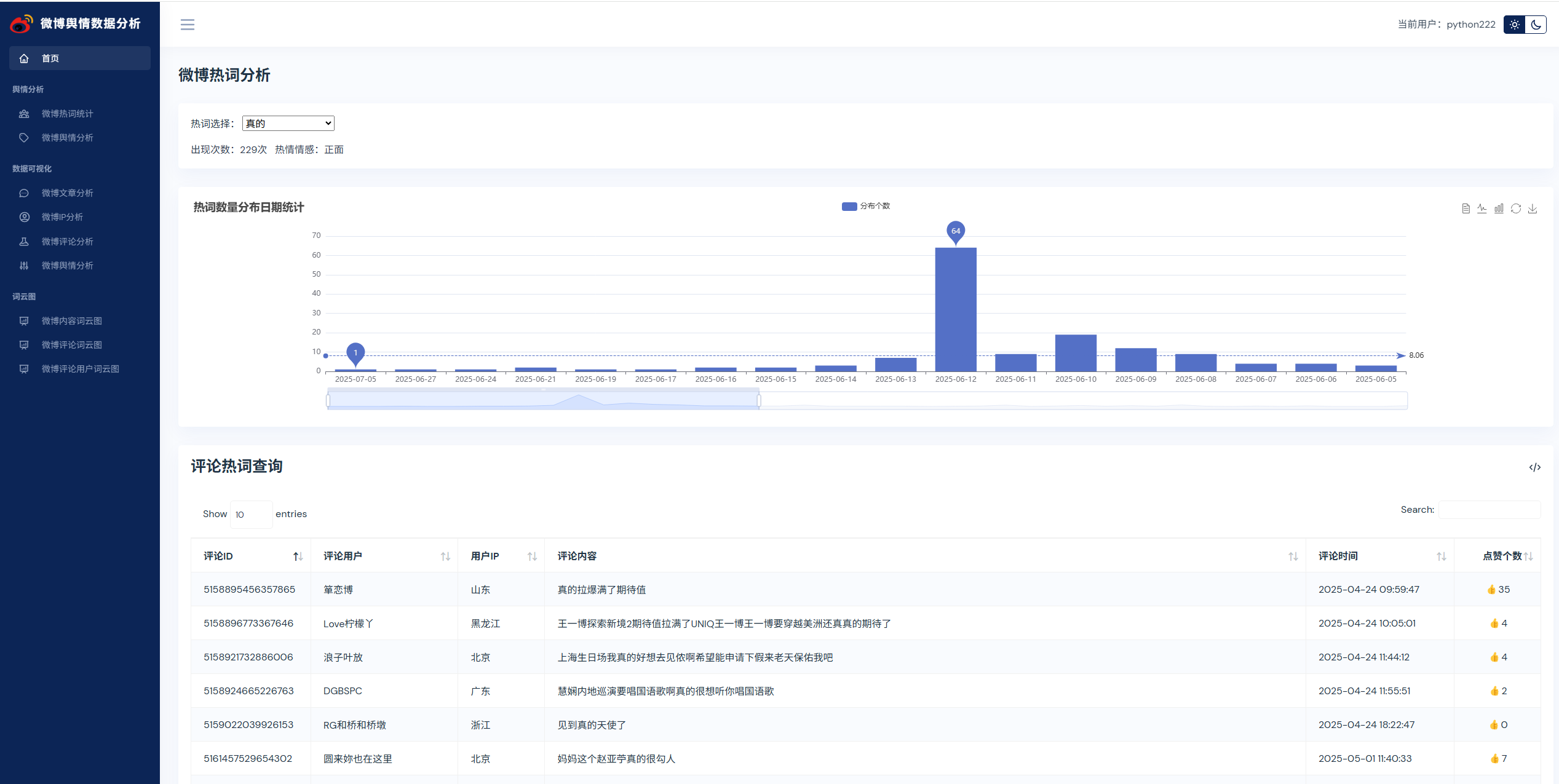
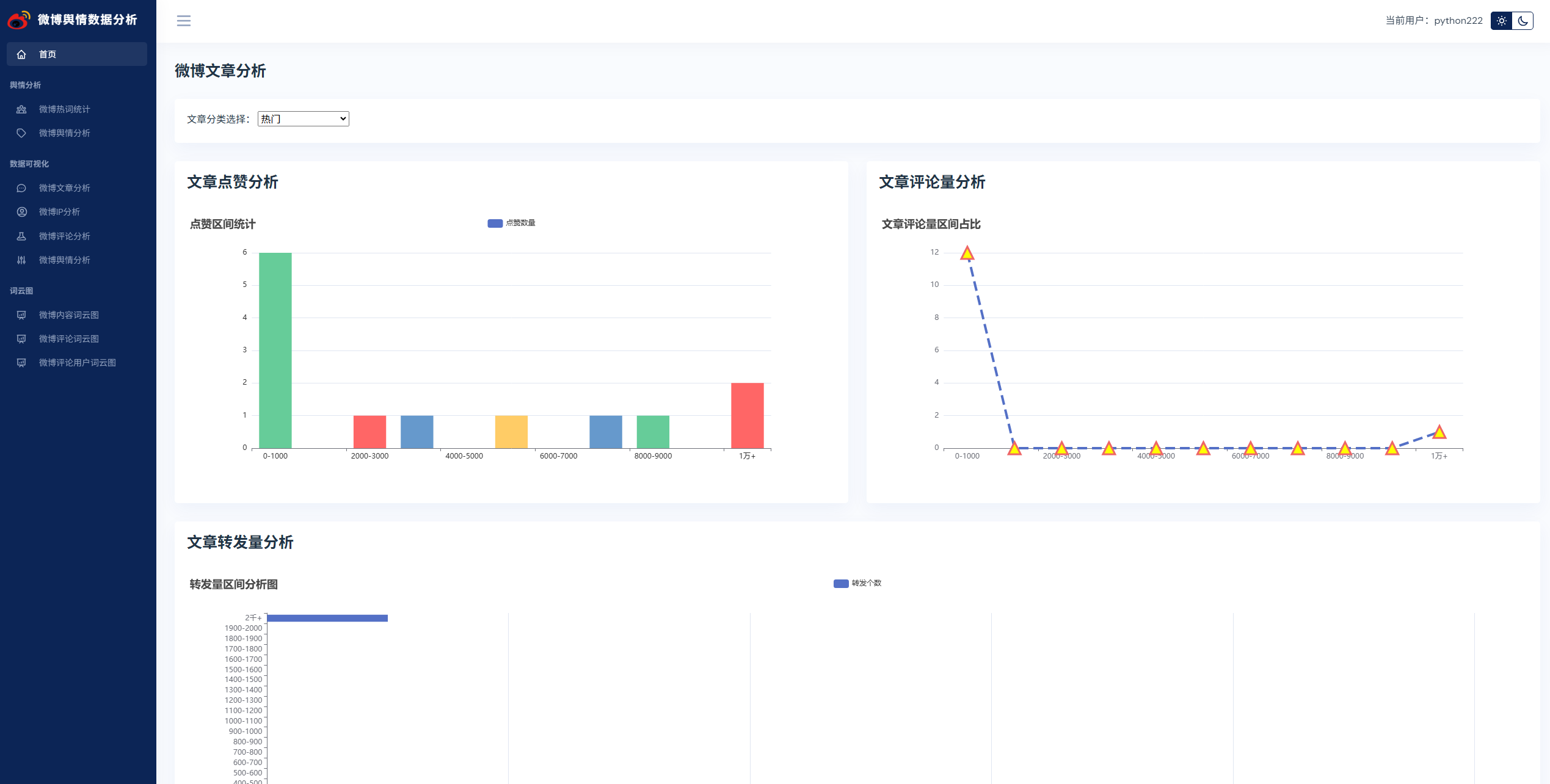
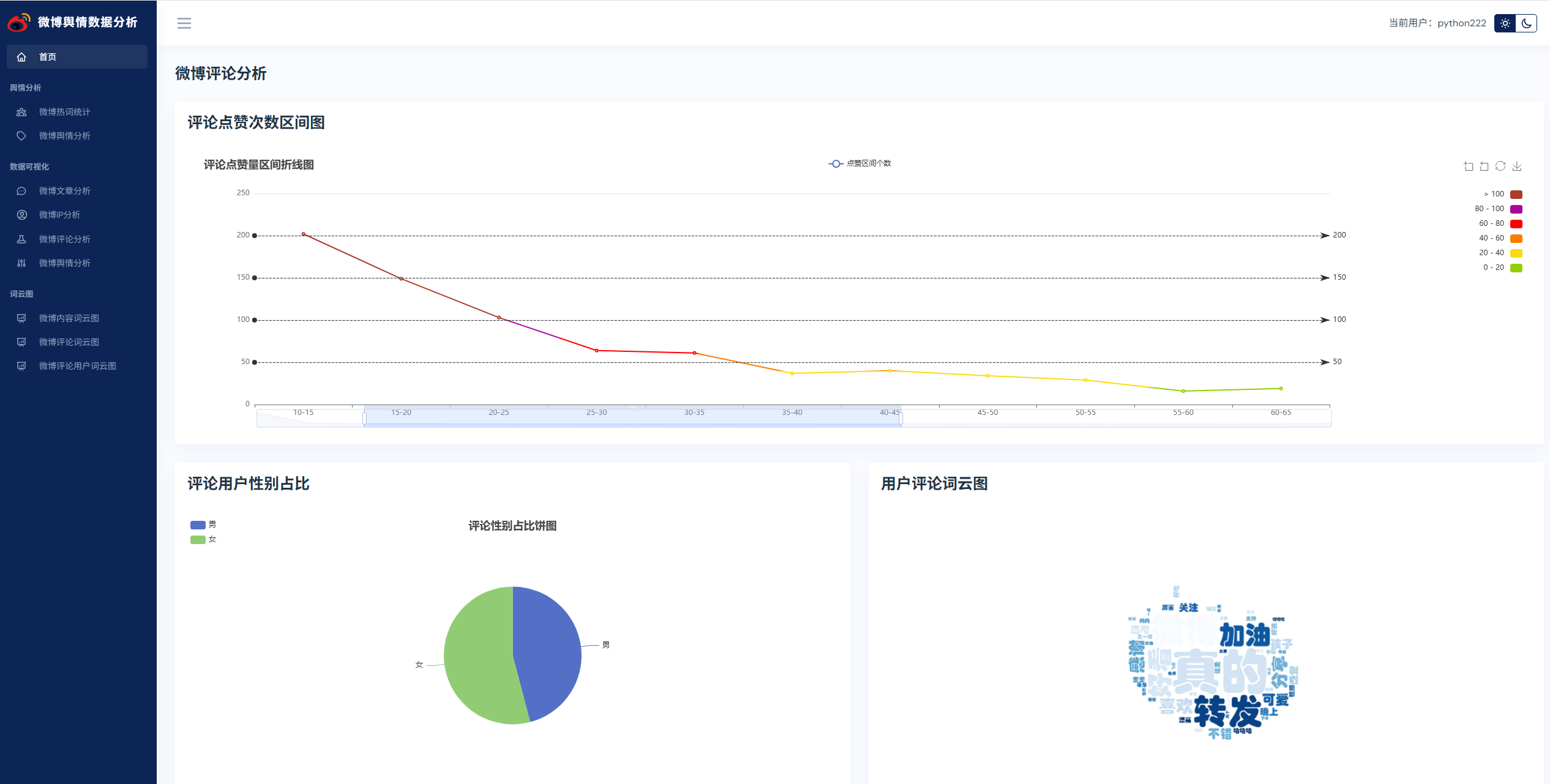
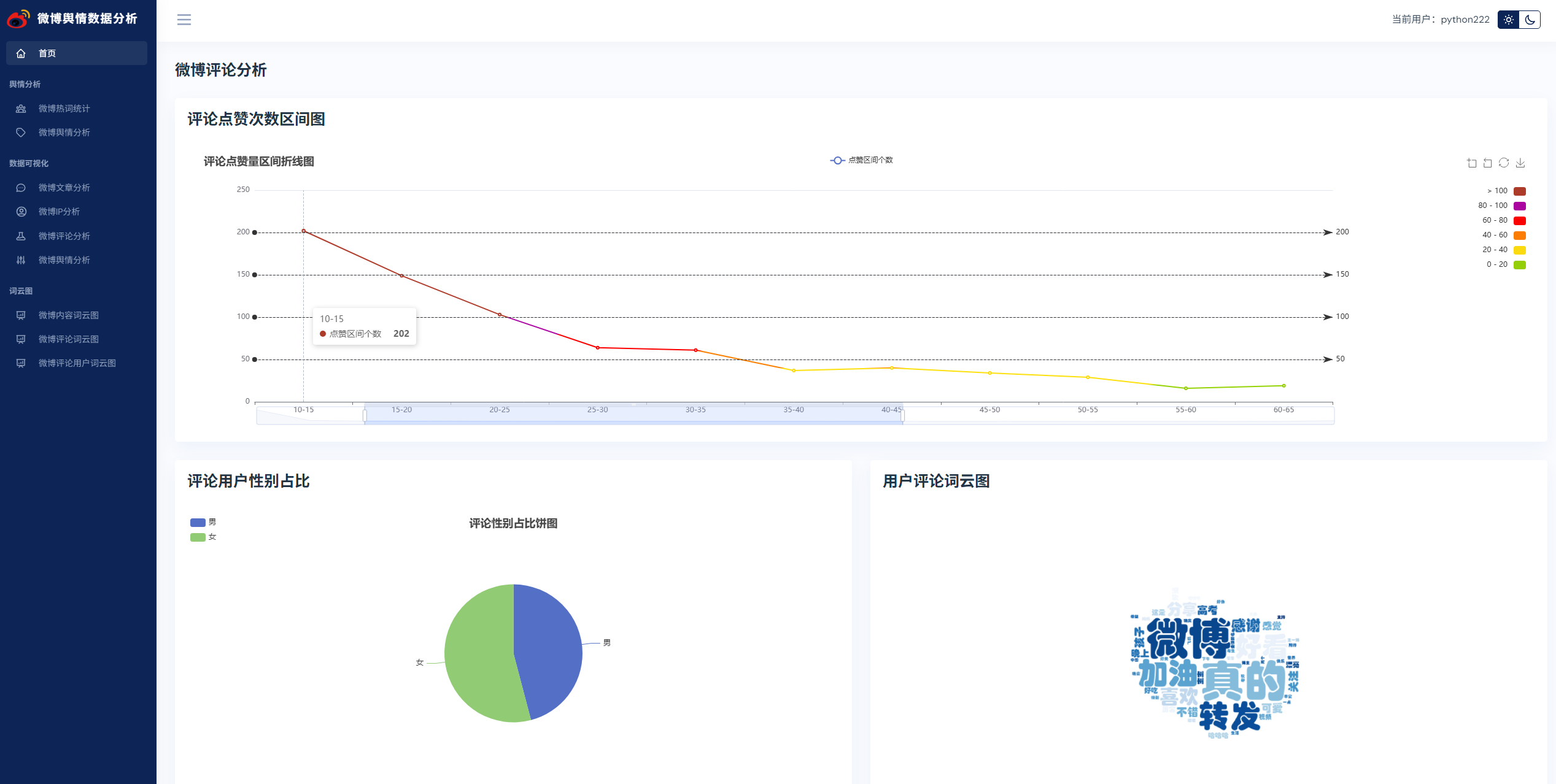
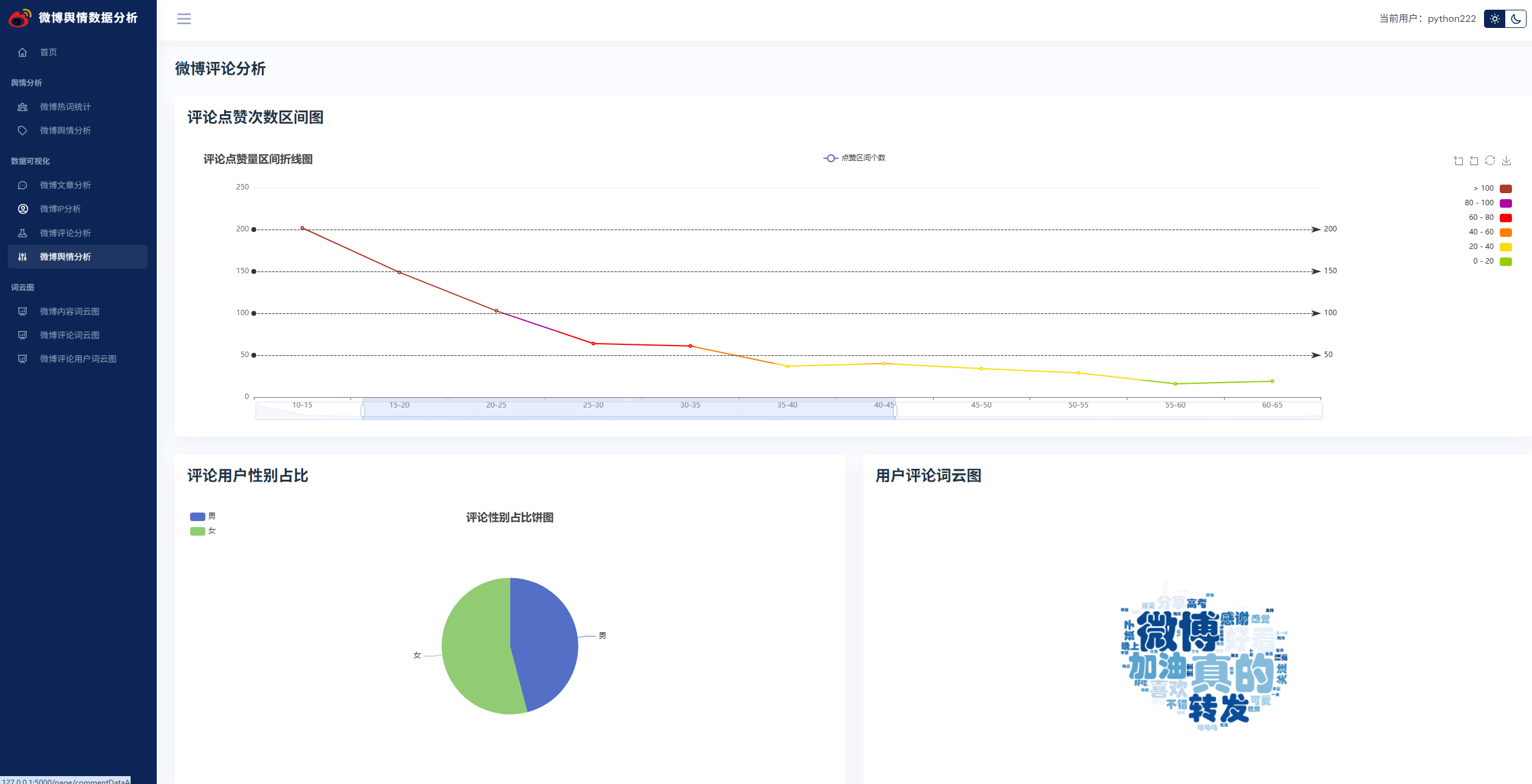
实现了,用户登录,注册,爬取微博帖子和评论信息,进行了热词统计以及舆情分析,以及基于echarts实现了数据可视化,包括微博文章分析,微博IP分析,微博评论分析,微博舆情分析。最后也基于wordcloud库实现了词云图,包括微博内容词云图,微博评论词云图,微博评论用户词云图等功能。
系统展示

演示代码
import re
import jieba
from dao import articleDao
import pandas as pd
def getStopWordsList():
"""
获取停顿词
:return:
"""
