ScreenCoder:视觉-代码对齐新范式,为多模态程序合成开辟道路
本文提出首个模块化多智能体框架,通过三阶段分工协作,实现精准、可解释、支持交互的代码生成,同时构建数据引擎推动VLMs进化。现有基于文本的AI工具(如GPT-4)需冗长描述才能指定布局细节,而视觉语言模型(VLMs)虽可直接解析设计图,却常出现。低级指标:组件匹配(Block)、文字精度(Text)、位置对齐(Pos)、颜色一致性(Color):为每个节点生成专属提示(例:“生成一个固定在顶部的蓝
为什么需要更好的UI转代码工具?
前端开发中,将设计图转化为代码是耗时且易错的过程。现有基于文本的AI工具(如GPT-4)需冗长描述才能指定布局细节,而视觉语言模型(VLMs)虽可直接解析设计图,却常出现组件漏检(如忽略侧边栏)、布局错乱(如标题栏置于内容下方)等问题。

-
论文:ScreenCoder: Advancing Visual-to-Code Generation for Front-End Automation via Modular Multimodal Agents
-
链接:https://arxiv.org/pdf/2507.22827
ScreenCoder的诞生源于一个关键洞察:UI转代码需融合视觉理解、工程布局知识、代码生成三方面能力。传统端到端VLMs缺乏模块化设计,难以注入领域知识。本文提出首个模块化多智能体框架,通过三阶段分工协作,实现精准、可解释、支持交互的代码生成,同时构建数据引擎推动VLMs进化。
研究背景与挑战
前端自动化的价值
-
缩短开发周期(如电商页面生成从小时级降至分钟级)
-
降低非开发者参与门槛(设计师直接生成可运行原型)
现有方法的缺陷
-
文本驱动模型(如GPT-4):
-
-
需超长提示词描述组件位置/样式(例:“左侧导航栏宽度15%,主内容区右侧有卡片网格...”)
-
语言难以精确表达视觉关系(如像素级对齐、颜色渐变)。
-
-
视觉驱动模型:
-
-
漏检率高达30%(实验显示GPT-4V忽略10%的按钮)
-
布局违反基础规则(如将
footer置于页面中部) -
缺乏前端工程知识(如未使用CSS Grid响应式布局)
-
UI设计本质是视觉空间任务,需直接解析设计图而非依赖文本中转。
方法论:三阶段智能体框架
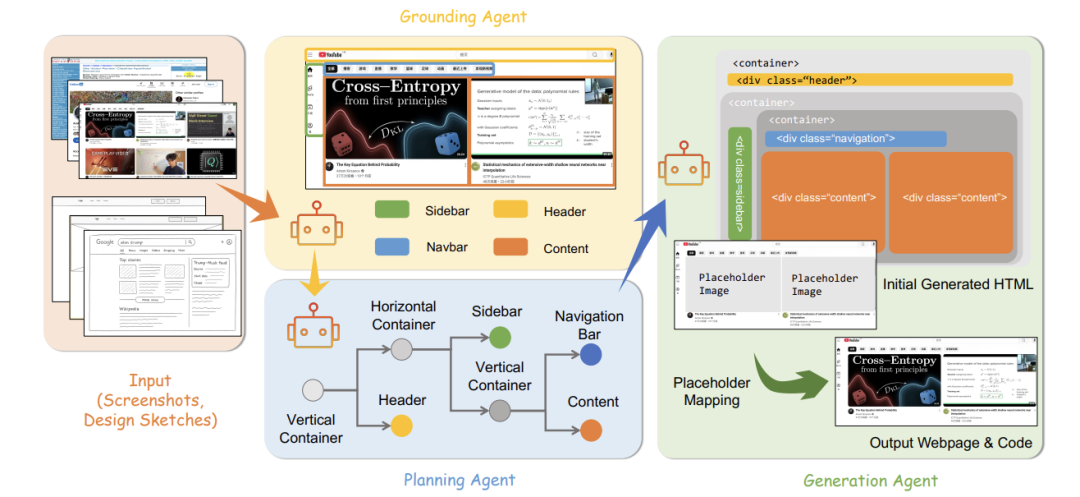
Grounding Agent:视觉组件标注
核心任务:识别图中关键区域并打语义标签(如header, sidebar)。
技术实现:
-
提示驱动VLM:用问题引导检测(例:“定位导航栏位置?”)
