多模态与具身智能:技术突破与应用革新
在人工智能的演进历程中,从单模态数据的浅层感知到多模态信息的融合理解,从“云端思考”的虚拟智能到“物理交互”的具身实体,技术的突破正推动智能形态实现质的飞跃。多模态智能打破了数据类型的壁垒,让机器能像人类一样整合视觉、听觉、语言等多元信息;具身智能则赋予机器物理实体,使其在真实环境中通过交互学习与适应。本文将聚焦多模态与具身智能的关键技术原理、创新发展趋势,结合典型案例解析其应用路径,展现这一领域的核心价值与未来图景。
模块一:多模态与具身智能的核心逻辑——从“感知融合”到“交互决策”多模态智能与具身智能并非孤立存在,二者呈现“感知-决策-执行”的闭环协同关系。多模态智能为具身智能提供全面的环境感知能力,确保其精准理解复杂场景;具身智能则为多模态技术提供真实的交互场景与反馈数据,推动模型持续优化。要深入理解这一领域,首先需明确其核心技术框架,以下思维导图清晰呈现了两大智能形态的技术体系与关联逻辑:从技术本质来看,多模态智能解决“信息全面获取与精准解读”的问题,具身智能解决“在真实环境中高效执行与动态调整”的问题,二者结合使人工智能从“被动响应”走向“主动适应”,这也是当前智能技术发展的核心方向。

模块二:多模态与具身智能关键技术原理及创新发展趋势一、多模态智能:打破数据壁垒的融合技术人类对世界的认知依赖于视觉、听觉、触觉等多种感官的协同作用,多模态智能正是模拟这一过程,通过融合不同类型数据实现更全面的理解与更精准的生成。其关键技术原理围绕“数据处理-融合建模-理解生成”三个核心环节展开,各环节的技术突破推动了多模态智能的快速发展。1. 关键技术原理深度解析多模态数据具有“异质性、互补性、冗余性”三大特征,这也决定了其技术核心在于解决“异质数据对齐与有效融合”的难题。在多模态数据预处理阶段,核心任务是实现“数据标准化”与“初步特征提取”。不同模态数据的格式差异巨大,例如图像数据为二维像素矩阵,语音数据为时序波形信号,文本数据为离散字符序列。技术上,需通过图像分割、语音分帧、文本分词等操作将原始数据转化为结构化特征,再利用特征对齐技术(如时间对齐用于音视频同步、语义对齐用于文本与图像匹配)消除模态间的差异。例如,在视频会议的实时字幕生成系统中,需将语音信号的时间轴与视频画面的帧序列精准对齐,同时提取语音的声学特征与文本的语义特征,为后续融合做准备。多模态融合技术是核心环节,根据融合阶段的不同可分为早期、中期、晚期三种融合策略,各有适用场景与技术优势。早期融合(特征级融合)是在数据特征提取后直接融合,能最大程度保留原始数据信息,但对数据异质性的处理要求极高,常用技术包括多模态自编码器、注意力机制等。例如,CLIP模型通过将图像特征与文本特征映射到同一语义空间,实现了跨模态的相似性计算。中期融合(模态级融合)则先对单一模态进行初步理解,再融合各模态的中间结果,兼顾了信息完整性与处理效率,适用于复杂场景的分析。