【大模型训练】Distributed Optimizer
这张图生动地描绘了 ZeRO-2 在一个训练步中如何通过**分片(Sharding)和计算梯度: 各自计算完整梯度。规约并分片梯度 (: 汇总所有梯度并只保留自己负责的一小部分,释放梯度占用的显存。分片式更新 (Optim Step: 使用分片的梯度,更新分片的参数(这背后是分片的优化器状态),节省了优化器状态占用的显存。收集并重建参数 (All-Gather: 从所有rank收集更新后的参数分片
好的,这是一份对这张图的详细解释。
这张图清晰地展示了 ZeRO (Zero Redundancy Optimizer) 优化器 Stage 2 的核心工作流程。ZeRO 是一种用于大规模模型分布式训练的优化技术,旨在通过在多个 GPU 之间**分片(sharding)**模型状态来大幅减少单个 GPU 的显存占用。
让我们一步步解析这个图。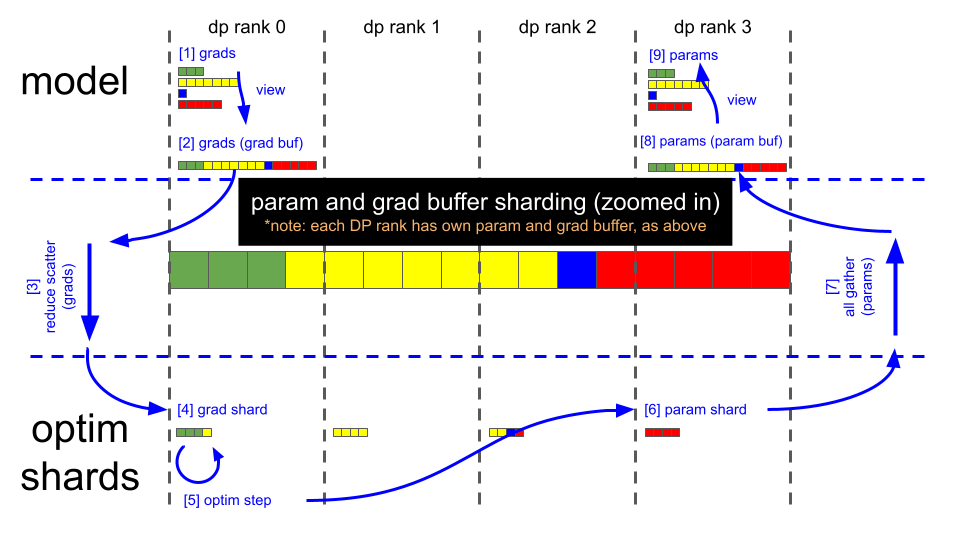
核心概念解读
在深入步骤之前,先理解图中的关键元素:
- dp rank 0, 1, 2, 3: 这代表一个**数据并行(Data Parallelism, DP)**组中有 4 个 GPU(或进程)。每个
rank是一个独立的计算单元。 - model: 指代神经网络模型本身。在 ZeRO-2 中,每个
rank在训练开始(前向传播)时都拥有一份完整的模型参数副本。 - optim shards: 指代优化器状态分片。这是 ZeRO 的核心。像 Adam 这样的优化器需要为每个模型参数存储额外的状态(如动量和方差),这通常会使显存需求增加两倍。ZeRO 将这些优化器状态分片,每个
rank只负责存储和更新其中一部分。 - params (Parameters): 模型的权重。
- grads (Gradients): 在反向传播后计算出的梯度,用于更新模型参数。
- param and grad buffer sharding (zoomed in): 中间这个放大的条形图是一个概念示意图。它展示了完整的模型参数/梯度是如何被逻辑上划分为 4 个分片(用不同颜色表示:绿、黄、蓝、红)的,每个分片对应一个
dp rank。
训练步骤详解 (按图中数字顺序)
整个流程从一次前向传播和反向传播完成之后开始。此时,每个 dp rank 都使用自己的数据批次计算出了一份针对完整模型的梯度。
步骤 [1] & [2]: 梯度缓冲 (Gradient Buffering)
- [1] grads: 反向传播完成后,模型的梯度(
grads)可能以非连续的方式存储在显存中,对应着模型的各个层。 - [2] grads (grad buf): 为了提高通信效率,系统会将这些零散的梯度拷贝到一个连续的显存块中,即梯度缓冲区(
grad buf)。图中view箭头表示的就是这个整理数据的过程。对一个大块内存进行单次通信,远比对许多小块内存进行多次通信要快。
步骤 [3] & [4]: 梯度规约与分发 (Reduce Scatter)
- [3] reduce scatter (grads): 这是 ZeRO-2 的关键一步,也是与标准数据并行(只用
All-Reduce)最大的不同之处。reduce scatter是一个复合通信操作,它包含两个动作:- Reduce (规约): 将所有 4 个
