个人本地知识库最优管理方案 FastGPT 部署指南
这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。进入到模型供应商界面,选择模型渠道,点击新增渠道。但是,我查了一下,其实,config.json 文件不在根目录,而是在 projects/app/data/ 目
为什么要折腾 FastGPT 项目
- FastGPT 是一个基于大语言模型(LLM)的知识型平台,支持数据处理、RAG 检索、可视化 AI 工作流编排等功能,可以帮助你快速搭建复杂的问答系统,无需复杂配置。
- 业内推崇的是 FastGPT 的知识库解析和管理能力。非常适合作为知识库的底层,然后再和 Dify 这一类生态繁荣的 AIAgent 平台对接使用。
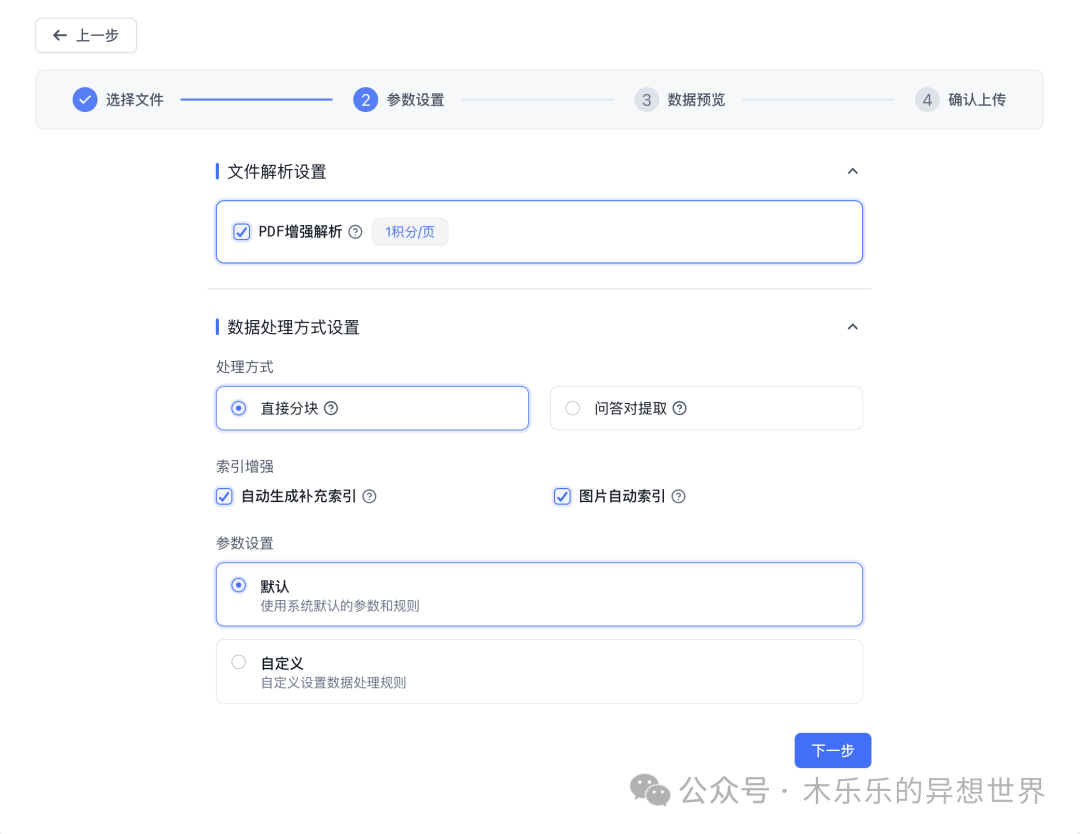
FastGPT知识库系统对导入数据的处理极为灵活,可以智能处理PDF文档的复杂结构,保留图片、表格和LaTeX公式,自动识别扫描文件,并将内容结构化为清晰的Markdown格式。同时支持图片自动标注和索引,让视觉内容可被理解和检索,确保知识在AI问答中能被完整、准确地呈现和应用。
