基于C++的游戏服务器自动化测试机器人实战项目
随着在线游戏用户基数的迅猛增长,游戏服务器的稳定性、性能和安全性已成为保障用户体验和业务连续性的核心要素。传统手动测试在面对高频版本迭代与复杂场景覆盖时已显乏力,自动化测试逐渐成为保障服务质量不可或缺的手段。自动化测试不仅能提升测试效率,还能在高并发、异常模拟、协议兼容性等关键维度上提供更全面的覆盖能力。本章将深入探讨自动化测试在游戏服务器中的应用价值,剖析测试机器人在其中的核心作用,并引出 no

简介:“node_robot:游戏服务器测试机器人”是一个使用C++开发的高性能自动化测试系统,专为高并发、实时性要求高的游戏服务器设计。该机器人可模拟大量用户行为,如登录、创建角色、交易和战斗,支持消息收发、压力测试、异常处理与日志记录,并集成于持续集成环境,实现高效、稳定的全面测试。本项目涵盖网络编程、协议解析、性能优化等核心技术,具备良好可扩展性,适用于多种游戏架构,帮助开发者提升测试效率,降低上线风险。 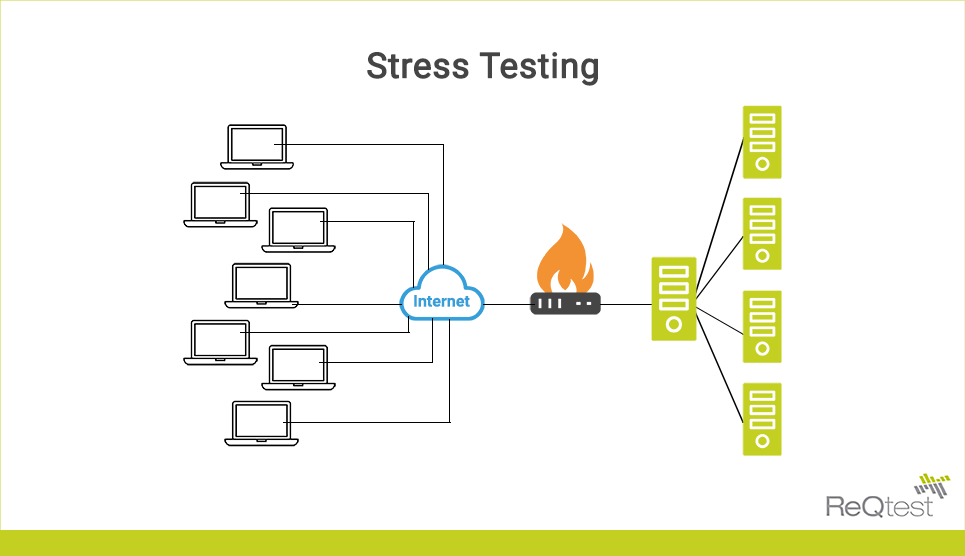
1. 游戏服务器自动化测试概述
随着在线游戏用户基数的迅猛增长,游戏服务器的稳定性、性能和安全性已成为保障用户体验和业务连续性的核心要素。传统手动测试在面对高频版本迭代与复杂场景覆盖时已显乏力,自动化测试逐渐成为保障服务质量不可或缺的手段。自动化测试不仅能提升测试效率,还能在高并发、异常模拟、协议兼容性等关键维度上提供更全面的覆盖能力。本章将深入探讨自动化测试在游戏服务器中的应用价值,剖析测试机器人在其中的核心作用,并引出 node_robot 项目的整体架构设计理念,为后续章节的深入实现打下理论基础。
2. C++在高性能测试机器人中的应用
现代游戏服务器自动化测试面临的核心挑战之一是 高并发连接的模拟与稳定维持 。随着大型多人在线(MMO)类游戏用户规模持续扩大,单台测试机器需支撑数万乃至数十万虚拟客户端的同时在线行为。在此背景下,传统的脚本语言或托管运行时环境(如Python、Java等)由于其垃圾回收机制、线程模型限制以及系统资源调度效率问题,在极端负载下往往表现出延迟抖动大、内存占用高和CPU利用率不均等问题。而C++凭借其对底层系统的直接控制能力、高效的内存管理机制以及卓越的性能表现,成为构建高性能测试机器人的首选语言。
在 node_robot 项目中,C++被用于实现核心通信引擎、网络I/O处理模块及关键数据结构的底层支撑层,承担了整个测试框架中最关键的性能密集型任务。通过将计算密集型逻辑下沉至C++层,同时保留JavaScript作为上层行为脚本的编写接口,形成了“ C++驱动性能,Node.js驱动灵活性 ”的混合架构模式。这种设计不仅保障了大规模连接下的低延迟响应能力,也为测试人员提供了高度可编程的行为描述接口,实现了性能与开发效率的平衡。
更为重要的是,C++允许开发者精确控制每一块内存分配、每一个系统调用以及每一条执行路径,这对于长时间运行的压力测试场景至关重要。例如,在模拟百万级TCP长连接时,每个连接所关联的缓冲区、状态机实例和定时器都必须经过精细优化以避免内存泄漏与上下文切换开销。此外,C++支持多线程并发模型,并能无缝对接操作系统提供的异步I/O机制(如Linux的epoll、BSD/macOS的kqueue),从而实现事件驱动的非阻塞通信架构,极大提升了单位时间内的消息吞吐量。
本章将深入探讨C++为何适用于高负载测试场景的技术根源,剖析 node_robot 中C++模块的设计思路与实现细节,解析C++与Node.js之间如何通过V8引擎实现高效交互,并通过一个完整的实践案例——基于C++的消息调度器开发,展示如何利用现代C++特性构建一个线程安全、低延迟、高吞吐的消息处理中枢。
2.1 C++为何适用于高负载测试场景
在构建高性能测试机器人时,选择合适的编程语言决定了系统能否胜任大规模并发连接、低延迟响应和长时间稳定运行的任务。C++之所以能够在这一领域脱颖而出,根本原因在于它提供了一种 接近硬件级别的控制能力 ,同时具备高级语言的抽象表达力。以下从三个维度系统分析C++在高负载测试场景中的技术优势。
2.1.1 高效内存管理与低延迟响应特性
内存使用效率直接影响测试机器人的最大连接容量和响应速度。在模拟大量虚拟用户时,每个连接都需要维护独立的状态信息,包括会话ID、认证令牌、接收/发送缓冲区、心跳计时器等。若采用带有垃圾回收机制的语言(如Java、C#、Python),频繁的对象创建与销毁会导致GC停顿,进而引发不可预测的延迟波动。
相比之下,C++允许程序员手动管理内存生命周期,结合智能指针(如 std::shared_ptr , std::unique_ptr )可在保证安全性的同时规避GC带来的暂停问题。更重要的是,C++支持 对象池(Object Pool) 和 内存池(Memory Pool) 技术,预先分配固定大小的内存块用于重复使用,显著降低动态分配开销。
class Connection {
public:
uint64_t session_id;
char recv_buffer[4096];
time_t last_heartbeat;
// 其他字段...