rank上的梯度缓冲区(grad buf)逐元素相加并求平均。这样就得到了全局的、正确的平均梯度。 - Scatter (分发): 紧接着,它并不会把完整的平均梯度广播给所有
rank,而是将这个完整的梯度缓冲区切片,每个rank只接收它所负责的那一部分。
- Reduce (规约): 将所有 4 个
- [4] grad shard:
reduce scatter操作的结果。dp rank 0接收到绿色的梯度分片,dp rank 1接收到黄色的,以此类推。现在,每个rank只持有全部梯度的 1/4,显存占用大幅降低。
步骤 [5]: 优化器更新 (Optim Step)
- [5] optim step: 每个
rank使用它刚刚收到的梯度分片(grad shard),去更新它所保管的那一部分模型参数。重要的是,每个rank只持有与其参数分片相对应的优化器状态分片。例如,dp rank 0只需动用它本地存储的、用于更新绿色参数分片的优化器状态来执行更新计算。 - 内存节省点:
- 梯度: 每个 GPU 只保存 1/N 的梯度 (N 是 DP rank 数量)。
- 优化器状态: 每个 GPU 只保存 1/N 的优化器状态。这是最主要的显存节省来源。
步骤 [6]: 更新后的参数分片 (Param Shard)
- [6] param shard: 优化器步骤完成后,每个
rank就拥有了自己负责的那一部分更新后的参数分片。例如,dp rank 0现在有了最新的绿色参数。
步骤 [7], [8], [9]: 同步并重建完整参数 (All-Gather)
- [7] all gather (params): 为了准备下一次的前向传播(前向传播需要完整的模型),所有
rank需要同步彼此的更新结果。all gather是一个“全体集合”操作,每个rank将自己的参数分片(param shard)发送给所有其他rank。 - [8] params (param buf):
all gather完成后,每个rank都集齐了所有分片(绿、黄、蓝、红),并在本地将它们重新组合成一个完整且连续的参数缓冲区(param buf)。 - [9] params: 最后,系统通过一个
view操作,将这个连续的参数缓冲区“映射”回模型中各个层对应的参数结构。至此,每个rank上都有了一份完整的、更新后的模型参数,准备好进行下一次的迭代(forward/backward pass)。
总结
这张图生动地描绘了 ZeRO-2 在一个训练步中如何通过**分片(Sharding)和集合通信(Collective Communication)**来管理显存:
- 计算梯度: 各自计算完整梯度。
- 规约并分片梯度 (
Reduce Scatter): 汇总所有梯度并只保留自己负责的一小部分,释放梯度占用的显存。 - 分片式更新 (
Optim Step): 使用分片的梯度,更新分片的参数(这背后是分片的优化器状态),节省了优化器状态占用的显存。 - 收集并重建参数 (
All-Gather): 从所有rank收集更新后的参数分片,重建完整的模型,为下一次迭代做准备。
通过这个“分发-更新-聚合”的循环,ZeRO-2 成功地将梯度和优化器状态的显存开销均摊到了所有 GPU 上,从而让有限的单卡显存能够训练远超其容量的大模型。
