企业级数据分析Agentic实践,如何让LLM更懂你的数据(集成Finebi)
本文提出了一套智能BI落地方案,重点解决数据治理和LLM理解问题。核心设计包括数据应用分段、描述总结、案例SQL参考及元数据完善,并基于OpenMetadata平台实现资产同步。架构采用三层设计(UI、BLL、DAL),结合LangGraph多Agent系统处理不同场景问题,如数据查询、BI看板获取等。通过钉钉集成权限控制,优化了企业级数据交互效率,案例验证了非数据问题过滤、数据应用路由等功能的实
智能BI落地的难点,在于对于结果的准确度要高,主要工作会包含数据治理,而非rag知识库搭建,在BI场景中rag知识库可用于企业黑话描述(企业中的术语),来优化LLM理解用户问题。基于这个实现背景下,方案设计如下。
一、核心思想
数据仓库中有上千甚至上万张表,进行分层存储,但是大部分进行数据应用时,只会使用到“应用集市层(ads/dm层)” 或者 “预聚合层(dws层)” 中的几张表。
基于这个思想我们做了以下几个数据治理动作(很重要):
1. 分段:设计了数据应用概念,每个数据应用中包含多张表(其实用一张宽表对LLM更好,但是不灵活),这个动作和rag知识库录入时的分段很像。
2. 总结:对数据应用进行描述,类似于给rag段进行总结,LLM进行选择(检索)数据应用时,基于描述选择最适合的应用来解决问题
3. 案例sql:给数据应用添加案例sql,prompt中暗示LLM一定要参考案例sql进行问题解决
4. 完善资产:数仓中有些表的描述、血缘不太清楚或者缺失,完善数据表的字段描述含义、不同表之间的字段关联方式。