- FastGPT 完全对齐 OpenAI 官方接口,支持一键接入企业微信、公众号、飞书、钉钉等平台,
- 参考资料:FastGPT 官方仓库 https://github.com/labring/FastGPT?tab=readme-ov-file
第二步:本地部署前的准备
- auto. 安装 Git(用于下载代码)
在终端输入:
brew install git
安装完成后,输入以下命令检查版本:
git --versio
第三步:下载 FastGPT 项目代码。
切换到你要安装 FastGPT 的文件夹目录下,然后,输入 git 指令,下载 FastGPT 项目代码。
git clone https://github.com/labring/FastGPT.git
下载docker-compose.yml文件
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml
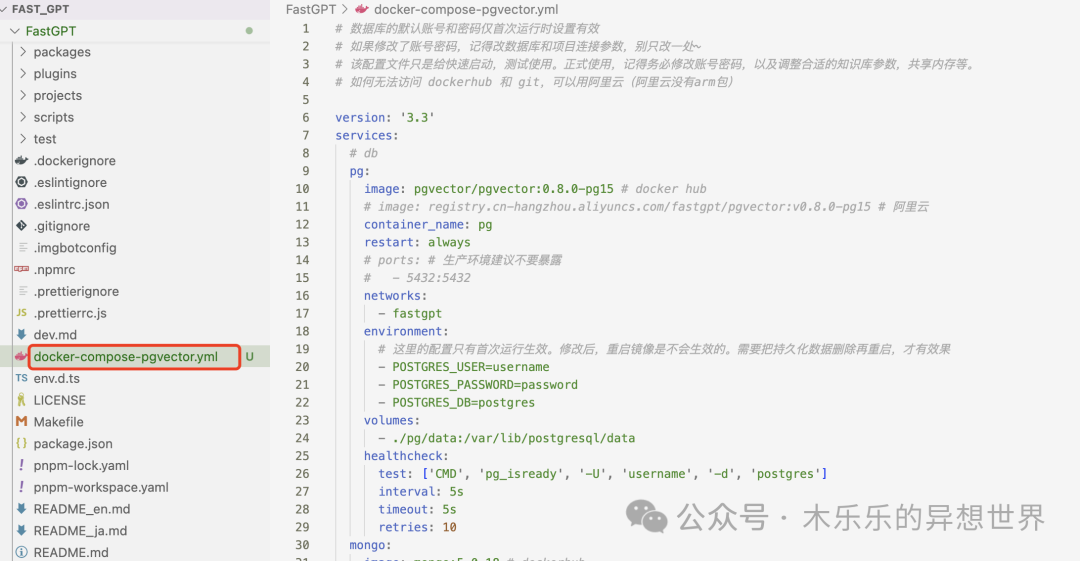
