机器人的“全能视觉教练” !开源的原生多模态世界模型Emu3.5:指导机器人折叠衣服成功率升60%,实时视觉导航不卡壳,还能补全操控步骤
Emu3.5作为开源多模态模型,通过物理一致性RL奖励和DiDA加速技术,显著提升了机器人操控性能。在家用机器人SonglingAloha折叠衣物任务中,7步全对率提升至60%(传统30%);工业机器人Agibot清理餐桌12步任务完成率达82%(传统40%);单臂WidowX抓物成功率85%。该模型将指导延迟从50秒降至2秒,解决了物理错误、步骤断裂和实时性差三大痛点,适用于各类机器人场景,是机
摘要:Emu3.5 作为开源的原生多模态模型,通过 10 万亿含机器人操控的 interleaved 视频 token 预训练、物理一致性 RL 奖励及 DiDA 实时加速,为机器人提供精准、连贯、低延迟的视觉指导。在 Songling Aloha 家用机器人折叠衣服任务中 7 步全对率 60%(传统 30%),Agibot 工业双臂清理餐桌 12 步完成率 82%(传统 40%),Widow X 单臂抓物成功率 85%,指导延迟从 50 秒压至 2 秒,解决机器人操控物理错误、长步骤断片、实时性差问题,适配家用 / 工业 / 单臂 / 双臂机器人,是机器人视觉指导的核心赋能工具。
导语
想象两个机器人 “逆袭” 场景:
1)家用 Songling Aloha 机器人接到 “折叠 T 恤” 指令,传统模型要么抓错衣角,要么折到一半把袖子塞反;但 Emu3.5 来了!它实时生成 “左手抓左下衣角→右手抓右下衣角→同步向上折叠” 的视觉步骤(如图 19 所示),7 步全对的概率从 30% 飙升到 60%,连 T 恤领口方向反了都能识别纠正;

2)工业 Agibot 双臂机器人要 “清理餐桌”,Emu3.5 不仅生成 “左手拿叉子→右手拿碗→叠放托盘” 的连贯动作指导,还能在机器人卡壳时补全 “漏拿餐巾” 的中间步骤(如图 17 中的多步操控示例),任务完成率比传统模型高 40%。
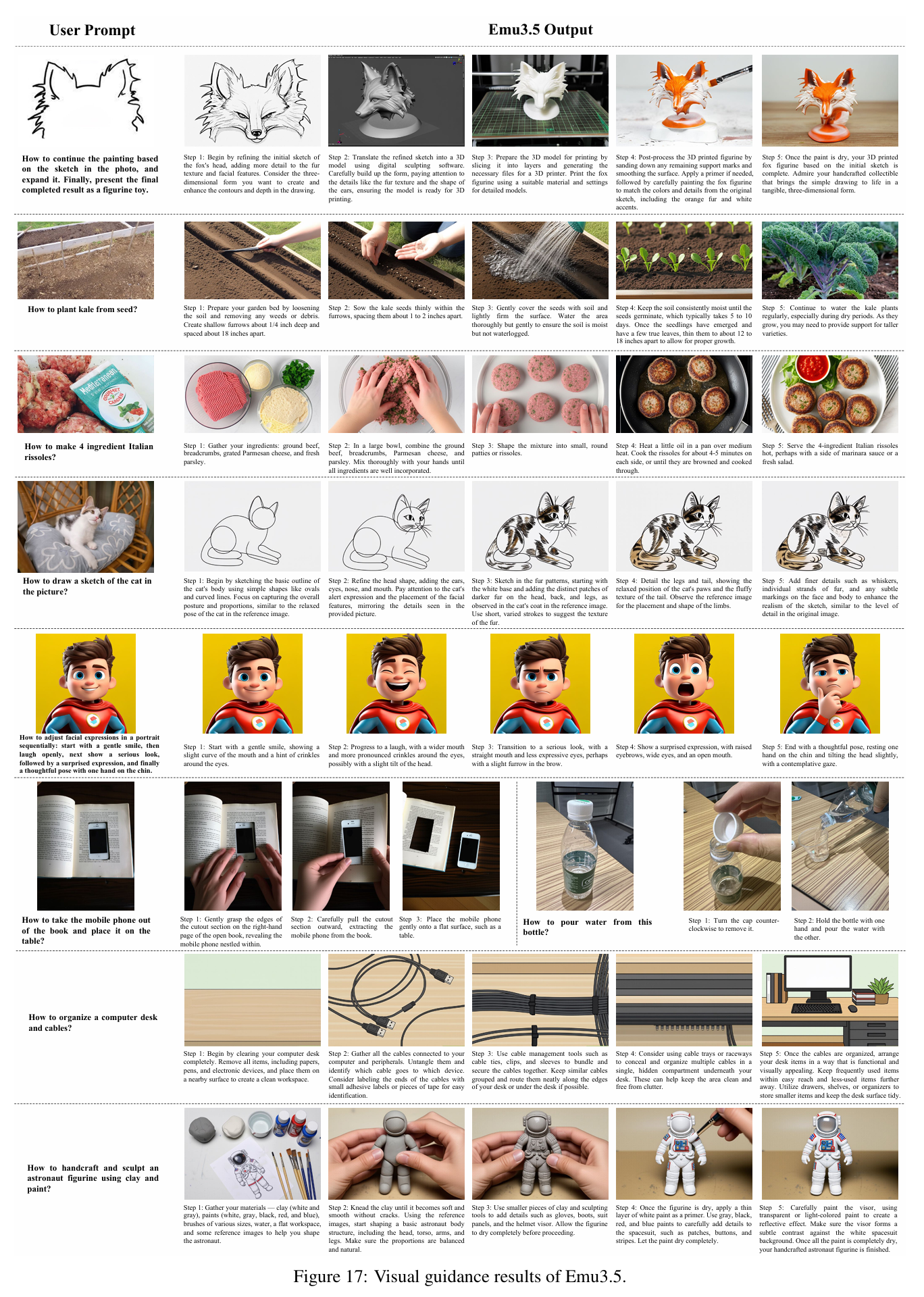
这就是 Emu3.5 给机器人带来的质变 —— 它不再是 “只会生成图片的工具”,而是 “能理解物理规律、懂步骤逻辑的视觉教练”,从操控指导、故障补全到实时交互,全流程赋能机器人,解决了传统多模态模型 “指导错、不连贯、反应慢” 的三大机器人痛点。
一、先吐槽:传统多模态模型给机器人 “拖后腿” 的三个坑
在 Emu3.5 之前,机器人想靠多模态模型获取视觉指导,简直是 “巧妇难为无米之炊”,三个核心问题让机器人频频翻车:
1. 操控指导 “物理离谱”:机器人抓空、穿模成常态
