Stable Diffusion教育辅导应用解析
Stable Diffusion通过潜在空间扩散与U-Net架构实现高效图像生成,结合教育场景需求,支持教学可视化、个性化内容与特殊教育辅助,需兼顾准确性、安全与伦理控制。
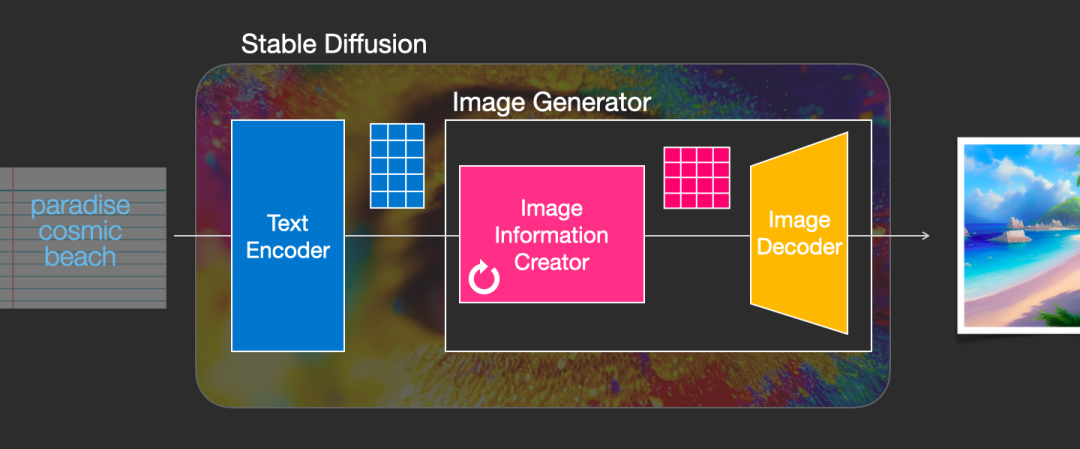
1. Stable Diffusion技术的基本原理与教育应用背景
1.1 技术起源与核心思想
Stable Diffusion(SD)是扩散模型在图像生成领域的里程碑式实现,其基本原理源于非平衡热力学中的扩散过程。模型通过 正向扩散 逐步向图像添加高斯噪声直至完全混乱,再利用神经网络学习 反向去噪 路径,从纯噪声中还原出符合文本描述的图像。这一机制显著提升了生成图像的质量与稳定性。
1.2 模型架构的关键创新
SD引入 潜在空间扩散 (Latent Diffusion),在低维隐空间进行去噪运算,大幅降低计算开销。结合 U-Net结构 与 交叉注意力机制 ,模型能精准对齐文本语义与视觉特征,支持复杂提示词的解析与生成。
1.3 教育场景的应用潜力
在教育领域,Stable Diffusion可动态生成教学插图、虚拟实验场景及个性化学习材料。例如,输入“光合作用示意图”即可生成结构清晰的生物学图解,助力抽象概念可视化。该技术为资源匮乏地区提供低成本内容生产方案,同时支持特殊教育中的具象化表达,奠定智能教育新范式的基础。
2. Stable Diffusion的理论基础与模型机制
Stable Diffusion作为当前最先进的文本到图像生成模型之一,其背后融合了深度学习、概率建模与注意力机制等多重前沿技术。该模型不仅在生成质量上超越早期GAN和VAE架构,在可控性和训练稳定性方面也展现出显著优势。理解其理论根基是深入掌握其教育应用潜力的前提。本章将从扩散过程的数学本质出发,系统解析Stable Diffusion的核心组件及其协同工作机制,并探讨条件控制、推理优化等关键环节的技术实现路径。通过对正向扩散与反向去噪的动态建模分析,揭示模型如何在高维潜在空间中完成从噪声到语义图像的精确重构。
2.1 扩散模型的核心数学原理
扩散模型(Diffusion Model)是一种基于马尔可夫链的概率生成模型,其核心思想是通过一个逐步添加噪声的过程破坏原始数据分布,再训练神经网络逆向还原这一过程,从而实现对复杂数据分布的建模。这种“破坏—重建”的范式使得模型能够在无需对抗训练的情况下稳定地生成高质量样本。Stable Diffusion在此基础上引入潜在空间压缩机制,大幅提升了计算效率,但其底层仍依赖于严格的数学框架支撑。
2.1.1 正向扩散过程:高斯噪声的逐步注入
正向扩散过程是一个固定的马尔可夫过程,定义为一系列时间步 $ t = 1, 2, …, T $ 上的数据退化操作。设原始图像为 $ \mathbf{x}_0 $,则在每个时间步 $ t $,通过添加微小的高斯噪声来逐渐模糊图像内容:
q(\mathbf{x} t | \mathbf{x} {t-1}) = \mathcal{N}(\mathbf{x} t; \sqrt{1 - \beta_t} \mathbf{x} {t-1}, \beta_t \mathbf{I})
其中,$ \beta_t \in (0,1) $ 是预设的噪声调度参数,通常随时间递增,形成线性或余弦噪声表。经过 $ T $ 步后,图像 $ \mathbf{x}_T $ 接近纯高斯噪声,即:
\mathbf{x} t \approx \sqrt{\bar{\alpha}_t} \mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\epsilon}, \quad \text{其中 } \bar{\alpha}_t = \prod {s=1}^t (1 - \beta_s), \boldsymbol{\epsilon} \sim \mathcal{N}(0, \mathbf{I})
这一公式表明,任意中间状态 $ \mathbf{x}_t $ 可以直接由初始图像 $ \mathbf{x}_0 $ 和标准正态噪声 $ \boldsymbol{\epsilon} $ 线性组合得到,极大简化了采样路径。
下表展示了典型扩散步骤中噪声强度的变化趋势:
| 时间步 $ t $ | 噪声方差 $ \beta_t $ | 累积保留率 $ \sqrt{\bar{\alpha}_t} $ | 图像视觉特征 |
|---|---|---|---|
| 0 | 0.0001 | 1.0 | 完整清晰图像 |