然后,在 terminal 启动 docker 安装
docker-compose -f docker-compose-pgvector.yml up -d
但是,在启动后,系统提醒,config.json 文件找不到。

Docker 在启动 fastgpt 这个服务时,需要一个叫做 config.json 的配置文件。它想把你电脑上的 config.json 文件 “挂载”到 Docker 容器内部的 /app/data/config.json 位置。
但是,我查了一下,其实,config.json 文件不在根目录,而是在 projects/app/data/ 目录下。
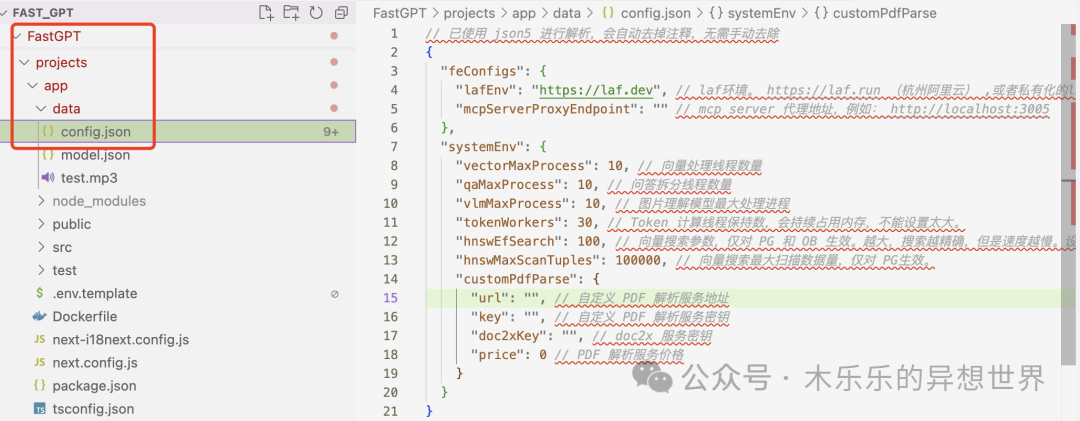
我们需要编辑 docker-compose-pgvector.yml 文件,把里面写错的路径改过来。
-
- 找到 docker-compose-pgvector.yml 文件里,找到 fastgpt: 这一段。
-
- 定位到 volumes(数据卷):在 fastgpt: 下面,找到 volumes: 这一行。