return [line.strip() for line in open('stopWords.txt', encoding='UTF-8').readlines()]
def outArticleFenciToText():
"""
分词后,写入到txt
:return:
"""
with open('article_fenci.txt', 'a+', encoding='utf-8') as file:
seg_list = cut_article(articleDao.getAllArticle())
file.write(" ".join(seg_list))
def outArticleFreToCsv(sorted_wfc_list):
"""
词频统计后,写入到txt
:return:
"""
df = pd.DataFrame(sorted_wfc_list, columns=['热词', '数量'])
df.to_csv('article_fre2.csv', index=False)
def cut_article():
"""
分词
:return:
"""
# 拼接所有评论信息
allArticleStr = " ".join([x[1].strip() for x in articleDao.getAllArticle()])
seg_list = jieba.cut(allArticleStr) # 精准模式分词
return seg_list
def word_fre_count():
"""
词频统计 过滤数字,单个字以及停顿词
:param sentence:
:return:
"""
seg_list = cut_article()
stopWord_list = getStopWordsList()
# 正则去掉数字,单个字以及停顿词
new_set_list = []
for s in seg_list:
number = re.search('\d+', s)
if not number and s not in stopWord_list and len(s) > 1:
new_set_list.append(s)
# 词频统计,定义一个列表
wfc = {}
for w in set(new_set_list):
wfc[w] = new_set_list.count(w)
sorted_wfc_list = sorted(wfc.items(), key=lambda x: x[1], reverse=True)
return sorted_wfc_list
if __name__ == '__main__':
# outArticleFenciToText()
outArticleFreToCsv(word_fre_count())
import sys
import pandas as pd
from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
from wordcloud import WordCloud
sys.path.append('fenci')
def genCloudPic(str, maskImg, outImg):
"""
生成云图
:param str: 词云 空格隔开
:param maskImg: 遮罩图片
:param outImg: 输出的词云图文件名
:return:
"""
img = Image.open('./static/' + maskImg) # 打开遮罩图片
img_arr = np.array(img) # 将图片转化为列表
wc = WordCloud(
width=800, height=600,
background_color='white',
colormap='Blues',
font_path='STHUPO.TTF',
mask=img_arr,
)
wc.generate_from_text(str)
# 绘制图片
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
# 输入词语图片到文件
plt.savefig('./static/' + outImg, dpi=500)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 87
87 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)