科普文:AI时代DeepSeek【DeepSeek-R1论文:蒸馏技术有效提升小型模型能力】
这篇论文奠定了 DeepSeek 大模型的基础,提出模型参数规模并非越大越好,而是要找到模型参数量、数据量和算力的最优配比,通过分阶段的 Multi-step 学习率下降的方式,在不损失性能的情况下,可以更便捷地进行持续训练。DeepSeek-R1论文是一篇专注于通过强化学习提升大型语言模型(LLMs)推理能力的开创性研究,DeepSeek-R1论文通过纯强化学习训练大型语言模型,实现了推理能力的
玄姐:阿里基于 Spring AI 发布新版本-CSDN博客
OpenAI在2024.7.9终止对中国提供API服务后,国内可替代的API_openai国内替代-CSDN博客
科普文:马里奥AI实现方式探索 ——神经网络+增强学习_神经网络 超级马里奥-CSDN博客
科普文:AI时代DeepSeek【ollama本地傻瓜式安装deepseek-r1】-CSDN博客
DeepSeek 4篇重要论文
DeepSeek 4篇重要论文及工程优化要点:
1.DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
这篇论文奠定了 DeepSeek 大模型的基础,提出模型参数规模并非越大越好,而是要找到模型参数量、数据量和算力的最优配比,通过分阶段的 Multi-step 学习率下降的方式,在不损失性能的情况下,可以更便捷地进行持续训练。
2.DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Multi-Head Latent Attention (MLA):通过对 Key 和 Value 进行低秩压缩,极大地减少了推理时的 KV cache,提高了推理效率,同时性能又比 MHA 更好。
DeepSeekMoE:通过精细化的专家划分和共享专家的隔离,DeepSeekMoE 能够在更低成本下训练更强大的模型。
Device-Limited Routing: 在训练过程中对 MoE 架构进行了改进,实现了训练效率的提升,并在跨节点通信时加入了平衡负载策略。
低成本训练:V2 在性能超越 DeepSeek 67B 的同时,训练成本却降低了 42.5%。
3.DeepSeek V3 Technical Report
辅助损失函数 (Auxiliary Loss) 新策略: 解决了在 MOE 模型训练中,为了平衡负载而引入的辅助损失带来的模型性能损失问题。
Multi-Token Prediction: V3 不再采用传统的单 Token 预测,而是采用多个 token 同时预测,从而提高了模型的整体性能,同时也有利于在推理阶段使用 speculative decoding 来提升推理速度。
FP8 混合精度训练:使用 FP8 混合精度框架训练,并在大规模模型上验证了其可行性和有效性。通过 FP8 计算和存储,训练得到了显著的加速,并减少了 GPU 内存的使用。
DualPipe:通过 DualPipe 算法,显著减少了 pipeline 过程中存在的 bubble,并使得通信过程和计算过程能够高度重叠,大幅提升了训练效率。
高效的跨节点通信: 使用高效的跨节点 all-to-all 通信内核,充分利用 IB 和 NVLink 的带宽,减少训练时的通信开销。
4.DeepSeek R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
不依赖监督微调的 RL:DeepSeek-R1-Zero 直接在 base 模型上运用 RL (强化学习)训练,证明AI大模型可以通过 RL 训练出更强的推理能力,不需要预先经过监督微调的训练。
多阶段强化学习:为了克服 RL 产生的不稳定性,DeepSeek-R1 先使用少量数据进行监督学习,再进行面向推理的强化学习。之后,再通过拒绝采样的方式来做监督微调,并结合全场景的 RL,最终形成了 DeepSeek-R1 模型。