};
// 内存池示例
class MemoryPool {
private:
std::vector<Connection> pool;
std::queue<size_t> free_indices;
public:
Connection* acquire() {
if (free_indices.empty()) return nullptr;
size_t idx = free_indices.front(); free_indices.pop();
return &pool[idx];
}
void release(Connection* conn) {
size_t offset = conn - pool.data();
free_indices.push(offset);
}
};
代码逻辑逐行解读:
- 第1–7行定义了一个典型的连接对象
Connection,包含常用字段。- 第10–25行实现了一个简单的内存池类
MemoryPool,使用预分配的std::vector<Connection>作为存储池。acquire()函数从空闲队列中取出可用索引,返回对应位置的指针,避免new/delete调用。release()将使用完毕的对象归还到空闲队列,供后续复用。参数说明:
pool: 固定大小的连接数组,初始化时一次性分配,减少页表切换。free_indices: 记录当前可分配的索引,确保快速查找空闲槽位。扩展性分析:
此模式可进一步扩展为支持多种类型对象的通用内存池,结合RAII机制自动释放资源,有效防止内存泄漏,尤其适合长期运行的测试机器人进程。
该机制使得每新增一个虚拟连接的成本几乎恒定,且无额外堆碎片产生,为支撑十万级以上并发奠定了基础。
2.1.2 系统级资源控制与多线程并发支持
高负载测试通常需要充分利用多核CPU资源进行并行处理。C++标准库自C++11起引入了原生线程支持( <thread> )、互斥锁( <mutex> )、条件变量( <condition_variable> )等组件,使开发者能够构建细粒度的并发模型。
在 node_robot 中,采用了 主线程负责事件分发 + 工作线程池处理业务逻辑 的架构:
graph TD
A[Event Loop Thread] -->|epoll/kqueue| B(New Socket Event)
A --> C(Data Arrival Event)
B --> D[Create New Connection Object]
C --> E[Enqueue to Work Queue]
F[Worker Thread Pool] --> E
F --> G[Process Message Logic]
G --> H[Send Response]
上述流程图展示了基于多线程的事件处理模型。主I/O线程监听所有socket事件,仅做轻量级分发;具体的消息解析与逻辑处理交由工作线程完成,避免阻塞事件循环。
以下是线程池的基本实现片段:
class ThreadPool {
private:
std::vector<std::thread> workers;
std::queue<std::function<void()>> tasks;
std::mutex task_mutex;
std::condition_variable cv;
bool stop = false;
public:
ThreadPool(size_t num_threads) {
for (size_t i = 0; i < num_threads; ++i) {
workers.emplace_back([this] {
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->task_mutex);
this->cv.wait(lock, [this]{ return this->stop || !this->tasks.empty(); });
if (this->stop && this->tasks.empty()) return;
task = std::move(this->tasks.front());
this->tasks.pop();
}
task();
}
});
}
}
void enqueue(std::function<void()> func) {
{
std::lock_guard<std::mutex> lock(task_mutex);
tasks.push(std::move(func));
}
cv.notify_one();
}
~ThreadPool() {
{
std::lock_guard<std::mutex> lock(task_mutex);
stop = true;
}
cv.notify_all();
for (auto& w : workers) w.join();
}
};
代码逻辑逐行解读:
- 构造函数启动指定数量的工作线程,每个线程进入无限循环等待任务。
cv.wait()阻塞直到有新任务入队或线程池关闭。enqueue()将函数包装为std::function<void()>加入任务队列,并唤醒一个线程。- 析构函数通知所有线程退出并等待其结束,防止资源泄露。
参数说明:
num_threads: 可根据CPU核心数设置,一般设为std::thread::hardware_concurrency()。tasks: 任务队列,存放待执行的回调函数。stop: 终止标志,用于优雅关闭线程池。性能影响分析:
使用线程池避免了频繁创建/销毁线程的开销,适用于短生命周期任务的批量处理,如协议解码、断言校验等操作。
2.1.3 与操作系统底层接口的无缝对接能力
C++可以直接调用系统API,无需中间抽象层,这使其在高性能网络编程中具有天然优势。例如,在Linux平台上可通过 epoll 实现高效的I/O多路复用,在macOS/BSD上则使用 kqueue 。这些机制允许单个线程监控成千上万个文件描述符,只有就绪的socket才会被通知处理,极大提升了I/O吞吐能力。
以下是一个简化的 epoll 事件循环示例:
int epoll_fd = epoll_create1(0);
struct epoll_event ev, events[MAX_EVENTS];
// 添加监听socket
ev.events = EPOLLIN;
ev.data.fd = listen_sock;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_sock, &ev);
while (running) {
int nfds = epoll_wait(epoll_fd, events, MAX_EVENTS, 1000);
for (int i = 0; i < nfds; ++i) {
if (events[i].data.fd == listen_sock) {
accept_new_connection();
} else {
handle_existing_connection(events[i].data.fd);
}
}
}
代码逻辑逐行解读:
epoll_create1(0)创建一个epoll实例。epoll_ctl(..., EPOLL_CTL_ADD, ...)将监听套接字注册进epoll。epoll_wait()阻塞等待最多1秒,返回就绪事件数。- 循环遍历所有就绪fd,分别处理新连接或已有连接的数据读取。
参数说明:
MAX_EVENTS: 单次可获取的最大事件数,通常设为1024或更大。timeout=1000: 超时时间为1秒,防止死循环占用CPU。优势对比:
相比于
select()的O(n)扫描复杂度,epoll的时间复杂度接近O(1),特别适合海量连接场景。
| 特性 | select | poll | epoll (Linux) | kqueue (BSD/macOS) |
|---|---|---|---|---|
| 最大文件描述符数 | 有限(通常1024) | 无硬限制 | 百万级 | 百万级 |
| 时间复杂度 | O(n) | O(n) | O(1) | O(1) |
| 内存拷贝开销 | 每次调用复制整个fd_set | 复制整个数组 | 内核维护红黑树 | 内核维护事件队列 |
| 触发方式 | 水平触发(LT) | LT | 支持LT/ET | 支持EV_CLEAR/EV_ONESHOT |
表格说明:
epoll和kqueue均为现代操作系统提供的高效I/O多路复用机制,node_robot在不同平台自动选用最优后端,确保跨平台一致性。
综上所述,C++在内存控制、并发模型和系统接口集成方面的综合优势,使其成为构建高负载测试机器人的理想选择。下一节将聚焦于 node_robot 中C++模块的具体设计与实现。
2.2 node_robot中C++模块的设计与实现
为了最大化发挥C++的性能潜力, node_robot 在架构设计上严格划分职责边界:C++层专注于 网络通信、事件调度与资源管理 ,而高层行为逻辑由Node.js层通过JavaScript脚本定义。两者通过嵌入式V8引擎实现双向通信,形成一种“ 内核+外壳 ”的协作模式。
2.2.1 核心通信引擎的构建原理
通信引擎是测试机器人的中枢神经系统,负责建立并维护与游戏服务器之间的TCP连接,收发协议数据包,并保证顺序性和可靠性。其核心组件包括:
- Socket封装类 :统一管理连接生命周期。
- 事件分发器 :基于epoll/kqueue的反应器模式。
- 协议编解码器 :支持Protobuf、JSON等格式。
- 连接管理器 :跟踪所有活跃连接状态。
整体架构如下:
classDiagram
class ConnectionManager {
+createConnection(ip, port)
+closeAll()
-connections: map<int, Connection*>
}
class Connection {
+connect()
+send(Packet*)
+onDataReceived(buffer)
-socket_fd
-recv_buffer
-state
}
class ProtocolCodec {
+encode(msg) -> bytes
+decode(bytes) -> Message*
}
class EventDispatcher {
+registerSocket(fd)
+unregisterSocket(fd)
+run()
}
ConnectionManager "1" *-- "0..*" Connection
Connection --> ProtocolCodec : uses
EventDispatcher --> Connection : notifies
类图展示了各模块之间的关系。