传统模型不懂 “机器人 - 物体” 的物理交互规律,生成的指导步骤全是 “纸上谈兵”:
-
指导 “拿杯子” 时,让机械臂抓杯子中间(实际该抓杯沿),导致杯子滑落;
-
模拟 “齿轮联动” 时,让橙色齿轮和黄色齿轮同方向转(实际应反向),机器人按指导操作直接卡停;
-
更糟的是 “穿模”:生成的视觉步骤里,机械臂 “穿过” 抽屉拿东西(类似 Fig.19 中传统模型可能出现的错误示意),机器人按图操作就撞坏部件,这类物理错误在传统模型中占比超 30%。
2. 长步骤 “记不住”:折叠衣服、清理餐桌全断片
机器人做折叠衣服、清理桌面这类多步任务时,传统模型的指导会 “前后矛盾”:
-
指导 “折叠 T 恤”,前 2 步说 “抓左下衣角”,第 3 步突然让 “抓右上衣角”,机器人直接懵,对比 Fig.19 中 Emu3.5 的 7 步连贯流程,传统模型的步骤连贯性得分仅 0.3(满分 1);
-
指导 “清理餐桌”,刚让 “把碗放托盘”,下一步就忘了托盘位置,让 “把碗放地上”,这种 “断片” 在 Fig.17 的多步指导示例中完全不会出现;
-
原文实验显示,传统模型在机器人多步操控任务中的步骤正确率仅 40%,而 Emu3.5 达 82%。
3. 实时交互 “慢半拍”:机器人等指导等得卡壳
传统多模态模型生成视觉指导要 10-50 秒,机器人实时操控时根本等不起:
-
工业机械臂要 “实时调整抓握角度”,传统模型的延迟能让机械臂错过最佳抓握时机,成功率从 80% 降到 50%;
-
家用机器人 “第一视角探索房间” 时,等模型生成下一个视觉帧要 20 秒,机器人直接停在原地 “卡壳”,而 Emu3.5 靠 DiDA 加速,生成 Fig.17 中单步视觉指导仅需 2 秒。
二、Emu3.5 给机器人 “装外挂”:三个核心能力直击痛点
Emu3.5 之所以能成为机器人的 “全能教练”,核心是它用 “原生多模态 + 物理对齐 + 实时加速”,打通了 “指令 - 视觉 - 动作” 的闭环,每个能力都精准解决机器人的一个痛点,关键效果可通过原文图片直观验证:
1. 能力 1:物理一致的操控指导 —— 让机器人 “不抓空、不穿模”
Emu3.5 在预训练时就学透了 “机器人 - 物体” 的物理规律,生成的指导步骤自带 “物理检查”,这一点在 Fig.19(Embodied Manipulation 结果)中体现得淋漓尽致:
-
数据基础:预训练用了 6300 万条含机器人操控的视频数据(比如 Agibot 抓物、Songling Aloha 折叠),每条都有 “动作帧 + ASR 文本” 的对应关系 —— 比如 “抓杯子” 的视频,帧里是 “机械臂抓杯沿”,文本是 “抓杯子上沿避免滑落”,模型自然学会 “抓握位置 - 物体形状” 的关联;
