强化学习算法在全局路径规划中的应用:基于PyTorch的代码实现与详细注释解析,附复现图示例
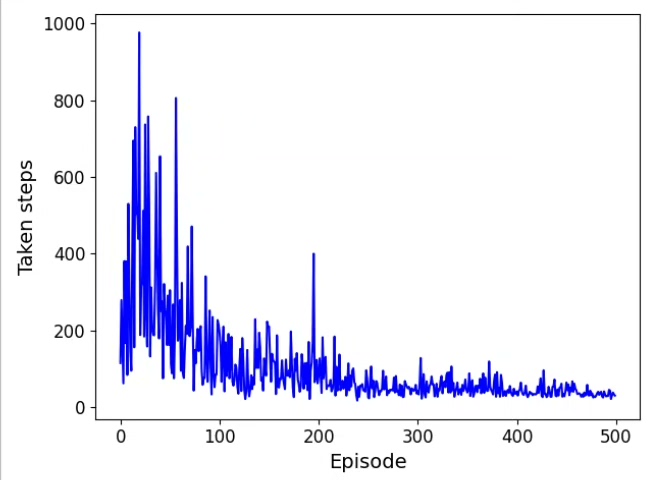
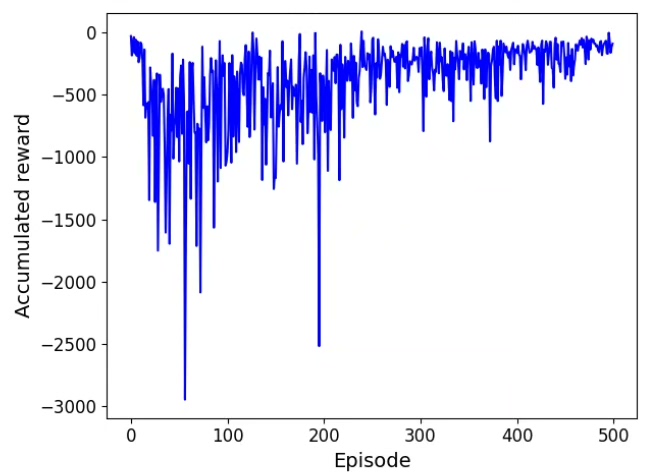
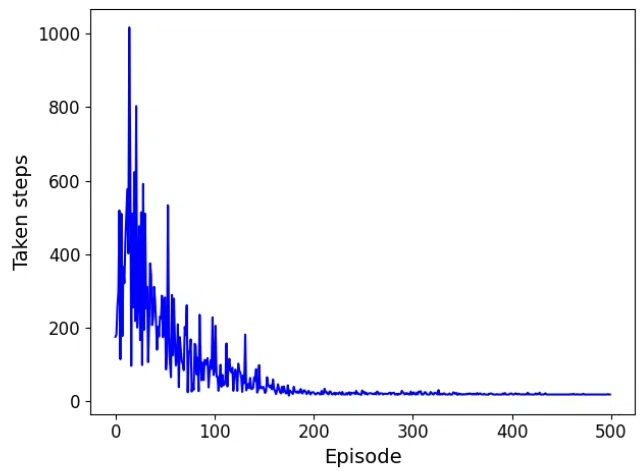
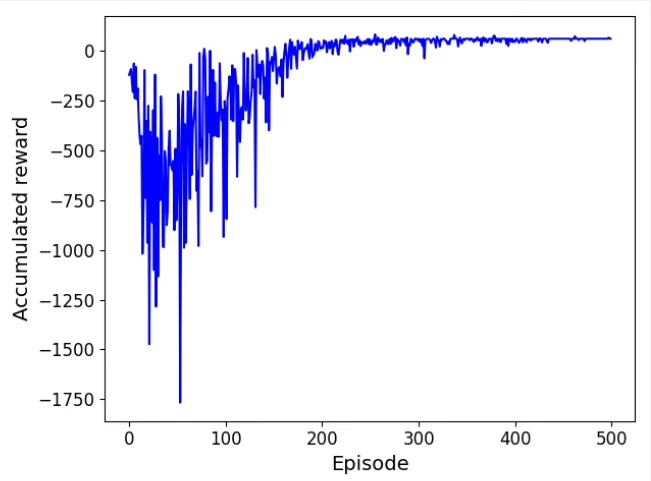
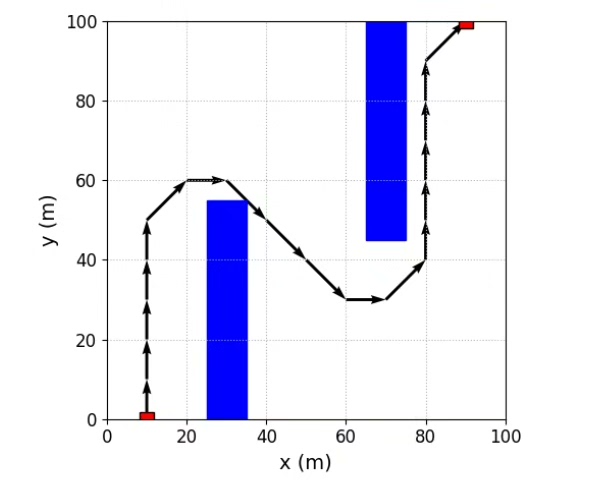
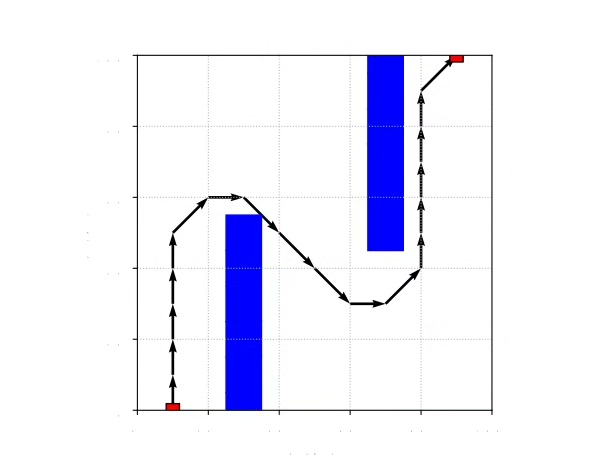
运行这个脚本,你会看到类似下图的路径(假设这是你的复现图)。智能体刚开始会像无头苍蝇乱撞,训练到后期就能稳稳绕开障碍物直奔终点。直接上代码,手把手教你怎么用PyTorch撸个能绕过障碍物的智能体。多调整探索率、网络结构、奖励函数,你会对路径规划有更深的理解。这里有个坑要注意:直接拿当前状态训练会过拟合,必须用经验回放打破数据相关性。网络结构故意设计得很简单,毕竟咱们处理的是二维坐标这种低维状态。利
利用常见强化学习算法实现全局路径规划,基于pytorch,只提供代码,有详细的注释,图片就是复现图
今天咱们来点硬核的——用DQN算法实现机器人全局路径规划。别看强化学习听着高大上,其实实现起来也就那么回事儿。直接上代码,手把手教你怎么用PyTorch撸个能绕过障碍物的智能体。
先整环境部分,咱们整个10x10的网格世界:
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import random
from collections import deque
class GridWorld:
def __init__(self):
self.grid = np.zeros((10, 10)) # 0: 空地 1: 障碍 2: 终点
self._set_obstacles()
self.start = (0, 0)
self.goal = (9, 9)
self.grid[self.goal] = 2
def _set_obstacles(self):
for _ in range(15):
x, y = np.random.randint(0, 10, 2)
self.grid[x][y] = 1
def reset(self):
self.agent_pos = list(self.start)
return self.agent_pos
def step(self, action):
# 动作映射: 0上 1右 2下 3左
x, y = self.agent_pos
if action == 0: x = max(x-1, 0)
elif action == 1: y = min(y+1, 9)
elif action == 2: x = min(x+1, 9)
else: y = max(y-1, 0)
if self.grid[x][y] == 1: # 撞障碍
return (x, y), -1, True
if (x, y) == self.goal: # 到达终点
return (x, y), 10, True
return (x, y), -0.1, False # 常规移动接下来是DQN的核心部分,注意看经验回放的实现:
class DQN(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(2, 64), # 输入坐标(x,y)