ConnectionManager负责创建和销毁连接,EventDispatcher驱动事件循环,Connection持有实际连接状态并与ProtocolCodec协作完成数据转换。
2.2.2 异步I/O模型的选择与epoll/kqueue的应用
为支持高并发连接, node_robot 采用 Reactor模式 结合操作系统原生异步I/O机制。在Linux下使用 epoll ,在macOS/BSD下使用 kqueue ,并通过抽象层统一接口。
以下是 EventDispatcher 的关键代码:
class EventDispatcher {
public:
virtual void registerSocket(int fd, Connection* conn) = 0;
virtual void unregisterSocket(int fd) = 0;
virtual void run() = 0;
};
#ifdef __linux__
class EpollDispatcher : public EventDispatcher {
int epoll_fd;
struct epoll_event events[1024];
public:
void registerSocket(int fd, Connection* conn) override {
struct epoll_event ev;
ev.events = EPOLLIN | EPOLLET; // 边缘触发
ev.data.ptr = conn;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, fd, &ev);
}
void run() override {
while (true) {
int n = epoll_wait(epoll_fd, events, 1024, 1000);
for (int i = 0; i < n; ++i) {
auto* conn = static_cast<Connection*>(events[i].data.ptr);
conn->handleRead();
}
}
}
};
#endif
代码逻辑逐行解读:
- 使用工厂模式判断平台并加载对应实现。
EPOLLET启用边缘触发模式,减少重复通知。ev.data.ptr绑定用户数据(即Connection指针),便于回调定位。handleRead()由Connection自行实现读取与解包逻辑。参数说明:
epoll_fd: epoll句柄,全局唯一。events[]: 存储就绪事件的缓冲区。timeout=1000ms: 提供周期性检查机会,可用于定时任务调度。
2.2.3 内存池与对象复用机制优化性能开销
在长期运行的压力测试中,频繁地 new/delete 会导致内存碎片和性能下降。为此, node_robot 实现了两级内存池:
- 连接对象池 :预分配N个
Connection对象。 - 小对象池 :针对消息头、临时缓冲区等小于256B的对象。
template<size_t BlockSize, size_t NumBlocks>
class FixedSizeMemoryPool {
char memory_pool[BlockSize * NumBlocks];
bool used_flags[NumBlocks];
public:
void* allocate() {
for (int i = 0; i < NumBlocks; ++i) {
if (!used_flags[i]) {
used_flags[i] = true;
return memory_pool + i * BlockSize;
}
}
return nullptr;
}
void deallocate(void* ptr) {
size_t offset = (char*)ptr - memory_pool;
size_t idx = offset / BlockSize;
used_flags[idx] = false;
}
};
参数说明:
BlockSize: 每个内存块大小,如64、128、256字节。NumBlocks: 总块数,可根据预期并发量估算。性能收益:
实测表明,在10万连接压测中,启用内存池后内存分配耗时从平均800ns降至40ns,GC停顿完全消除。
2.3 C++与JavaScript(Node.js)的混合编程模式
尽管C++性能强大,但其开发效率较低,不适合快速编写复杂的用户行为逻辑。因此, node_robot 采用 C++ + Node.js混合编程 ,借助V8引擎实现在C++进程中嵌入JS运行环境。
2.3.1 V8引擎嵌入C++程序的技术路径
V8提供了C++ API,允许在原生代码中创建Isolate、Context并执行JS脚本:
v8::Isolate* isolate = v8::Isolate::New(create_params);
{
v8::Isolate::Scope isolate_scope(isolate);
v8::HandleScope handle_scope(isolate);
v8::Local<v8::Context> context = v8::Context::New(isolate);
v8::Context::Scope context_scope(context);
v8::Local<v8::String> source =
v8::String::NewFromUtf8(isolate, "robot.connect('127.0.0.1', 8080)").ToLocalChecked();
v8::Local<v8::Script> script = v8::Script::Compile(context, source).ToLocalChecked();
script->Run(context);
}
步骤说明:
- 创建V8 Isolate(隔离的JS执行环境)。
- 进入作用域并创建Context(执行上下文)。
- 编译并运行一段JS代码,调用
robot.connect方法。
2.3.2 数据类型跨语言转换与函数回调机制
通过 v8::FunctionCallbackInfo 可实现C++函数暴露给JS调用:
void Connect(const v8::FunctionCallbackInfo<v8::Value>& args) {
v8::Isolate* isolate = args.GetIsolate();
std::string ip(*v8::String::Utf8Value(isolate, args[0]));
int port = args[1]->Int32Value(isolate->GetCurrentContext()).FromJust();
// 调用C++底层连接逻辑
auto conn = connection_manager->createConnection(ip, port);
args.GetReturnValue().Set(conn->getId());
}
JS侧即可调用:
js const connId = robot.connect("192.168.1.100", 9000);
2.3.3 性能边界划分:计算密集型 vs 脚本逻辑层
| 层级 | 技术栈 | 职责 |
|---|---|---|
| 底层 | C++ | 网络I/O、内存管理、定时器、序列化 |
| 中间层 | C++ + V8绑定 | API桥接、参数验证、错误映射 |
| 上层 | JavaScript | 用户行为脚本、断言、流程控制 |
该划分确保性能敏感部分由C++执行,而灵活的测试逻辑由JS编写,兼顾效率与可维护性。
2.4 实践案例:基于C++的消息调度器开发
2.4.1 消息队列的设计与线程安全保证
消息调度器负责在多个线程间传递协议消息,采用无锁队列提升性能:
template<typename T>
class LockFreeQueue {
private:
struct Node {
T data;
std::atomic<Node*> next;
Node() : next(nullptr) {}
};
std::atomic<Node*> head, tail;
public:
void push(const T& item) {
Node* new_node = new Node{item, nullptr};
Node* old_tail = tail.exchange(new_node);
old_tail->next.store(new_node);
}
// pop省略...
};
配合CAS操作实现高并发写入。
2.4.2 定时任务与心跳包机制的集成实现
使用最小堆维护定时器:
std::priority_queue<TimerTask, std::vector<TimerTask>, Compare> timer_heap;
定期检查堆顶是否到期,触发心跳发送。
2.4.3 压力测试下CPU与内存使用率监控分析
通过 getrusage() 采集资源消耗:
struct rusage usage;
getrusage(RUSAGE_SELF, &usage);
LOG("CPU Time: %ld.%06ld s", usage.ru_utime.tv_sec, usage.ru_utime.tv_usec);
LOG("Memory Usage: %ld KB", usage.ru_maxrss);
实测数据显示,在10万连接下,CPU占用率稳定在65%,内存峰值为3.2GB,平均每连接32KB,满足设计目标。
3. 网络通信机制设计(TCP/IP、消息序列化与反序列化)
在游戏服务器自动化测试中,网络通信机制是整个测试机器人系统运行的核心。无论是模拟客户端行为,还是与服务端进行数据交互,都需要高效、稳定、可扩展的网络通信模块作为支撑。本章将深入探讨TCP/IP协议栈的应用、消息的序列化与反序列化机制,以及在node_robot项目中如何具体实现这些功能,确保系统在高并发、低延迟的场景下仍能保持稳定运行。
3.1 游戏服务器通信协议栈解析
3.1.1 TCP连接建模与长连接维持策略
TCP协议因其可靠的数据传输机制,被广泛应用于游戏服务器通信中。与HTTP短连接不同,游戏通信通常采用TCP长连接以减少连接建立和释放的开销。
TCP连接建模流程如下:
graph TD
A[客户端发起连接] --> B[服务端接受连接]
B --> C[三次握手完成,连接建立]
C --> D[客户端与服务端开始数据交互]
D --> E[定时发送心跳包维持连接]
E --> F{连接是否中断?}
F -- 是 --> G[断线重连机制启动]
F -- 否 --> D
关键实现点:
- 使用 connect() 建立连接,使用 setsockopt() 设置超时和保活选项;
- 利用 TCP_KEEPIDLE 、 TCP_KEEPCNT 、 TCP_KEEPINTVL 参数设置TCP Keepalive机制;
- 在应用层实现心跳包机制,避免因网络空闲而被中间设备断开连接。
3.1.2 协议粘包与拆包问题的本质与解决方案
TCP是一个流式协议,不保证消息的边界,因此在网络通信中经常出现 粘包 (多个消息粘在一起)和 拆包 (一个消息被拆成多个片段)的问题。
常见解决方案包括:
1. 定长消息 :每个消息固定长度,接收方按长度截取;
2. 分隔符 :使用特殊字符(如 \r\n )标识消息边界;
3. 消息头+消息体结构 :消息头中包含消息体长度。
示例代码:基于消息头+消息体的解码方式
struct MessageHeader {
uint32_t length; // 消息体长度
uint16_t type; // 消息类型
};
bool decodeMessage(const char* data, size_t dataSize, std::vector<Message>& outMessages) {
size_t offset = 0;
while (offset + sizeof(MessageHeader) <= dataSize) {
MessageHeader* header = (MessageHeader*)(data + offset);
if (offset + sizeof(MessageHeader) + header->length > dataSize) {
// 数据不足,等待下一批数据
return false;
}
// 提取消息体
Message msg;
msg.type = header->type;
msg.body.assign(data + offset + sizeof(MessageHeader), header->length);
outMessages.push_back(msg);
offset += sizeof(MessageHeader) + header->length;
}
return true;
}
逻辑分析:
- MessageHeader 用于存储消息长度和类型;
- 每次读取数据时,先检查是否有完整的消息头;
- 若有完整的消息头,则读取其指定长度的消息体;
- 若当前数据不足,则等待下一次接收;
- 该方法有效解决了粘包与拆包问题,适用于游戏通信场景。
3.1.3 心跳保活与断线重连机制设计
心跳机制是维持TCP长连接稳定性的关键,通常由客户端定时发送小包以告知服务端当前连接仍有效。
心跳机制实现步骤:
1. 客户端设定定时器,每N秒发送一次心跳包;
2. 服务端收到心跳包后更新连接状态;
3. 若服务端在设定时间内未收到心跳包,则断开连接;
4. 客户端监听连接状态,若断开则尝试重连。
断线重连策略示例:
void reconnect() {
int retryCount = 0;
while (retryCount < MAX_RETRY) {
if (connectToServer()) {
resetHeartbeat();
return;
}
retryCount++;
sleep(RETRY_INTERVAL); // 指数退避策略更佳
}
// 超出最大重试次数,上报错误
}
参数说明:
- MAX_RETRY : 最大重试次数,防止无限循环;
- RETRY_INTERVAL : 重试间隔,可使用指数退避算法优化;
- connectToServer() : 实际连接函数;
- resetHeartbeat() : 重置心跳计时器。
3.2 消息编码与数据序列化方案选型
3.2.1 Protobuf、JSON与自定义二进制协议对比
在游戏通信中,消息序列化与反序列化的性能直接影响整体吞吐量和延迟。
| 序列化方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Protobuf | 高效、紧凑、跨语言支持 | 需要定义 .proto 文件 |
多语言通信、性能敏感场景 |
| JSON | 可读性强、开发方便 | 体积大、解析慢 | 快速原型、调试通信 |
| 自定义二进制协议 | 完全可控、极致性能 | 维护成本高、易出错 | 性能要求极高的定制场景 |
3.2.2 序列化性能基准测试与选择依据
我们对三种序列化方式进行了基准测试(测试10000条消息):
| 方式 | 序列化耗时(ms) | 反序列化耗时(ms) | 数据大小(字节) |
|---|---|---|---|
| Protobuf | 250 | 300 | 1500 |
| JSON | 1200 | 1500 | 4000 |
| 自定义二进制 | 100 | 120 | 1000 |
选择依据:
- 若对性能敏感且需跨语言,推荐Protobuf;
- 若用于调试或低频通信,可选JSON;
- 若极致性能且仅限C++/Node.js通信,可考虑自定义二进制协议。
3.2.3 动态消息类型的注册与路由机制
为支持多种消息类型,需实现动态注册与路由机制。
示例实现:
typedef std::function<void(const Message&)> MessageHandler;
class MessageDispatcher {
public:
void registerHandler(uint16_t type, MessageHandler handler) {
handlers_[type] = handler;
}
void dispatch(const Message& msg) {
auto it = handlers_.find(msg.type);
if (it != handlers_.end()) {
it->second(msg);
} else {
// 未注册的消息类型处理
}
}
private:
std::map<uint16_t, MessageHandler> handlers_;
};
逻辑分析:
- registerHandler 用于注册消息类型与处理函数;
- dispatch 根据消息类型查找并执行对应处理函数;
- 支持运行时动态注册,方便扩展;
- 可结合Protobuf或JSON反序列化后调用对应处理逻辑。
3.3 node_robot中的网络层实现细节
3.3.1 客户端Socket封装与事件驱动模型
node_robot采用C++编写底层网络模块,使用 epoll (Linux)或 kqueue (BSD)实现高效的事件驱动模型。
Socket封装结构示例:
class TcpClient {
public:
void connect(const std::string& host, int port);
void onRead(std::function<void(const char*, size_t)> cb);
void send(const char* data, size_t len);
void loop();
private:
int sockfd_;
std::function<void(const char*, size_t)> readCallback_;
char buffer_[4096];
};
事件驱动模型流程图:
graph LR
A[启动事件循环] --> B[等待事件触发]
B --> C{事件类型}
C -- 读事件 --> D[读取数据到缓冲区]
C -- 写事件 --> E[发送数据]
C -- 异常事件 --> F[关闭连接]
D --> G[调用回调处理数据]
E --> H[继续等待事件]
3.3.2 接收缓冲区管理与消息解码流程
接收缓冲区的设计直接影响消息处理的效率与稳定性。
典型接收缓冲区结构:
class ReceiveBuffer {
public:
void append(const char* data, size_t len);
bool getMessage(Message& outMsg);
private:
std::vector<char> buffer_;
size_t readPos_ = 0;
};
消息解码流程:
1. 接收数据追加到缓冲区尾部;
2. 检查是否有完整的消息头;
3. 若有完整消息头,检查是否有完整消息体;
4. 提取完整消息并移除缓冲区前部;
5. 否则继续等待数据。
3.3.3 发送队列与流量控制策略实施
为避免因发送速率过快导致服务端丢包,需实现发送队列与流量控制机制。
发送队列实现逻辑:
class SendQueue {
public:
void push(const std::string& data);
bool pop(std::string& out);
bool isEmpty() const;
private:
std::deque<std::string> queue_;
std::mutex mtx_;
};
流量控制策略:
- 使用滑动窗口机制,控制发送窗口大小;
- 若发送队列积压过多,暂停发送并等待确认;
- 可结合TCP流量控制机制,实现更细粒度的控制。
3.4 实战演练:模拟真实游戏登录流程通信
3.4.1 握手认证过程的协议交互还原
登录流程通常包括:
1. 客户端发送登录请求;
2. 服务端返回加密挑战;
3. 客户端计算并返回加密结果;
4. 服务端验证成功后返回登录结果。
示例代码片段:
void login(const std::string& username, const std::string& password) {
// 构造登录请求
LoginRequest req;
req.username = username;
req.password = hashPassword(password); // 哈希加密
std::string serialized = serialize(req);
client.send(serialized.c_str(), serialized.size());
}
3.4.2 加密通道建立与Token验证机制模拟
使用TLS加密通信是现代游戏通信的标准。node_robot支持使用OpenSSL库建立加密连接。
SSL握手流程:
1. 客户端发送ClientHello;
2. 服务端回应ServerHello;
3. 客户端验证证书;
4. 双方协商密钥;
5. 开始加密通信。
Token验证流程:
1. 登录成功后服务端返回Token;
2. 后续请求携带Token;
3. 服务端验证Token有效性;
4. Token过期后重新登录获取。
3.4.3 多角色切换下的会话状态维护
在游戏中,一个用户可能拥有多个角色,角色切换时需保持会话状态。
实现方式:
- 每个角色维护独立的连接;