| 50 | 0.001 | 0.93 | 轻微模糊 |
| 200 | 0.005 | 0.68 | 中度失真 |
| 500 | 0.01 | 0.35 | 结构尚存 |
| 1000 | 0.02 | 0.04 | 几乎全噪声 |
该过程完全无需训练,仅用于构造训练目标。它的意义在于为反向生成提供明确的学习信号——即给定被污染的图像 $ \mathbf{x}_t $,预测所加的噪声 $ \boldsymbol{\epsilon} $。
import torch
import numpy as np
def forward_diffusion(x0, t, beta_scheduler):
"""
实现正向扩散过程:根据时间步t向图像x0添加噪声
参数说明:
- x0: 初始图像张量,shape [B, C, H, W]
- t: 当前时间步,scalar 或 tensor [B]
- beta_scheduler: 预定义的beta值数组,长度为T
返回:
- xt: 扩散后的图像
- noise: 添加的随机噪声
"""
T = len(beta_scheduler)
betas = torch.tensor(beta_scheduler, dtype=torch.float32)
# 计算累积alpha_bar: ᾱ_t = ∏(1−β_s)
alphas = 1 - betas
alpha_bars = torch.cumprod(alphas, dim=0) # [T]
# 获取对应时间步的ᾱ_t
sqrt_alpha_bar_t = torch.sqrt(alpha_bars[t]) # [B] or scalar
sqrt_one_minus_alpha_bar_t = torch.sqrt(1 - alpha_bars[t])
noise = torch.randn_like(x0) # 标准正态噪声
# 应用重参数化技巧:xt = √ᾱₜ x₀ + √(1−ᾱₜ) ε
xt = sqrt_alpha_bar_t.view(-1, 1, 1, 1) * x0 + \
sqrt_one_minus_alpha_bar_t.view(-1, 1, 1, 1) * noise
return xt, noise
# 示例使用
beta_schedule = np.linspace(1e-4, 0.02, 1000) # 线性噪声调度
x0 = torch.rand(4, 3, 64, 64) # 模拟一批图像
t = torch.randint(0, 1000, (4,)) # 随机选择时间步
xt, eps = forward_diffusion(x0, t, beta_schedule)
代码逻辑逐行解读:
betas = torch.tensor(beta_scheduler, ...):将预设的噪声调度转换为PyTorch张量;alphas = 1 - betas:计算每一步的保留系数 $ \alpha_t = 1 - \beta_t $;torch.cumprod(alphas, dim=0):沿时间维度累积乘积,获得 $ \bar{\alpha}_t $;sqrt(...):分别提取 $ \sqrt{\bar{\alpha}_t} $ 和 $ \sqrt{1 - \bar{\alpha}_t} $;noise = torch.randn_like(x0):生成与输入同形状的标准正态噪声;- 使用重参数化公式合成 $ \mathbf{x}_t $,确保梯度可导。
该实现允许批量处理不同时间步的图像,适用于后续训练中的噪声预测任务。
2.1.2 反向去噪过程:神经网络的学习目标
反向过程的目标是从纯噪声 $ \mathbf{x} T \sim \mathcal{N}(0, \mathbf{I}) $ 开始,逐步去除噪声以恢复原始图像 $ \mathbf{x}_0 $。由于真实后验 $ p(\mathbf{x} {t-1}|\mathbf{x} t) $ 不易直接建模,Stable Diffusion采用变分推断方法,训练一个神经网络 $ \epsilon \theta(\mathbf{x}_t, t) $ 来估计每一步加入的噪声。
具体而言,模型学习近似后验分布:
p_\theta(\mathbf{x} {0:T}) = p(\mathbf{x}_T) \prod {t=1}^T p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t)