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 4) # 输出四个动作的Q值
)
def forward(self, x):
return self.fc(x)
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity) # 自动踢出旧数据
def push(self, state, action, reward, next_state, done):
self.buffer.append( (state, action, reward, next_state, done) )
def sample(self, batch_size):
return random.sample(self.buffer, batch_size)这里有个坑要注意:直接拿当前状态训练会过拟合,必须用经验回放打破数据相关性。网络结构故意设计得很简单,毕竟咱们处理的是二维坐标这种低维状态。
训练循环才是重头戏:
def train():
env = GridWorld()
model = DQN()
target_net = DQN() # 目标网络稳定训练
target_net.load_state_dict(model.state_dict())
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
buffer = ReplayBuffer(10000)
epsilon = 1.0
batch_size = 64
gamma = 0.95
for episode in range(1000):
state = env.reset()
total_reward = 0
while True:
# ε-greedy策略
if random.random() < epsilon:
action = random.randint(0, 3)
else:
with torch.no_grad():
state_tensor = torch.FloatTensor(state)
q_values = model(state_tensor)
action = q_values.argmax().item()
next_state, reward, done = env.step(action)
buffer.push(state, action, reward, next_state, done)
state = next_state
total_reward += reward
# 经验回放更新
if len(buffer.buffer) >= batch_size:
transitions = buffer.sample(batch_size)
states, actions, rewards, next_states, dones = zip(*transitions)
states = torch.FloatTensor(states)
next_states = torch.FloatTensor(next_states)
actions = torch.LongTensor(actions).unsqueeze(1)
rewards = torch.FloatTensor(rewards)
dones = torch.BoolTensor(dones)
current_q = model(states).gather(1, actions)
