如何让 RAG 从“能用”到“好用”
自己可见。

本手册为简化版手册,点击完整版实验手册链接
提示:建议使用 lazyllm==0.6.1
奖励
提交任务结果
奖励一:最先得出回答的前 8 名开发者可以领取150元京东E卡
奖励二:实战结束后,随机抽出提交结果 6 名同学 送出 50元京东卡
./docs文件下载
https://drive.weixin.qq.com/s?k=AIcA6Qe3AAkR4Gj0Zz
实验结束后随机抽出 6 名同学送出 50元京东卡
10 分钟拿下 Agent 快速部署
LazyLLM RAG 优化体验指南
10 分钟拿下 Agent 快速部署
1.环境准备
LazyLLM 基于 Python 开发,我们需要保证系统中已经安装好了 Python(3.10-3.12), Pip
本次实验手册基于 python 3.10 操作, python 3.13 可能不兼容
IDE 可以选用:Trae 、Pycharm、VSCode 等等等
2.配置虚拟环境
在 IDE 中新建一个本次项目的文件夹例如agentLazyLLM,并在终端中打开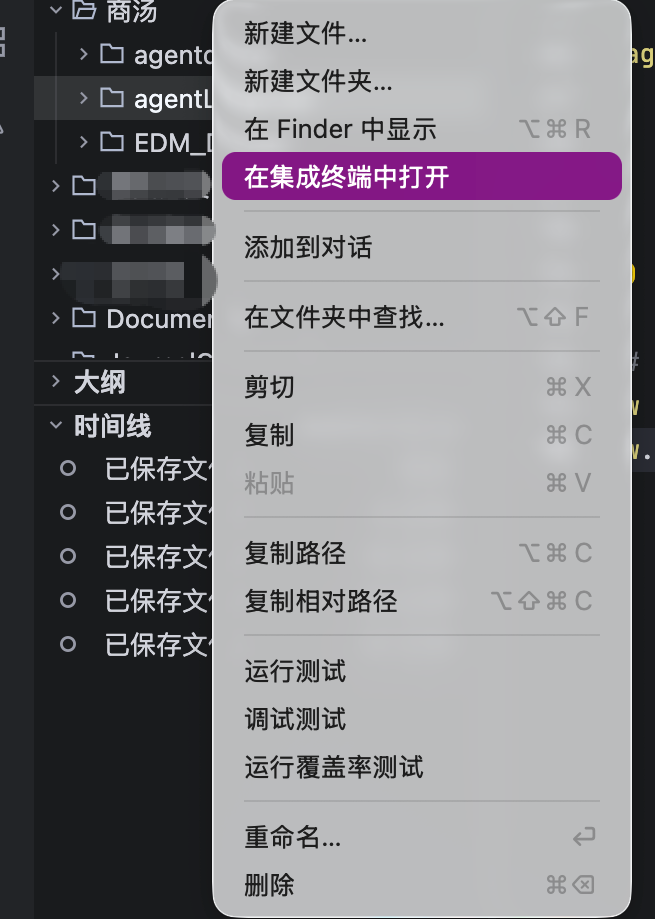
在终端中创建一个虚拟环境名为lazyllm-venv并激活:
python3 -m venv lazyllm-venv
source lazyllm-venv/bin/activate
如果正常运行,你可以在命令行的开头看到 (lazyllm-venv) 的提示。
接下来我们的操作都在这个虚拟环境中进行。
3. 从 pip 安装 LazyLLM
在控制台中输入pip3 install lazyllm==0.6.1 -i https://mirrors.aliyun.com/pypi/simple,等待安装结束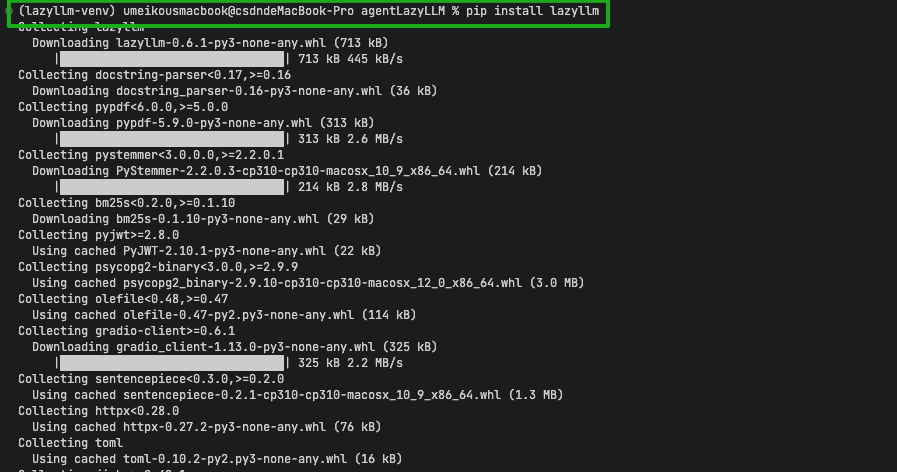
4.配置模型
LazyLLM 支持线上调用和本地调用
本文演示方法为线上调用,需要提供相应平台的API Key。本次活动将用到sensenova 以及 qwen平台的api(已经开通过的同学可跳过此步骤)
API 1:qwen api 申请
- 前往:https://bailian.console.aliyun.com/?tab=model#/api-key 如果没有注册过 请先注册
- 点击创建API KEY
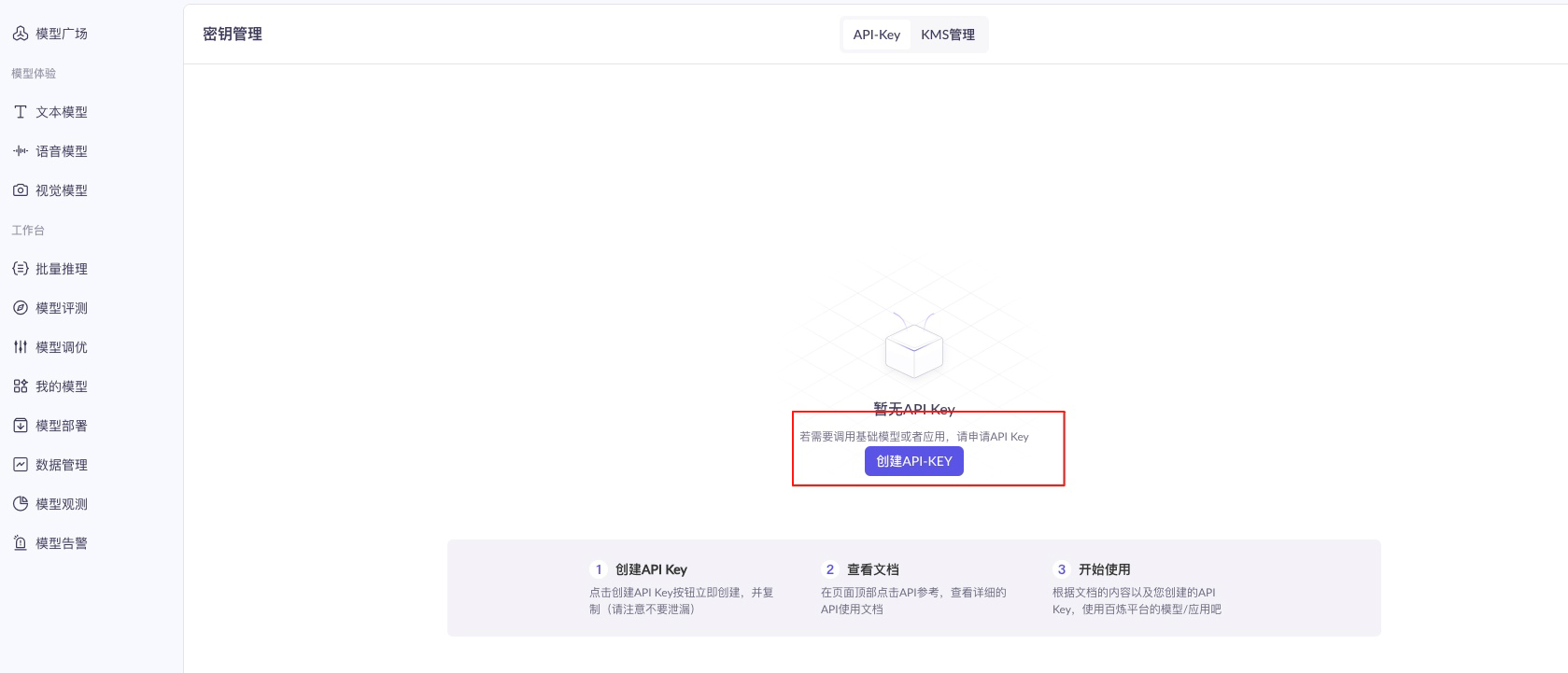
- 保存该字符串
API 2:sensenova api申请
