牛啊!本地化搭建DeepSeek+RAGFlow,构建个人知识库!【附带详细视频教程】
最近DeepSeek异常火爆,我也积极的体验,研究它的API和模型,确实很Nice,搞私活真的很香,搭建个人的知识库也很爽!今天继续给大家带来手把手的教学,本地化搭建DeepSeek+RAGFlow,构建个人知识库!掌握了本文的方法, 你也可以在骚气的搭建个人知识库,首先要说明下为啥要构建个人知识库呢?在线版DeepSeek需要将数据传输到云端服务器处理,存在日志留存的可能,用户需要信任服务商的隐
最近DeepSeek异常火爆,我也积极的体验,研究它的API和模型,确实很Nice,搞私活真的很香,搭建个人的知识库也很爽!
今天继续给大家带来手把手的教学,本地化搭建DeepSeek+RAGFlow,构建个人知识库!

本文分享的方法全部免费!全程无尿点,实战+手把手教,小白也可以学会!
掌握了本文的方法, 你也可以在骚气的搭建个人知识库,建议点赞、收藏、转发,防止以后找不到。
首先要说明下为啥要构建个人知识库呢?
在线版DeepSeek需要将数据传输到云端服务器处理,存在日志留存的可能,用户需要信任服务商的隐私政策。对于涉及敏感数据的场景,如金融、医疗等行业,数据隐私和合规性要求极高,在线版可能无法满足这些需求。
使用RAG技术(Retrieval-Augmented Generation,检索增强生成)构建个人知识库。本地部署RAG技术所需要的自带Embedding模型的开源框架RAGFlow。
下载地址:
https://github.com/infiniflow/ragflow
下文带来详细的文字教程,当然有些小伙伴需要视频教程,视频教程也已经录制好了,由王汉远亲自录制,王哥是小孟佩服的一名技术员,大家多多三联支持下他的视频,全部都是免费的。