基于以上设计,评估自研工具和调研开源工具后,引入了OpenMetadata平台,有开源和商业两种方案,以下OpenMetadata工具截图:
为了获取Finebi中的数据集和BI看板资产,基于OpenMetadata api 自研了Finebi connector来同步元数据
二、架构设计
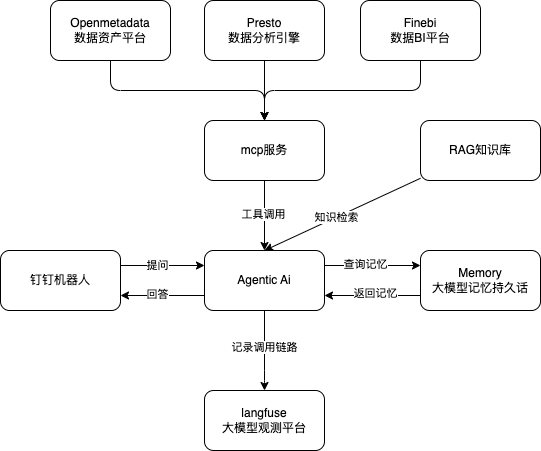
2.1、整体架构
- 三层架构
- 表示层(UI):
- 钉钉机器人聊天窗口(
- 按照企业日常工作工具进行选择,例如企业微信,slack等
- 业务逻辑层(BLL):
- 使用langgraph,dify api、crewai 等其他ai框架开发的Agentic应用
- 数据访问层(DAL):
- 使用mcp封装了企业资产平台、数仓平台、报表平台等数据,
- RAG知识库按需搭建
- 长短期记忆数据持久化
- 表示层(UI):
- 运维监控
- 模型观测:
- langfuse 记录每个用户的对话记录
- 模型观测:
- 权限控制:
- 钉钉入口获取员工的工号,作为权限识别ID(根据企业日常工具进行定制开发)
三、落地方案
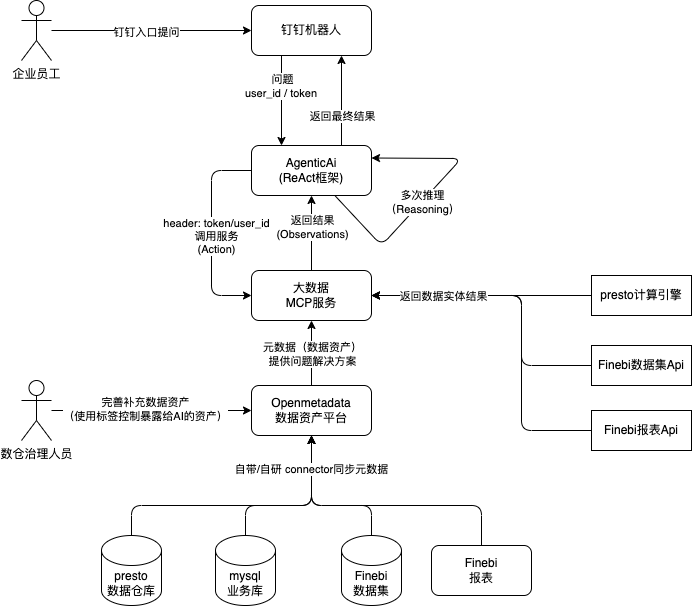
3.1、Langchain ReAct Agentic 实现链路
实现功能:
- 钉钉入口,基于用户id识别权限
- 自助Finebi看板获取
- 基于数据应用的sql生成
- 自助Finebi数据集获取、分析