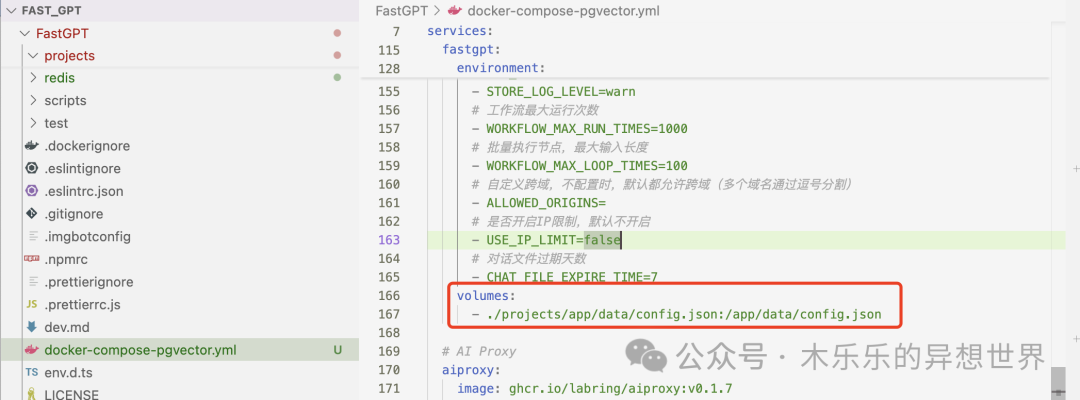
-
- 修改路径:把 - ./config.json:/app/data/config.json 这一行,修改为正确的路径:./projects/app/data/config.json。
修改内容我直接贴出来:
- ./projects/app/data/config.json:/app/data/config.json
接下来,清理旧容器(以防万一):
docker-compose -f docker-compose-pgvector.yml down
重新启动:
docker-compose -f docker-compose-pgvector.yml up -d
ok,一切顺利

终端会显示本地访问地址(通常是 http://localhost:3000 )。
默认登录用户名是: root 密码是:1234
第四步:使用和测试
1-配置 LLM 大模型
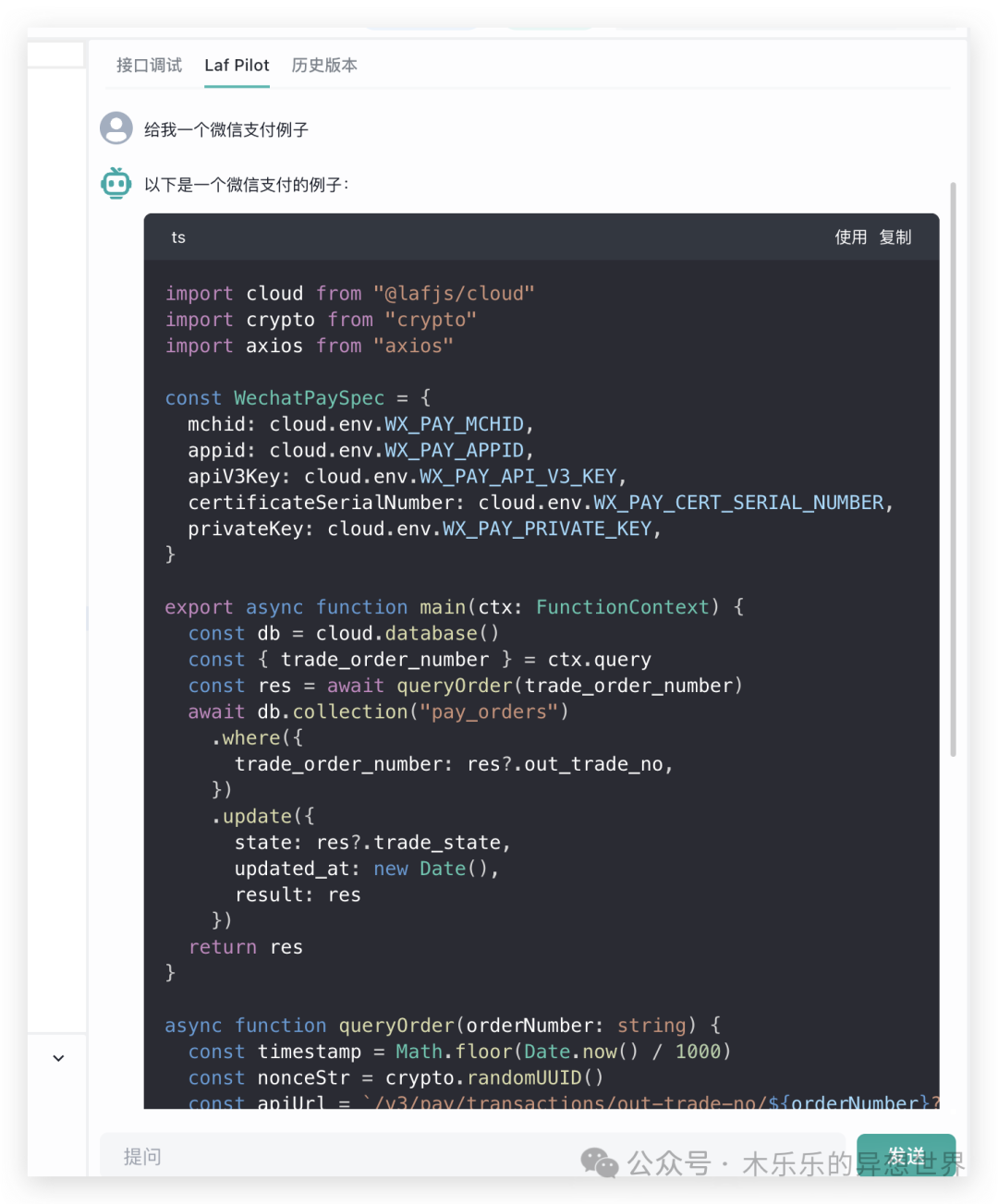
