爬取B站排行榜数据的Python实现
爬虫技术核心是自动化数据采集工具,能模拟人类浏览行为,从网页 / 网络资源中抓取并提取目标信息。爬虫的基本原理与应用场景B站数据的开放性与反爬机制合法合规的爬虫实践(遵守Robots协议)
·
爬虫技术概述
爬虫技术核心是自动化数据采集工具,能模拟人类浏览行为,从网页 / 网络资源中抓取并提取目标信息。
- 爬虫的基本原理与应用场景
- B站数据的开放性与反爬机制
- 合法合规的爬虫实践(遵守Robots协议)
目标分析
- B站排行榜页面结构解析(URL、动态加载机制)
- 数据类型需求(视频标题、播放量、UP主、弹幕数等)
- 数据存储格式选择(CSV、MySQL、MongoDB等)
工具与库准备
- 请求库:
requests或异步库aiohttp - 解析库:
BeautifulSoup/lxml或pyquery - 动态渲染支持:
selenium或playwright(如需处理JavaScript) - 数据存储:
pandas/csv或数据库驱动(如pymysql)import requests from bs4 import BeautifulSoup import csv import time代码解读:1.requests:用于发送HTTP请求获取网页内容。2.BeautifulSoup:用于解析HTML内容并提取数据。3.csv:用于将数据保存为CSV格式文件。4.time:用于设置请求间隔,防止被封禁。
爬取流程实现
- 构造请求头(模拟浏览器,处理
User-Agent和Cookie) - 通过设置
User-Agent模拟浏览器访问,避免被服务器识别为爬虫。 -
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' } - 发送HTTP请求获取页面(静态HTML或API接口数据)
- 解析响应数据(HTML解析或JSON数据处理)
- 异常处理(超时、反爬拦截、数据字段缺失)
获取视频信息函数
地址:B站排行榜页面的URL地址。
url = "https://www.bilibili.com/v/popular/rank/all"
def get_video_info():
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
items = soup.select('.rank-item')
video_list = []
for item in items[:100]: # 只取前100条
title = item.select_one('.info a').text.strip()
play = item.select_one('.data-box:nth-child(1)').text.strip()
danmu = item.select_one('.data-box:nth-child(2)').text.strip()
up = item.select_one('.data-box:nth-child(3)').text.strip()
href = item.select_one('.info a')['href']
full_href = f"https:{href}" if not href.startswith('http') else href