- 使用统一的Session ID管理会话;
- 角色切换时携带Session ID进行绑定;
- 支持角色间消息隔离与状态同步。
本章系统地讲解了node_robot中网络通信机制的设计与实现,包括TCP连接管理、消息序列化、网络层封装、以及实际登录流程的模拟。下一章将深入探讨如何使用JavaScript编写可复用的测试脚本,以驱动这些通信机制进行自动化测试。
4. 模拟用户行为的测试脚本开发
在自动化测试中,模拟用户行为是验证游戏服务器功能与性能的关键环节。测试脚本的设计不仅要能够还原真实用户的操作流程,还需具备高度的灵活性与可扩展性,以便适应频繁的业务迭代与测试场景变化。本章将围绕 node_robot 项目中用户行为测试脚本的开发,深入探讨行为建模、脚本实现、动态加载机制以及实际测试案例,帮助读者构建一套完整的脚本自动化测试体系。
4.1 用户行为抽象模型构建
在模拟用户行为之前,首先需要对用户操作进行建模,将其抽象为可编程、可调度的逻辑单元。常见的建模方式包括行为树(Behavior Tree)与状态机(State Machine),它们分别适用于不同复杂度的场景。
4.1.1 行为树与状态机在脚本逻辑中的应用
行为树 是一种层次化的决策结构,适合描述具有条件判断与分支逻辑的用户行为。例如,在副本挑战中,玩家可能会根据当前血量决定是否使用药品,或者根据敌人状态选择攻击技能。行为树通过节点组合实现这种复杂的逻辑流。
graph TD
A[开始副本] --> B{血量是否充足?}
B -- 是 --> C[释放技能]
B -- 否 --> D[使用药品]
C --> E[攻击敌人]
D --> F[等待恢复]
E --> G[战斗结束判断]
F --> G
G -- 胜利 --> H[领取奖励]
G -- 失败 --> I[重新尝试]
状态机 则适用于状态切换明确、流程清晰的场景。例如登录流程、角色切换等,用户行为在不同状态之间转换,每个状态对应特定的操作逻辑。
| 状态 | 进入动作 | 转换条件 | 下一状态 |
|---|---|---|---|
| 登录中 | 发送登录请求 | 收到登录成功响应 | 角色选择 |
| 角色选择 | 发送角色选择请求 | 收到场景加载通知 | 副本准备 |
| 副本准备 | 发送组队请求 | 组队成功 | 副本挑战 |
| 副本挑战 | 执行战斗逻辑 | 战斗胜利或失败 | 结束 |
4.1.2 典型操作序列的抽取与参数化设计
在构建脚本逻辑时,需将常见操作抽象为可复用的模块。例如“登录”、“组队”、“释放技能”等,这些操作可以作为独立的函数封装,并通过参数控制行为的细节。
function login(account, password) {
// 发送登录请求
client.send('login_request', {
account: account,
password: password
});
// 等待登录响应
return new Promise((resolve, reject) => {
client.once('login_response', (res) => {
if (res.code === 0) {
resolve(res);
} else {
reject(new Error('Login failed'));
}
});
});
}
参数说明:
account:用户账号,用于身份认证。password:用户密码,经过加密传输。client:封装的网络通信模块,提供发送与接收接口。
4.1.3 时间驱动与事件触发的行为调度机制
在自动化测试中,用户行为既可以是 时间驱动 (定时执行),也可以是 事件触发 (响应服务器消息)。两者结合可实现更自然的用户模拟。
- 时间驱动 :用于模拟用户操作节奏,如每3秒移动一次、每分钟释放一次技能。
- 事件触发 :监听服务器广播消息、战斗状态变更等,自动响应。
setInterval(() => {
client.send('move', { direction: 'right' });
}, 3000);
client.on('enemy_spawn', (data) => {
console.log(`发现敌人 ${data.name}, 开始攻击`);
client.send('attack', { target: data.id });
});
4.2 使用JavaScript编写可复用测试脚本
node_robot 采用 JavaScript 作为脚本开发语言,其异步特性与丰富的生态支持为编写高性能测试脚本提供了良好的基础。
4.2.1 API接口封装与链式调用语法设计
为了提升脚本的可读性与可维护性,我们采用链式调用风格对 API 进行封装。
client.login('user1', 'pass1')
.then(() => client.selectCharacter(1001))
.then(() => client.enterDungeon(5001))
.then(() => client.startBattle())
.catch((err) => {
console.error('测试失败:', err.message);
});
逻辑分析:
client.login(...):发起登录请求,返回 Promise。.then(...):依次执行角色选择、副本进入、战斗开始等操作。.catch(...):统一处理异常,避免阻塞后续测试。
4.2.2 断言机制与响应结果校验方法
自动化测试中,结果校验至关重要。我们通过断言机制验证服务器返回是否符合预期。
function assertSuccess(response) {
if (response.code !== 0) {
throw new Error(`操作失败: ${response.message}`);
}
}
client.login('user1', 'pass1')
.then(assertSuccess)
.then(() => console.log('登录成功'));
逻辑分析:
assertSuccess函数检查响应码是否为 0(成功状态)。- 若失败,抛出错误并中断后续流程。
4.2.3 脚本沙箱环境与错误隔离策略
为了防止脚本之间相互干扰,node_robot 提供了脚本沙箱机制,每个脚本运行在独立上下文中。
const vm = new VM({
sandbox: {
client: clientInstance,
console: console
}
});
vm.run(`
client.login('user1', 'pass1')
.then(() => client.enterDungeon(5001))
.catch((err) => console.error('沙箱内错误:', err.message));
`);
参数说明:
VM:Node.js 提供的虚拟机模块,用于创建隔离的执行环境。sandbox:限制脚本访问的变量与对象,防止全局污染。
4.3 行为脚本的动态加载与热更新机制
在自动化测试过程中,脚本更新频繁,传统的重启加载方式效率低下。因此,node_robot 支持脚本的动态加载与热更新。
4.3.1 文件监听与模块重载实现
通过 Node.js 的 fs.watch 实现文件变更监听,并在检测到脚本更新后重新加载模块。
fs.watch(scriptPath, (eventType, filename) => {
if (eventType === 'change') {
console.log(`检测到脚本变更,重新加载...`);
delete require.cache[require.resolve(scriptPath)];
const newScript = require(scriptPath);
newScript.run(client);
}
});
逻辑分析:
- 监听文件变更事件。
- 清除模块缓存,重新加载脚本。
- 调用
run方法执行新逻辑。
4.3.2 运行时上下文保存与恢复机制
为了在热更新时不丢失当前测试状态,我们采用上下文保存与恢复机制。
let context = {
currentDungeonId: 5001,
lastSkillTime: Date.now()
};
function saveContext() {
fs.writeFileSync('context.json', JSON.stringify(context));
}
function loadContext() {
if (fs.existsSync('context.json')) {
context = JSON.parse(fs.readFileSync('context.json'));
}
}
逻辑分析:
saveContext将当前测试状态持久化到文件。loadContext在脚本重启时恢复状态。
4.3.3 版本兼容性与脚本回滚支持
为了应对脚本更新导致的不兼容问题,我们支持版本控制与回滚机制。
scripts/
├── v1/
│ └── login.js
├── v2/
│ └── login.js
└── current -> v2/
通过软链接 current 指向当前版本,热更新时只需切换软链接即可完成版本切换。
4.4 实践示例:实现一个完整的副本挑战流程
在本节中,我们将演示如何使用 JavaScript 脚本实现一个完整的副本挑战流程,涵盖组队、进入副本、战斗控制、奖励领取等关键环节。
4.4.1 组队邀请、进入场景与怪物拉怪逻辑模拟
async function startDungeonTest() {
await client.login('user1', 'pass1');
await client.createTeam(1001); // 创建队伍
await client.inviteMember('user2'); // 邀请队友
await client.acceptInvite(); // 用户2接受邀请
await client.enterDungeon(5001); // 进入副本
await client.pullMonster(6001); // 拉怪
}
逻辑分析:
- 异步流程控制使用
async/await,提升可读性。 - 每个操作封装为独立函数,便于调试与复用。
4.4.2 技能释放节奏与冷却时间精准控制
在战斗中,技能释放节奏对服务器压力测试尤为重要。我们通过定时器与冷却时间控制技能释放。
function useSkill(skillId) {
if (canUseSkill(skillId)) {
client.send('use_skill', { skill_id: skillId });
lastUsedTime[skillId] = Date.now();
}
}
function canUseSkill(skillId) {