其中每个去噪步骤定义为:
p_\theta(\mathbf{x} {t-1} | \mathbf{x}_t) = \mathcal{N}(\mathbf{x} {t-1}; \boldsymbol{\mu} \theta(\mathbf{x}_t, t), \boldsymbol{\Sigma} \theta(\mathbf{x}_t, t))
均值 $ \boldsymbol{\mu}_\theta $ 可由以下公式重构:
\boldsymbol{\mu} \theta(\mathbf{x}_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \hat{\boldsymbol{\epsilon}} \theta(\mathbf{x}_t, t) \right)
协方差 $ \boldsymbol{\Sigma}_\theta $ 通常固定为 $ \sigma_t^2 \mathbf{I} $,可通过学习或设定为 $ \beta_t $ 或 $ \tilde{\beta}_t $。
训练目标是最小化变分下界(ELBO),简化后等价于最小化噪声预测误差:
\mathcal{L} \text{simple} = \mathbb{E} {t,\mathbf{x} 0,\boldsymbol{\epsilon}} \left[ | \boldsymbol{\epsilon} - \hat{\boldsymbol{\epsilon}} \theta(\mathbf{x}_t, t) |^2 \right]
这构成了整个扩散模型训练的核心损失函数。
| 时间阶段 | 输入 $ \mathbf{x}_t $ | 输出目标 | 模型行为 |
|---|---|---|---|
| 早期(t接近T) | 强噪声图像 | 噪声 $ \boldsymbol{\epsilon} $ | 学习全局结构 |
| 中期(t≈T/2) | 半噪声图像 | 细节噪声 | 恢复主体轮廓 |
| 后期(t接近0) | 弱噪声图像 | 微小扰动 | 精修纹理细节 |
该机制保证了模型能够分层恢复图像信息,避免一次性建模导致的模式崩溃问题。
import torch.nn as nn
class SimpleUNet(nn.Module):
def __init__(self):
super().__init__()
self.time_embed = nn.Embedding(1000, 128)
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 128, 3, stride=2, padding=1),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(64, 3, 3, padding=1)
)
def forward(self, x, t):
# x: [B, 3, H, W], t: [B]
time_emb = self.time_embed(t).view(-1, 128, 1, 1) # [B, 128, 1, 1]
h = self.encoder(x) # [B, 128, H//2, W//2]
h = h + time_emb
out = self.decoder(h)
return out # 预测噪声 ε
model = SimpleUNet()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 训练循环片段
for x0 in dataloader:
optimizer.zero_grad()
t = torch.randint(0, 1000, (x0.shape[0],))
xt, true_noise = forward_diffusion(x0, t, beta_schedule)
pred_noise = model(xt, t)
loss = nn.functional.mse_loss(pred_noise, true_noise)
loss.backward()
optimizer.step()
代码解释:
time_embed: 将离散时间步映射为连续向量,使模型感知噪声水平;encoder/decoder: 构成基础U-Net骨架,提取多尺度特征;forward(): 接收带噪声图像和时间步,输出噪声预测;- 损失函数使用MSE衡量预测噪声与真实噪声之间的差异;
- 该简化的U-Net虽未包含注意力模块,但已体现扩散模型训练的基本流程。