好的,这是对这段英文描述的翻译和详细解释。这段文字以上一幅图为基础,更具体地描述了在**混合精度训练(Mixed Precision Training)**场景下,ZeRO-2 的一个完整优化步骤。
原文翻译
关键步骤
(注:使用上文图示,假设模型权重为 bf16 格式,反向传播计算出的模型梯度也是 bf16 格式,而用于优化器步骤的 fp32 主梯度;我们总是使用 fp32 主权重来进行优化器更新)
- 反向传播结束(此时梯度缓冲区中持有 16 个 fp32 格式的梯度元素)。
- 在每个 DP rank 上调用
reduce-scatter操作。 - 现在,每个 DP rank 的梯度缓冲区中拥有 4 个已经完全规约(reduced)好的元素(缓冲区中其余的 12 个元素是无用数据)。
- DP rank 0 拥有元素 [0:4] 的梯度值。
- DP rank 1 拥有元素 [4:8] 的梯度值。
- DP rank 2 拥有元素 [8:12] 的梯度值。
- DP rank 3 拥有元素 [12:16] 的梯度值。
- 执行
Optimizer.step()。 - 每个 DP rank 将其 4 个 fp32 格式的主参数元素(main parameter)复制到对应的 bf16 参数缓冲区中(每个元素都从 fp32 向下转型为 bf16)。
- 在每个 DP rank 上调用
all-gather操作。 - 现在,参数缓冲区包含了全部 16 个、已完全更新的、bf16 格式的模型参数元素。PyTorch 模块中的参数已经指向了这个参数缓冲区中的相应位置,因此,一旦
all-gather完成,就可以立即开始执行下一次的前向传播。 - 此时,梯度缓冲区也准备就绪,可以被清零以用于下一次迭代。
详细解读
这段文字的核心是解释了 ZeRO-2 如何与混合精度训练相结合,以在保持训练稳定性的同时最大化效率和显存节省。
1. 混合精度训练背景
首先,理解文中的几个关键数据类型:
- bf16 (BFloat16): 一种 16 位浮点数格式。它的数值范围与 32 位浮点数(fp32)相同,但精度较低。由于位数少,它在计算和存储上都更快、更省显存,非常适合用于模型的前向和反向传播。
- fp32 (FP32): 标准的 32 位浮点数。精度高,是传统训练的默认格式。
- fp32 主权重 (main weights) / 主梯度 (main gradients): 在混合精度训练中,为了避免在多次迭代中因使用低精度(如 bf16 或 fp16)累加更新而导致的精度损失,通常会在后台维护一份高精度(fp32)的模型参数副本。优化器的更新步骤(
optimizer.step)是作用在这份 fp32 副本上的。这份高精度副本被称为“主参数”或“主权重”。
所以,整个流程是:
- 计算:使用
bf16权重和梯度进行快速的前向/反向传播。 - 更新:将
bf16梯度转换为fp32,然后用它来更新fp32的主权重,以保证更新的准确性。 - 同步:将更新后的
fp32主权重转换回bf16,用于下一次的计算。
2. 步骤分解(结合图示)
让我们把文本描述和图中的步骤对应起来: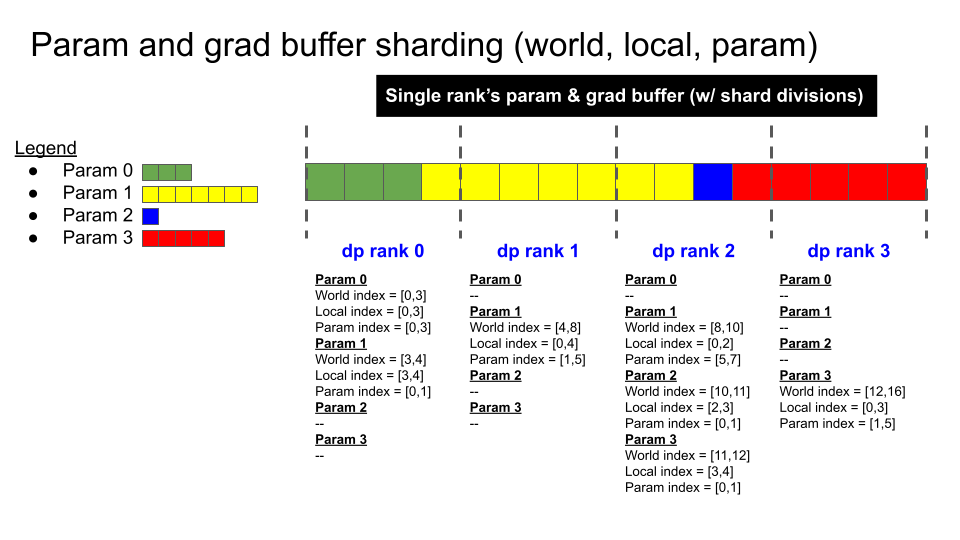
-
反向传播结束:
- 此时,每个 DP rank 都计算出了一份
bf16格式的完整梯度。 - 文本中提到“梯度缓冲区中持有 16 个 fp32 梯度元素”,这隐含了一个步骤:框架自动将