# 获取点赞、投币、收藏、分享数据
detail_url = f"https://api.bilibili.com/x/web-interface/archive/stat?aid={href.split('/')[-1]}"
detail_res = requests.get(detail_url, headers=headers)
detail_data = detail_res.json()['data']
video_list.append({
'标题': title,
'播放数': play,
'弹幕数': danmu,
'作者': up,
'点赞数': detail_data['like'],
'投币数': detail_data['coin'],
'收藏数': detail_data['favorite'],
'分享数': detail_data['share'],
'视频链接': full_href
})
time.sleep(0.5) # 防止请求过于频繁
return video_list
- 发送GET请求获取排行榜页面内容。
- 使用
BeautifulSoup解析HTML并通过CSS选择器提取.rank-item元素。 - 遍历前100个视频条目,提取标题、播放数、弹幕数、作者和视频链接。
- 通过B站API获取每个视频的详细数据(点赞、投币、收藏、分享)。
- 将数据存入字典列表,并设置0.5秒的请求间隔
数据存储与清洗
- 结构化数据存储为CSV
def save_to_csv(data): with open('bilibili_rank.csv', 'w', newline='', encoding='utf-8-sig') as f: writer = csv.DictWriter(f, fieldnames=data[0].keys()) writer.writeheader() writer.writerows(data) - 打开文件准备写入,设置编码为
utf-8-sig以兼容中文。 - 使用
csv.DictWriter将字典数据写入CSV文件,包含表头。 - 主程序入口
-
if __name__ == '__main__': video_data = get_video_info() save_to_csv(video_data) print("数据已保存为bilibili_rank.csv") - 调用
get_video_info()获取数据。 - 调用
save_to_csv()保存数据。 - 去重与脏数据处理(如播放量单位统一为“万”)
完整代码示例
- 静态页面爬取代码片段(含注释)
import requests from bs4 import BeautifulSoup import csv import time headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' } url = "https://www.bilibili.com/v/popular/rank/all" def get_video_info(): response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') items = soup.select('.rank-item') video_list = [] for item in items[:100]: # 只取前100条 title = item.select_one('.info a').text.strip() play = item.select_one('.data-box:nth-child(1)').text.strip() danmu = item.select_one('.data-box:nth-child(2)').text.strip() up = item.select_one('.data-box:nth-child(3)').text.strip() href = item.select_one('.info a')['href'] full_href = f"https:{href}" if not href.startswith('http') else href # 获取点赞、投币、收藏、分享数据 detail_url = f"https://api.bilibili.com/x/web-interface/archive/stat?aid={href.split('/')[-1]}" detail_res = requests.get(detail_url, headers=headers) detail_data = detail_res.json()['data'] video_list.append({ '标题': title, '播放数': play, '弹幕数': danmu, '作者': up, '点赞数': detail_data['like'], '投币数': detail_data['coin'], '收藏数': detail_data['favorite'], '分享数': detail_data['share'], '视频链接': full_href }) time.sleep(0.5) # 防止请求过于频繁 return video_list def save_to_csv(data): with open('bilibili_rank.csv', 'w', newline='', encoding='utf-8-sig') as f: writer = csv.DictWriter(f, fieldnames=data[0].keys()) writer.writeheader() writer.writerows(data) if __name__ == '__main__': video_data = get_video_info() save_to_csv(video_data) print("数据已保存为bilibili_rank.csv")如果API请求出现问题,可以使用纯HTML解析方案:
import requests from bs4 import BeautifulSoup import csv headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' } url = "https://www.bilibili.com/v/popular/rank/all" def get_video_info(): response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') items = soup.select('.rank-item') video_list = [] for item in items[:100]: title = item.select_one('.info a').text.strip() play = item.select_one('.data-box:nth-child(1)').text.strip() danmu = item.select_one('.data-box:nth-child(2)').text.strip() up = item.select_one('.data-box:nth-child(3)').text.strip() href = item.select_one('.info a')['href'] full_href = f"https:{href}" if not href.startswith('http') else href # 从HTML中获取其他数据(如果页面有显示) try: like = item.select_one('.like').text.strip() coin = item.select_one('.coin').text.strip() favorite = item.select_one('.favorite').text.strip() share = item.select_one('.share').text.strip() except: like = coin = favorite = share = 'N/A' video_list.append({ '标题': title, '播放数': play, '弹幕数': danmu, '作者': up, '点赞数': like, '投币数': coin, '收藏数': favorite, '分享数': share, '视频链接': full_href }) return video_list # 保存函数同上
扩展方向
- 定时任务自动化(
APScheduler或crontab) - 数据可视化(
matplotlib/pyecharts生成趋势图) - 结合评论爬取与情感分析(NLP扩展)
注意事项
- 法律风险提示(避免商业用途未经授权的数据抓取)
- B站API更新应对策略(接口变动监控)
- 如果API请求被限制,可能需要添加更多请求头或使用代理
- 实际运行时可能需要根据页面结构微调CSS选择器
- 确保安装了必要的库:
requests,beautifulsoup4
使用jupyter notebook的详细过程以及数据可视化趋势图生成
-
1. 导入工具包,请求 B 站排行榜接口,提取数据并整理成表格
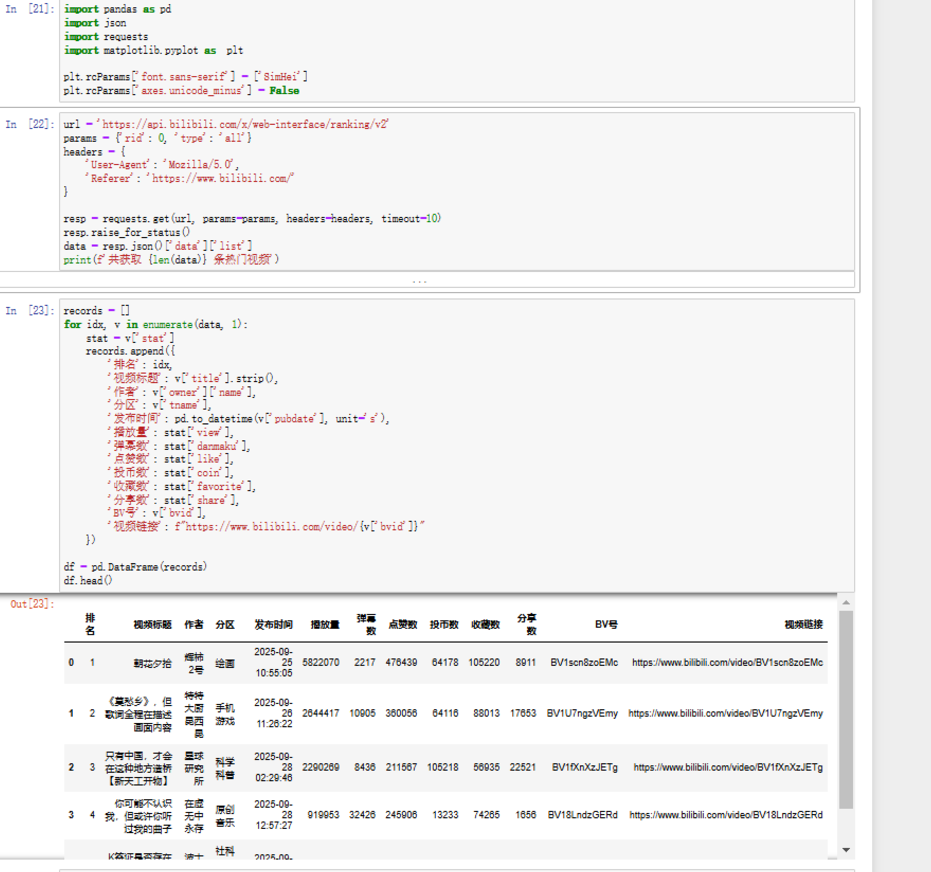
-
2.对 B 站榜单数据做描述性统计 + 分区数量可视化
-
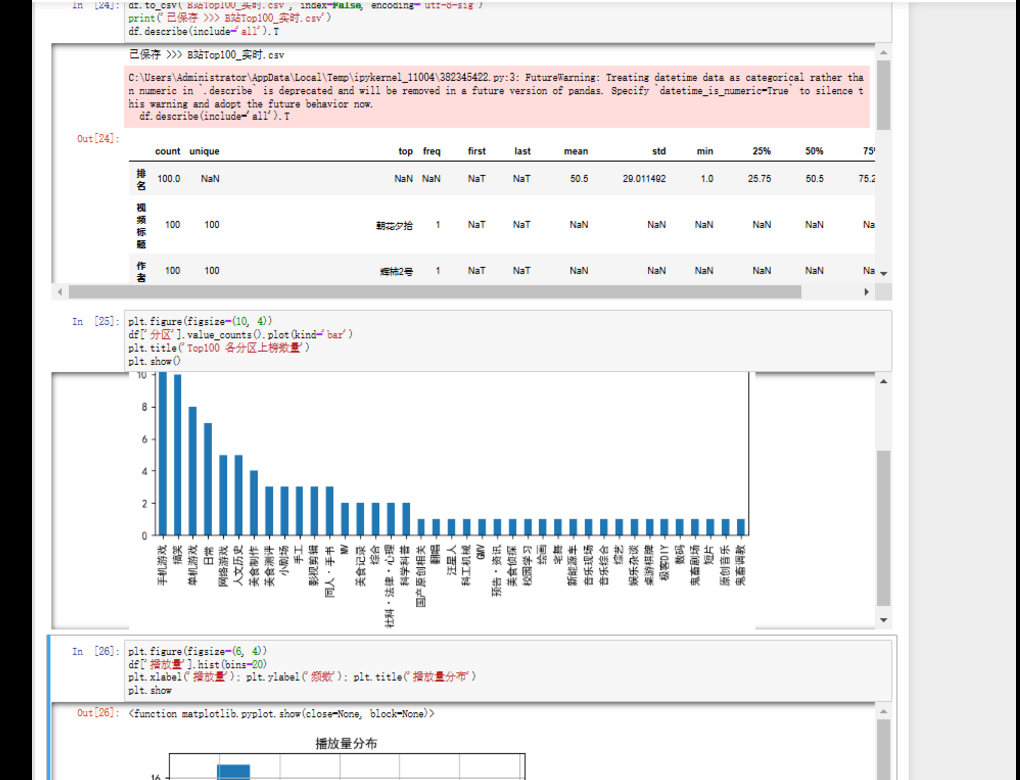
-
3.对之前爬取的 B 站榜单数据做可视化分析 + 数据保存
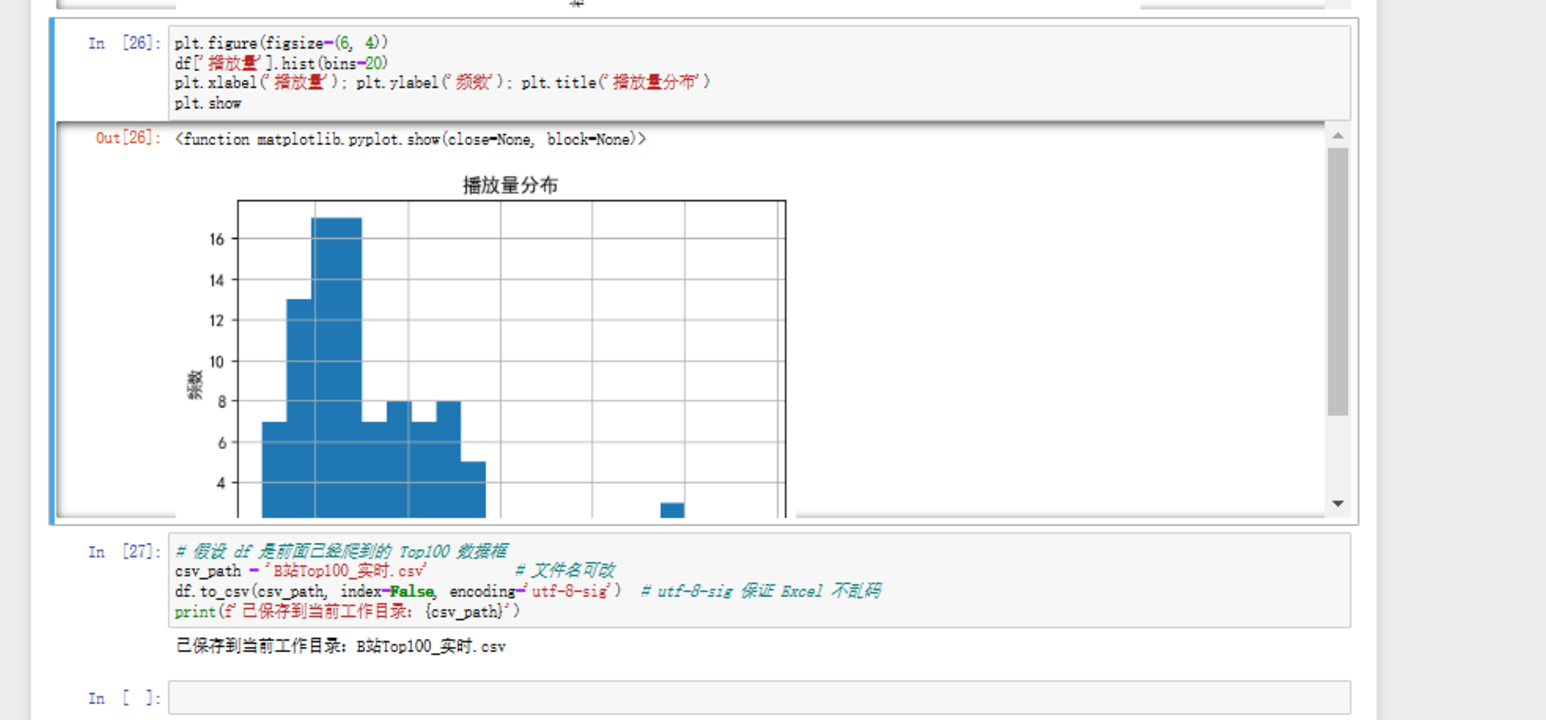
- 4.以下数据为即时数据


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)