基于深度强化学习的混合动力汽车能量管理策略探索
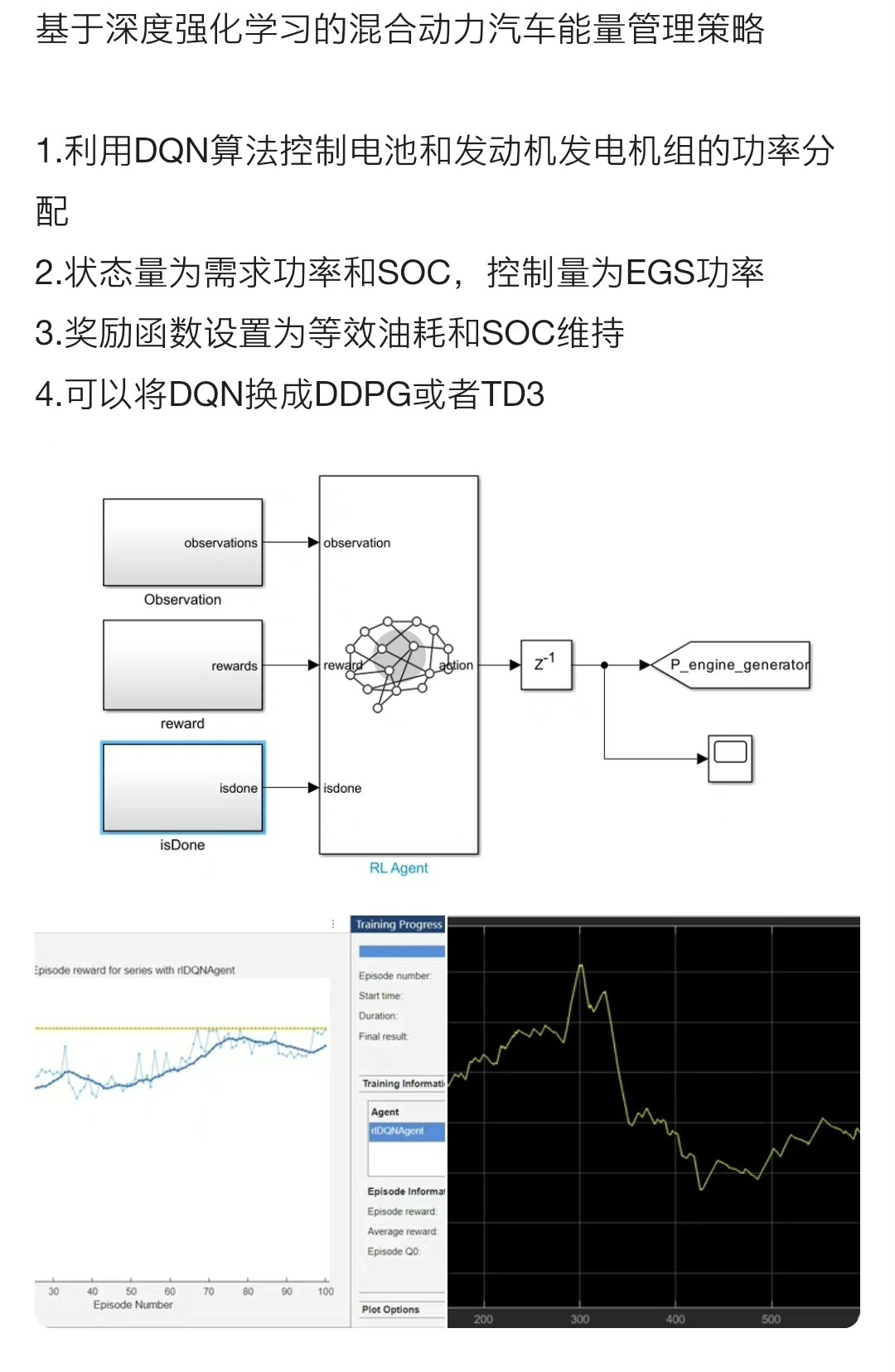
基于深度强化学习的混合动力汽车能量管理策略1.利用DQN算法控制电池和发动机发电机组的功率分配2.状态量为需求功率和SOC,控制量为EGS功率3.奖励函数设置为等效油耗和SOC维持4.可以将DQN换成DDPG或者TD3在当今汽车行业,如何优化混合动力汽车的能量管理策略,提升能源利用效率,成为了众多科研人员和工程师关注的焦点。深度强化学习的出现,为这一领域带来了新的思路和方法。今天咱们就来聊聊基于深
基于深度强化学习的混合动力汽车能量管理策略 1.利用DQN算法控制电池和发动机发电机组的功率分配 2.状态量为需求功率和SOC,控制量为EGS功率 3.奖励函数设置为等效油耗和SOC维持 4.可以将DQN换成DDPG或者TD3
在当今汽车行业,如何优化混合动力汽车的能量管理策略,提升能源利用效率,成为了众多科研人员和工程师关注的焦点。深度强化学习的出现,为这一领域带来了新的思路和方法。今天咱们就来聊聊基于深度强化学习实现混合动力汽车能量管理策略,主要围绕利用DQN算法控制电池和发动机发电机组的功率分配展开。
基于DQN算法的功率分配控制
咱们知道,在混合动力汽车中,电池和发动机发电机组之间的功率分配直接影响着整车的能耗和性能。这里选用DQN(Deep Q - Network)算法来巧妙地处理这一关键问题。
状态量与控制量的设定
在这个系统里,状态量被设定为需求功率和SOC(State of Charge,电池荷电状态)。需求功率很好理解,就是车辆行驶过程中所需要的即时功率,它反映了车辆当前的行驶工况,比如加速、匀速还是减速。而SOC则直观体现了电池剩余电量的情况。这两个状态量就像是给算法装上了“眼睛”,让它能够清晰地“看”到车辆当下的能量需求与电池状态。
控制量被设定为EGS(这里假设EGS为发动机发电机组相关功率控制量)功率。通过调整EGS功率,就能实现电池和发动机发电机组之间功率的合理分配。
奖励函数的重要性
奖励函数在强化学习中扮演着极其重要的角色,它就像是引导智能体(这里的智能体就是我们的算法)行动的“指挥棒”。在混合动力汽车能量管理策略里,奖励函数被设置为等效油耗和SOC维持。
等效油耗很好解释,降低油耗一直是汽车领域追求的目标,通过最小化等效油耗,可以让车辆更加节能。而SOC维持也至关重要,如果SOC过高或过低,都会影响电池的性能和寿命,甚至影响整车的运行。所以,将两者结合作为奖励函数,能引导算法找到一个既节能又能维持电池良好状态的功率分配方案。
简单代码示例及分析
import gym
import numpy as np
import tensorflow as tf
from collections import deque
# 定义DQN网络
class DQN:
def __init__(self, state_size, action_size, learning_rate=0.001):
self.state_size = state_size
self.action_size = action_size
self.learning_rate = learning_rate
self.build_model()
def build_model(self):
self.inputs = tf.keras.layers.Input(shape=(self.state_size,))
x = tf.keras.layers.Dense(24, activation='relu')(self.inputs)
x = tf.keras.layers.Dense(24, activation='relu')(x)
self.q_values = tf.keras.layers.Dense(self.action_size, activation='linear')(x)