-
输出:带标签的边界框集合符号说明: 为像素坐标框, 为组件标签。
创新处理:
-
主内容区推断:若未检测到
main_content,取剩余最大矩形区域:意义:避免强制标注,适应多样设计布局。 -
冲突消解:对同一标签多个框,用非极大抑制(NMS)保留最置信框。
Planning Agent:布局树构建
核心任务:将标注区域组织为层级结构,反映前端工程规则。
关键技术:
-
根容器:全屏
div,设置position: relative -
CSS Grid布局:对复杂区域(如卡片网格)插入
<div class="container grid"> -
Tailwind工具类:用
grid-cols-*,gap-*等快速定义栅格
输出:树结构 ,节点含布局语义(如“侧边栏→导航列表→图标+文字”)
为何有效:将空间关系转化为工程师熟悉的层级结构,为代码生成提供蓝图。
Generation Agent:自适应代码生成
核心任务:基于布局树
和用户指令
生成HTML/CSS。
创新设计:
-
动态提示:为每个节点生成专属提示(例:“生成一个固定在顶部的蓝色导航栏,包含Logo和菜单”)
-
交互支持:用户指令 直接拼接至提示(如“ =将导航栏改为深色模式”)
-
组件级生成:按树结构组装代码,保留模块化(便于二次修改)
Placeholder Mapping:图像内容还原
问题:生成代码常将真实图片替换为灰色占位符,需手动替换。
解决方案:
-
对原图做UI元素检测(UIED),获组件框集合
-
计算占位符框 与检测框 的匹配代价:符号说明:CIoU=综合交并比(衡量框重叠度), =坐标变换矩阵。
-
用匈牙利算法实现最优一对一匹配,替换占位符为真实图片切片
价值:提升生成页面的视觉保真度,减少开发者手动调整。
数据引擎与模型优化
数据引擎流程:
-
用ScreenCoder自动生成50K图像-代码对
-
覆盖8类场景(电商/仪表盘/社交媒体等)
双阶段训练:
-
监督微调(SFT):
冷启动训练Qwen-VL模型,学习布局-代码映射。 -
强化学习(RL):
用复合奖励函数优化策略:公式解析: -
-
:组件区域匹配度( )
-
:文字相似度(Dice系数)
-
:中心点对齐度( )
作用:联合优化布局、文本、位置精度,避免模型偏科。
-
实验验证
数据集:3,000个真实UI-代码对,覆盖多类型组件与布局。
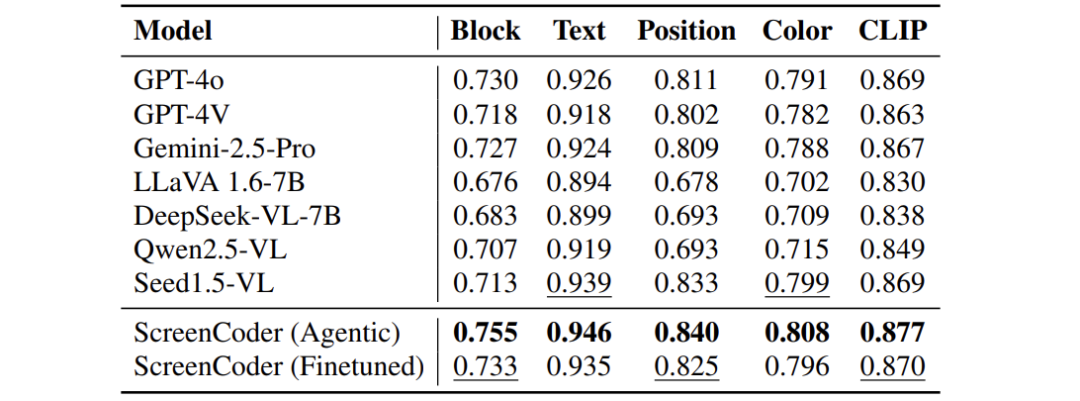
评估指标:
-
低级指标:组件匹配(Block)、文字精度(Text)、位置对齐(Pos)、颜色一致性(Color)
-
高级指标:CLIP图像相似度(掩蔽文字防作弊)
关键结论:
-
智能体协作优势:模块化设计使布局错误率降低40%
-
数据引擎价值:微调后Qwen-VL性能逼近GPT-4o
-
案例展示:
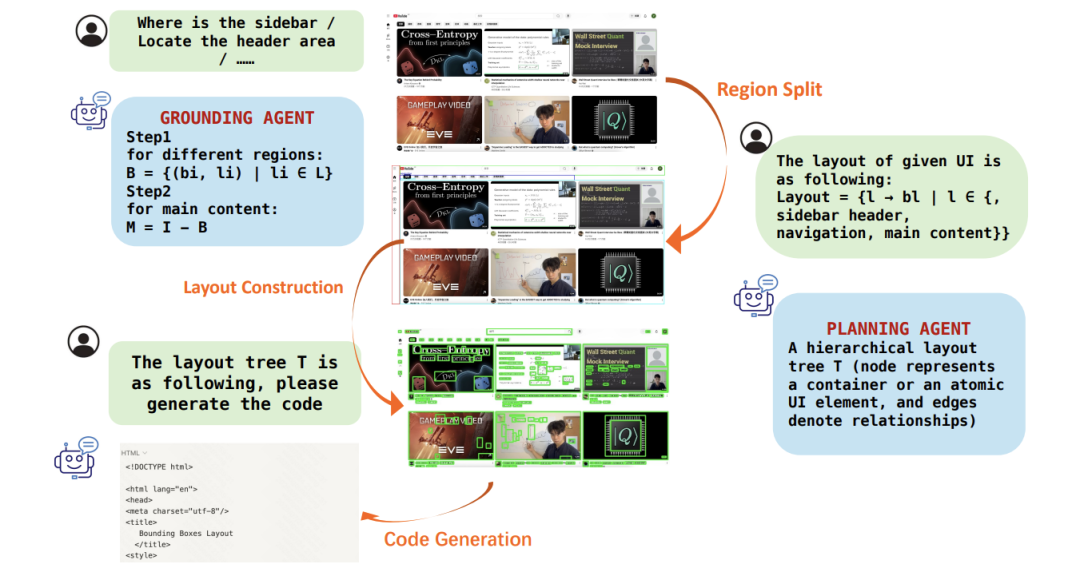
输入设计图→VLM分割→布局树→生成代码页面
结论:突破与展望
核心贡献:
-
模块化框架:三智能体分工解决视觉理解、布局规划、代码生成割裂问题。
-
数据引擎:自动生成高质量训练数据,推动VLM进化。
-
工业价值:生成代码可直接用于生产环境(实验显示减少前端70%重复劳动)。
未来方向:
-
跨平台扩展:适配移动端(iOS/Android)及游戏UI。
-
实时交互:集成IDE插件,支持“边改边生成”。
-
长页面生成:突破单屏限制,支持多页面应用。
ScreenCoder不仅是一个工具,更建立了视觉-代码对齐的新范式,为多模态程序合成开辟道路。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)