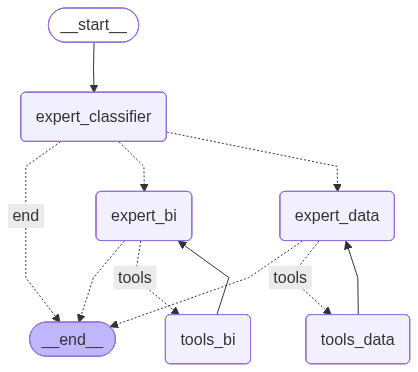
3.2、优化:Langgraph Multi ReAct Agentic 设计
Agentic项目结构:
- agentci_app模块:集成多个ai框架的agent实现
- service模块:集成用户的交互方式,目前实现的钉钉机器人
上面实现链路中【Agentic Ai (React框架)】节点可以用 Multi ReAct Agentic替换,实现更多的“专家角色” 处理不同领域的问题。
- 多agentic方案
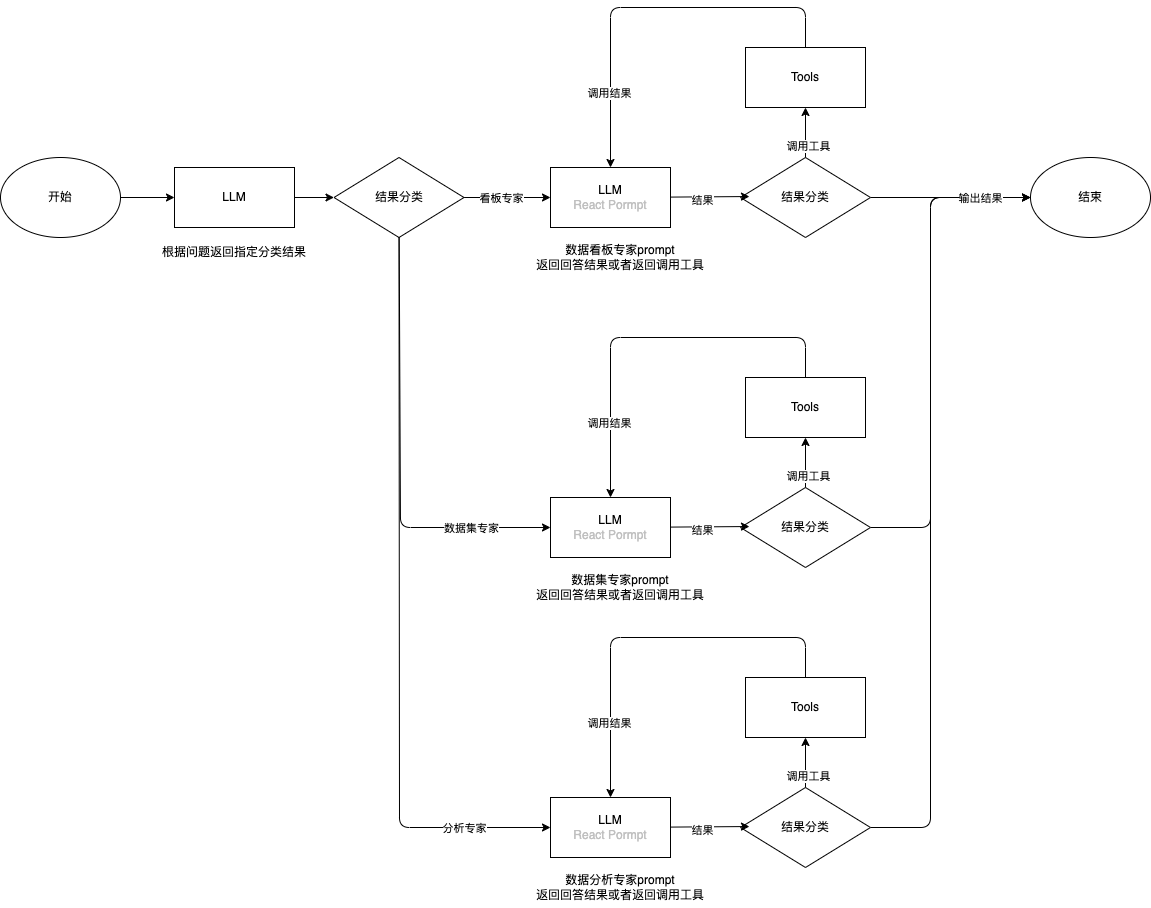
- Langgraph 实现多agent
async def multi_agentic(user_query, user_id):
Langfuse(
secret_key="sk-xxxxx",
public_key="pk-xxxxx",
host="http://xxxxxxx"
)
langfuse = get_client()
langfuse_handler = CallbackHandler()
langfuse.update_current_trace()
# 获取agent和工具
llm = dashcope_llm()
dingding_token = get_dingding_token()
tools = await get_mcp_tools(dingding_token, user_id)
# 用户会话记忆线程id配置
now = datetime.now()
