4090单卡跑满血版DeepSeek-R1!清华团队开源项目再破大模型推理门槛!
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【Mamba/多模态/扩散】交流群添加微信号:CVer2233,小助手会拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!转载自:量子位DeepSeek-R1火遍海内外,但推理服务器频频宕机,专享版按GPU小
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

转载自:量子位
DeepSeek-R1火遍海内外,但推理服务器频频宕机,专享版按GPU小时计费的天价成本更让中小团队望而却步。
而市面上所谓“本地部署”方案,多为参数量缩水90%的蒸馏版,背后原因是671B参数的MoE架构对显存要求极高——即便用8卡A100也难以负荷。因此,想在本地小规模硬件上跑真正的DeepSeek-R1,被认为基本不可能。
但就在近期,清华大学KVCache.AI团队联合趋境科技发布的KTransformers开源项目公布更新:
支持24G显存在本地运行DeepSeek-R1、V3的671B满血版。预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。
其实早在DeepSeek-V2 时代,这个项目就因“专家卸载”技术而备受关注——它支持了236B的大模型在仅有24GB显存的消费级显卡上流畅运行,把显存需求砍到10分之一。
△HuggingFace 的开源负责人的点赞
随着DeepSeek-R1的发布,社区的需求迅速激增,在GitHub盖起上百楼的issue,呼吁对其进行支持。
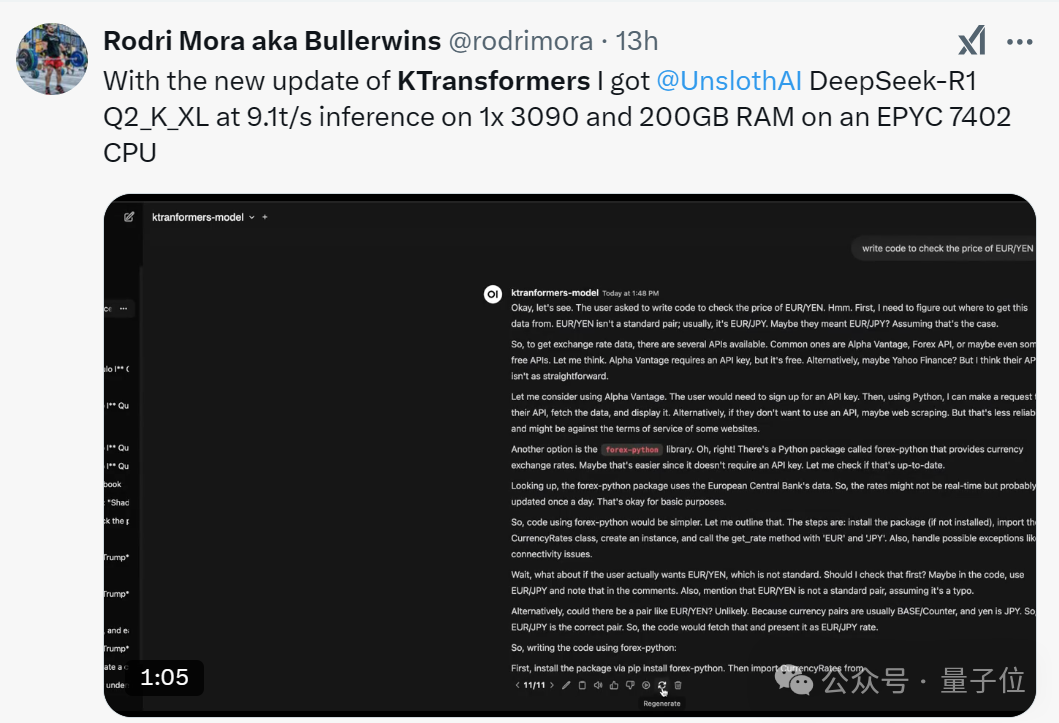
版本更新发布后,不少开发者也纷纷用自己的3090显卡和200GB内存进行实测,借助与Unsloth优化的组合,Q2_K_XL模型的推理速度已达到9.1 tokens/s,真正实现了千亿级模型的“家庭化”。
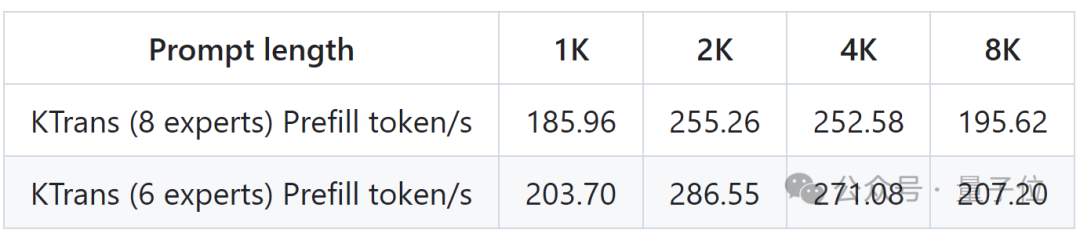