self.model = tf.keras.Model(inputs=self.inputs, outputs=self.q_values)
self.model.compile(optimizer=tf.keras.optimizers.Adam(lr=self.learning_rate),
loss='mse')
# 环境模拟(这里简单假设一个环境类)
class HybridCarEnv:
def __init__(self):
self.state = np.array([0.0, 0.0]) # 初始需求功率和SOC
self.action_space = 10 # 假设EGS功率有10种离散取值
self.demand_power_range = [0, 100]
self.soc_range = [0, 1]
def step(self, action):
# 简单模拟功率分配对需求功率和SOC的影响
# 这里是伪代码,实际需要根据车辆动力学等知识精确计算
new_soc = self.state[1] - action * 0.1
new_demand_power = self.state[0] - action * 5
new_state = np.array([new_demand_power, new_soc])
reward = self.calculate_reward(new_state)
done = new_soc < 0 or new_soc > 1 or new_demand_power < 0
self.state = new_state
return new_state, reward, done, {}
def reset(self):
self.state = np.array([np.random.uniform(self.demand_power_range[0], self.demand_power_range[1]),
np.random.uniform(self.soc_range[0], self.soc_range[1])])
return self.state
def calculate_reward(self, state):
demand_power, soc = state
# 简单计算等效油耗和SOC维持的奖励
# 实际需更精确模型
fuel_consumption = demand_power * 0.01
soc_penalty = abs(soc - 0.5) * 10
reward = -fuel_consumption - soc_penalty
return reward
# 训练过程
def train_dqn(env, dqn, episodes=1000, gamma=0.95, batch_size=32):
memory = deque(maxlen=10000)
for episode in range(episodes):
state = env.reset()
state = np.reshape(state, [1, dqn.state_size])
done = False
while not done:
action = np.argmax(dqn.model.predict(state))
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, dqn.state_size])
memory.append((state, action, reward, next_state, done))
state = next_state
if len(memory) > batch_size:
minibatch = random.sample(memory, batch_size)
