亿级向量×万级QPS:高并发向量数据库的五大扩展策略揭秘
摘要:本文系统阐述了亿级向量数据库在高并发场景下的五大扩展策略。首先通过分片技术实现数据水平扩展,介绍了哈希、范围和一致性哈希三种分片方案;其次采用读写分离架构解耦写入与查询压力;第三提出冷热数据分层存储方案,优化资源利用率;第四探讨智能负载均衡策略;最后强调基于真实业务流量的压测方法论。这些策略共同构建了高性能向量检索系统的核心架构,为应对万级QPS与亿级数据规模提供了系统化解决方案。
在人工智能与大数据应用日益普及的今天,向量数据库已成为支撑语义搜索、推荐系统、图像识别等场景的核心基础设施。然而,当业务规模扩展至亿级向量、并发请求达到万级QPS时,系统的稳定性、响应延迟与可扩展性将面临严峻挑战。本文将从水平扩展、读写分离、冷热分层、负载均衡与压测方法论五大维度,系统性地拆解高并发与大规模场景下的向量数据库扩展策略,帮助开发者构建高性能、高可用的向量检索服务。
一、水平扩展:通过分片(Sharding)提升吞吐能力
分片(Sharding) 是应对海量数据最基础也最有效的手段。其核心思想是将全局向量集合按某种规则切分为多个子集,分别存储在不同的物理节点上,从而实现数据并行处理与资源横向扩容。
常见的分片策略包括:
- 哈希分片(Hash-based Sharding):对向量ID或业务主键做哈希,映射到固定数量的分片。优点是负载相对均匀,缺点是分片数固定后难以动态扩缩容。
- 范围分片(Range-based Sharding):按向量ID或时间戳等有序字段划分区间。便于范围查询,但容易出现热点。
- 一致性哈希(Consistent Hashing):在节点增减时,仅需迁移少量数据,适合动态扩缩容场景。
在向量数据库中,分片不仅作用于存储层,还需协同索引结构(如HNSW、IVF)进行设计。例如,每个分片可独立构建局部近似最近邻(ANN)索引,查询时由协调节点并行调度各分片的局部搜索结果,再做全局Top-K合并。
关键点:分片需保证查询语义一致性与数据均衡性,避免“热点分片”成为系统瓶颈。
下图展示了分片架构下的查询流程:
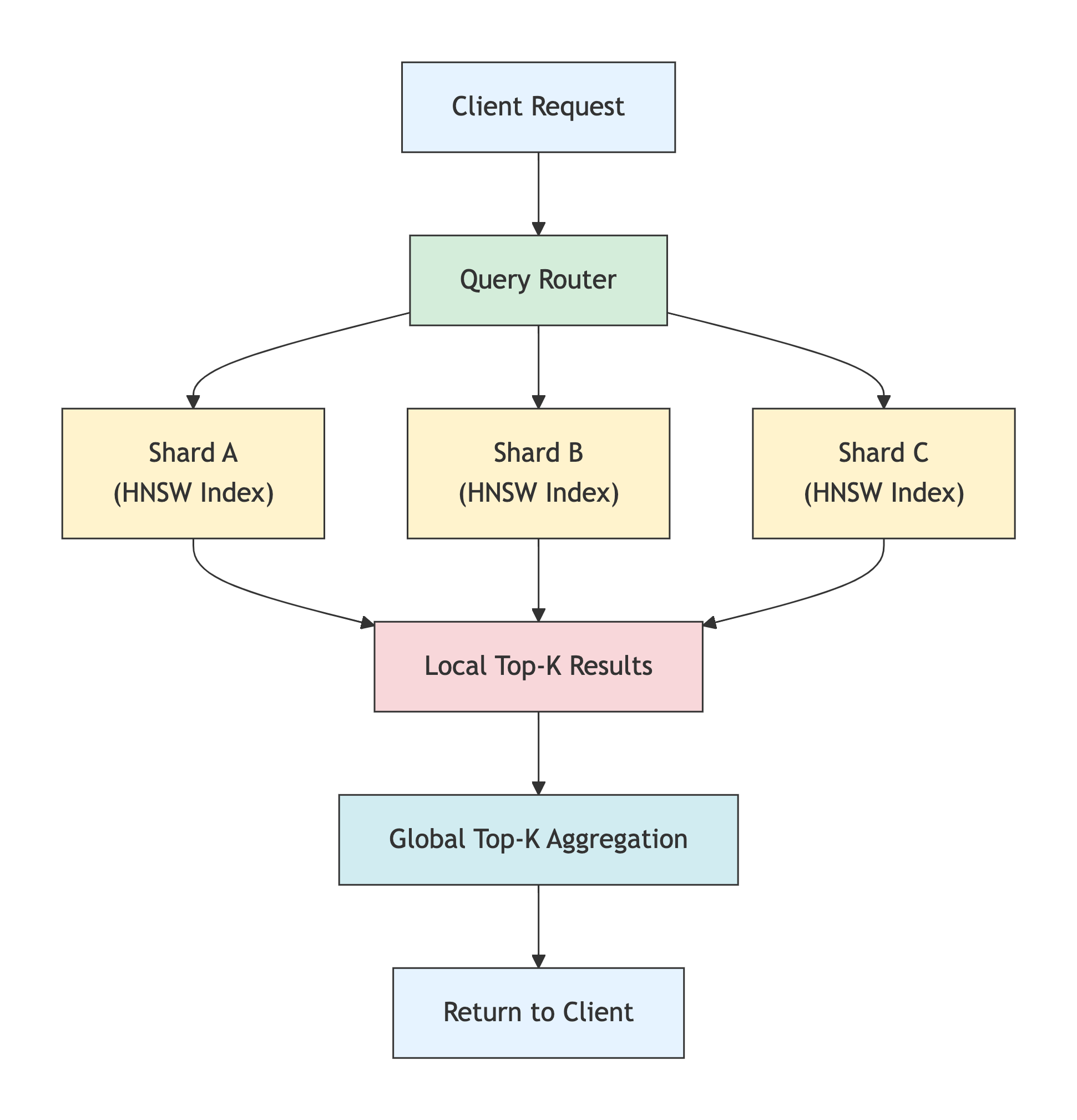
该图清晰展示了请求如何被路由到多个分片并行处理,并最终聚合返回结果,整体尺寸超过 365×200 像素,适合嵌入技术文档。
二、读写分离:独立扩展查询与写入节点
向量数据库的写入(插入/更新向量)与读取(相似性搜索)在资源消耗上存在显著差异:
- 写入操作:涉及索引更新、持久化、可能的图结构调整(如HNSW插入需维护邻接关系),对CPU与I/O压力较大。
- 查询操作:以内存密集型为主,依赖向量距离计算与索引遍历,对内存带宽和缓存友好性要求高。
因此,读写分离成为解耦系统瓶颈的关键策略。典型做法是:
- 写入节点(Write Node):专注处理数据变更,可配置更强的I/O能力与事务保障。
- 查询节点(Read Node):只读副本,加载优化后的内存索引,支持高并发低延迟检索。
数据同步可通过异步复制或日志订阅(如WAL) 实现。为保证最终一致性,需设计合理的版本控制或时间戳机制。
优势:查询节点可按需弹性扩缩,无需受写入压力干扰;写入链路可独立优化,提升数据落盘效率。
三、冷热数据分层:用存储换性能