官网链接:https://console.sensecore.cn/home
-
进入sensecore官网注册页面并进行账号注册:
-
进入万象模型开发平台
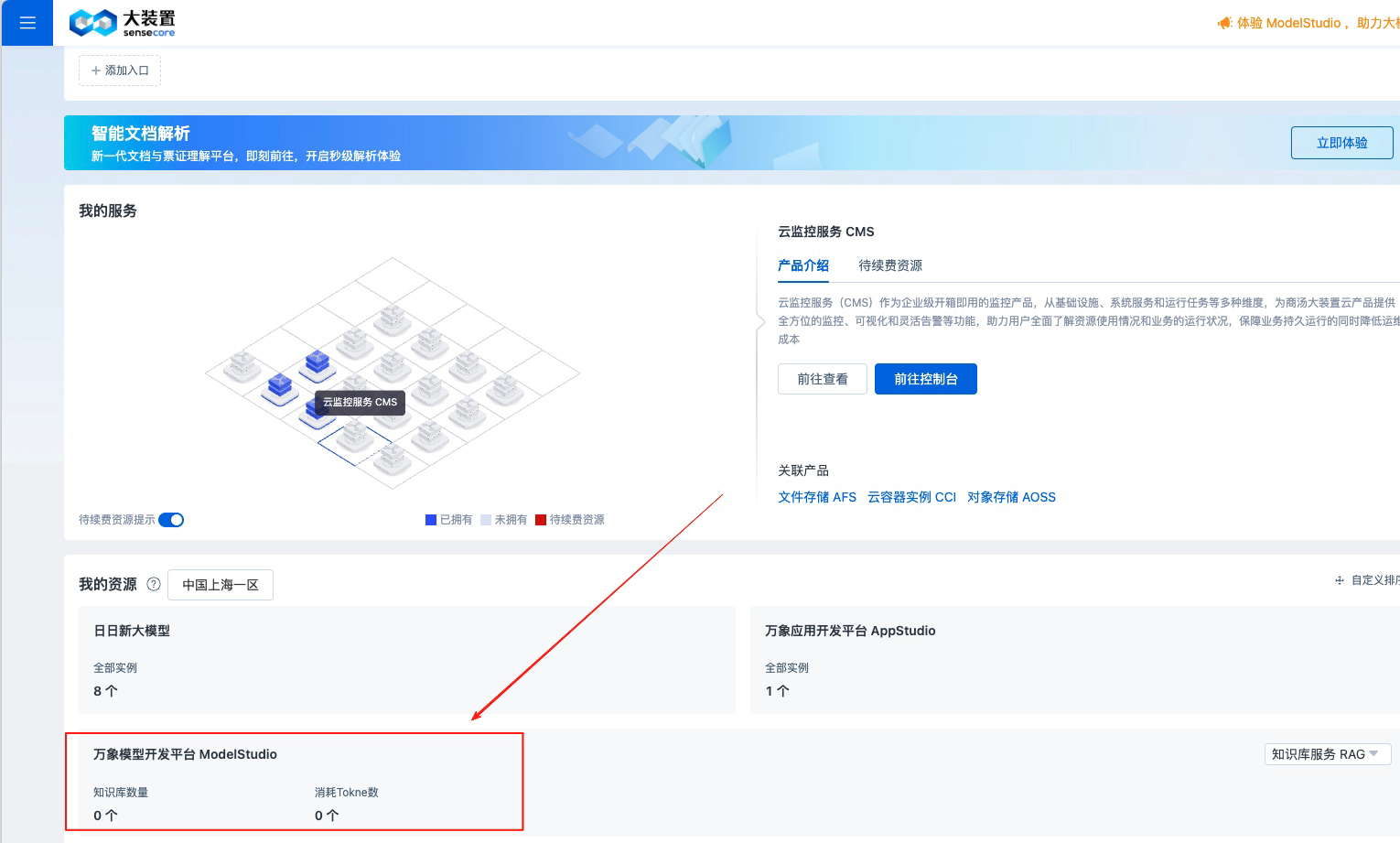
-
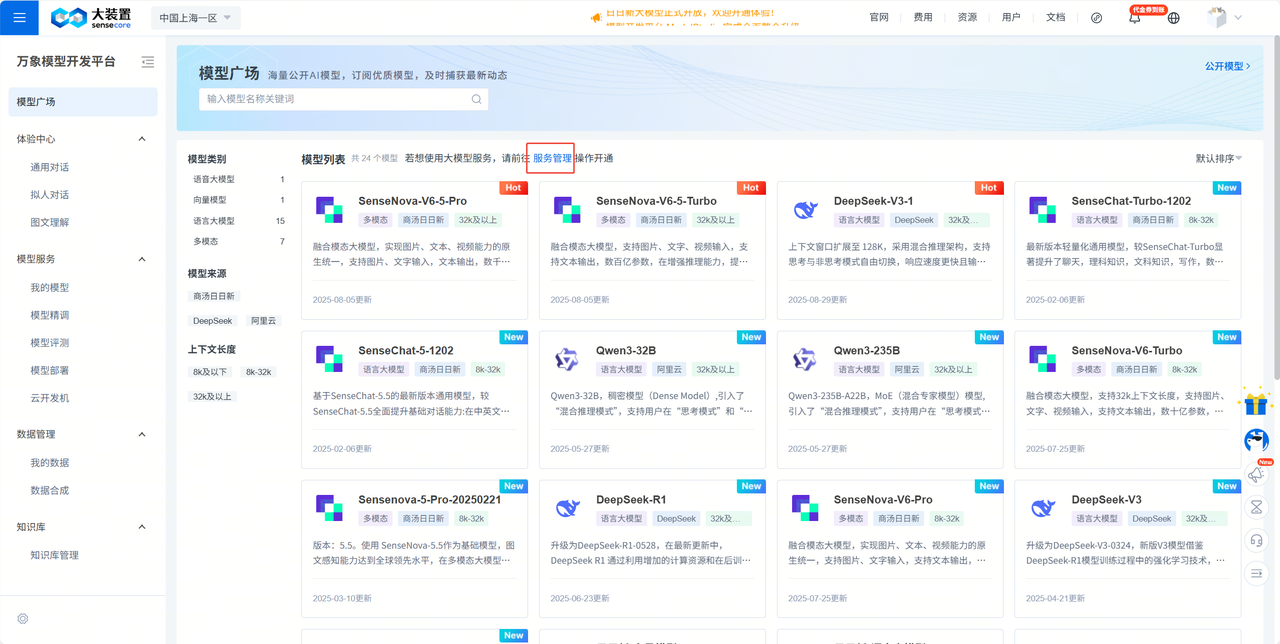
点击
立即体验-服务管理开通需要的模型(开通DeepSeek-V3-1)
-
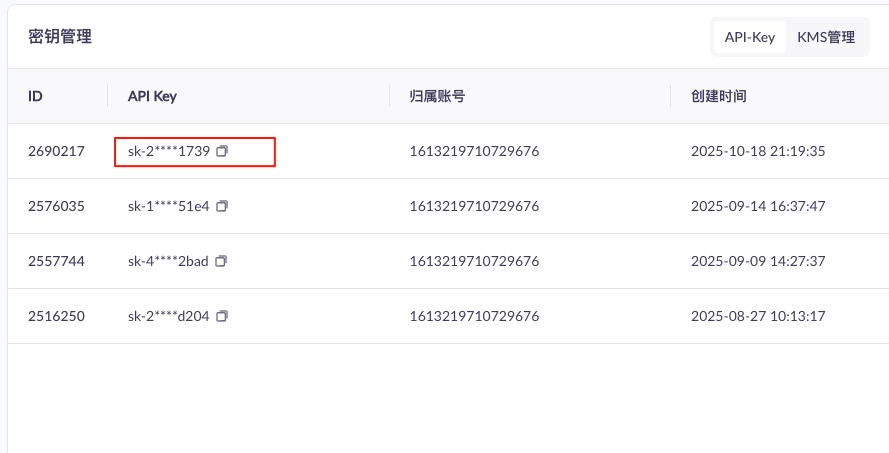
在 API 管理中保存好 你的 API Key
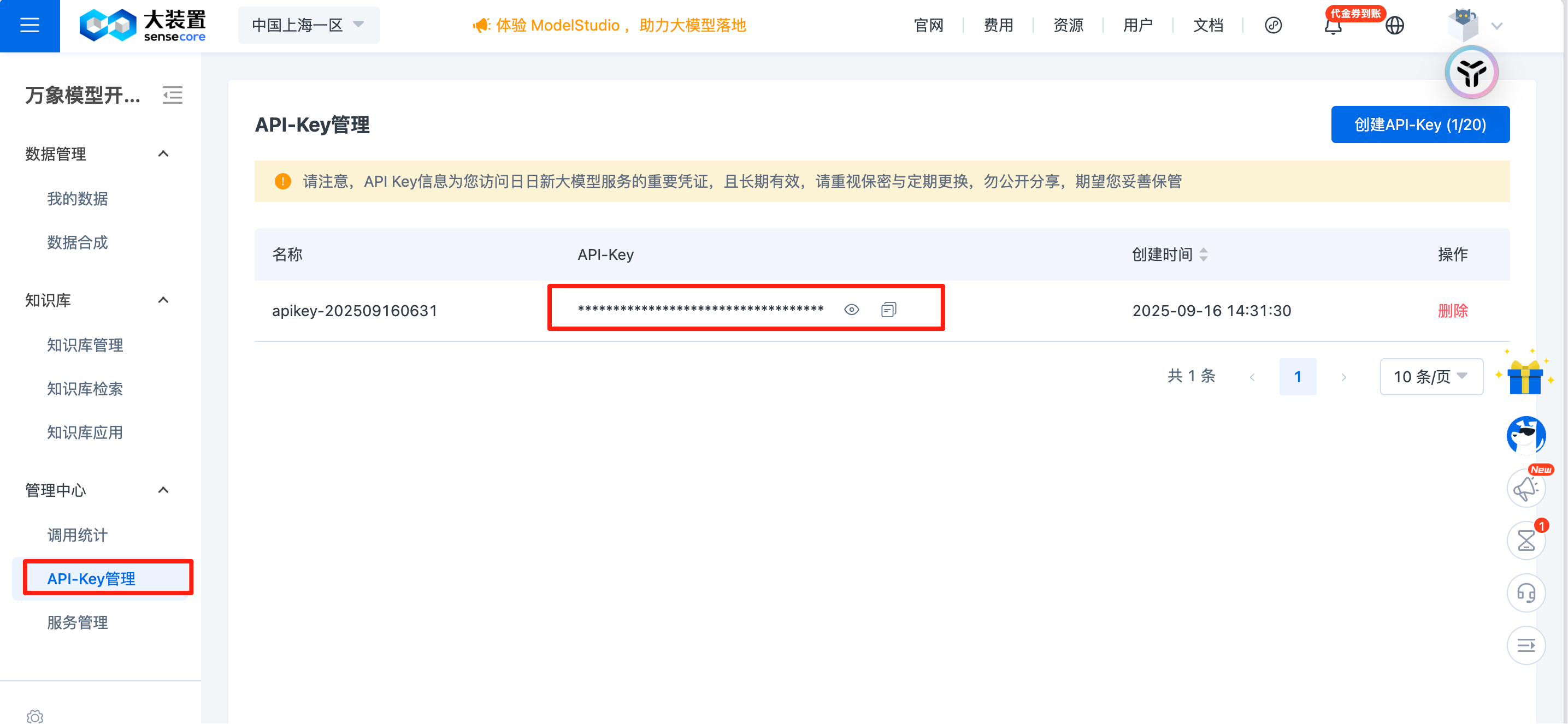
设置环境变量
好了我们保存好了两个平台的密钥,现在将他配置到环境变量中
(1) Mac OS 配置方法
# macos
vi ~/.zshrc
按 e 进入编辑模式,再按 i 进入插入状态
用方向键移动光标,插入下面的语句,YOUR-API-KEY替换为上面保存的 API-KEY
export LAZYLLM_SENSENOVA_API_KEY='YOUR-API-KEY'
export LAZYLLM_QWEN_API_KEY='YOUR-API-KEY'
插入后 按键盘的Esc ,再输入:wq!,保存并退出
再输入 source ~/.zshrc 使命令永久生效
(2)windows 配置方法
- 右键点击"此电脑"或"我的电脑",选择"属性"
- 点击"高级系统设置"
- 在"系统属性"窗口中点击"环境变量"
- 在"系统变量"或"用户变量"区域点击"新建"
- 输入变量名(`LAZYLLM_QWEN_API_KEY`)和变量值(您的"API密钥")
- 输入变量名(`LAZYLLM_SENSENOVA_API_KEY`)和变量值(您的"API密钥")
- 点击"确定"保存
- 点击"确定"关闭所有窗口
- 重新启动命令提示符或PowerShell以使更改生效
(3) linux 配置方法
export LAZYLLM_SENSENOVA_API_KEY='YOUR-API-KEY'
YOUR-API-KEY替换为上面保存的 API-KEY
2.5 恭喜你 一切准备就绪
尝试在刚刚创建的的虚拟环境下运行以下代码:
import lazyllm
chat = lazyllm.OnlineChatModule(source='sensenova',model='DeepSeek-V3-1')
while True:
query = input("query(enter 'quit' to exit): ")
if query == "quit":
break
res = chat.forward(query)
print(f"answer: {res}")
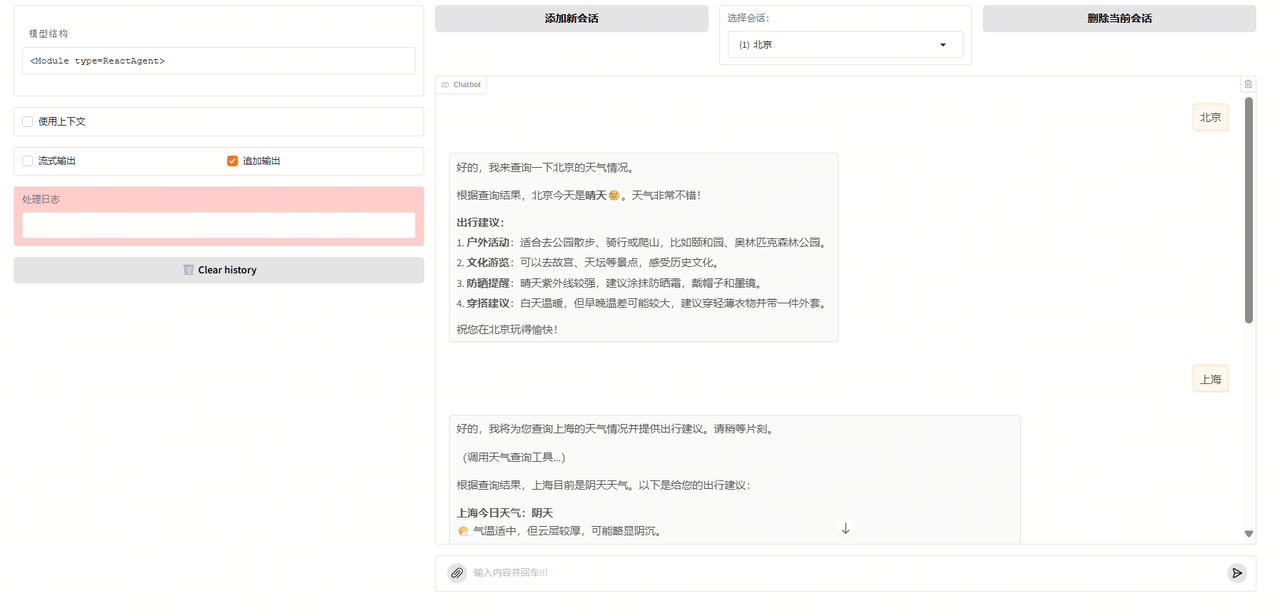
运行后就可以进行模型的调用,结果如下
2.6 创建一个天气查询工具
您可以使用外部API查询天气(例如高德天气(基础 API 文档-开发指南-Web服务 API | 高德地图API)),也可以使用LazyLLM提供的天气工具。
这里我们为了方便演示,构造了一个dict来模拟天气示例,使用3个城市对应晴天、阴天和雨天
# 天气数据字典
WEATHER_DATA = {
"北京": {
"province": "北京市",
"city": "北京",
"publish_time": "2024-01-15 08:00:00",
"weather": "晴天",
"wind": "西北风 3-4级",
"sunriseSunset": "日出: 07:30, 日落: 17:20",
"temperature": "5°C / -3°C"
},
"上海": {
"province": "上海市",
"city": "上海",
"publish_time": "2024-01-15 08:00:00",
"weather": "阴天",
"wind": "东南风 2-3级",
"sunriseSunset": "日出: 07:00, 日落: 17:30",
"temperature": "12°C / 8°C"
},
"广州": {
"province": "广东省",
"city": "广州",
"publish_time": "2024-01-15 08:00:00",
"weather": "雨天",
"wind": "南风 4-5级",
"sunriseSunset": "日出: 07:10, 日落: 18:00",
"temperature": "18°C / 15°C"
}
}
用 Agent 组装实现
import json
from lazyllm import ReactAgent, fc_register, LOG, OnlineChatModule, WebModule
# 天气数据字典
WEATHER_DATA = {
"北京": {
"province": "北京市",
"city": "北京",
"publish_time": "2024-01-15 08:00:00",