已经出视频教程,免费学习,直接获取,本公众号后台回复:deepseek
废话不多说,我们直接开始教学。
一,安装CUDA,显卡也能参与运算
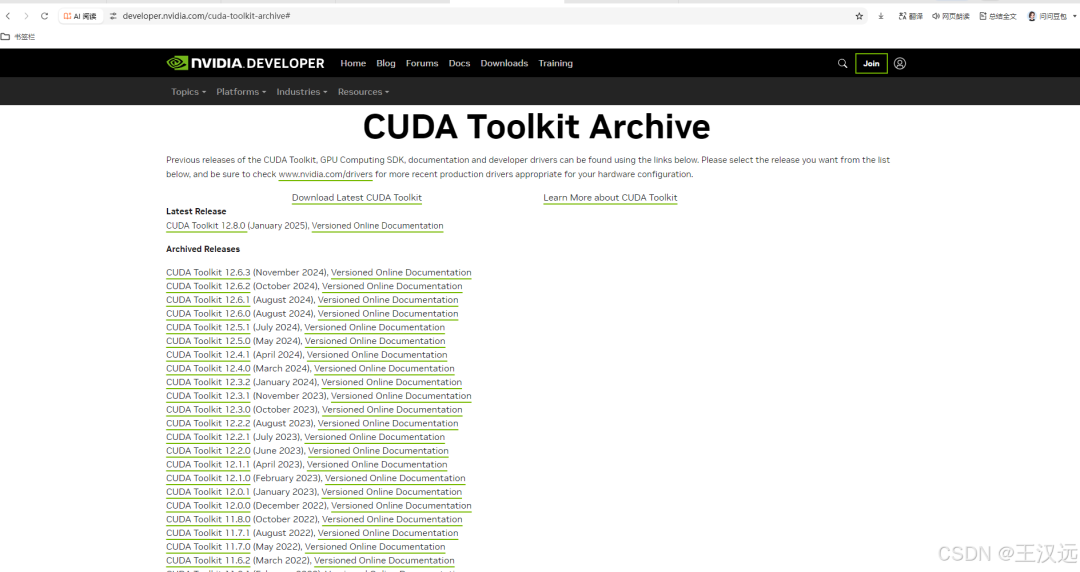
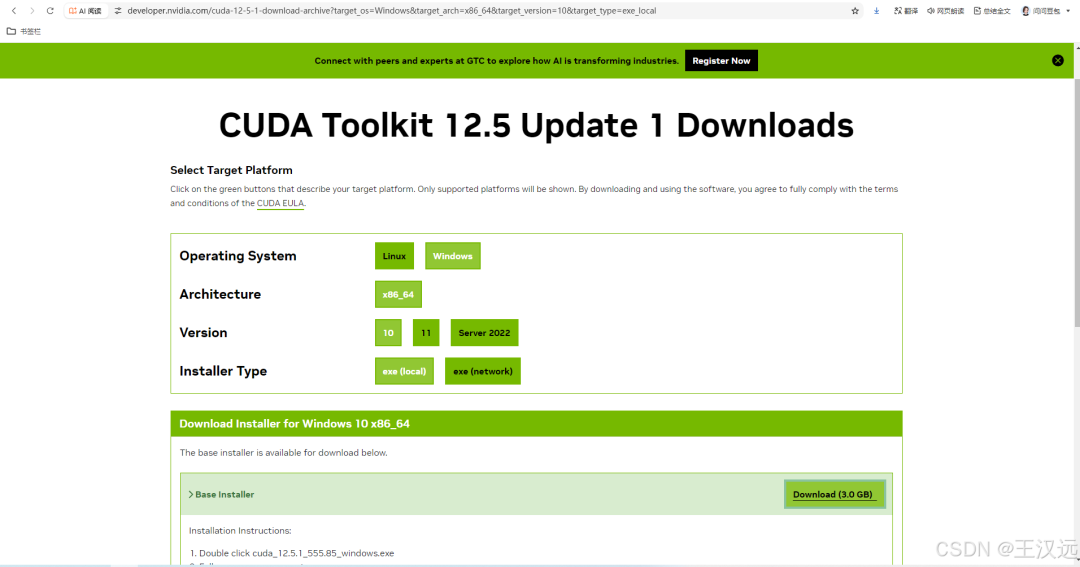
在cmd窗口运行nvidia-smi查看CUDA版本号,然后下载相同版本的cuda toolkit就可以了,只能低于不能高于这个版本。解决ollama不在GPU上跑的问题。
下载地址:
https://developer.nvidia.com/cuda-toolkit-archive
nvcc --version检测安装了CUDA。
二,安装Ollama,用它来运行大模型
Ollama是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。
下载Ollama
环境变量设置:
变量名OLLAMA_HOST 变量值 0.0.0.0
变量名OLLAMA_MODELS,变量值E:\backup\software\ds\ollama
变量名OLLAMA_ORIGINS,变量值*
前面的话,小孟也出了本地部署DeepSeek的教程,大家也可以跟着教程来:
三,运行DeepSeek
deepseek-r1下载地址:
https://ollama.com/library/deepseek-r1
跑一下程序:
四,安装配置Docker
如果是苹果系统的话,选择苹果芯片Apple Silicon或因特尔芯片Intel chip的安装包下载。如果是Windows系统的话,在下面的网站直接下载:
https://docs.docker.com/desktop/setup/install/windows-install/
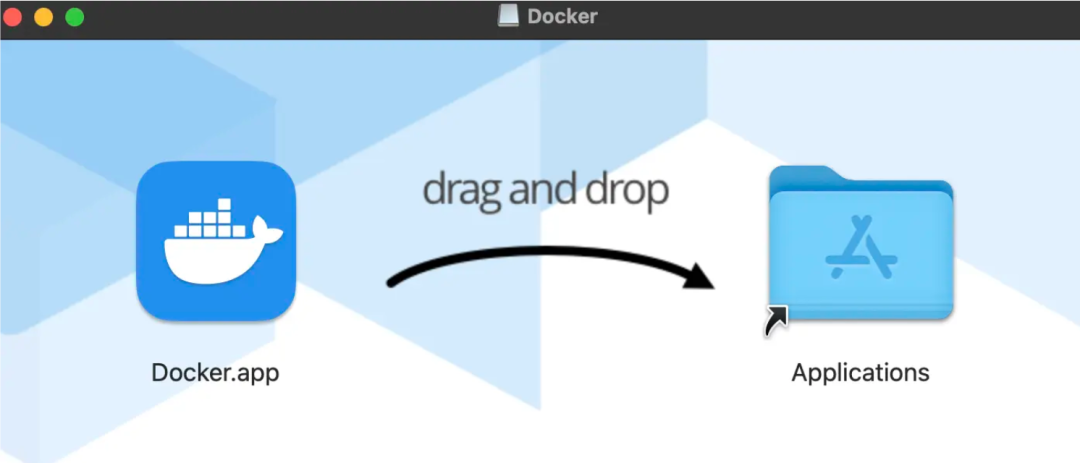
Step1: 下载后,双击Docker.dmg,直接拖拽到Applications文件夹即可完成安装
Step2: 双击Docker.app就可以启动Docker DeskTop
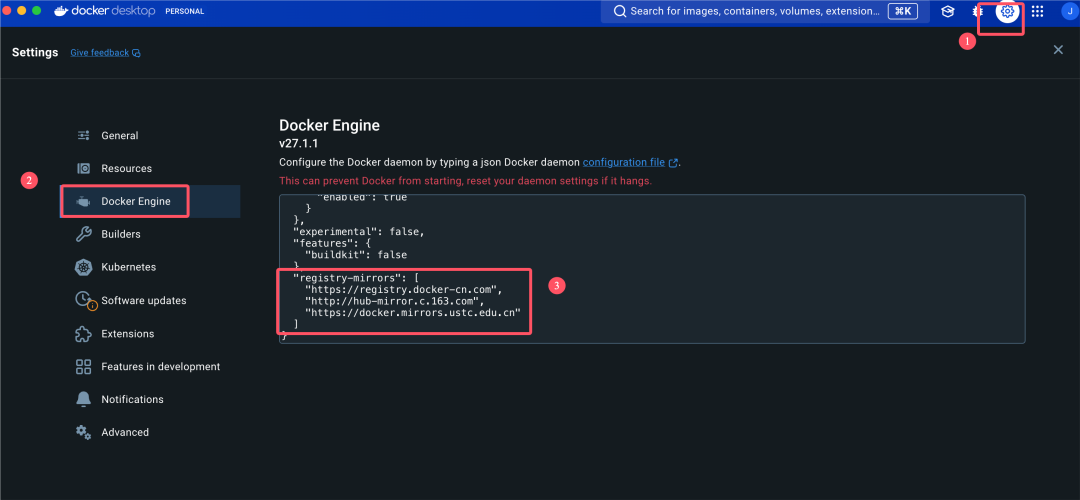
配置 Docker 镜像加速
国内镜像地址,我整理了很多的国内镜像地址,可以直接下方获取使用!!

修改 Docker 配置文件
先点击设置按钮,再点击此处:
测试 & 验证
打开一个命令行窗口 cmd,输入如下命令,没有报错就是安装成功了。
小孟微信:fly996868
# 查看版本
docker --version
# 下载demo镜像并启动容器
docker run hello-world
输出如下则安装成功:
小孟微信:fly996868
ludynice % docker --version
Docker version 24.0.2, build cb74dfc
ludynice % docker run hello-world
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(arm64v8)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
测试无误后,就能够进行后续的docker和docker compose的操作了~
跟到这里你已经战胜了70%的人!
我们继续往下!