晚期融合(决策级融合)是在各模态独立完成决策后,通过投票、加权等方式整合结果,稳定性高但信息损失较大,多用于医疗诊断等对可靠性要求极高的领域。多模态理解与生成是技术的最终输出环节,核心是实现“跨模态语义的精准映射”。理解任务如跨模态检索(图搜文、文搜图)、多模态内容摘要等,需建立不同模态间的语义关联;生成任务如文生图(MidJourney)、图生语音、多模态对话等,则需基于一种模态的信息生成另一种或多种模态的内容。这一过程依赖于大规模预训练模型的支撑,通过在海量多模态数据上的训练,模型能够学习到不同模态间的潜在语义关联。2. 多模态智能创新发展趋势当前,多模态智能正朝着“更深度融合、更高效适配、更贴近场景”的方向发展。一是融合模式从“线性拼接”走向“动态自适应融合”,传统融合方式多采用固定的融合策略,而新型模型如FLAVA、Florence等能够根据数据特征与任务需求,动态调整各模态的权重与融合方式,提升复杂场景下的处理效果。二是模型走向“轻量化与专用化”,随着多模态技术在移动端、边缘设备的应用需求增加,轻量化模型成为研究热点,通过知识蒸馏、量化等技术,在保证性能的同时降低模型的计算成本;同时,针对医疗、教育等特定领域的专用多模态模型不断涌现,如医疗领域的多模态诊断模型,能融合医学影像、病理报告、基因数据等实现精准诊断。三是“人机协同标注与弱监督学习”突破数据瓶颈,多模态数据的标注成本极高,新型技术通过人机协同的方式,由机器完成初步标注,人类进行修正,大幅提升标注效率;弱监督学习则能利用少量标注数据与大量未标注数据进行训练,降低对标注数据的依赖。

二、具身智能:赋予机器“物理实体”的交互技术具身智能的核心是“具身认知”理论,即智能只能在与环境的交互中产生,机器必须拥有物理实体(如机器人),通过感知环境、执行动作、获取反馈,才能实现真正的智能。其技术体系围绕“感知-控制-决策”形成闭环,每个环节的技术突破都推动具身智能从实验室走向实际应用。1. 关键技术原理深度解析具身感知技术是具身智能的“眼睛和耳朵”,负责获取环境与自身状态的信息。环境感知方面,通过视觉传感器(摄像头、深度相机)获取图像、三维空间信息,通过听觉传感器(麦克风阵列)实现语音定位与降噪,通过触觉传感器(力传感器、触觉阵列)感知物体的硬度、温度等物理属性;自身状态感知方面,通过惯性测量单元(IMU)、编码器等获取机器人的位置、姿态、运动速度等信息,确保动作执行的精准性。例如,工业机器人通过视觉传感器识别工件的位置与姿态,通过力传感器感知抓取力度,避免工件损坏。运动控制技术是具身智能的“手脚”,负责将决策指令转化为精准的物理动作。核心技术包括高精度驱动、轨迹规划与自适应控制。