states = np.array([i[0] for i in minibatch])
actions = np.array([i[1] for i in minibatch])
rewards = np.array([i[2] for i in minibatch])
next_states = np.array([i[3] for i in minibatch])
dones = np.array([i[4] for i in minibatch])
target = rewards + (1 - dones) * gamma * np.amax(dqn.model.predict(next_states), axis=1)
target_f = dqn.model.predict(states)
for i in range(len(minibatch)):
target_f[i][actions[i]] = target[i]
dqn.model.fit(states, target_f, epochs=1, verbose=0)
if episode % 100 == 0:
print(f'Episode {episode}, average reward: {np.mean([i[2] for i in memory])}')
# 初始化环境和DQN
env = HybridCarEnv()
state_size = 2
action_size = env.action_space
dqn = DQN(state_size, action_size)
train_dqn(env, dqn)在这段代码里,首先定义了一个简单的DQN网络结构。DQN类中的build_model方法构建了一个包含两个隐藏层的神经网络,输入是状态量(需求功率和SOC,共两个维度),输出是对应不同EGS功率取值的Q值,也就是每个可能行动的预估回报。
HybridCarEnv类模拟了混合动力汽车的环境。step方法根据采取的EGS功率行动,更新需求功率和SOC,并计算奖励值。calculate_reward方法根据新的状态,简单计算等效油耗和SOC维持相关的奖励。这里的计算都是简化的,实际中需要更精确的车辆模型。
train_dqn函数则是整个训练过程,它使用经验回放(memory存储过往的经验)来训练DQN网络。每次从经验池中随机抽取一批数据(minibatch),计算目标Q值并更新网络,逐步优化功率分配策略。
可替换算法:DDPG与TD3
当然,除了DQN算法,我们还可以考虑使用DDPG(Deep Deterministic Policy Gradient)或者TD3(Twin Delayed DDPG)算法。
DDPG是基于DQN发展而来的,适用于连续动作空间的问题。在混合动力汽车功率分配场景中,如果EGS功率是连续变化的,DDPG就更有优势。它采用了Actor - Critic架构,Actor网络负责输出连续的动作(即EGS功率值),Critic网络则评估Actor输出动作的好坏,通过两者的交互学习,不断优化功率分配策略。
TD3则是在DDPG基础上进行改进的算法。它引入了两个Critic网络(双Q网络)来减少过估计问题,同时采用延迟更新策略,让Actor网络更新得更稳定。在实际应用中,如果环境噪声较大或者存在一些不确定性,TD3可能会表现得更加鲁棒,能让混合动力汽车在复杂工况下也能实现较好的能量管理。
总之,基于深度强化学习的混合动力汽车能量管理策略有着广阔的研究和应用前景,通过合理选择算法和精心设计状态量、控制量以及奖励函数,有望大幅提升混合动力汽车的能源利用效率。大家一起探索,说不定能在这个领域搞出更多创新成果!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)