小模型蒸馏:DeepSeek 团队探索了如何把 R1 模型的推理能力迁移到小模型中。他们使用 蒸馏的方法训练了基于 Qwen 和 Llama 的系列小模型。
解读DeepSeek R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1论文是一篇专注于通过强化学习提升大型语言模型(LLMs)推理能力的开创性研究,DeepSeek-R1论文通过纯强化学习训练大型语言模型,实现了推理能力的显著提升,为AI领域的发展带来了新的突破和启示。
论文地址:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
以下是论文的核心要点解读:
一、核心亮点
- 纯强化学习训练:DeepSeek-R1-Zero模型是首个完全没有使用任何监督微调(SFT)数据,仅通过纯粹的强化学习(RL)训练的模型。它打破了传统依赖监督数据提升推理能力的常规,证明了仅通过设计合适的奖励机制和训练模板,模型就能自发地学习到复杂的推理策略。
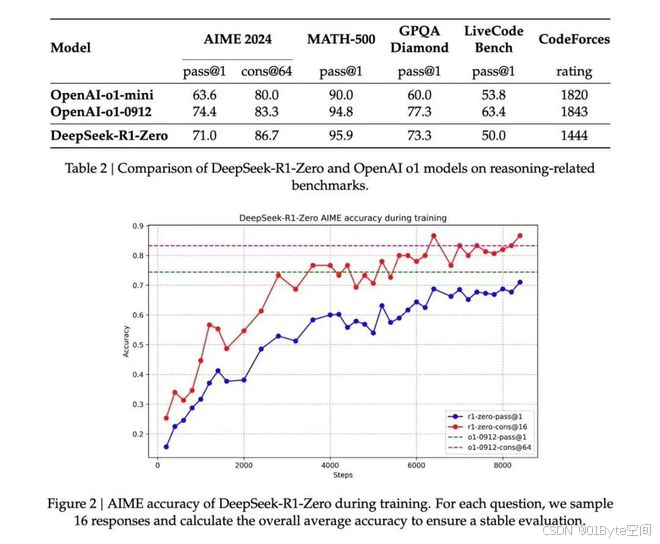
- 惊人的性能提升:在AIME 2024基准测试上,DeepSeek-R1-Zero的pass@1分数从15.6%提升到了71.0%,通过多数投票更是达到了86.7%,与OpenAI的o1系列模型表现相当甚至更好。这种巨大的性能飞跃仅通过强化学习实现,非常令人震撼。
- “顿悟”现象:论文中描述了DeepSeek-R1-Zero在训练过程中出现的“顿悟”现象,即模型会自发地重新评估之前的步骤,并进行反思。这种自发涌现的复杂行为展示了纯强化学习训练的巨大潜力。

二、研究方法
- DeepSeek-R1通过两段式强化学习训练,首先使用无监督或弱监督学习方法提升模型的基础能力,然后通过强化学习进一步优化模型的推理能力。
- 论文中详细探讨了奖励机制的设计,以及如何通过自我博弈和进化策略来激励模型学习到复杂的推理策略。
- 蒸馏技术有效提升小型模型能力
-
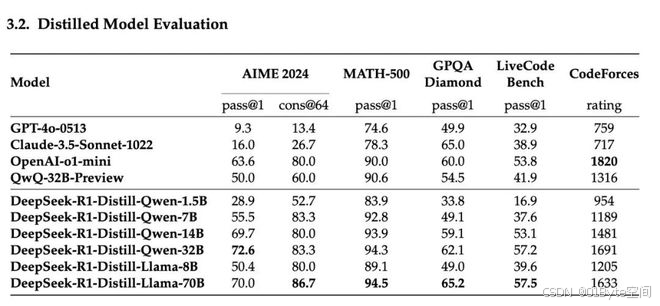
蒸馏效果显著:论文展示了将 DeepSeek-R1 的推理能力蒸馏到较小的模型(如 Qwen 和 Llama 系列)上的显著效果。例如,DeepSeek-R1-Distill-Qwen-7B 在多个基准测试上超过了非推理模型 GPT-40-0513,而 14B 模型则全面超越了 QwQ-32B-Preview。
-
小型模型的巨大潜力:这说明通过合理的蒸馏策略,小型模型也能获得强大的推理能力,为资源受限场景下的应用提供了可能
-
同等规模下,蒸馏优于纯 RL:论文通过对比实验,发现将 DeepSeek-R1 蒸馏到 Qwen-32B 上的效果,远好于直接在 Qwen-32B-Base 上进行大规模 RL 训练。这表明对于较小的模型,直接学习大型模型的推理模式比自身探索更为有效
-
对计算资源的考量:这也暗示了在提升模型能力时,需要综合考虑计算资源和效率,蒸馏在特定情况下可能是更优的选择
-
三、实验与评估
- 实验部分对DeepSeek-R1进行了全面的评估,包括与OpenAI的o1系列模型的对比,以及在多个推理基准测试上的表现。
- 评估结果显示,DeepSeek-R1在多个任务上展现出了与OpenAI-o1相当甚至更好的性能,证明了纯强化学习训练的有效性。
四、未来方向
- 论文最后讨论了未来的研究方向,包括如何进一步优化强化学习算法,以及如何将DeepSeek-R1的方法应用到更多领域,如自动驾驶等。
- 此外,论文还提到了蒸馏与强化学习的比较,以及未成功的尝试,为未来的研究提供了宝贵的经验和教训。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)