支持多模型的视觉页码识别工具,助力档案数字化高效处理
基于先进视觉模型的页码识别软件,兼容多种qwen系列大模型,提升档案数字化效率。
温馨提示:文末有联系方式
高效档案数字化解决方案
本工具专为需要进行大规模文档扫描与归档的用户设计,提供基于视觉AI模型的智能页码识别功能,显著提升档案数字化流程的自动化水平和准确率。
适用于图书馆、档案馆、企业文档中心等场景。
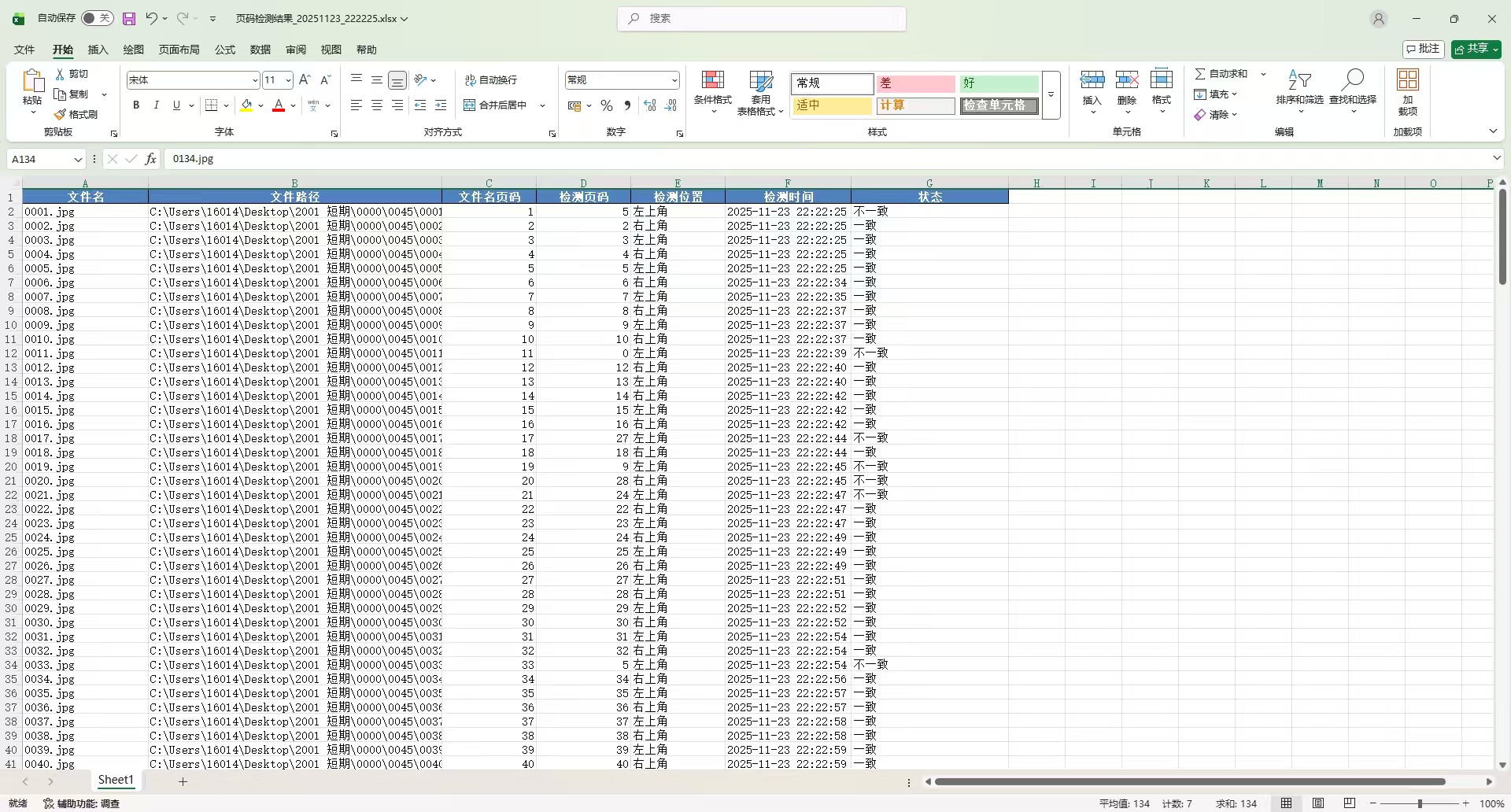
基于视觉AI的页码自动检测技术
系统采用先进的计算机视觉算法,能够从扫描图像中精准定位并识别页面上的页码信息。
支持多种由Ollama平台托管的视觉语言模型,包括qwen2.5vl:7b、qwen3-vl:2b、qwen3-vl:4b以及qwen3-vl:8b等主流型号,模型性能随参数量增加而提升。
广泛兼容Ollama平台视觉模型
只要是在Ollama环境中可运行的视觉模型,本工具均可调用。
用户可根据硬件配置和精度需求自由选择合适的模型版本。