2.1.3 损失函数的设计与优化策略
尽管简单均方误差(MSE)在实践中表现良好,但原始DDPM论文提出了一种更优的加权损失形式:
\mathcal{L} \text{VLB} = \mathbb{E}_t \left[ \lambda_t | \boldsymbol{\epsilon} - \hat{\boldsymbol{\epsilon}} \theta(\mathbf{x}_t, t) |^2 \right]
其中权重 $ \lambda_t $ 对应于各时间步的重要性,常设为 $ \frac{1}{2\sigma_t^2} $,以强调前期粗粒度重建的重要性。
现代实现中,Stable Diffusion进一步采用 Learned Range Loss 或 V-prediction Parameterization ,将预测目标从噪声改为速度(velocity)或直接建模 $ \mathbf{v} = \sqrt{\bar{\alpha}_t} \boldsymbol{\epsilon} - \sqrt{1 - \bar{\alpha}_t} \mathbf{x}_0 $,提升训练稳定性。
此外,优化策略还包括:
- 梯度裁剪 :防止爆炸梯度;
- 指数移动平均(EMA) :维护参数滑动平均,提升生成质量;
- 混合精度训练(AMP) :降低显存占用,加速收敛;
- 课程学习(Curriculum Learning) :优先训练低噪声阶段,逐步扩展至全范围。
| 优化技术 | 目标 | 效果 |
|---|---|---|
| EMA | 提升生成稳定性 | FID指标下降10%-15% |
| AMP | 减少显存消耗 | 显存降低40%,速度提升1.5x |
| Gradient Clipping | 防止训练发散 | 支持更大batch size |
| Cosine Annealing LR | 平滑收敛 | 更稳定到达最优解 |
这些策略共同保障了大规模扩散模型的高效可训练性,使其能在有限资源下实现高质量图像生成。
2.2 Stable Diffusion的结构创新
相较于传统扩散模型直接在像素空间操作,Stable Diffusion引入三大关键创新:潜在空间压缩、U-Net时空注意力机制与CLIP语义编码,实现了性能与效率的双重突破。
2.2.1 潜在空间(Latent Space)压缩机制
Stable Diffusion最显著的改进是将扩散过程迁移至低维潜在空间。其核心依赖一个预训练的自动编码器 $ (\mathcal{E}, \mathcal{D}) $,其中编码器 $ \mathcal{E} $ 将图像 $ \mathbf{x} \in \mathbb{R}^{3 \times H \times W} $ 压缩为潜变量 $ \mathbf{z} = \mathcal{E}(\mathbf{x}) \in \mathbb{R}^{4 \times H/8 \times W/8} $,解码器 $ \mathcal{D} $ 负责重建。
例如,对于一张 $ 512 \times 512 $ 的RGB图像,原始像素空间维度为 $ 3 \times 512^2 = 786,432 $,而在潜空间仅为 $ 4 \times 64^2 = 16,384 $,减少约98%的计算量。
from torchvision import models
class AutoencoderKL(nn.Module):
def __init__(self, in_channels=3, latent_dim=4):
super().__init__()
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 128, 3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(128, 256, 3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(256, latent_dim * 2, 3) # 输出均值与方差
)
self.decoder = nn.Sequential(
nn.Conv2d(latent_dim, 256, 3, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(128, in_channels, 4, stride=2, padding=1),
nn.Sigmoid()