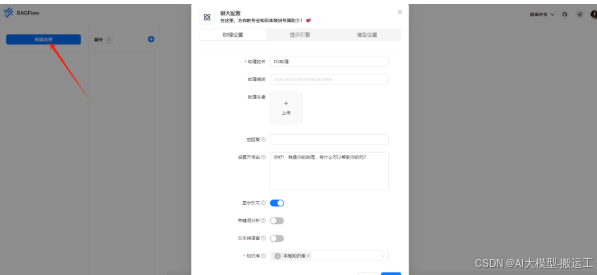
五,用RAGFlow构建个人助
1. 下载RAGFlow
RAGFlow我也给大家整理好了,直接下载。
2.确保 vm.max_map_count 不小于 262144
如需确认 vm.max_map_count 的大小:
sysctl vm.max_map_count
如果 vm.max_map_count 的值小于 262144,可以进行重置,这里我们设为 262144:
sudo sysctl -w vm.max_map_count=262144
你的改动会在下次系统重启时被重置。如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把 vm.max_map_count 的值再相应更新一遍:
vm.max_map_count=262144
3.切换到ragflow目录,执行
docker compose -f docker/docker-compose.yml up -d
以下命令是解决装坏了才要做的,正常不要做:
docker stop $(docker ps -q) # 停止所有正在运行的容器
docker rm $(docker ps -a -q) # 删除所有容器
docker rmi $(docker images -q) # 删除所有镜像
docker volume rm $(docker volume ls -q) # 删除所有卷
docker network prune # 清理未使用的网络
以下命令是切换到ragflow/docker目录,可以重新启动ragflow:
docker compose stop
docker compose up -d
4.服务器启动成功后再次确认服务器状态
docker logs -f ragflow-server
如果出现以下界面提示说明服务器启动成功,恭喜你!
\_\_\_\_ \_\_\_ \_\_\_\_\_\_ \_\_\_\_\_\_ \_\_
/ \_\_ \\ / | / \_\_\_\_// \_\_\_\_// /\_\_\_\_ \_ \_\_
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit
如果您跳过这一步系统确认步骤就登录 RAGFlow,你的浏览器有可能会提示 network anormal 或 网络异常,因为 RAGFlow 可能并未完全启动成功。
在你的浏览器中输入你的服务器对应的 IP 地址并登录 RAGFlow。
上面这个例子中,您只需输入 http://IP_OF_YOUR_MACHINE 即可:未改动过配置则无需输入端口(默认的 HTTP 服务端口 80)。
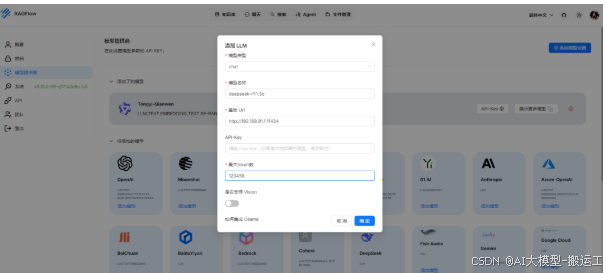
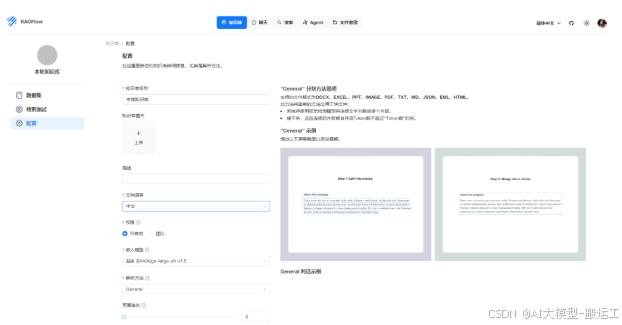
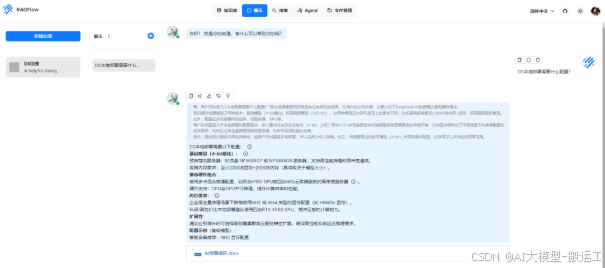
到此,你已经完成了个人知识库的搭建!你又变强了!
除此之外,前面我也更新了很多的DeepSeek教程。
DeepSeek有很多强大的点,也可以集成到IDEA或者Vscode,*
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献154条内容
已为社区贡献154条内容

{kind=link}
所有评论(0)