"weather": "晴天",
"wind": "西北风 3-4级",
"sunriseSunset": "日出: 07:30, 日落: 17:20",
"temperature": "5°C / -3°C"
},
"上海": {
"province": "上海市",
"city": "上海",
"publish_time": "2024-01-15 08:00:00",
"weather": "阴天",
"wind": "东南风 2-3级",
"sunriseSunset": "日出: 07:00, 日落: 17:30",
"temperature": "12°C / 8°C"
},
"广州": {
"province": "广东省",
"city": "广州",
"publish_time": "2024-01-15 08:00:00",
"weather": "雨天",
"wind": "南风 4-5级",
"sunriseSunset": "日出: 07:10, 日落: 18:00",
"temperature": "18°C / 15°C"
}
}
@fc_register("tool")
def get_weather(city: str):
"""
天气查询。
Args:
city: 城市名(中文),当前仅支持北京、上海、广州
Returns: 当地当天的天气信息
"""
try:
# 从字典中查找天气数据
if city in WEATHER_DATA:
res = WEATHER_DATA[city]
return json.dumps(str(res), ensure_ascii=False)
else:
return f"抱歉,暂时无法查询到 {city} 的天气信息。目前支持的城市有:北京、上海、广州"
except Exception as e:
message = f"[Tool - get_weather] error occur, city: {city}, error: {str(e)[:512]}"
LOG.error(message)
return message
prompt = """
【角色】
你是一个出行建议助手,能够根据用户给定的城市名称主动查询天气信息,并给出出行建议。
【要求】
1. 根据用户的输入,调用工具查询当地天气情况
2. 城市名称为中文
3. 出行建议可以推荐一些活动
4. 目前支持的城市:北京(晴天)、上海(阴天)、广州(雨天)
"""
agent = ReactAgent(