bf16梯度累加并转换到一个高精度的fp32梯度缓冲区中。这对应图中的 [1] 和 [2],但增加了类型转换的细节。
- 此时,每个 DP rank 都计算出了一份
-
调用
reduce-scatter:- 这完全对应图中的步骤 [3]。
- 所有 DP rank 上的
fp32梯度缓冲区被相加并求平均,然后结果被切片分发。 - 操作完成后,
DP rank 0获得了参数[0:4]对应的最终fp32梯度,DP rank 1获得[4:8]的梯度,以此类推。这对应图中的步骤 [4]。 - “其余 12 个元素是无用数据”:因为
reduce-scatter只保证目标分片的数据是正确的,缓冲区里的其他位置没有被定义,可以视为垃圾数据。
-
执行
Optimizer.step():- 这对应图中的步骤 [5]。
- 关键点:每个 DP rank 使用它收到的那一小部分
fp32梯度,去更新它在本地维护的那一小部分fp32主权重。 - 例如,
DP rank 0用[0:4]的梯度去更新[0:4]的fp32主权重。
-
fp32 -> bf16 转换与复制:
- 更新是在
fp32主权重上完成的,但下一次前向传播需要bf16权重。 - 因此,每个 DP rank 将自己刚刚更新好的那一小部分
fp32主权重向下转型(cast)为bf16格式,并放回参数缓冲区。这对应图中的步骤 [6],即生成了更新后的bf16参数分片 (param shard)。
- 更新是在
-
调用
all-gather:- 这对应图中的步骤 [7]。
- 所有 DP rank 互相交换它们更新好的
bf16参数分片。 - 操作完成后,每个 DP rank 的参数缓冲区中都拥有了一份完整的、最新的、
bf16格式的模型参数。这对应图中的步骤 [8] 和 [9]。 - “PyTorch 模块中的参数已经指向了这个参数缓冲区”:这是一个实现上的优化,意味着模型的参数张量(tensor)直接就是这个缓冲区的一个视图(view),无需额外的数据拷贝,可以直接用于下一次计算。
-
清零梯度缓冲区:
- 梯度在完成权重更新后就完成了使命。将梯度缓冲区清零,为下一次迭代的反向传播做准备,可以释放这部分显存。
总结
这段描述为 ZeRO-2 的工作流程补充了混合精度这一重要维度,让解释更加完整和贴近实际应用。整个过程可以概括为:
低精度计算 -> 高精度更新 -> 低精度同步
这个循环既利用了 bf16 的速度和显存优势,又通过 fp32 的主权重保证了训练的稳定性和精度,是现代大规模模型训练的标准实践。
您提的这个问题,正点出了 ZeRO-2 流程中最核心也最容易混淆的地方!
答案是:既是,也不是。这取决于处在训练循环的哪个阶段。
让我们来彻底剖析这个问题,并结合您提供的文本进行解释。
阶段一:在前向传播和反向传播期间 -> 是完整的参数
在模型进行前向传播(Forward Pass)和反向传播(Backward Pass)时,每个 DP rank 必须拥有一份完整的、一模一样的模型参数。
- 为什么? 因为每个 DP rank 都在处理一个不同的数据批次(mini-batch),但它们必须在同一个模型上进行计算,才能保证最终汇总的梯度是有意义的。如果每个 rank 上的模型都不一样,那就变成了在训练不同的模型,整个数据并行的基础就不存在了。
- 如何实现? 这正是我们之前讨论的