- 接下来,试一下配置 deepseek 模型。
进入到模型供应商界面,选择模型渠道,点击新增渠道。然后逐个输入渠道名,协议,选择模型,然后,就是填入代理地址和 API。
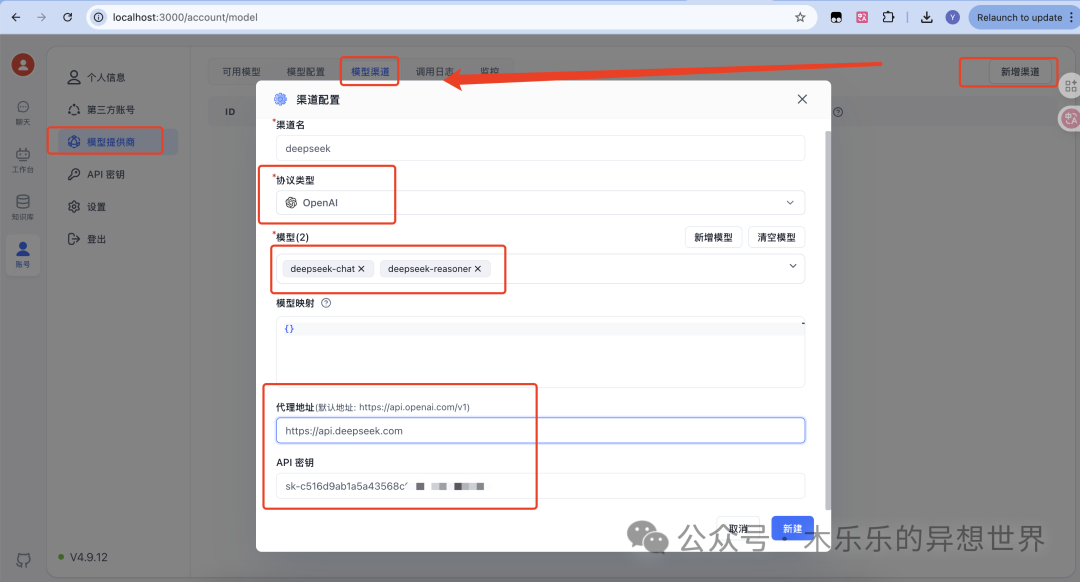
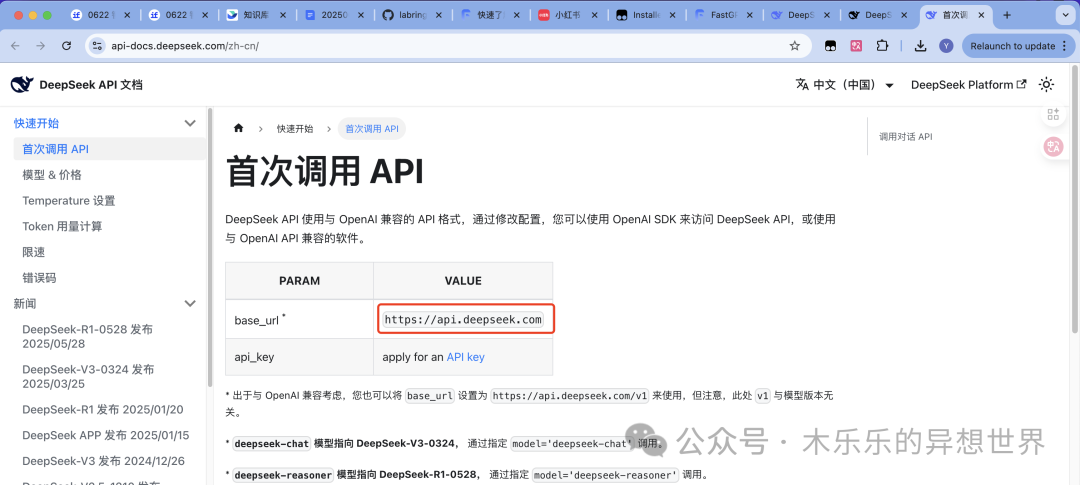
其中,deepseek 的代理地址和 api 需要自己注册 deepseek 账号,然后,通过开发者平台获取。
https://platform.deepseek.com/
配置完成后,需要批量测试一下模型,保证模型可用。
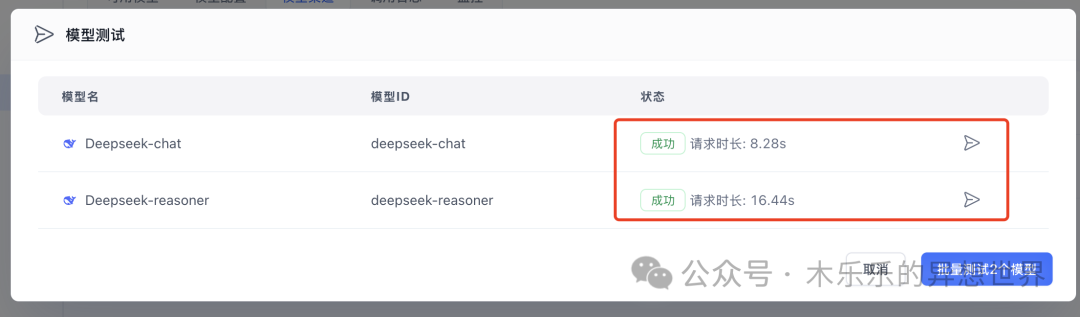
接下来,来到模型配置区域,选择 deepseek,然后,打开启用开关。
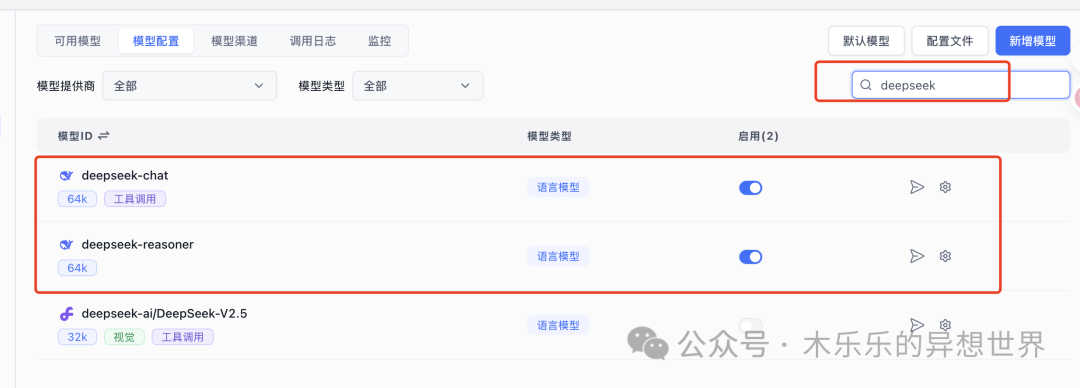
2-配置 embedding大模型
这个是解析文件知识的基本前提,我配置的是硅基流动的bge-m3。
硅基流动上已经预安装了非常多的开源模型。现在注册还有 2000 万 Tokens的免费额度https://cloud.siliconflow.cn/i/l9sTxT3i