llm=OnlineChatModule(source='sensenova',stream=False,model='DeepSeek-V3-1'),
tools=['get_weather'],
prompt=prompt,
stream=False
)
# 前端页面
w = WebModule(agent, port=8846, title="ReactAgent")
w.start().wait()
LazyLLM RAG 优化体验指南
1. 环境要求
- Python 3.10-3.12
- LazyLLM
2. 安装依赖
pip install lazyllm==0.6.1
将下载的文件夹解压后放在与代码同一根目录
最基础的rag
import lazyllm
from lazyllm import Retriever, Document, OnlineEmbeddingModule
# api_key = "sk-"
# qwen_api_key = "sk-"
doc_path = "./docs"
embed_model = OnlineEmbeddingModule(source="qwen", embed_model_name="text-embedding-v4")
doc = Document(dataset_path=doc_path, embed=embed_model)
retriever = Retriever(doc, group_name='CoarseChunk', similarity="cosine", topk=3)
llm = lazyllm.OnlineChatModule(source="sensenova",model="SenseChat-5")
# prompt 设计
prompt = 'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions.'
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
query = "你的问题"
# 将Retriever组件召回的节点全部存储到列表doc_node_list中
doc_node_list = retriever(query=query)
# 将query和召回节点中的内容组成dict,作为大模型的输入
res = llm({"query": query, "context_str": "".join([node.get_content() for node in doc_node_list])})
print(f'With RAG Answer: {res}')
agentic 一下
from lazyllm import (
fc_register, Document, Retriever,
OnlineEmbeddingModule, OnlineChatModule, WebModule,
ReactAgent
)
# api_key = "sk-"
# qwen_api_key = "sk-"
doc_path = "./docs"
embed_model = OnlineEmbeddingModule(source="qwen", embed_model_name="text-embedding-v4")
doc = Document(dataset_path=doc_path, embed=embed_model)
retriever = Retriever(doc, group_name='CoarseChunk', similarity="cosine", topk=3)
retriever.start()
# 注册RAG工具
@fc_register("tool")
def search_knowledge_base(query: str):
"""
搜索知识库并返回相关文档内容
Args:
query (str): 搜索查询字符串
"""
# 将Retriever组件召回的节点全部存储到列表doc_node_list中
doc_node_list = retriever(query=query)
# 将召回节点中的内容组合成字符串
context_str = "".join([node.get_content() for node in doc_node_list])
return context_str
# prompt 设计
prompt = 'You will act as an AI question-answering assistant and complete a dialogue task. In this task, you need to provide your answers based on the given context and questions. You can use the search_knowledge_base tool to find relevant information from the knowledge base.'