midnight = datetime(year=now.year, month=now.month, day=now.day, tzinfo=now.tzinfo)
timestamp = time.mktime(midnight.timetuple())
config = {
"configurable": {
"thread_id":f"{user_id}{int(timestamp)}_3"
},
"callbacks": [langfuse_handler],
"metadata": {
"langfuse_user_id": "user-id",
}
}
expert_set = {
"expert_bi": "BI专家",
"expert_data": "数据专家",
"expert_classifier": "智能助手"
}
expert_bi = create_short_term_expert_node(llm, bi_prompt, tools)
expert_data = create_short_term_expert_node(llm, data_prompt, tools)
expert_classifier = create_short_term_expert_node(llm, classifier_prompt, [], agent_type="classifier")
# summarization_node = create_summarization_node(llm)
DB_URI = f"postgresql://{os.getenv('PG_USER')}:{os.getenv('PG_PASSWORD')}@{os.getenv('PG_HOST')}:{os.getenv('PG_PORT')}/{os.getenv('PG_DB')}?sslmode=disable"
async with AsyncPostgresSaver.from_conn_string(DB_URI) as checkpointer:
# await store.setup()
# 创建graph
graph_builder = StateGraph(WorkFlowState)
# ********* 添加节点 *********
# graph_builder.add_node("summarize", summarization_node)
graph_builder.add_node("expert_classifier", expert_classifier)
graph_builder.add_node("expert_bi", expert_bi)
graph_builder.add_node("expert_data", expert_data)
graph_builder.add_node("tools_bi", ToolNode(tools))
graph_builder.add_node("tools_data", ToolNode(tools))