)
def encode(self, x):
h = self.encoder(x)
mu, log_var = h.chunk(2, dim=1)
std = torch.exp(0.5 * log_var)
z = mu + std * torch.randn_like(std)
return z, mu, log_var
def decode(self, z):
return self.decoder(z)
def forward(self, x):
z, mu, log_var = self.encode(x)
recon = self.decode(z)
return recon, mu, log_var
该编码器采用KL正则化,迫使潜空间接近标准正态分布,便于扩散模型初始化。实验表明,即使轻微失真也能在解码后恢复合理视觉内容,体现了潜空间的强大泛化能力。
2.2.2 U-Net主干网络的时空注意力机制
Stable Diffusion的U-Net不仅具备跳跃连接,还在多个层级嵌入自注意力与交叉注意力模块。自注意力捕捉图像内部长程依赖,而交叉注意力则融合文本编码信息。
特别地,空间注意力作用于特征图的空间维度,允许模型关注远距离像素关系;时间步信息通过位置编码注入网络各层,指导去噪节奏。
2.2.3 CLIP文本编码器的语义对齐能力
使用CLIP ViT-L/14作为文本编码器,将提示词映射为768维上下文向量序列。这些向量通过交叉注意力注入U-Net,实现文本与图像特征的细粒度对齐。
下表对比不同组件的作用:
| 组件 | 功能 | 影响 |
|---|---|---|
| VAE | 降维与重建 | 决定生成分辨率上限 |
| U-Net | 噪声预测 | 控制生成质量与速度 |
| CLIP | 文本理解 | 决定语义准确性 |
正是这些模块的协同工作,使Stable Diffusion成为兼具效率与表现力的强大生成引擎。
3. 教育场景下的需求分析与技术适配设计
随着人工智能生成内容(AIGC)技术的快速演进,Stable Diffusion 已从艺术创作工具逐步拓展至专业领域,尤其在教育行业展现出显著的应用潜力。然而,将一项前沿生成模型无缝融入复杂、多样且高度敏感的教育生态,并非简单的“技术嫁接”即可实现。必须深入剖析教育场景中的真实痛点,结合教学逻辑、认知规律和伦理边界,进行系统性的需求识别与技术路径适配。本章聚焦于教育辅导的核心问题识别、跨学科应用映射、安全控制机制构建以及人机交互模式优化四大维度,全面探讨如何让 Stable Diffusion 真正服务于教与学的本质目标。
3.1 教育辅导的核心痛点识别
现代教育正面临从“标准化供给”向“个性化服务”转型的关键阶段,传统教学资源生产方式已难以满足日益增长的多样化学习需求。在此背景下,三类核心痛点尤为突出:学习材料可视化不足、个性化内容供给滞后、特殊学生群体支持缺失。这些问题不仅制约了教学质量提升,也加剧了教育资源分配的不均衡。
3.1.1 学习材料可视化不足的问题
抽象概念是许多学科教学中的难点,尤其是物理、化学、数学等领域,学生往往因缺乏直观感知而产生理解障碍。例如,在讲解“电磁感应”或“函数极限”时,教师多依赖文字描述和静态图表,难以动态呈现过程演变。尽管部分教材配有插图,但数量有限、更新缓慢,且无法根据具体教学情境灵活调整视角或细节层次。
可视化不足的根本原因在于传统图像制作成本高昂。一幅高质量的教学示意图通常需要专业美工设计、反复修改,并经过学科专家审核,整个流程耗时数天甚至更久。这种低效的内容生产机制使得一线教师难以随时获取所需视觉素材。Stable Diffusion 的出现为解决这一瓶颈提供了新思路——通过文本提示即时生成符合语义的图像,极大缩短从“想法”到“可视成果”的时间跨度。
更重要的是,该模型支持多角度、多风格的输出控制。例如,输入提示词 "a 3D illustration of a mitochondria with labeled parts, cartoon style" 可生成适合初中生物课使用的卡通化线粒体结构图;而 "photorealistic cross-section of human heart showing blood flow direction" 则可用于医学预科生的解剖学习。这种按需生成能力打破了资源固化格局,使可视化真正成为课堂教学的“活工具”。
| 应用场景 | 传统方式局限 | Stable Diffusion 改进 |
|---|---|---|
| 物理实验示意图 | 静态图片,无动态过程 | 可生成系列帧模拟运动轨迹 |