# 创建ReactAgent
agent = ReactAgent(
llm=OnlineChatModule(source='sensenova', model="SenseChat-5", stream=True),
tools=['search_knowledge_base'],
prompt=prompt,
stream=True
)
# 创建Web模块并启动
w = WebModule(agent, stream=True)
w.start().wait()
多策略检索优化
1. 自定义解析器-随心所欲解析文档
# customize_rag.py
from pathlib import Path
from typing import List, Optional, Dict
from lazyllm.tools.rag import DocNode
from pptx import Presentation
from pptx.enum.shapes import MSO_SHAPE_TYPE
from pptx.oxml.ns import nsmap
import uuid
import os
import subprocess
import time
from lazyllm import LOG
# register the reader for one document
from lazyllm import Document
# 借助python-pptx库,实现pptx文件的读取与解析
class PPTXReader:
image_save_path = os.getenv("RAG_IMAGE_PATH_PREFIX", "./images") # 图片保存路径,兼容多模态
def __init__(self):
os.makedirs(self.image_save_path, exist_ok=True)
LOG.info(f"[PPTXReader] Image save path: {self.image_save_path}")
def _save_picture(self, image) -> str:
orig_fn = Path(image.filename).name
ext = Path(orig_fn).suffix or ".png"
fname = f"{uuid.uuid4()}{ext}"
full_path = os.path.join(self.image_save_path, fname)
with open(full_path, "wb") as f:
f.write(image.blob)
return fname
def _extract_shape_text(self, shape):
texts = []
# 1. normal text frame
if getattr(shape, "has_text_frame", False):
for p in shape.text_frame.paragraphs:
texts.append("".join(run.text for run in p.runs))
if getattr(shape, "has_table", False):
rows = [[cell.text.strip() for cell in row.cells]
for row in shape.table.rows]
header = [""] * len(rows[0])
md = ["| " + " | ".join(header) + " |",
"| " + " | ".join("---" for _ in header) + " |"]
for row in rows:
md.append("| " + " | ".join(cell or " " for cell in row) + " |")
texts.append("\n".join(md))
if shape.shape_type == MSO_SHAPE_TYPE.GROUP:
for shp in shape.shapes:
texts.append(self._extract_shape_text(shp))
return "\n".join(filter(None, texts))
def __call__(self, file: Path, extra_info: Optional[Dict] = None, **kwargs) -> List[DocNode]:
return self._load_data(file, extra_info, **kwargs)
def _load_data(
self, file: Path, extra_info: Optional[Dict] = None, **kwargs
) -> List[DocNode]:
_metadata = {"file_name": file.name}
if extra_info is not None:
_metadata.update(extra_info)
if not isinstance(file, Path): file = Path(file)
presentation = Presentation(file)
doc_list = []
# 逐页处理
for i, slide in enumerate(presentation.slides):
slide_content = f"# Slide - {i}\n"
metadata = {"index": i}
metadata.update(_metadata)
text = ""
images = []
# 每页逐shape处理
for shape in slide.shapes:
txt = self._extract_shape_text(shape) # 文字提取
if txt:
text += f"{txt}\n\n"
# 图片提取
if shape.shape_type == MSO_SHAPE_TYPE.PICTURE:
img = shape.image
fname = self._save_picture(img)
images.append(fname)
if text:
slide_content += f"## Text\n{text}\n\n"
if images:
slide_content += f"## Images\n"
for img in images:
slide_content += f"\n"
# ppt的每页作为一个独立节点
doc_list.append(DocNode(text=slide_content, metadata=metadata))
return doc_list
doc = Document(dataset_path="./docs")
doc.add_reader("*.pptx", PPTXReader)
# register for Global
Document.add_reader("*.pptx", PPTXReader)
reader = PPTXReader()
file = Path("./docs/李晨_个人简历.pptx")
res = reader(file)
for node in res:
print(node.text)
2. 高性能向量检索&检索过滤
使用前在终端运行 pip install chromadb安装chromadb库
import lazyllm
from lazyllm import pipeline, bind, Document, Retriever, OnlineEmbeddingModule, OnlineChatModule, WebModule, SentenceSplitter
prompt = """
You will play the role of an AI Q&A assistant and complete a dialogue task.
In this task, you need to provide your answer based on the given context and question.