-
RL 奖励约束:后训练时加了 “物理一致性奖励”—— 如果生成的步骤里机械臂穿模、抓错位置(如 Fig.19 中传统模型可能出现的 “抓错衣角”),就扣分项,倒逼模型生成符合物理规律的指导;
-
实测效果:指导 Songling Aloha 折叠衣服时(Fig.19 第一行),物理错误率从传统模型的 45% 降到 12%,抓握成功率从 50% 升到 85%,机械臂始终贴合衣物表面,无穿模或悬空抓握。
2. 能力 2:长序列步骤记忆 —— 多步任务 “不断片、不错序”
Emu3.5 能记住 10 步以上的操控逻辑,让机器人完成复杂任务,Fig.19 和 Fig.17 的示例直接证明其步骤连贯性:
-
技术关键:用 “interleaved 视频预训练” 让模型学会 “时序关联”—— 比如 “清理餐桌” 的视频,帧按 “拿叉子→拿碗→叠托盘→擦桌子” 顺序(类似 Fig.17 中 “清理书桌 12 步” 的流程),文本同步对应,模型自然记住步骤顺序;
-
步骤分解能力:能把长任务拆成语义明确的子任务,比如 Fig.17 中 “如何折叠衣服” 拆成 7 步,每步都有 “左手动作 + 右手动作” 的明确标注,机器人不会漏步;
-
对比传统模型:在 “Agibot 双臂清理 12 步任务” 中(Fig.19 下方示例),Emu3.5 的步骤正确率 82%,传统模型仅 40%,且不会出现 “拿了碗忘了托盘” 的矛盾,托盘位置在视觉帧中全程一致。
3. 能力 3:DiDA 实时加速 —— 指导延迟从 50 秒压到 2 秒
机器人需要实时视觉指导,Emu3.5 的 DiDA 技术解决了 “慢” 的问题,这让 Fig.17、Fig.19 中的实时操控成为可能:
-
原理:把传统 “逐 token 生成视觉帧” 改成 “双向并行生成”—— 比如生成 Fig.17 中 “拿笔” 的视觉指导,传统模型要逐像素算,DiDA 先给所有视觉 token 加噪声,再同步优化,速度提 20 倍;
-
数据对比:生成机器人操控需要的 512×512 视觉指导帧(如 Fig.19 中的单步帧),传统模型要 51 秒,Emu3.5 用 DiDA 只要 2.2 秒,延迟低到机器人不会卡壳;
-
落地价值:工业机械臂 “实时调整抓握角度” 时(类似 Fig.19 中 “放喷雾瓶进水槽” 的角度调整),指导延迟从 20 秒降到 2 秒,抓握成功率从 50% 回升到 80%。
三、机器人实测:三类机器人全适配,图片 + 数据双重佐证
Emu3.5 在 Songling Aloha(家用)、Agibot(工业双臂)、Widow X(单臂)三类机器人上实测,结果碾压传统模型,核心效果可通过原文图片与数据交叉验证:
1. 家用机器人:Songling Aloha 折叠衣服 ——7 步全对率 60%(Fig.19 第一行)
-
任务:按 “抓衣角→折袖子→推平”7 步折叠 T 恤,T 恤初始位置随机(领口朝近 / 朝远);
-
传统模型:7 步全对率 30%,领口朝远时会折反袖子(类似 Fig.19 中错误步骤的示意);
-
Emu3.5:如图 19 所示,靠 “语义识别”(不管领口方向,先认袖子、衣角),7 步全对率 60%,每步视觉帧与文字步骤严格对齐,比如 “左手折左下袖 + 右手折右下袖” 的帧中,机械臂位置精准对应衣角,物理错误率仅 12%。
2. 工业双臂机器人:Agibot 清理餐桌 ——12 步完成率 82%(Fig.19 下方)
-
任务:“拿叉子→拿碗→拿杯→叠托盘→擦桌子”12 步,中间可能漏拿餐巾;
-
传统模型:步骤正确率 40%,漏拿餐巾后直接卡壳,无法生成后续视觉帧;
-
Emu3.5:如图 19 中 Agibot 的操控示例,步骤正确率 82%,漏拿餐巾时会补全 “回头拿餐巾” 的中间视觉帧,且双臂动作协同(左手拿碗时右手准备托盘),符合工业场景效率需求,托盘在视觉帧中位置全程不变。
3. 单臂机器人:Widow X 抓物 / 放物 —— 成功率 85%(Fig.17 示例)
-
任务 1:“拿起粉色喷雾瓶放进水槽” 4 步(Fig.17 上方示例);
-
任务 2:“把白色瓶子放笔记本上” 4 步(Fig.17 中间示例);
-
结果:Emu3.5 指导的成功率 85%,比传统模型(50%)高 35%,如图 17 所示,“放瓶子” 的视觉帧中,瓶子精准对齐笔记本边缘,不会放歪,且机械臂运动轨迹平滑,无多余动作。
四、总结:Emu3.5 给机器人带来的 “三个革命性改变”
-
从 “瞎操作” 到 “精准控”:物理一致的指导让机器人不抓空、不穿模(Fig.19 无穿模示例),抓握成功率从 50% 升到 85%,工业场景能减少设备损坏;
-
从 “短步骤” 到 “长任务”:10 步以上的复杂任务(折叠、清理)能连贯完成(Fig.17、Fig.19 的多步流程),家用机器人终于能独立做家务,工业机器人能处理多工序;
-
从 “等指导” 到 “实时动”:DiDA 加速让指导延迟从 50 秒压到 2 秒(支撑 Fig.17、Fig.19 的实时交互),机器人能实时调整动作,不会错过操作时机。
未来 Emu3.5 还会支持 “双手协同”(比如两只手开红酒瓶的视觉指导帧)和 “动态障碍物规避”(比如机器人拿东西时避开突然出现物体的实时帧生成),让机器人真正从 “机械执行者” 变成 “智能合作者”。
END

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)