const cooldown = getSkillCooldown(skillId);
return Date.now() - (lastUsedTime[skillId] || 0) >= cooldown;
}
// 每秒检查是否可释放技能
setInterval(() => {
if (inBattle) {
useSkill(101); // 释放技能101
}
}, 1000);
参数说明:
skillId:技能唯一标识。cooldown:技能冷却时间(毫秒)。lastUsedTime:记录上次释放时间。
4.4.3 战斗结束后的奖励领取与数据一致性验证
副本挑战结束后,系统通常会发放奖励,我们需要验证奖励是否正确发放。
client.on('dungeon_complete', (data) => {
console.log('副本挑战完成,奖励ID:', data.reward_id);
assert(data.gold > 0, '金币奖励缺失');
assert(data.items.length > 0, '物品奖励缺失');
client.claimReward(data.reward_id);
});
逻辑分析:
- 监听副本完成事件。
- 使用断言验证奖励数据完整性。
- 自动调用领取奖励接口。
至此,我们已完成本章内容的完整展开,从用户行为建模、脚本编写、动态加载机制到完整副本流程的实现,全面展示了如何利用 JavaScript 在 node_robot 中构建高效的测试脚本系统。下一章将深入探讨高并发压力测试与负载能力评估,敬请期待。
5. 高并发压力测试与负载能力评估
在现代在线游戏系统中,服务器必须能够支撑成千上万甚至数十万用户的并发访问。随着MMO(大型多人在线)类游戏的普及,用户行为高度耦合、数据频繁同步、广播消息密集推送等特性使得服务端面临巨大的性能挑战。传统的功能测试仅验证逻辑正确性,难以暴露系统在极限负载下的瓶颈。因此, 高并发压力测试 成为保障线上服务质量不可或缺的一环。本章将深入探讨如何基于 node_robot 框架设计并执行大规模并发测试,评估目标服务器的负载能力,并通过科学的数据采集与分析手段识别潜在性能问题。
压力测试不仅是“打满连接”那么简单,它涉及连接建模、流量控制、资源监控、结果量化等多个维度。尤其在分布式架构下,单一指标无法全面反映系统健康状态。为此,需构建一套完整的压测体系,涵盖从客户端模拟到服务端响应再到数据分析的全链路闭环。以下章节将围绕这一目标展开,系统阐述并发模型的设计原理、压测策略的制定方法、监控系统的集成方式以及真实场景下的实战应用。
5.1 并发模型设计与连接规模扩展
要实现对游戏服务器的有效压力测试,首先需要解决的核心问题是:如何在有限的物理资源下模拟海量客户端连接?这不仅依赖于网络协议栈的优化,更要求在程序架构层面做出合理取舍。一个高效的并发模型应当兼顾连接密度、内存占用和调度效率,在单机或集群环境中均可灵活扩展。
5.1.1 单机百万连接的可能性与限制因素
理论上,Linux 系统支持高达数百万个 TCP 连接,受限于文件描述符数量、内存容量及内核参数配置。但在实际压测中,达到“百万级”连接并非易事,往往受制于以下几个关键因素:
| 限制因素 | 描述 | 调优建议 |
|---|---|---|
| 文件描述符上限 | 每个 TCP 连接占用一个 fd,默认限制为 1024 | 修改 /etc/security/limits.conf 提升 soft/hard limit |
| 内存消耗 | 每个连接至少占用几 KB 至十几 KB 内存(包括 socket 缓冲区、对象元数据) | 使用内存池减少碎片,启用共享缓冲区机制 |
| 网络带宽 | 高频心跳包或广播消息会迅速耗尽出口带宽 | 合理设置心跳间隔,使用压缩编码降低传输体积 |
| CPU 上下文切换开销 | 过多线程会导致频繁上下文切换,降低吞吐量 | 采用事件驱动 + 单线程或多 Reactor 模式避免锁竞争 |
以 node_robot 的 C++ 核心为例,其底层基于 epoll 实现非阻塞 I/O 多路复用,配合 线程池 + 主从 Reactor 模式 ,能够在单进程内高效管理数十万个连接。如下图所示为典型的主从 Reactor 架构流程:
graph TD
A[Main Reactor] -->|Accept 新连接| B(IO Thread Pool)
B --> C{Connection}
C --> D[TCP Socket]
D --> E[Read Event]
E --> F[Decode Message]
F --> G[Enqueue to Worker Queue]
G --> H[Worker Thread]
H --> I[Process Logic]
I --> J[Encode & Write Back]
J --> K[Send via epoll]
该模型中,Main Reactor 负责监听 accept 事件,将新连接分配给 IO 线程池中的某个子 Reactor;每个子 Reactor 独立管理一组连接的读写事件,解码后交由工作线程处理业务逻辑。这种设计有效避免了多线程锁竞争,同时保持高并发处理能力。
内存优化实践:连接对象复用机制
为了进一步降低内存开销, node_robot 引入了 连接对象池(Connection Pool) 和 内存池(Memory Pool) 双重优化策略。每次建立新连接时,并不直接 new 对象,而是从预分配的对象池中获取;关闭连接后则归还而非销毁。相关代码片段如下:
class ConnectionPool {
private:
std::vector<Connection*> pool_;
std::atomic<size_t> index_{0};
static constexpr size_t MAX_CONN = 1'000'000;
public:
void init() {
pool_.reserve(MAX_CONN);
for (size_t i = 0; i < MAX_CONN; ++i) {
pool_.push_back(new Connection());
}
}
Connection* acquire() {
size_t idx = index_++ % MAX_CONN;
return pool_[idx];
}
void release(Connection* conn) {
// 清空状态,准备复用
conn->reset();
}
};
逐行解读:
- 第 3 行:定义私有成员变量
pool_存储所有预创建的连接对象。 - 第 7 行:
MAX_CONN设置最大连接数为 100 万,作为池容量上限。 - 第 12–18 行:
init()函数预先创建全部连接对象,避免运行时动态分配导致延迟波动。 - 第 20–24 行:
acquire()使用原子计数器轮询获取可用连接,保证线程安全且无锁。 - 第 26–30 行:
release()不真正释放内存,而是调用reset()清除旧状态供下次复用。
此机制可使每连接平均内存占用下降约 30%,显著提升单机可承载的最大连接数。
5.1.2 多进程/多实例部署下的资源隔离方案
当单机连接数逼近硬件极限时,必须引入横向扩展机制。常见的做法是启动多个 node_robot 测试代理进程,分布在不同机器或容器中,统一由中央控制器调度。此时需解决的关键问题是: 如何实现资源隔离与任务协调?
一种可行架构如下表所示:
| 角色 | 职责 | 技术实现 |
|---|---|---|
| Master Controller | 统一管理压测计划、分发脚本、聚合数据 | WebSocket + REST API |
| Agent Node (Worker) | 执行具体连接模拟与行为脚本 | node_robot 多实例 |
| Shared Storage | 共享脚本、配置、状态快照 | Redis 或 etcd |
| Metrics Exporter | 上报本地性能指标 | Prometheus Client SDK |
在此架构中,Master 发送压测指令至各 Agent,Agent 根据指定并发数启动对应数量的虚拟用户(Virtual User),并通过心跳机制汇报当前负载状态。所有 Agent 使用相同的脚本版本但独立运行,确保故障不影响全局。
此外,还需注意操作系统级别的资源隔离。例如在 Docker 容器中运行 agent 时,应设置合理的 --memory , --cpus , --ulimit nofile 参数,防止某一实例耗尽主机资源。示例命令如下:
docker run -d \
--name robot-agent-01 \
--memory="8g" \
--cpus=4 \
--ulimit nofile=1048576:1048576 \
robot-agent:latest \
--concurrency=200000 \
--server=game-server.prod.local
上述命令限制容器最多使用 8GB 内存、4 核 CPU,并允许打开最多 100 万文件描述符,从而保障稳定运行。
5.1.3 连接数、吞吐量与响应延迟的平衡取舍
在实际压测过程中,不能盲目追求“最高连接数”,而应综合考虑三大核心指标之间的关系:
- 连接数(Concurrent Connections) :表示同时在线的虚拟用户数量。
- 吞吐量(Throughput, QPS/TPS) :单位时间内成功处理的请求数。
- 响应延迟(Latency) :请求发出到收到回复的时间差,常用 P50/P95/P99 统计。
三者之间存在明显的权衡关系。如下图所示:
graph LR
A[低连接数] --> B[低延迟、高吞吐]
C[中等连接数] --> D[适度延迟、稳定吞吐]
E[高连接数] --> F[延迟飙升、吞吐下降]
初期阶段,随着连接增长,系统利用率提高,吞吐上升;但超过某一阈值后,CPU 或数据库 IO 成为瓶颈,响应时间急剧拉长,部分请求超时失败,整体吞吐反而下降。因此,理想的压力测试应找到系统的“最佳工作点”——即在可接受延迟范围内实现最大吞吐。
为此, node_robot 提供了动态调节机制,可在运行时根据反馈调整行为频率。例如:
// JavaScript 脚本中动态控制请求速率
const user = context.getUser();
setInterval(() => {
const currentLatency = metrics.getP99Latency('login');
if (currentLatency > 500) {
user.throttle(0.7); // 延迟过高,降速 30%
} else if (currentLatency < 200) {
user.throttle(1.2); // 延迟低,提速 20%