All-Gather步骤(图中的步骤 [7])的目的。在上一个优化步骤的最后,每个 rank 把自己更新好的参数分片广播给所有其他 rank,然后在本地重新组装成一个完整的模型,为下一次的计算做好准备。
阶段二:在优化器更新步骤期间 -> 只关心分片的参数
在 optimizer.step() 执行的那个核心阶段,情况就完全不同了。在这个阶段,每个 DP rank 只关心并操作自己负责的那一部分(分片)。
- 为什么? 这就是 ZeRO 节省显存的魔力所在。
reduce-scatter之后,每个 rank 只收到了梯度的分片。- 它在显存里也只存储了优化器状态的分片。
- 因此,它只需要用梯度的分片去更新主参数(main parameters)的分片。
在这个阶段,虽然完整的 bf16/fp16 模型参数还存在于显存中(等待被更新),但优化器实际操作的对象(fp32 主参数)是以分片形式存在的。
动态视角下的完整流程
让我们用一个时间轴来串联这个过程,您会看得更清楚:
- 开始(准备前向传播): 每个 DP rank 上都有一份完整的、更新好的模型参数。
- 前向/反向传播: 使用完整参数进行计算,得到一份完整的梯度。
- 梯度通信 (
reduce-scatter): 完整的梯度被规约、切片并分发。操作结束后,每个 rank 只持有梯度的分片。此时,完整梯度的显存被释放。 - 优化器更新 (
optimizer.step): 每个 rank 使用梯度分片来更新它本地存储的主参数分片,这个过程只动用了优化器状态分片。 - 参数同步 (
all-gather): 每个 rank 将自己更新好的参数分片广播给所有人。 - 结束(回到起点): 每个 rank 接收到所有分片,重新组装成一份完整的、更新好的模型参数,准备下一次迭代。
一句话总结:为了计算,参数是完整的;为了更新和节省显存,参数(及其梯度和优化器状态)被分片处理。
解读您提供的文本和表格
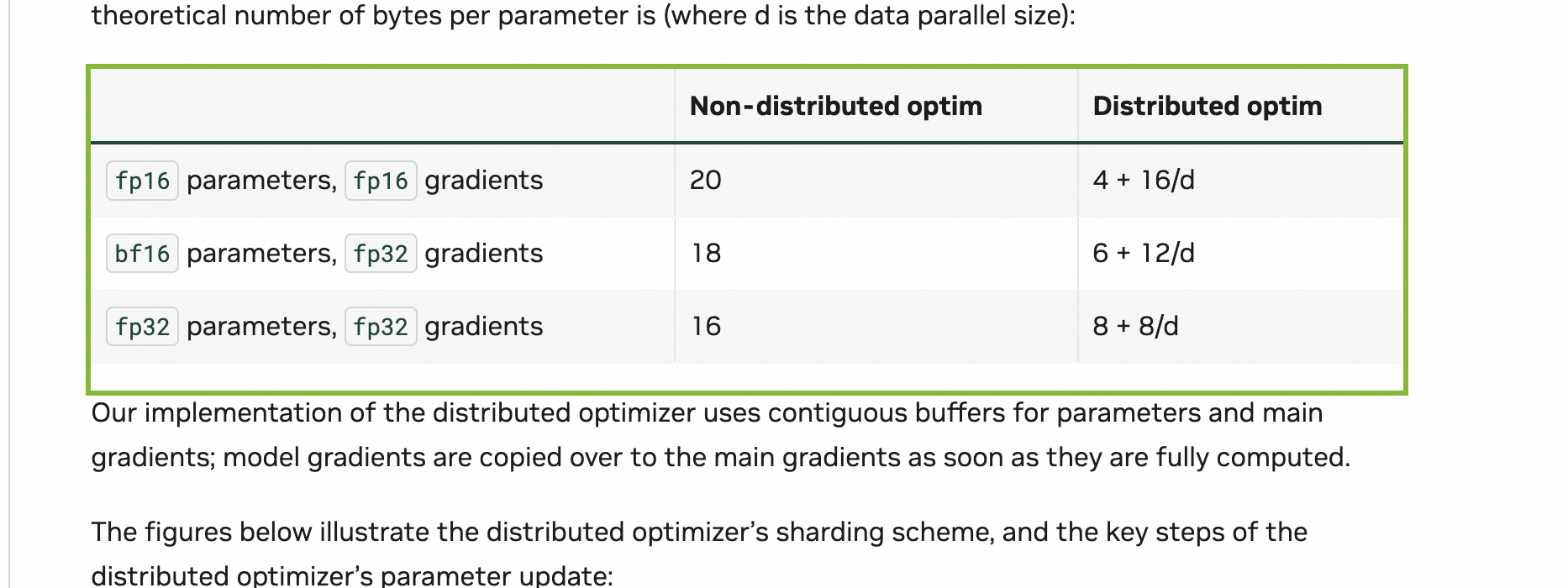
现在我们回头看您提供的文本和表格,一切就都说得通了。以 bf16 parameters, fp32 gradients 这一行为例,它说每个参数消耗 6 + 12/d 字节。
这个公式精确地反映了我们上面讨论的动态过程:
-
6(常数部分): 这部分是不被分片的,每个 rank 都必须完整持有的。它包括:- bf16 模型参数: 2 字节。这是用于前向/反向传播的完整模型。
- fp32 主梯度缓冲区: 4 字节。在
reduce-scatter之前,每个 rank 都需要一个完整的缓冲区来存放从bf16转换来的fp32梯度。 - 合计: 2 + 4 = 6 字节。
-
12/d(分片部分): 这部分是根据 DP rank 数量d进行分片的,是显存节省的核心。它包括:- fp32 主参数: 4 字节。这是优化器真正更新的对象。
- fp32 优化器状态 (Adam): 8 字节 (动量+方差)。
- 合计: 4 + 8 = 12 字节。这 12 字节被分摊到
d个 GPU 上,所以每个 GPU 只承担12/d。
这个公式完美地印证了:模型参数是完整的(体现在常数项里),而优化器相关的部分是分片的(体现在 /d 项里)。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)