高精度驱动依赖于伺服电机、减速器等核心部件,确保机器人动作的精度与稳定性;轨迹规划则通过算法计算出最优的运动路径,避免碰撞并提升效率;自适应控制则能根据环境变化(如工件重量变化、地面不平)实时调整控制参数,例如服务机器人在不同地面材质上行走时,通过自适应控制调整步态,确保行走稳定。交互决策技术是具身智能的“大脑”,负责根据感知信息与任务目标做出决策。当前主流技术是强化学习与迁移学习的结合,强化学习通过“试错”的方式让机器人在与环境的交互中积累经验,优化决策策略;迁移学习则将在虚拟环境中训练好的模型迁移到真实环境中,解决真实场景下训练数据稀缺、训练成本高的问题。例如,波士顿动力的Atlas机器人,通过在虚拟环境中大量训练跑跳、翻越等动作,再将模型迁移到真实机器人上,实现了复杂地形下的灵活运动。此外,场景化决策模型也成为研究重点,通过对特定场景(如家庭、工厂)的环境特征与任务需求进行建模,使机器人能够快速适应场景变化,做出符合需求的决策。2. 具身智能创新发展趋势具身智能正从“特定场景专用”走向“通用化、自适应”,其发展趋势体现在三个方面。一是“虚实融合训练”大幅提升训练效率,虚拟仿真技术能够构建与真实环境高度一致的虚拟场景,机器人可以在虚拟环境中进行大规模、高风险的训练(如火灾救援、高空作业),再将训练成果迁移到真实环境,解决了真实场景训练成本高、风险大的问题。二是“多模态感知融合与主动感知”成为趋势,具身智能不再被动接收感知信息,而是通过主动调整感知角度、力度等获取更精准的信息,例如机器人在抓取未知物体时,会主动通过触觉感知物体硬度,通过视觉观察物体形状,结合多模态信息做出抓取决策。三是“模块化与协作化”提升适用性,模块化机器人能够根据任务需求更换不同的功能模块(如抓取模块、焊接模块),适应多样化场景;协作机器人则能与人类在同一空间内协同工作,通过力反馈、视觉识别等技术避免碰撞,提升生产效率与安全性。以下图片展示了多模态与具身智能融合应用的典型架构,清晰呈现了感知、融合、决策、执行的完整流程:
模块三:多模态与具身智能应用路径及典型案例深度解析多模态与具身智能的融合应用,正从工业、服务、医疗等重点领域切入,逐步渗透到社会生产生活的各个方面。其应用路径的核心是“场景需求驱动-技术融合适配-落地效果迭代”,即根据特定场景的需求,选择合适的多模态感知技术与具身执行方案,通过实际应用反馈持续优化系统性能。以下结合典型案例,解析不同领域的应用路径与技术价值。一、工业领域:智能制造的“全流程革新者”工业场景对精准度、效率、安全性的高要求,使其成为多模态与具身智能的重要应用阵地。应用路径主要围绕“生产检测-装配执行-协同协作”三个核心环节,通过多模态感知确保检测精准,通过具身智能实现高效执行。典型案例:某汽车制造企业的多模态智能装配机器人系统。该系统整合了视觉、触觉、力觉三种核心模态,在汽车底盘装配环节实现全自动化作业。