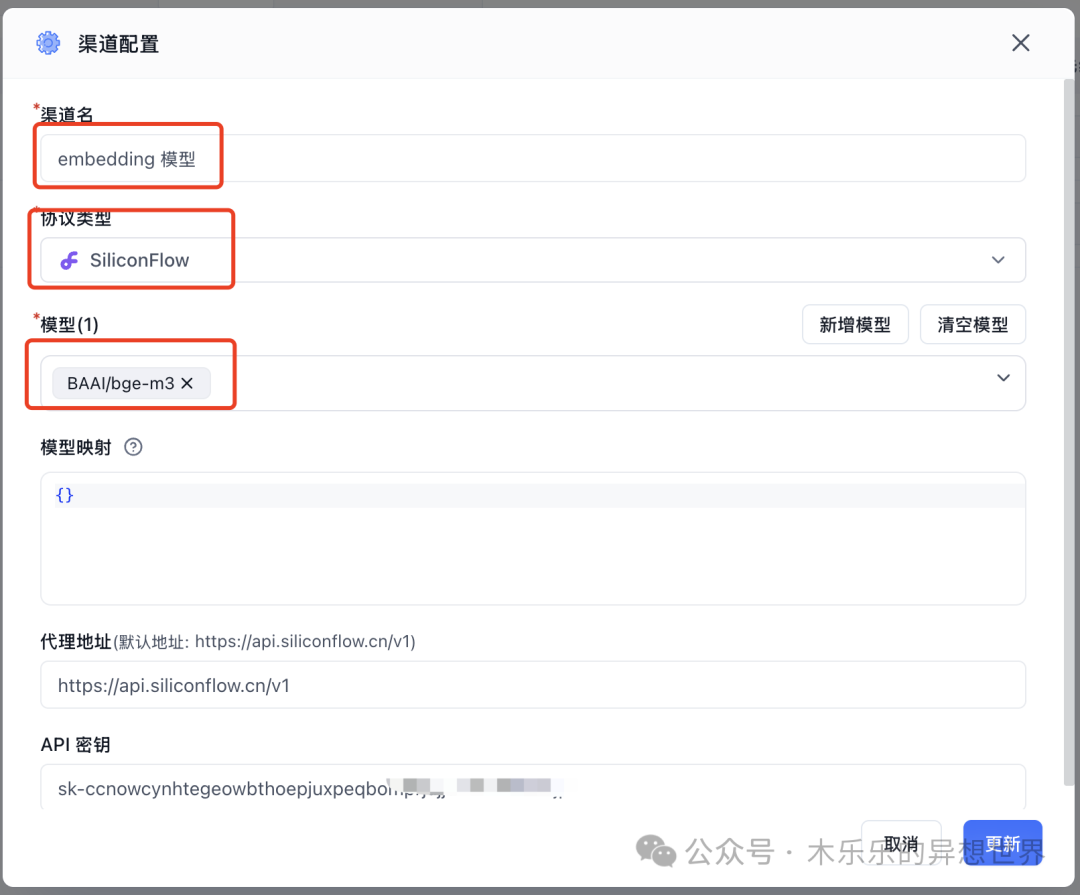
3-测试知识解析能力
这里省略知识库的导入和解析过程。
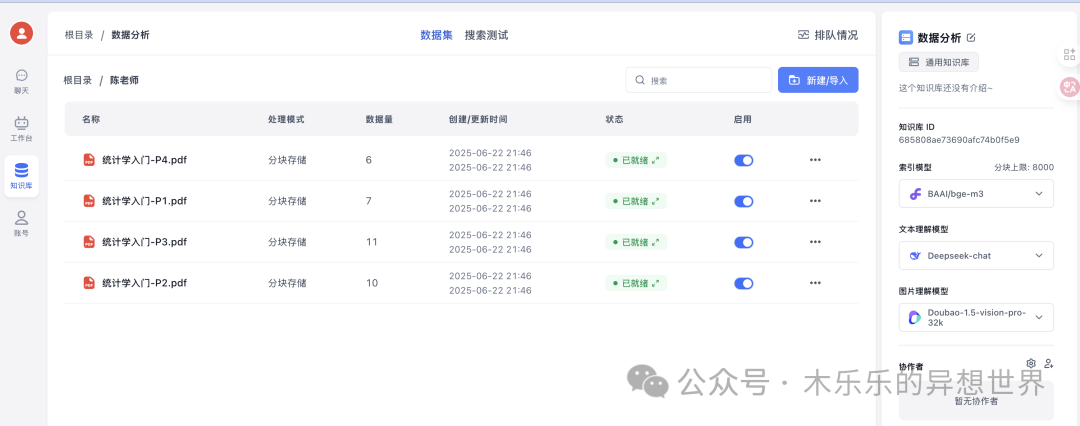
直接看知识库索引结果。
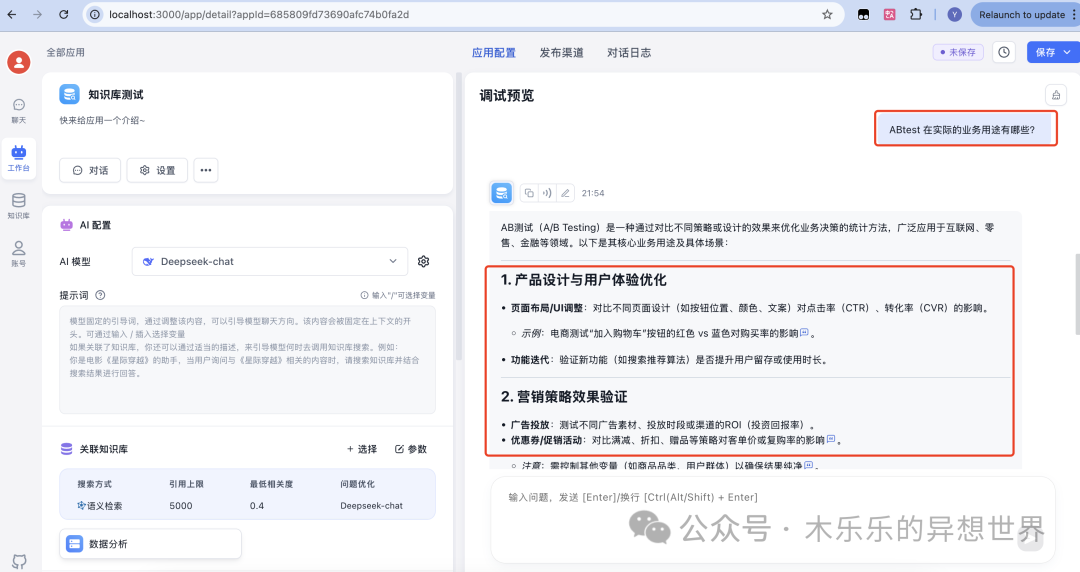
简直是完美:
AB测试(A/B Testing)是一种通过对比不同策略或设计的效果来优化业务决策的统计方法,广泛应用于互联网、零售、金融等领域。以下是其核心业务用途及具体场景:
- 产品设计与用户体验优化
-
页面布局/UI调整:对比不同页面设计(如按钮位置、颜色、文案)对点击率(CTR)、转化率(CVR)的影响。
-
- 示例:电商测试“加入购物车”按钮的红色 vs 蓝色对购买率的影响。
-
功能迭代:验证新功能(如搜索推荐算法)是否提升用户留存或使用时长。
- 营销策略效果验证
-
广告投放:测试不同广告素材、投放时段或渠道的ROI(投资回报率)。
-