# ********* 添加边 *********
# graph_builder.add_edge(START, "summarize")
# graph_builder.add_edge("summarize", "expert_classifier")
graph_builder.add_edge(START, "expert_classifier")
# 路由决策,问题分类
graph_builder.add_conditional_edges(
"expert_classifier",
question_classifier_router,
{
"expert_bi": "expert_bi",
"expert_data": "expert_data",
"end": END,
},
)
# BI 专家:1、路由决策,是否需要调用工具 2、 反馈思考
graph_builder.add_conditional_edges("expert_bi",
tools_condition,
{
"tools":"tools_bi",
END:END
}
)
graph_builder.add_edge("tools_bi", "expert_bi")
# 数据 专家:1、路由决策,是否需要调用工具 2、 反馈思考
graph_builder.add_conditional_edges("expert_data",
tools_condition,
{
"tools": "tools_data",
END: END
}
)
graph_builder.add_edge("tools_data", "expert_data")
# 编译
graph = graph_builder.compile(
checkpointer=checkpointer
)
result = ""
total_tokens = 0
expert = "智能助手"
async for chunk in graph.astream({"messages": [{"role": "user", "content": user_query}], "next_agent":"", "iter_count": 0},
stream_mode='values',
config=config
):
for msg in chunk["messages"][-1:]:
try:
expert = expert_set[chunk.get("next_agent", "expert_classifier")]
except Exception as e:
print(e)
pass
if msg.type == "tool":
yield f"{msg.name} tool calling..."
if msg.type == "ai":
result = msg.text()
try:
total_tokens = msg.usage_metadata["total_tokens"]
# model = msg.response_metadata["model_name"]
except Exception as e:
print(e)
pass
yield f"{expert} thinking..."
langfuse.flush()