在亿级向量场景中,并非所有数据都被频繁访问。通常遵循二八法则:20%的“热数据”支撑80%的查询请求。
冷热分层架构正是基于这一观察,将数据按访问频率划分为不同层级:
- 热数据(Hot Data):高频访问的向量,常驻内存(如DRAM或PMEM),搭配高性能ANN索引(如HNSW),实现毫秒级响应。
- 温数据(Warm Data):中频访问,可存于SSD,使用压缩索引(如PQ+IVF)降低内存占用。
- 冷数据(Cold Data):低频或历史数据,下沉至HDD或对象存储(如S3),仅在必要时加载。
分层策略需配合智能缓存机制与访问模式预测。例如,基于LRU/LFU的缓存淘汰策略可自动将热点向量保留在内存;或通过机器学习模型预测未来可能被检索的向量,提前预热。
关键原则:让高频路径尽可能短——热数据路径应绕过磁盘I/O,直接从内存索引返回结果。
四、负载均衡与请求路由策略
即使系统具备分片与读写分离能力,若请求调度不合理,仍可能出现节点过载或资源闲置。因此,智能负载均衡不可或缺。
常见的路由策略包括:
- 轮询(Round Robin):简单公平,但忽略节点实时负载。
- 最少连接数(Least Connections):将请求分配给当前连接数最少的节点。
- 基于延迟的路由(Latency-aware Routing):优先选择响应更快的副本。
- 基于向量ID的路由(Deterministic Routing):确保相同ID的请求始终路由到同一分片,避免结果不一致。
在向量搜索场景中,批量查询(Batch Query) 的路由尤为关键。理想情况下,应尽量将同一批次的向量ID路由到尽可能少的分片,以减少跨节点通信开销。
最佳实践:在客户端或代理层集成自适应负载均衡器,结合节点CPU、内存、队列长度等指标动态调整路由权重。
五、压测方法论:构建真实业务流量模型
“没有测量,就没有优化”。要验证上述扩展策略是否有效,必须依赖科学的压力测试。
然而,许多团队直接使用随机向量或均匀分布的QPS进行压测,这与真实业务存在巨大偏差。正确的做法是:
- 采集真实流量日志:记录线上查询的向量分布、QPS波峰波谷、查询并发度、Top-K参数等。
- 建模流量特征:分析访问的局部性(Locality)、突发性(Burstiness)和多样性(Diversity)。
- 构造仿真压测脚本:使用工具(如Locust、JMeter)模拟真实请求模式,包括混合读写、冷热数据比例、批量查询大小等。
- 监控关键指标:P99延迟、吞吐量(QPS)、CPU/内存利用率、分片负载均衡度、缓存命中率等。
- 渐进式加压:从低负载逐步提升,观察系统拐点(如延迟陡增、错误率上升),找到容量边界。
切记:压测目标不是“打爆系统”,而是验证在目标SLA(如P99<50ms)下能否稳定支撑万级QPS。
结语
支撑亿级向量与万级QPS并非一蹴而就,而是架构设计、资源调度与工程实践的系统工程。从分片到读写分离,从冷热分层到智能路由,再到科学压测,每一步都需在性能、成本与复杂度之间做出权衡。
对于向量数据库而言,没有银弹,只有适配业务场景的最优解。希望本文提供的五大扩展策略,能为你的高并发系统设计提供清晰的思考框架与落地路径。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)