模型需通过联网下载至本地,完成后即可离线使用,保障数据安全与运行稳定性。
识别效果受字迹质量影响
对于印刷体页码识别效果优异,但若为手写页码且书写潦草,可能出现误识别情况,例如将‘7’误判为‘1’或将‘9’识别成‘4’。
建议在原始文档中保持清晰规范的页码标注以获得最佳识别结果。
软件运行环境要求说明
本软件需搭配独立显卡使用,显存容量不低于10GB,操作系统为Windows 10或更高版本。
仅提供软件本体程序,不包含Ollama框架及模型文件,用户需自行安装并配置相关依赖。
安装方式与使用准备
请先通过命令行执行Ollama安装指令拉取所需模型,例如:ollama pull qwen3-vl:8b。
完成下载后即可断开网络,在本地环境中启动软件进行页码识别任务。
【资源编号:995828139159-----36.90】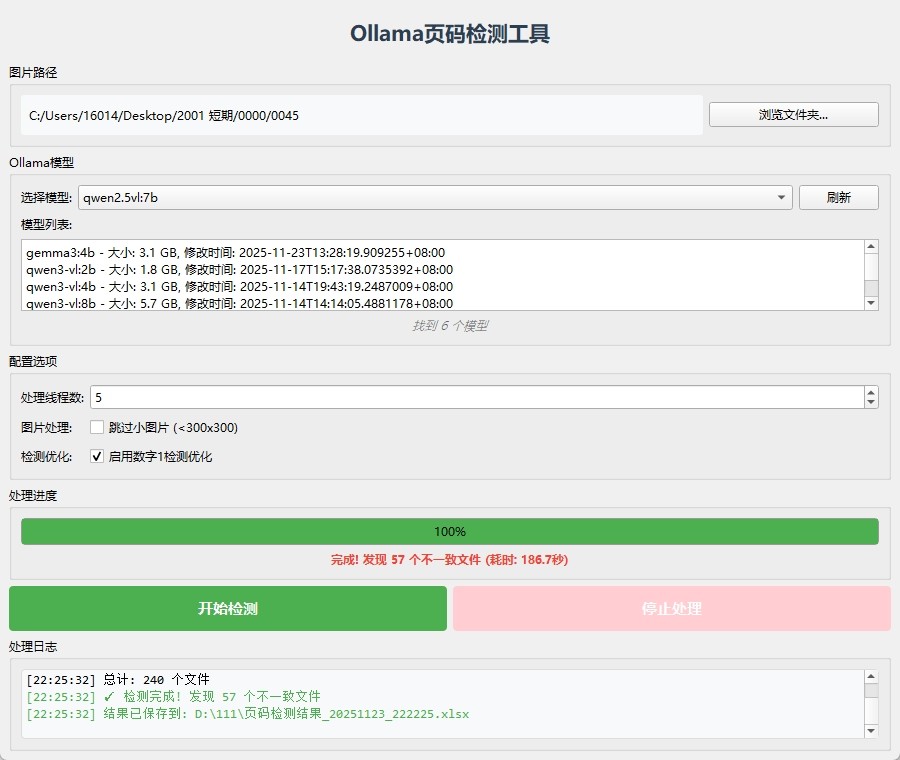
点击下面名片联系我
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)