yield f"【{expert}】:\n\n{result}\n\ntotal_tokens: {total_tokens}"
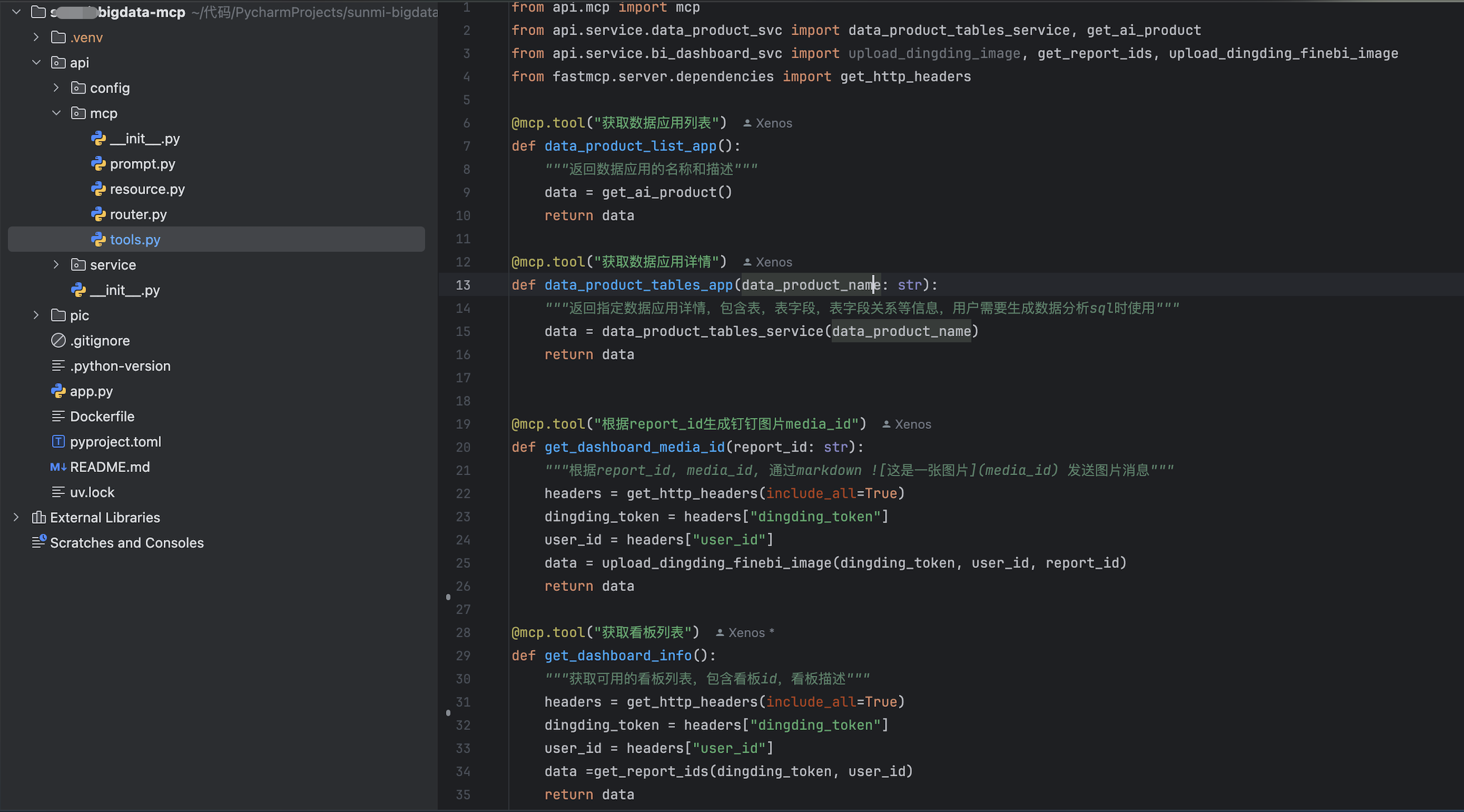
3.3、mcp开发
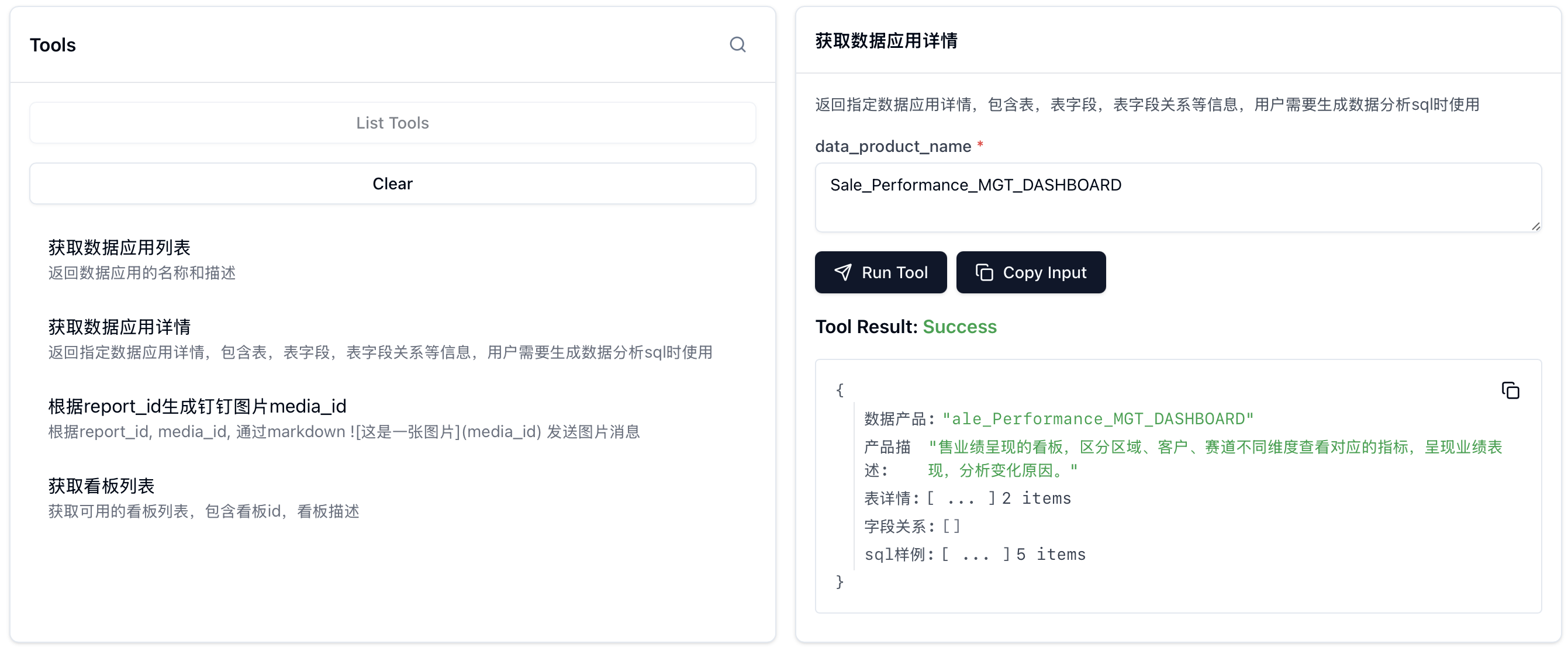
四、案例展示
-
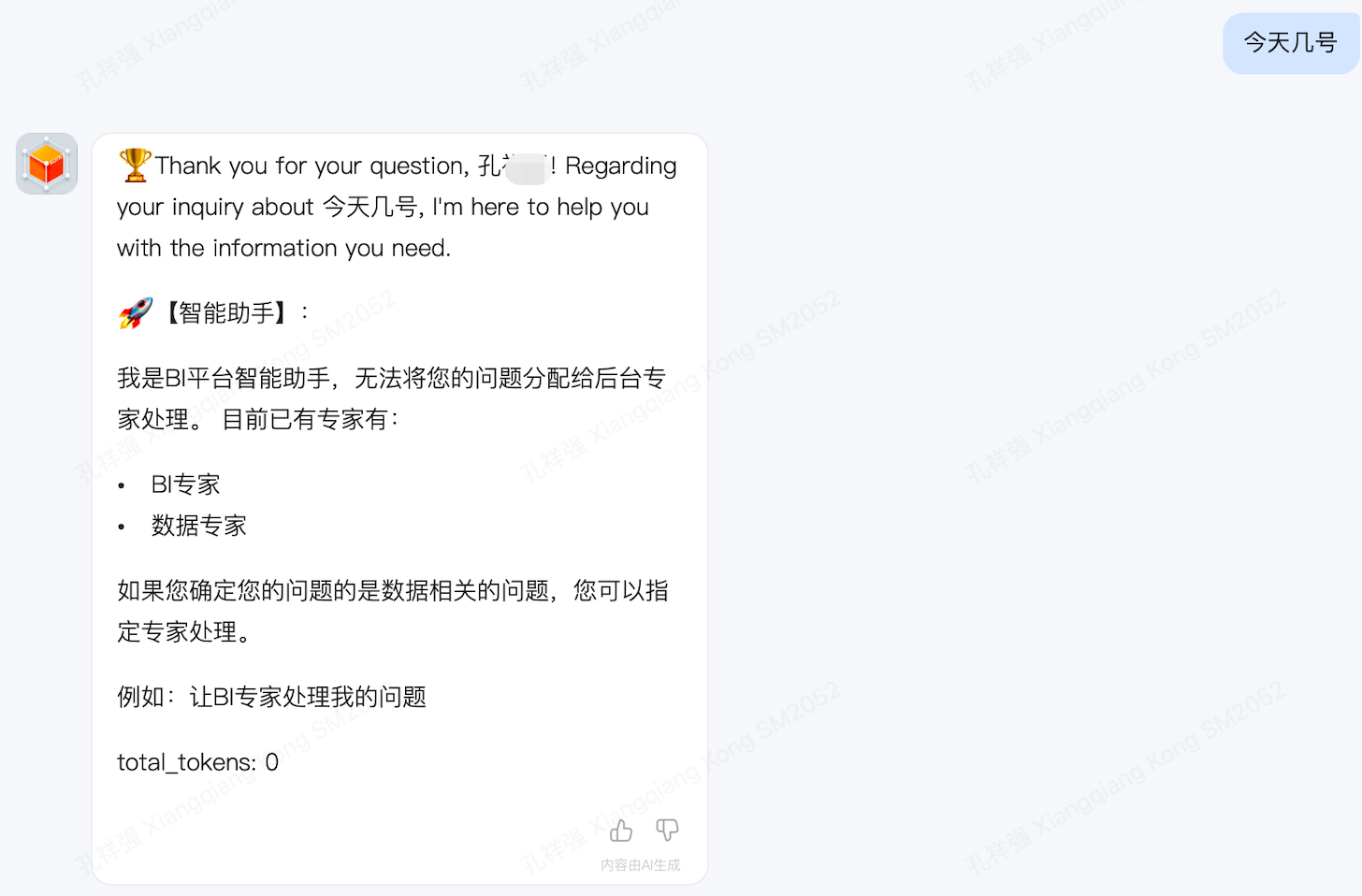
非数据相关问题
- 举例:今天天气怎么样
- 期望结果:不路由到后台专家agent,直接返回
-
数据应用问题
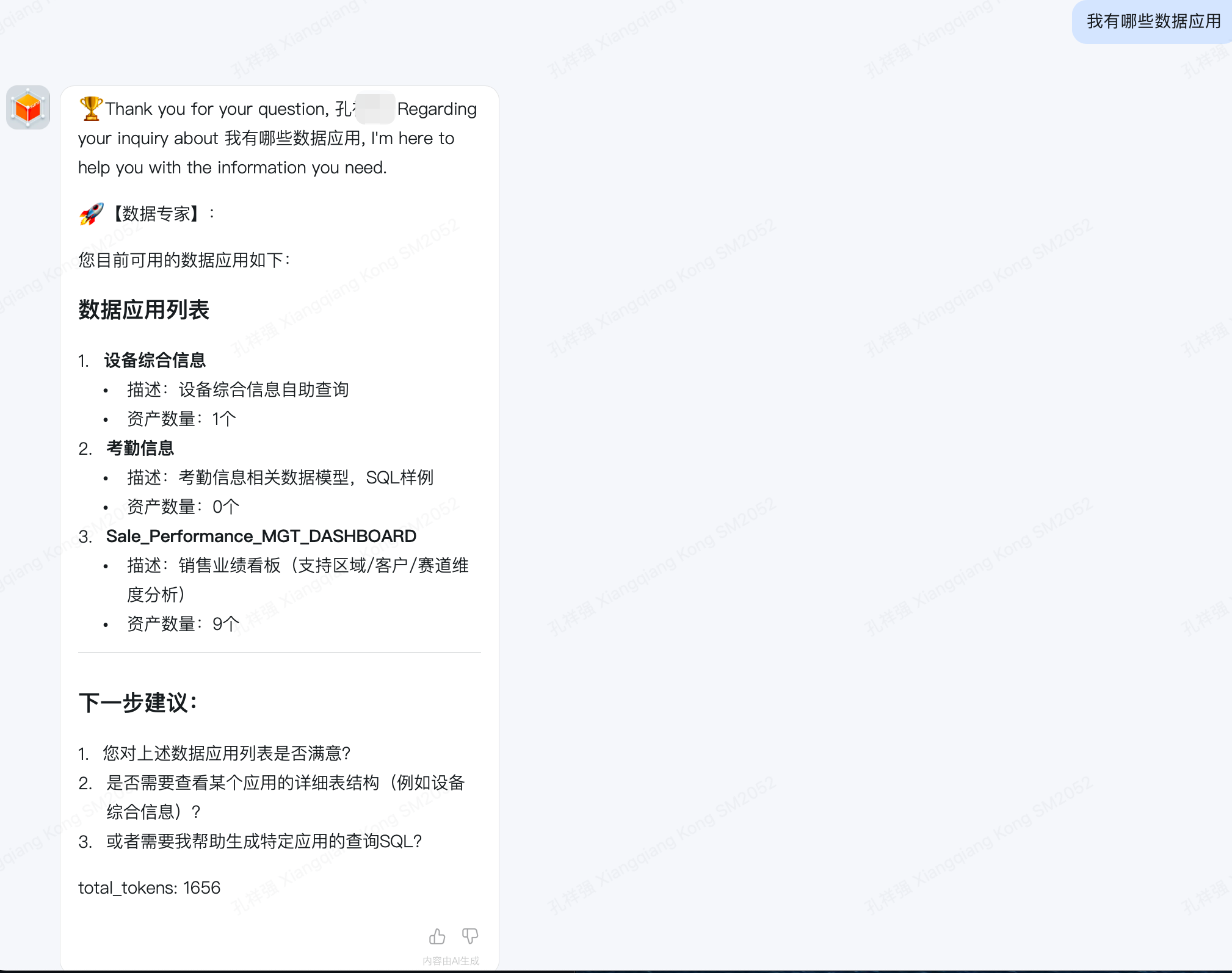
- 举例:我有哪些数据应用
- 期望结果:数据专家回答,并返回用户权限下的数据应用信息
-
BI相关问题
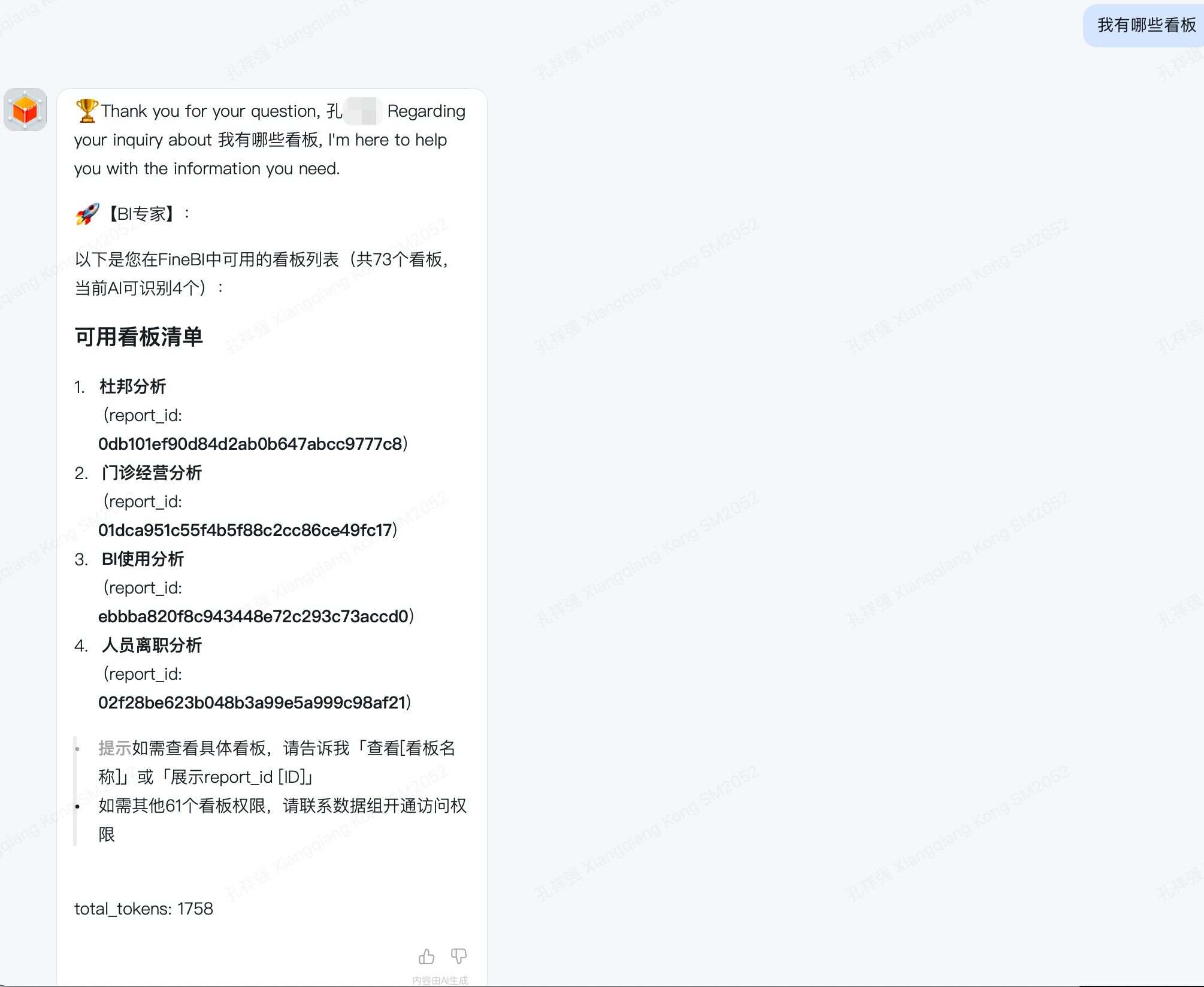
- 举例:我有哪些看板
- 期望结果:BI专家回答,并返回用户权限下的看板
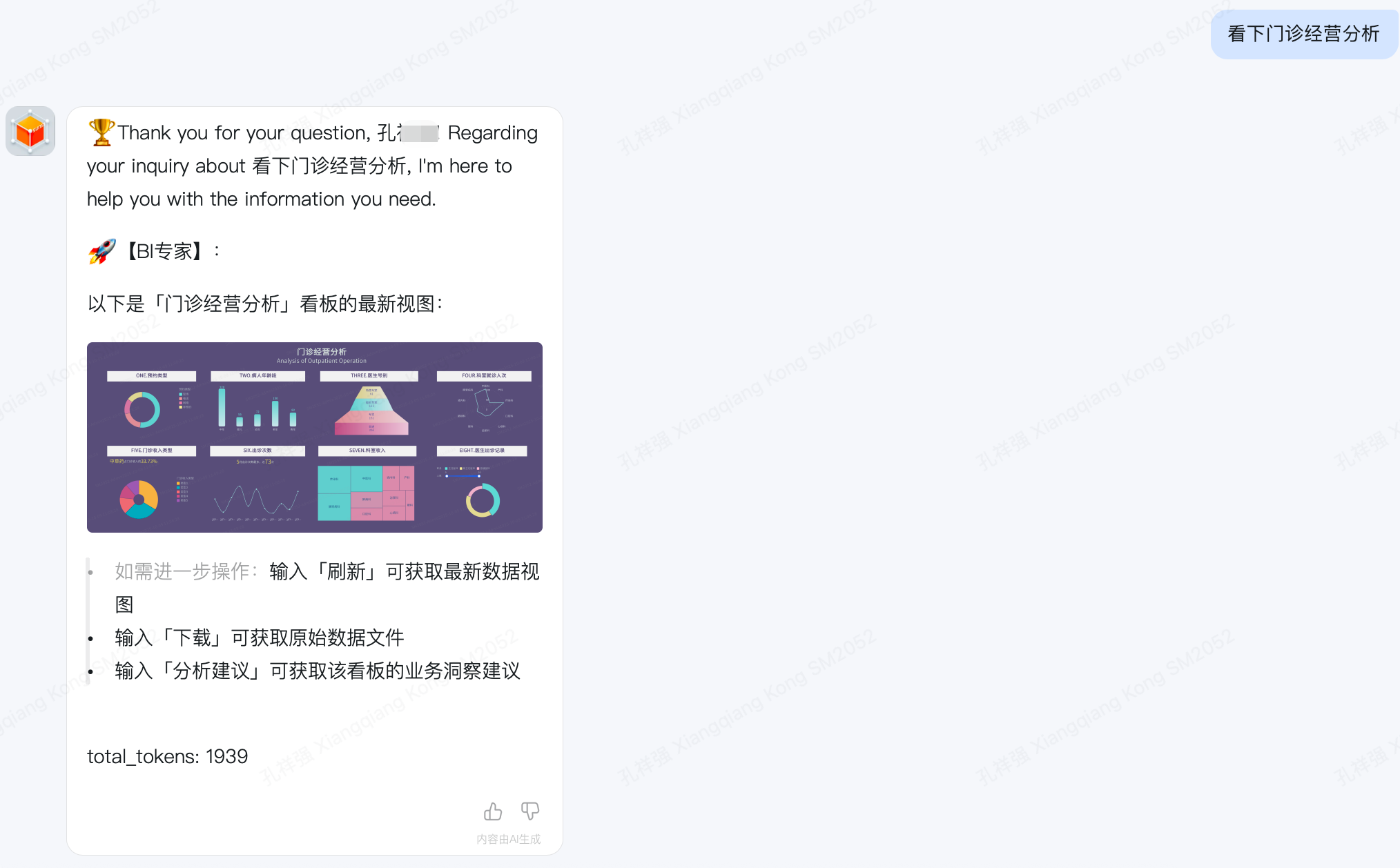
- 举例:看下门诊经营分析
- 期望结果:BI专家回答,并返回用户所需看板
-
指定专家处理问题
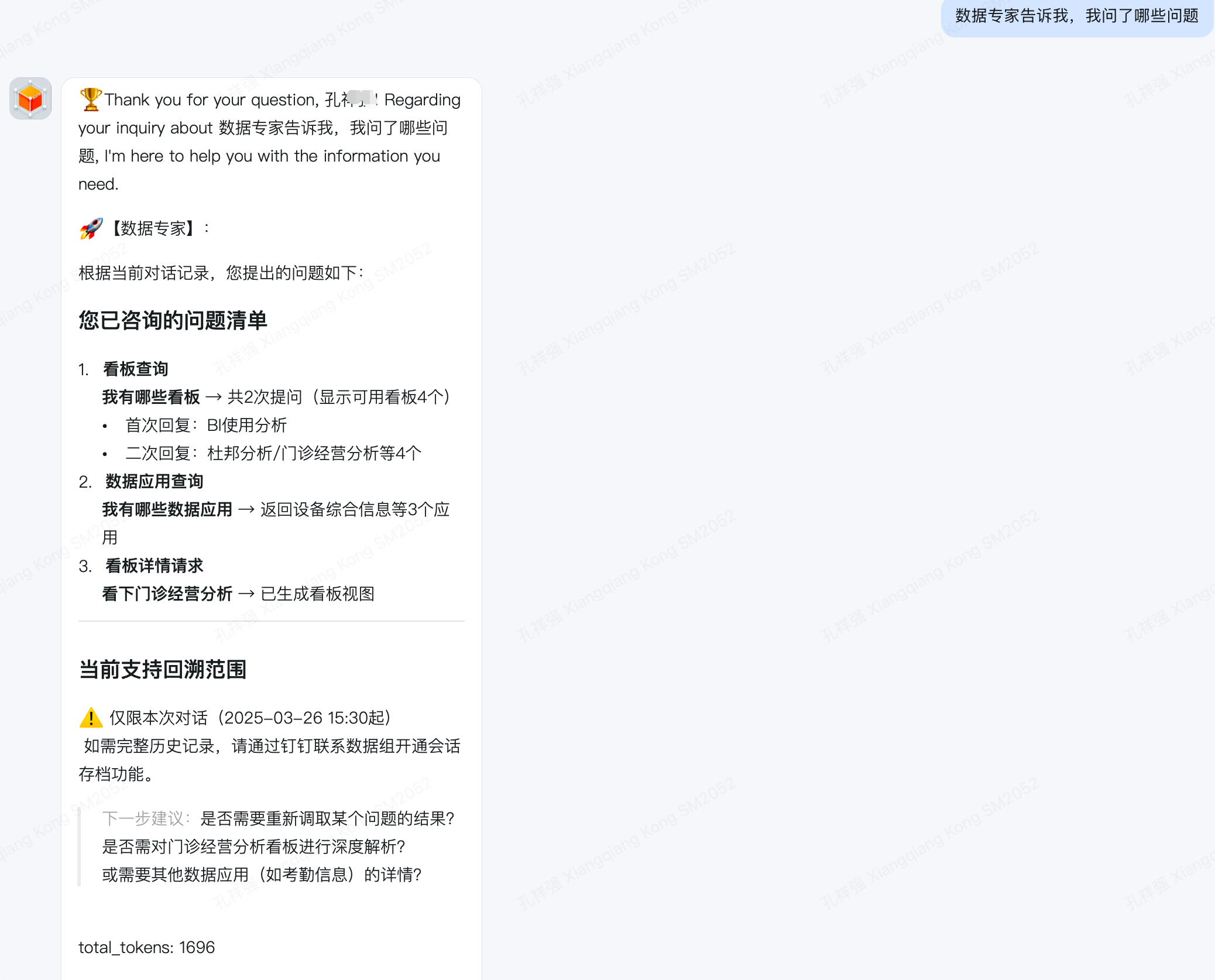
- 举例:数据专家告诉我,我问了哪些问题
- 期望结果:数据专家回答问题(目前记忆按自然天存储,考虑到成本及数据时效性,配置只拉取当天记忆)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)