在感知阶段,高清视觉传感器通过多视角拍摄,获取零部件的位置、姿态信息,结合3D点云数据构建零部件的三维模型;触觉传感器检测零部件表面的纹理与硬度,确认零部件型号;力传感器则实时感知装配过程中的压力变化。在融合决策阶段,多模态融合模型将三种模态的信息进行整合,精准判断零部件的装配位置与力度要求。在执行阶段,具身机器人根据决策指令,通过高精度运动控制完成零部件的抓取、定位与装配,当力传感器检测到压力超过阈值时,系统会立即调整动作,避免零部件损坏。该系统相比传统人工装配,效率提升50%以上,装配误差控制在0.02mm以内,大幅提升了生产质量与效率。该案例的核心应用经验:工业场景中,多模态感知需聚焦“精准性与实时性”,优先选择与工业场景适配的高精度传感器;具身智能需强化“力控与轨迹规划”能力,确保动作精准可控;同时,系统需与工业互联网平台对接,实现生产数据的实时上传与分析,为后续优化提供数据支撑。

二、服务领域:人性化服务的“核心载体”服务场景的多样性与复杂性,要求多模态与具身智能具备“环境自适应”与“人性化交互”能力。应用路径围绕“用户需求识别-个性化服务执行-情感交互反馈”展开,通过多模态感知理解用户需求与情感,通过具身智能提供物理服务。典型案例:某养老机构的多模态情感陪护机器人。该机器人具备视觉、听觉、触觉、语音四种模态的感知能力,能够为老人提供生活照料与情感陪伴服务。在需求识别阶段,视觉传感器通过面部识别判断老人的身份与表情(如是否开心、焦虑),听觉传感器捕捉老人的语音指令与语气变化,触觉传感器在与老人接触时感知其体温、握力等信息,语音模态则实现与老人的自然对话。在融合决策阶段,模型结合多模态信息判断老人的需求,例如当检测到老人表情焦虑、语气急促时,机器人会主动询问是否需要帮助;当检测到老人体温异常时,会及时通知医护人员。在执行阶段,机器人通过具身执行模块完成送餐、协助起身、陪同散步等服务,同时通过语音、表情(屏幕显示)与老人进行情感交互。该机器人的应用,使养老机构的医护人员工作量减少30%,老人的情感满意度提升65%。服务领域的应用关键:需强化“情感理解与人性化交互”能力,通过多模态信息精准捕捉用户的情感状态;具身执行模块需兼顾“安全性与舒适性”,例如在协助老人起身时,通过力反馈控制力度,避免对老人造成伤害;同时,需具备场景自适应能力,适应家庭、养老机构等不同场景的环境特征
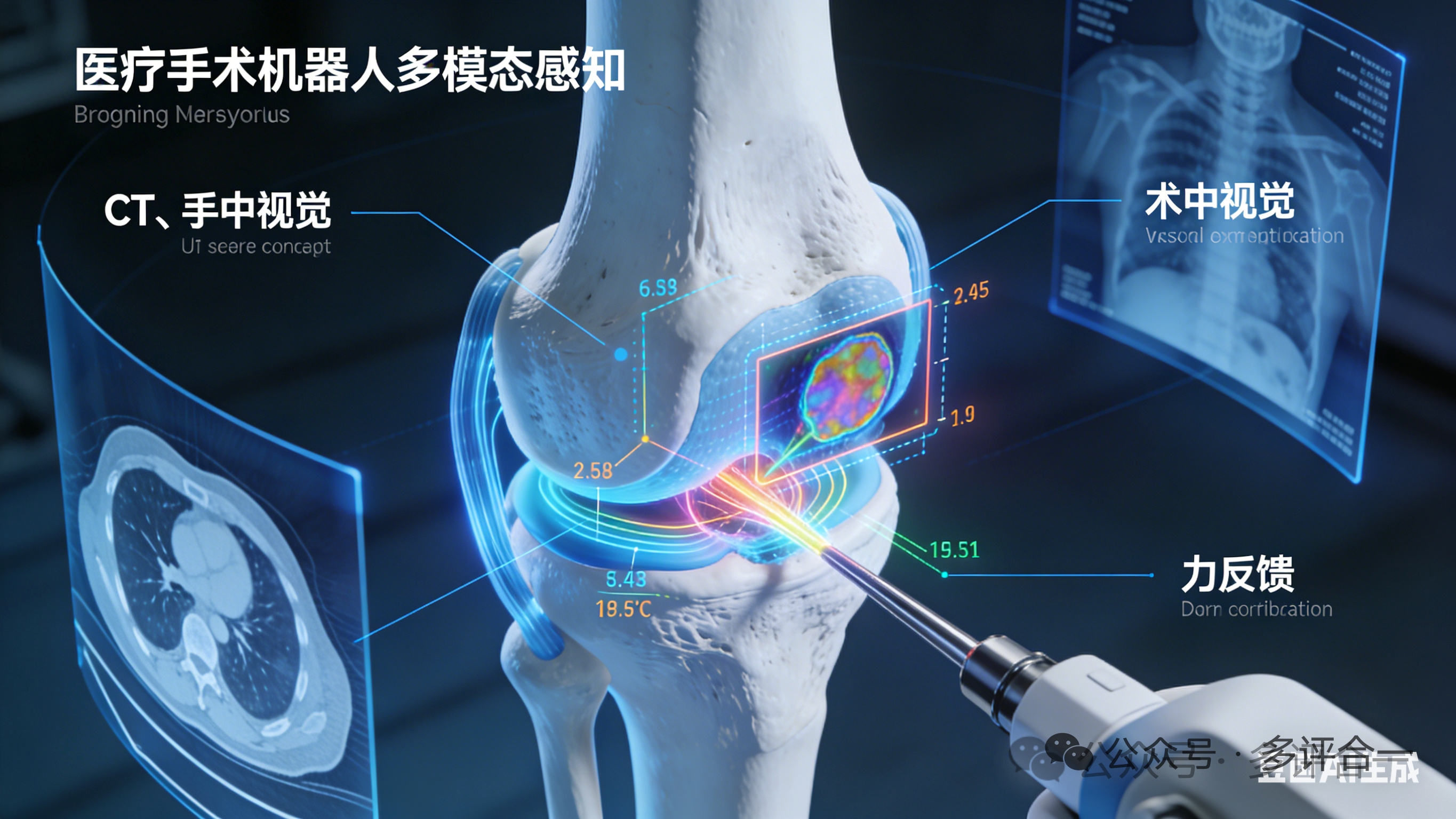
三、医疗领域:精准诊疗的“智能助手”医疗领域的严谨性要求多模态与具身智能具备“高可靠性与精准性”,应用路径围绕“诊断辅助-手术执行-康复护理”展开,通过多模态融合提升诊断精度,通过具身智能实现微创、精准的医疗操作。典型案例:某医院的多模态智能手术机器人系统。该系统应用于骨科手术,整合了医学影像(CT、MRI)、术中实时视觉、力觉、触觉等多模态信息。