优惠券/促销活动:对比满减、折扣、赠品等策略对客单价或复购率的影响。
-
- 注意:需控制其他变量(如商品品类、用户群体)以确保结果纯净。
- 运营策略决策
- 定价策略:分群体测试不同价格敏感度(如会员价 vs 普通价)。
- 推送策略:优化推送内容、频率或时机(如早晨 vs 晚间推送的打开率)。
- 算法与模型优化
- 推荐系统:对比新旧算法对点击率、GMV(总交易额)的提升效果。
- 搜索排序:测试不同排序规则(如相关性 vs 销量优先)对用户满意度的影响。
- 风险与流程控制
- 风控策略:验证新规则(如 stricter 欺诈检测)是否在减少损失的同时避免误杀正常用户。
- 注册/支付流程:简化步骤(如减少表单字段)能否提升完成率。
关键实施原则
-
单变量测试:一次仅测试一个变量(如只改按钮颜色,不同时改文案),避免混淆结果。
-
样本量充足:确保统计功效(Power)足够检测到差异,避免小样本误判。
-
结果解读:
-
- 若P值≤0.05,认为差异显著;否则需谨慎结论。
- 结合业务实际(如成本、用户体验)综合决策,避免仅依赖统计显著性。
常见误区
- 忽略外部干扰:如节假日、竞品活动可能影响测试结果。
- 过早终止测试:未达到预定样本量时停止,可能导致结论不可靠。
AB测试通过数据驱动决策,帮助业务在可控风险下实现持续优化
。
再追问一个问题“ABtest 的原理本质是什么”点开原文引用:
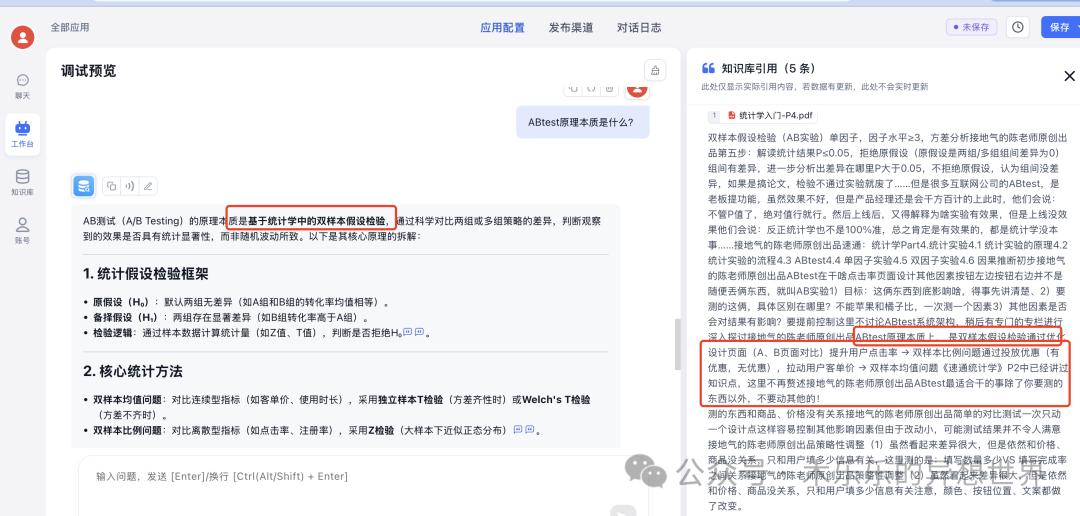
体验)综合决策,避免仅依赖统计显著性。
常见误区
- 忽略外部干扰:如节假日、竞品活动可能影响测试结果。
- 过早终止测试:未达到预定样本量时停止,可能导致结论不可靠。
AB测试通过数据驱动决策,帮助业务在可控风险下实现持续优化
。
再追问一个问题“ABtest 的原理本质是什么”点开原文引用:
[外链图片转存中…(img-7q1AXNFR-1750767361443)]
完美,收工!
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取
👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献201条内容
已为社区贡献201条内容

所有评论(0)