此外,KTransformers团队还公布了v0.3预览版的性能指标,将通过整合Intel AMX指令集,CPU预填充速度最高至286 tokens/s,相比llama.cpp快了近28倍。对于那些需要处理上万级Token上下文的长序列任务(比如大规模代码库分析)来说,相当于能够从“分钟级等待”瞬间迈入“秒级响应”,彻底释放CPU的算力潜能。
另外,KTransformers还提供了兼容Hugginface Transformers的API与ChatGPT式Web界面,极大降低了上手难度。同时,其基于YAML的“模板注入框架”能够灵活切换量化策略、内核替换等多种优化方式。
目前,KTransformers在localLLaMa社区持续位居热榜第一,有上百条开发者的讨论。
项目背后的技术细节,团队也给出了详细介绍。
利用MoE架构的稀疏性
DeepSeek-R1/V3均采用了MoE(混合专家)架构,这种架构的核心是将模型中的任务分配给不同的专家模块,每个专家模块专注于处理特定类型的任务。MoE结构的模型具有很强的稀疏性,在执行推理任务的时候,每次只会激活其中一部分的模型参数。
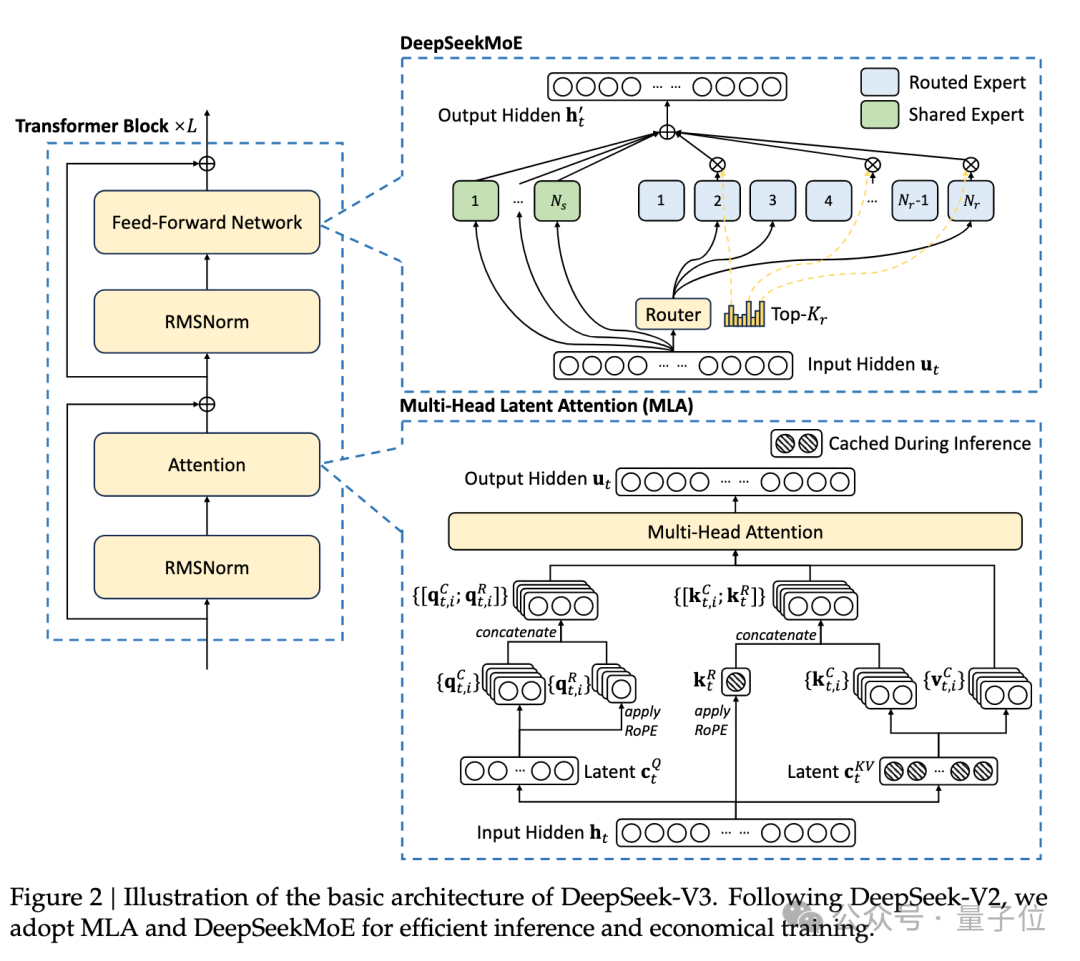
因此,MoE架构需要大量的存储空间,但是并不需要很多的计算资源。
基于此,团队采用了GPU/CPU的异构计算划分策略:仅将非Shared部分的稀疏MoE矩阵放在CPU/DRAM上并使用llamafile提供的高速算子处理,剩余稠密部分放在GPU上使用Marlin算子处理。
在这样的情况下,同样使用4bit量化,GPU上的参数只需要24GB的显存环境,这样的消耗只需要一张4090就能满足。
此外通过这样的组合,还能够大幅度提升整个推理的性能,达到286 token/s的预填充和14 token/s的生成速度,比llama.cpp快28倍。
具体到技术实现中,团队采用了基于计算强度的offload策略、高性能的CPU和GPU算子、CUDA Graph加速的多种方式来加速推理速度。
基于计算强度的offload策略
在Attention的核心,DeepSeek引入了一种新的MLA算子,它能够充分利用显卡算力,能够很大程度提升效率。然而,MLA运算符在官方开源的v2版本中,是将MLA展开成MHA进行的计算,这个过程不仅扩大了KV cache大小,还降低了推理性能。
为了真正发挥MLA的性能,在KTransformers推理框架中,团队将矩阵直接吸收到q_proj和out_proj权重中。因此,压缩表示不需要解压缩来计算Attention。