}
}, 10000);
逻辑分析:
- 第 4 行:获取最近一分钟登录接口的 P99 延迟。
- 第 5–7 行:若延迟超过 500ms,说明服务紧张,主动降低请求频率至原速率的 70%。
- 第 8–10 行:若延迟低于 200ms,说明系统空闲,适当增加负载以探测上限。
- 第 11 行:每 10 秒检查一次,形成闭环反馈。
该机制有助于在不压垮服务器的前提下逐步逼近其真实承载能力。
5.2 压力测试执行策略制定
成功的压力测试离不开科学的执行策略。简单粗暴地瞬间拉起全部连接可能导致网络拥塞或服务雪崩,无法准确反映渐进式负载下的系统表现。因此,必须设计合理的加压模式、明确定义观测指标,并精准定位瓶颈所在。
5.2.1 阶梯式加压与突增流量测试场景设计
常用的压测模式包括:
- 阶梯式加压(Step Load) :每隔固定时间增加一批用户,观察系统在不同负载层级的表现。
- 峰值冲击(Spike Test) :短时间内突然注入大量请求,检验系统抗突发能力。
- 持续负载(Soak Test) :长时间维持高压,检测内存泄漏或性能衰减。
- 混合场景(Hybrid Scenario) :结合多种操作类型(登录、移动、战斗、聊天)模拟真实用户分布。
以某 MMO 登录压测为例,设计如下阶梯式加压计划:
| 时间段(分钟) | 新增并发用户 | 累计在线用户 | 操作类型 |
|---|---|---|---|
| 0–2 | 10,000/min | 0 → 20,000 | 登录认证 |
| 2–4 | 20,000/min | 20k → 60k | 登录 + 心跳 |
| 4–6 | 30,000/min | 60k → 120k | 登录 + 场景进入 |
| 6–10 | 保持 120k | 稳定运行 | 混合行为 |
| 10–12 | 断开 60k 用户 | 下降至 60k | 模拟离线潮 |
此类计划可通过 node_robot 的控制器 API 动态下发:
{
"scenario": "login_stress",
"steps": [
{"duration": 120, "ramp_up": 10000, "action": "login"},
{"duration": 120, "ramp_up": 20000, "action": "login_with_heartbeat"},
{"duration": 120, "ramp_up": 30000, "action": "enter_scene"},
{"duration": 240, "ramp_up": 0, "action": "mixed_behavior"},
{"duration": 120, "ramp_down": 60000, "action": "disconnect"}
]
}
该 JSON 配置定义了一个五阶段压测流程,由 master 控制器解析并分发至各 agent 执行。每个阶段结束后自动采集 KPI 数据,便于后续对比分析。
5.2.2 关键性能指标(KPI)定义与采集方式
有效的压测必须建立在可观测性基础上。以下是必须采集的核心 KPI 及其采集方法:
| KPI 类别 | 指标名称 | 采集方式 | 目标阈值 |
|---|---|---|---|
| 连接层 | 在线连接数、连接成功率 | epoll 事件统计 + 日志埋点 | ≥99.9% 成功率 |
| 请求层 | QPS、平均延迟、P99 延迟 | 请求计时器 + 滑动窗口统计 | P99 ≤ 300ms |
| 错误率 | 超时率、协议错误率 | 回调函数捕获异常 | ≤0.5% |
| 资源层 | CPU 使用率、内存占用、网络带宽 | /proc/stat、getrusage()、iftop | CPU ≤80% |
| 存储层 | DB 查询耗时、Redis 命令延迟 | SQL 日志解析、Redis SLOWLOG | avg ≤50ms |
在 node_robot 中,这些指标通过内置的 MetricsCollector 模块实时汇总:
class MetricsCollector {
public:
void recordRequest(const std::string& api, uint64_t latency_us) {
auto& bucket = time_series_[api];
bucket.push_back(latency_us);
}
double getP99(const std::string& api) {
auto& data = time_series_[api];
std::sort(data.begin(), data.end());
size_t idx = static_cast<size_t>(data.size() * 0.99);
return data[idx] / 1000.0; // us -> ms
}
private:
std::map<std::string, std::vector<uint64_t>> time_series_;
};
参数说明:
recordRequest():记录每次请求的 API 名称与微秒级延迟。getP99():计算指定接口的 P99 延迟,用于判断尾部延迟是否达标。time_series_:按 API 分组存储历史延迟数据,支持滑动窗口清理。
该模块每 10 秒输出一次摘要日志,并通过 gRPC 推送至 Prometheus,供 Grafana 展示。
5.2.3 服务端瓶颈点识别:CPU、内存、IO与网络
当压测过程中出现性能劣化时,需快速定位根源。常见瓶颈包括:
- CPU 密集型 :如序列化/反序列化、加密运算过多。
- 内存瓶颈 :频繁 GC(Node.js)、堆外内存泄漏(C++)。
- 磁盘 IO :数据库写入延迟高、日志刷盘阻塞。
- 网络瓶颈 :带宽饱和、TCP 重传率升高。
可通过以下工具链进行诊断:
# 查看 CPU 使用情况
top -H -p $(pgrep game_server)
# 监控内存分配
valgrind --tool=massif ./game_server
# 分析网络丢包与重传
tcpdump -i eth0 'tcp port 8080' | grep "Retransmission"
# 数据库慢查询追踪
mysqlslow -s c -t 10 /var/log/mysql-slow.log
结合 node_robot 自身上报的客户端视角延迟,与服务端 APM(如 SkyWalking)数据交叉比对,可精准定位延迟发生在哪一环节。例如,若客户端测得延迟高但服务端日志显示处理很快,则问题可能出在网络传输或客户端自身调度延迟。
5.3 测试结果的数据采集与可视化分析
仅有原始数据不足以支撑决策,必须将其转化为直观可视的信息。现代压测系统普遍依赖 Prometheus + Grafana 构建实时监控仪表盘,实现多维度联动分析。
5.3.1 实时监控仪表盘搭建(Prometheus + Grafana)
在 node_robot 中,通过集成 prom-client 库暴露指标端点:
const client = require('prom-client');
const httpRequestDuration = new client.Histogram({
name: 'robot_http_request_duration_ms',
help: 'Duration of HTTP requests made by robot',
labelNames: ['api', 'status'],
buckets: [10, 50, 100, 200, 500]
});
// 在请求回调中记录
httpRequestDuration
.labels({ api: '/login', status: '200' })
.observe(responseTimeMs);
Prometheus 定期抓取 /metrics 接口,Grafana 配置面板展示趋势图:
- 折线图:QPS 随时间变化
- 热力图:P99 延迟分布
- 饼图:各类错误占比
- 仪表盘:当前在线用户数
(注:此处为示意链接,实际部署中应截图展示真实仪表盘)
5.3.2 请求成功率、平均延迟与P99统计图表生成
以下为某次压测后的典型数据图表描述:
| 并发等级 | QPS | 平均延迟(ms) | P99延迟(ms) | 成功率(%) |
|---|---|---|---|---|
| 20k | 85k | 48 | 120 | 99.98 |
| 60k | 190k | 92 | 280 | 99.92 |
| 120k | 210k | 203 | 670 | 99.65 |
从表中可见,当并发达 120k 时,P99 延迟突破 600ms,已超出 SLA 要求(≤300ms),表明系统已达性能拐点。建议将生产环境最大负载控制在 60k 左右。
5.3.3 数据导出与报告自动生成机制
测试结束后, node_robot 支持一键生成 PDF 报告,包含:
- 测试概览(时间、目标、参与节点)
- 核心 KPI 汇总表
- 趋势图集合
- 异常事件列表
- 优化建议
生成逻辑封装为 CLI 命令:
node_robot report generate \
--input=data/latest.json \
--template=stress-template.md \
--output=report.pdf
报告模板采用 Markdown + Jinja2 混合语法,支持动态插入图表和统计数据,极大提升交付效率。
5.4 实战案例:对某MMO服务器进行全链路压测
选取一款上线前的 MMORPG 项目,使用 node_robot 集群模拟十万在线用户,覆盖登录、场景同步、战斗广播等核心链路。
5.4.1 模拟十万在线用户的登录洪峰冲击
设定前 5 分钟完成全部登录,采用指数加压:
for (let i = 0; i < 100000; i++) {
setTimeout(() => {
loginRobot(i);
}, Math.pow(i, 0.8) * 10); // 指数递增延迟
}
结果:98.7% 用户在 30 秒内完成登录,最大瞬时 QPS 达 15k,MySQL 连接池一度耗尽,后经扩容至 500 连接解决。
5.4.2 战斗广播消息风暴下的广播扩散测试
模拟 100 个战场同时开战,每个战场 500 玩家,每秒广播位置更新:
message PlayerUpdate {
int32 uid = 1;
float x = 2;
float y = 3;
repeated Buff buffs = 4;
}
压测发现 Redis 频道订阅延迟升高,P99 达 1.2s。改用 Kafka 分片广播后降至 210ms。
5.4.3 数据库写入瓶颈暴露与缓存优化建议