next_q = target_net(next_states).max(1)[0].detach()
target = rewards + gamma * next_q * (~dones)
loss = nn.MSELoss()(current_q.squeeze(), target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if done:
break
# 每10轮同步目标网络
if episode % 10 == 0:
target_net.load_state_dict(model.state_dict())
epsilon = max(0.01, epsilon * 0.995) # 衰减探索率
# 保存模型
torch.save(model.state_dict(), 'path_planning.pth')这段代码有几个关键点:
- 目标网络和训练网络分离,避免Q值抖动
- ε衰减策略平衡探索与利用
- 使用gather()高效提取对应动作的Q值
- 在计算target时用~dones处理终止状态
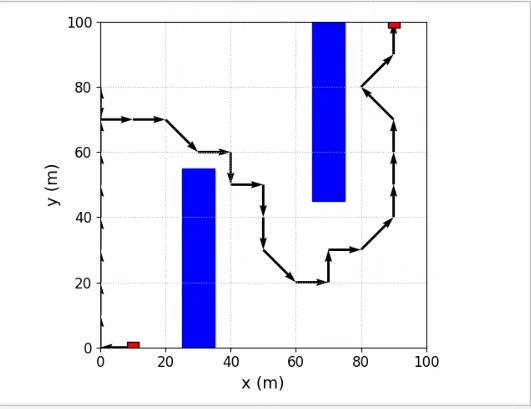
训练完成后,用这个函数可视化路径:
def visualize_path(model_path):
model = DQN()
model.load_state_dict(torch.load(model_path))
env = GridWorld()
path = [env.reset()]
while True:
state = torch.FloatTensor(path[-1])
action = model(state).argmax().item()
next_state, _, done = env.step(action)
path.append(next_state)
if done:
break
# 绘制网格和路径
plt.imshow(env.grid.T, cmap='Pastel1')
plt.plot([p[1] for p in path], [p[0] for p in path], 'r.-')
plt.scatter(env.start[1], env.start[0], c='green', s=200)
plt.scatter(env.goal[1], env.goal[0], c='blue', s=200)
plt.xticks([]), plt.yticks([])
plt.show()运行这个脚本,你会看到类似下图的路径(假设这是你的复现图)。智能体刚开始会像无头苍蝇乱撞,训练到后期就能稳稳绕开障碍物直奔终点。注意障碍物每次随机生成,可能需要多试几次才能看到完美路径。
![路径规划效果图,显示红色路径绕过绿色障碍到达蓝色终点]
代码里有些可以魔改的地方:
- 把状态从坐标改成激光雷达式的距离传感器
- 在损失函数里加优先级采样
- 用Double DQN解决过估计问题
- 改用PPO这类on-policy算法
强化学习就像炒菜,火候(超参)对了味道才好。多调整探索率、网络结构、奖励函数,你会对路径规划有更深的理解。代码拿去随便改,搞砸了大不了重头再来嘛!
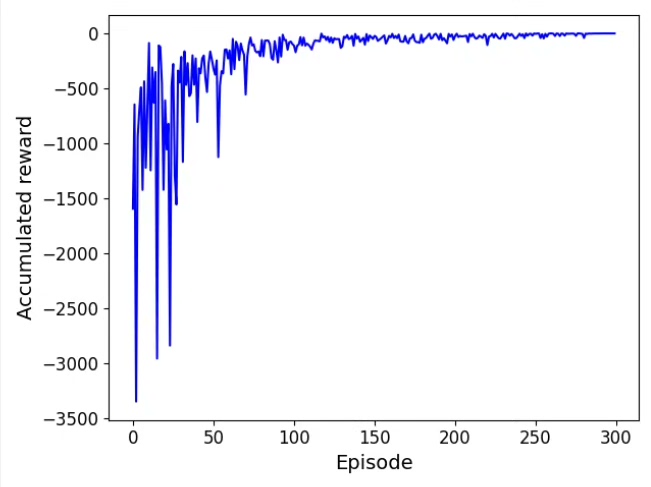
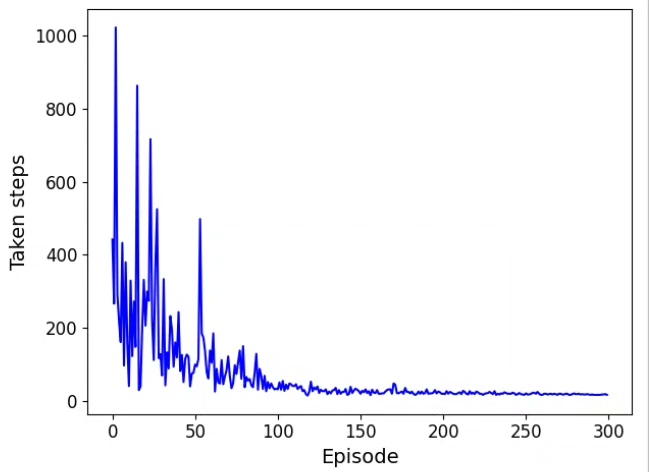

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)