这种调整显著减少了KV缓存大小,并增加了该运算符的算术强度,这非常显著地优化了GPU计算能力的利用率。
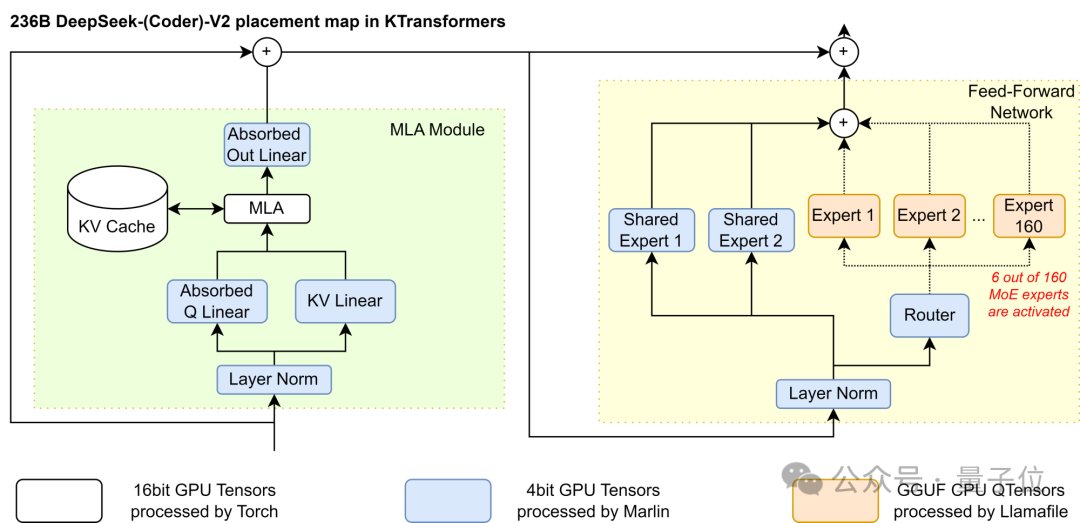
在计算中,MLA和Expert的计算强度相差数千倍。因此,团队通过计算强度来决定划分策略,优先将计算强度高的放入GPU(MLA > Shared Expert > Routed Expert),直到GPU放不下为止。
引入CPU和GPU的高性能算子
在CPU算子中,团队使用llamafile作为CPU内核,使用expert并行和其他优化,组成高性能算子框架CPUInfer。此外增加多线程、任务调度、负载均衡、NUMA感知等优化。
在GPU算子的使用上,团队引入Marlin算子作为GPU计算的内核,它能够非常高效地进行量化后的矩阵计算,和torch这些计算量化后的矩阵乘法的库相比,使用Marlin算子完成在GPU上面的计算大概可以达到3.87倍的理想加速效果。
CUDA Graph的改进和优化
为了平衡推理性能和框架本身的易用性/可扩展性,基于Python构建KTransformers框架,同时使用CUDA Graph降低Python调用开销是一个必然的选择。
KTransformers中使用CUDA Graph过程中尽可能地减少了CPU/GPU通讯造成的断点,在CUDA Graph中掺杂和CPU异构算子通讯,最终实现一次decode仅有一个完整的CUDA Graph调用的结果。
灵活高效的推理实验平台
值得关注的是,KTransformers不止是一个固定的推理框架,也不只能推理DeepSeek的模型,它可以兼容各式各样的MoE模型和算子,能够集成各种各样的算子,做各种组合的测试。
此外还同时提供了Windows、Linux的平台的支持,方便运行。
当大模型不断往上卷,KTransformers用异构计算打开一条新的推理路径。基于此,科研工作者无需巨额预算也能够探索模型本质。
GitHub 地址:https://github.com/kvcache-ai/ktransformers
具体技术细节指路:https://zhuanlan.zhihu.com/p/714877271
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)