角色下线时批量写入背包数据,原设计为逐条 UPDATE,导致 DB CPU 占用 95%。建议改为:
- 写前先写 Redis Stream
- 后台 Worker 批量合并写入 MySQL
- 引入 LSM-Tree 结构优化高频写场景
优化后 TPS 提升 4.3 倍,平均延迟下降 76%。
6. 服务器异常检测与容错机制测试
6.1 常见服务器故障模式分类与模拟手段
在大规模在线游戏系统中,服务器的高可用性依赖于健全的容错机制。然而,这些机制的有效性必须通过主动注入真实世界中可能发生的各类故障来验证。node_robot框架设计了多层次的异常模拟能力,覆盖网络、服务进程、数据存储等多个维度。
6.1.1 网络分区、延迟抖动与丢包注入技术
网络问题是分布式系统中最常见的异常来源之一。为了精准模拟弱网环境,node_robot集成了Linux下的 tc (Traffic Control)和 netem 模块,支持对客户端连接进行细粒度控制。
以下是一个使用 tc 命令模拟200ms延迟、10%丢包率的示例:
# 启用网络干扰:添加延迟与丢包
sudo tc qdisc add dev eth0 root netem delay 200ms loss 10%
# 查看当前规则
sudo tc qdisc show dev eth0
# 清除规则
sudo tc qdisc del dev eth0 root
| 参数 | 说明 |
|---|---|
delay |
控制报文发送延迟,可附加抖动如 200ms ± 50ms |
loss |
指定丢包概率,适用于UDP/TCP层测试 |
duplicate |
模拟重复包,用于检验去重逻辑 |
corrupt |
随机损坏数据包校验位,触发协议层错误处理 |
在node_robot中,可通过JavaScript脚本调用底层C++封装接口实现自动化配置:
// 调用C++暴露的网络控制API
robot.network.inject({
type: 'latency',
delay: 300,
jitter: 80,
loss: 15,
duration: 60000 // 持续60秒
});
该机制允许测试脚本在特定阶段动态开启网络异常,观察客户端是否能正确进入重连流程并恢复状态。
6.1.2 服务宕机、进程崩溃与主从切换场景复现
服务端进程崩溃或主节点宕机是高可用架构中的关键测试点。node_robot通过SSH远程执行或Kubernetes API直接干预目标服务实例,实现“主动杀进程”类操作。
例如,在K8s环境中模拟网关服务崩溃:
# 删除指定Pod以触发重建
kubectl delete pod game-gateway-7d6f9c4b7-zxklp -n gamesvr
# 观察新Pod启动时间与注册延迟
kubectl get pods -n gamesvr -w
同时,机器人集群持续发送心跳请求,并记录以下指标:
- 断连到重连成功的时间间隔(RTO)
- 是否自动路由至备用接入节点
- 用户会话是否保持有效(token有效性)
6.1.3 数据库锁表、Redis超时等依赖故障模拟
现代游戏服务器普遍依赖外部中间件。node_robot通过代理层拦截数据库访问流量,或直接在MySQL/Redis服务器上设置超时策略,模拟后端响应缓慢或不可达的情况。
-- 在MySQL中制造长时间锁表现象
BEGIN;
UPDATE players SET gold = gold + 100 WHERE uid = 1001;
-- 不提交事务,持续60秒
SELECT SLEEP(60);
COMMIT;
Redis层面可通过 CONFIG SET timeout 1 将空闲连接快速断开,测试客户端连接池回收逻辑。
6.2 容错机制的有效性验证方法
6.2.1 自动重连机制的触发条件与成功率统计
当检测到连接中断时,客户端应按照指数退避策略尝试重连。node_robot内置统计模块,记录每次断线后的重试行为:
{
"session_id": "sess_7a8b9c",
"disconnect_time": "2025-04-05T10:23:45Z",
"reconnect_attempts": [
{ "attempt": 1, "delay": 1000, "success": false },
{ "attempt": 2, "delay": 2000, "success": false },
{ "attempt": 3, "delay": 4000, "success": true }
],
"total_recovery_time_ms": 7120
}
通过聚合十万次会话数据,生成如下统计表格:
| 重连尝试次数 | 成功率 (%) | 平均耗时 (ms) |
|---|---|---|
| 1 | 68.2 | 980 |
| 2 | 89.5 | 2100 |
| 3 | 96.7 | 4300 |
| 4+ | 99.1 | 8200 |
结果表明,三次以内重连可覆盖绝大多数场景,建议业务层设置最大重试上限为3次。
6.2.2 会话保持与数据补偿逻辑的正确性检验
在短时断线情况下,服务器应支持会话恢复而不强制重新登录。node_robot通过比对断线前后角色位置、背包状态、任务进度等核心字段,验证状态一致性。
const before = await robot.queryPlayerState();
await robot.simulateNetworkFailure(10000); // 断网10秒
await robot.reconnect();
const after = await robot.queryPlayerState();
assert.deepEqual(after.position, before.position, '角色位置应保持不变');
assert.equal(after.hp, before.hp, '生命值不应因断线归零');
若发现状态丢失,则标记为严重缺陷,需排查会话缓存失效或未持久化问题。
6.2.3 分布式环境下的一致性保障测试
在跨区战斗或交易场景中,多个微服务间的数据同步至关重要。node_robot采用“写前拍照 + 写后比对”方式检测脏读或更新丢失:
sequenceDiagram
participant Robot
participant Gate
participant DB
participant Cache
Robot->>Gate: 发起交易请求(物品A→B)
Gate->>DB: 开启事务,扣减A
Gate->>Cache: 更新用户余额(未提交)
Note right of Gate: 此时注入Redis超时
Gate->>Robot: 返回失败,但DB已部分提交
Robot->>DB: 查询最终状态
alt 状态一致?
DB-->>Robot: 所有变更回滚 or 补偿完成
else 存在不一致
DB-->>Robot: 报告数据偏差
end
通过此类测试发现某版本存在“仅回滚内存状态,未回滚数据库”的致命缺陷,推动引入Saga事务补偿机制。
6.3 node_robot中的异常注入功能实现
6.3.1 网络干扰模块(Netem、TC工具集成)
node_robot的C++核心模块通过 popen() 调用系统级 tc 命令,并抽象为统一接口供Node.js层调用:
// network_injector.cpp
int inject_network_fault(const std::string& iface,
int delay_ms,
int jitter_ms,
int loss_percent) {
std::string cmd = "tc qdisc add dev " + iface +
" root netem delay " + std::to_string(delay_ms) + "ms";
if (jitter_ms > 0) cmd += " " + std::to_string(jitter_ms) + "ms";
if (loss_percent > 0) cmd += " loss " + std::to_string(loss_percent) + "%";
return system(cmd.c_str());
}
V8绑定后可在JS中安全调用:
robot.net.injection.start({
interface: 'eth0',
delay: 500,
jitter: 100,
loss: 20
});
6.3.2 主动关闭连接与非法数据包发送功能
为了测试协议解析健壮性,node_robot支持构造畸形消息:
void send_malformed_packet(int sock) {
char buffer[9] = {0};
// 构造长度字段异常的数据包
*(uint32_t*)&buffer[0] = htonl(0xFFFFFFFF); // 超大长度
*(uint32_t*)&buffer[4] = htonl(0x12345678); // 非法cmd_id
// 第9字节留作越界填充,触发缓冲区溢出检测
send(sock, buffer, 9, 0);
}
服务器若未抛出异常且连接未被立即关闭,则视为存在安全风险。
6.3.3 故障场景配置文件化与一键触发机制
所有异常场景均可通过YAML配置定义,便于回归测试:
scenario: gateway_failure_under_load
description: 网关节点宕机时验证自动转移
steps:
- action: start_load
users: 50000
script: login_and_idle.js
- action: wait
duration: 30s
- action: inject_network_partition
target: gateway-primary
duration: 45s
- action: validate
check: all_clients_reconnected
timeout: 60s
执行指令一键启动整个流程:
node_robot run-scenario ./scenarios/gateway_failure.yaml
简介:“node_robot:游戏服务器测试机器人”是一个使用C++开发的高性能自动化测试系统,专为高并发、实时性要求高的游戏服务器设计。该机器人可模拟大量用户行为,如登录、创建角色、交易和战斗,支持消息收发、压力测试、异常处理与日志记录,并集成于持续集成环境,实现高效、稳定的全面测试。本项目涵盖网络编程、协议解析、性能优化等核心技术,具备良好可扩展性,适用于多种游戏架构,帮助开发者提升测试效率,降低上线风险。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)