在术前诊断阶段,系统将CT、MRI等医学影像数据进行多模态融合,构建患者骨骼的三维模型,帮助医生精准定位病灶位置与病变程度。在术中执行阶段,视觉传感器实时捕捉手术场景的图像,与术前三维模型进行比对,确保手术器械的精准定位;力传感器实时感知手术器械与骨骼的接触力,避免过度用力造成骨骼损伤;触觉传感器则能感知骨骼的硬度变化,帮助医生识别病变组织。医生通过操纵台发出指令,具身机器人根据多模态信息进行自适应调整,完成骨骼钻孔、复位等精准操作。该系统应用后,骨科手术的平均时长从2小时缩短至1小时,手术出血量减少40%,术后并发症发生率降低35%。医疗领域的应用要点:需严格遵循医疗规范,所有技术方案需通过临床验证;多模态数据需满足医疗数据的隐私保护要求,采用加密存储与传输技术;具身机器人需具备“容错机制”,当检测到异常情况时能立即停止动作,确保手术安全。四、教育领域:个性化学习的“智能伙伴”教育场景的核心需求是“个性化指导”与“互动式学习”,多模态与具身智能的应用路径围绕“学习状态感知-个性化教学内容推送-互动式辅导”展开,通过多模态感知了解学生的学习状态,通过具身交互提升学习体验。典型案例:某教育科技公司的多模态智能教学机器人。该机器人面向K12阶段学生,具备视觉、语音、表情识别等多模态感知能力。在学习状态感知阶段,视觉传感器通过面部识别捕捉学生的注意力状态(如是否走神、疲劳),通过书写笔迹识别分析学生的答题思路与书写习惯;语音传感器捕捉学生的提问语音,结合自然语言处理技术理解问题意图;表情识别则判断学生的学习情绪(如是否困惑、兴奋)。在融合决策阶段,系统根据多模态信息生成学生的学习状态报告,精准定位知识薄弱点。在教学执行阶段,机器人通过语音、屏幕显示等多模态方式推送个性化学习内容,例如当检测到学生对数学几何问题困惑时,会通过三维模型展示几何图形,并结合语音讲解;当检测到学生注意力不集中时,会通过互动问答、小游戏等方式吸引学生注意力。该机器人在多所学校试点应用后,学生的学习兴趣提升40%,薄弱知识点掌握率提升55%。结语:多模态与具身智能的未来图景多模态与具身智能的融合发展,正推动人工智能从“工具化应用”走向“智能化协同”。技术层面,随着感知精度的提升、融合模型的优化、决策能力的进化,智能系统将具备更强的环境适应性与任务执行力;应用层面,将从当前的重点领域逐步渗透到日常生活的方方面面,如家庭服务机器人、智能出行工具、沉浸式教育系统等。但同时,这一领域也面临着技术挑战(如多模态语义对齐、具身机器人能源效率)与伦理问题(如隐私保护、就业影响)。未来,需通过技术创新突破瓶颈,通过政策规范引导发展,让多模态与具身智能真正服务于人类社会的进步与发展,构建“人机协同”的智能新生态。
针对文章内容有相关的课题会议,想了解具体内容的可以扫码加入社群


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)