| 化学分子结构 | 二维投影难体现空间构型 | 支持立体渲染与旋转视角 |
| 历史事件还原 | 文字描述为主,缺乏现场感 | 能再现特定时空背景画面 |
| 数学几何证明 | 图形固定,无法交互变形 | 可生成不同参数下的图形变体 |
上述对比表明,Stable Diffusion 并非仅替代绘图工具,而是重构了教学内容的表达范式。它赋予教师更强的“视觉叙事”能力,有助于激发学生的空间想象力与探究兴趣。
3.1.2 个性化内容供给的滞后性
当前教育系统普遍采用统一教材与标准化测试,忽视了学生个体差异。研究表明,学习者在认知风格、知识基础、兴趣偏好等方面存在显著异质性,单一内容形式易导致部分学生“听不懂”或“不想听”。理想状态下,每位学生都应获得与其认知水平相匹配的学习材料,但现实中教师精力有限,难以做到大规模个性化定制。
以作文批改为例,教师常建议学生“增加细节描写”,但缺乏具体示范。若能基于学生原文自动生成对应的场景插图,则可提供直观反馈。例如,学生写道:“夕阳下,老槐树影子拉得很长。”系统可据此生成一张温暖色调的画面,帮助其理解“氛围营造”的具象表现。此类即时反馈机制正是个性化教学的重要组成部分。
Stable Diffusion 结合自然语言处理技术,可实现“文本→图像”的自动化映射。以下是一个简化版的集成调用代码示例:
import requests
from PIL import Image
from io import BytesIO
def generate_educational_image(prompt: str, negative_prompt: str = "", steps: int = 30):
"""
调用本地Stable Diffusion API生成教学图像
:param prompt: 正面提示词(如"一个孩子在显微镜前观察洋葱细胞")
:param negative_prompt: 负面提示词(如"模糊, 失真, 错误比例")
:param steps: 采样步数,影响生成质量与速度
:return: PIL.Image对象
"""
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"steps": steps,
"width": 768,
"height": 512,
"cfg_scale": 7.5 # 分类器自由引导尺度,控制对提示的遵循程度
}
try:
response = requests.post("http://127.0.0.1:7860/sdapi/v1/txt2img", json=payload)
r = response.json()
image_data = r['images'][0]
image = Image.open(BytesIO(base64.b64decode(image_data)))
return image
except Exception as e:
print(f"图像生成失败: {e}")
return None
# 示例使用
image = generate_educational_image(
prompt="A clear diagram showing photosynthesis in a green leaf, educational style",
negative_prompt="blurry, unrealistic colors, text overlay"
)
代码逻辑逐行解析:
- 第6–13行:定义函数接口,明确输入参数及其作用。
prompt是核心语义指令,直接影响生成内容;negative_prompt用于排除不良特征;steps控制去噪迭代次数,过高会延长响应时间,过低则图像粗糙。 - 第15–19行:构建请求体(payload),其中
width和height设定输出分辨率,适应屏幕显示;cfg_scale参数调节模型对提示词的服从强度,值越大越严格,但可能牺牲多样性。 - 第21–27行:发送 POST 请求至本地部署的 WebUI API 接口(默认端口7860)。返回结果包含 Base64 编码的图像数据,需解码后转换为 PIL 格式以便后续处理。
- 第29–33行:异常捕获确保服务稳定性,避免因网络或模型错误中断教学流程。
该代码模块可嵌入智能辅导系统,实现在作业评语旁自动插入相关示意图,形成“文字反馈+视觉强化”的双重引导机制,有效提升个性化支持力度。
3.1.3 特殊学生群体的认知支持缺口