"""
# embed_model = OnlineEmbeddingModule(source="qwen", api_key=api_key)
embed_model = OnlineEmbeddingModule(source="qwen",)
store_conf = {
'segment_store': {
'type': 'map',
'kwargs': {
'uri': './db/segment_store_1.db',
},
},
'vector_store': {
'type': 'chromadb',
'kwargs': {
'dir': './db/chromadb_1',
'index_kwargs': {
'hnsw': {
'space': 'cosine',
'ef_construction': 100,
}
}
},
},
}
doc = Document(
dataset_path="./docs",
embed=lazyllm.OnlineEmbeddingModule(source='qwen',),
manager=False,
store_conf=store_conf
)
doc.create_node_group(name="sentences", transform=SentenceSplitter, chunk_size=1024, chunk_overlap=100)
with pipeline() as ppl:
ppl.retriever = Retriever(doc, group_name='sentences', similarity="cosine", topk=6, output_format='content')
ppl.formatter = (lambda context, query: dict(context_str=str(context), query=query)) | bind(query=ppl.input)
ppl.llm = OnlineChatModule(source='qwen', stream=True).prompt(lazyllm.ChatPrompter(prompt, extra_keys=["context_str"]))
w = WebModule(m=ppl, stream=True)
w.start().wait()
3.多路召回重排
# rerank_rag.py
import lazyllm
from lazyllm import pipeline, bind, OnlineEmbeddingModule, SentenceSplitter, Retriever, Reranker
from lazyllm.tools.rag import Document
# 目前 LazyLLM 支持 qwen和glm 在线重排模型,使用前请指定相应的 API key。
doc=Document(dataset_path="./docs",
embed=OnlineEmbeddingModule(source="qwen", embed_model_name="text-embedding-v4"), manager=False)
online_rerank = OnlineEmbeddingModule(source="qwen",type="rerank")
rerank_model=lazyllm.OnlineEmbeddingModule(type="rerank", source="qwen",
)
reranker = Reranker('ModuleReranker', model=online_rerank, topk=3)
prompt="""
"""
with pipeline() as ppl:
with lazyllm.parallel().sum as ppl.prl:
prl.r1 = Retriever(doc, group_name='line', similarity="cosine", topk=6, target='block')
prl.r2 = Retriever(doc, group_name='block', similarity="cosine", topk=6)
ppl.reranker = Reranker('ModuleReranker', model=rerank_model, output_format='content',
join=True) | bind(query=ppl.input)
# 添加打印重排结果的模块
def print_rerank_results(context, query):
print("\n=== 重排结果 ===")
print(f"查询: {query}")
if isinstance(context, list):
for i, item in enumerate(context, 1):
print(f"\n排名 {i}:")
print(f"内容: {item}")
else:
print(f"内容: {context}")
print("================\n")
return context
ppl.print_results = print_rerank_results | bind(query=ppl.input)
ppl.formatter = (lambda context, query: dict(context_str=str(context), query=query)) | bind(query=ppl.input)
ppl.llm = lazyllm.OnlineChatModule(source='qwen', stream=True).prompt(lazyllm.ChatPrompter(prompt, extra_keys=["context_str"]))
ppl.start()
4. Query改写
4.1 子问题查询
import lazyllm
llm = lazyllm.OnlineChatModule(source="qwen")
prompt = "你是一个查询重写助手,如果用户查询较为抽象或笼统,将其分解为多个角度的具体问题。\
注意,你不需要进行回答,只需要根据问题的字面进行子问题拆分,输出不要超过3条.\
下面是一个简单的例子:\
输入:RAG是什么?\
输出:RAG的定义是什么?\
RAG是什么领域内的名词?\
RAG有什么特点?"
query_rewriter = llm.prompt(lazyllm.ChatPrompter(instruction=prompt))
print(query_rewriter("有哪些健康饮食的建议"))
4.2 多步骤查询
import lazyllm
from lazyllm import Document, ChatPrompter, Retriever
# prompt设计
rewrite_prompt = "你是一个查询改写助手,将用户的查询改写的更加清晰。\
注意,你不需要对问题进行回答,只需要对原问题进行改写.\
下面是一个简单的例子:\
输入:RAG\
输出:为我介绍下RAG\
用户输入为:"
judge_prompt = "你是一个判别助手,用于判断某个回答能否解决对应的问题。如果回答可以解决问题,则输出True,否则输出False。 \
注意,你的输出只能是True或者False。不要带有任何其他输出。 \
当前回答为{context_str} \n"
robot_prompt = '你是一个友好的 AI 问答助手,你需要根据给定的上下文和问题提供答案。\
根据以下资料回答问题:\
{context_str} \n '
# 加载文档库,定义检索器在线大模型,
documents = Document(dataset_path="./docs")
retriever = Retriever(doc=documents, group_name="CoarseChunk", similarity="bm25_chinese", topk=3)
llm = lazyllm.OnlineChatModule(source='qwen', model='qwen-turbo')
# 重写查询的LLM
rewrite_robot = llm.share(ChatPrompter(instruction=rewrite_prompt))
# 根据问题和查询结果进行回答的LLM
robot = llm.share(ChatPrompter(instruction=robot_prompt, extra_keys=['context_str']))
# 用于判断当前回复是否满足query要求的LLM
judge_robot = llm.share(ChatPrompter(instruction=judge_prompt, extra_keys=['context_str']))
# 推理
query = ""
LLM_JUDGE = False
while LLM_JUDGE is not True:
query_rewrite = rewrite_robot(query) # 执行查询重写
print('\n重写的查询:', query_rewrite)
doc_node_list = retriever(query_rewrite) # 得到重写后的查询结果
res = robot({"query": query_rewrite, "context_str": "\n".join([node.get_content() for node in doc_node_list])})
# 判断判断当前回复是否能满足query要求
LLM_JUDGE = bool(judge_robot({"query": query, "context_str": res}))
print(f"\nLLM判断结果:{LLM_JUDGE}")
# 打印结果
print('\n最终回复: ', res)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)