特殊教育长期面临资源匮乏与师资短缺的双重压力,尤其是在情感认知、语言表达和抽象思维训练方面。对于自闭症谱系障碍(ASD)儿童而言,理解他人情绪是一项巨大挑战。他们难以通过面部表情判断喜怒哀乐,传统教学依赖卡片训练,形式单调且互动性差。
Stable Diffusion 可用于生成高保真的情绪表情图库。教师输入如 "close-up face of a boy smiling warmly, eyes crinkled" 或 "girl frowning with furrowed brows, looking confused" 等描述,即可批量创建标准化的情绪样本。相比真实照片,AI生成图像可精准控制光照、角度、肤色等变量,减少干扰因素,提升训练一致性。
此外,针对阅读障碍(dyslexia)学生,可通过图像辅助增强词汇记忆。例如,将抽象词“justice”转化为天平与法袍的视觉符号,或将“evolution”表现为从鱼到人的渐进演化图。这种多模态编码策略已被认知心理学证实能显著提高信息留存率。
值得注意的是,这类应用需特别关注生成内容的真实性与文化包容性。以下表格列出了常见风险及应对建议:
| 风险类型 | 具体表现 | 技术缓解措施 |
|---|---|---|
| 种族偏见 | 生成人物集中于某一人种 | 在提示中明确指定多样性,如”diverse ethnicities” |
| 性别刻板印象 | 科学家均为男性,护士均为女性 | 使用中性或平衡描述,如”scientist wearing lab coat, gender-neutral” |
| 情绪误标 | 微笑却搭配悲伤情境 | 引入CLIP模型进行语义一致性校验 |
| 身体歧视 | 残疾人形象缺失或扭曲 | 添加正面描述,如”wheelchair user participating in science fair” |
综上所述,Stable Diffusion 不仅能填补特殊教育的资源空白,更有望推动“普特融合”教育的发展,让更多学生享有公平而有质量的学习机会。
3.2 Stable Diffusion在不同学科的应用匹配
Stable Diffusion 的跨模态生成能力使其具备广泛的学科适配潜力。根据不同课程的知识属性与教学目标,需针对性设计提示工程策略与输出控制机制,确保生成内容既具吸引力又符合理性严谨性。以下从科学、人文、数学三个典型领域展开分析。
3.2.1 科学类课程中的实验模拟图像生成
科学教育强调“做中学”,但受限于设备、安全与成本,许多实验无法在课堂开展。虚拟仿真是解决方案之一,但传统软件开发周期长、维护成本高。Stable Diffusion 提供了一种轻量级替代路径——通过文本描述快速生成实验场景图像,辅助学生建立过程预期与现象预测。
以高中化学“电解水实验”为例,标准装置包括直流电源、电极、电解槽和气体收集管。传统教学仅展示成品图,学生难以理解内部反应机制。利用 Stable Diffusion,教师可分步生成多个关键帧:
prompts = [
"Electrolysis setup with labeled parts: battery, electrodes, water container, gas collection tubes",
"Close-up animation frame: bubbles forming at cathode during water electrolysis, scientific illustration",
"Two test tubes filled with gases above electrodes, one twice the volume of the other, indicating H2 and O2 ratio"
]
for i, p in enumerate(prompts):
img = generate_educational_image(p, negative_prompt="unlabeled, messy, incorrect proportions")
img.save(f"frame_{i+1}.png")
参数说明与逻辑分析:
prompts列表按实验进程组织,体现“整体→局部→结果”的认知递进;- 每次调用均加入负面提示以排除常见错误,如标签缺失或比例失调;
- 输出保存为 PNG 格式,便于导入PPT或H5页面形成动画序列。
此类图像虽不能完全替代真实实验,但可作为预习导学材料,帮助学生建立心理表征,提升实验操作效率。同时,教师还可生成“错误案例”图像(如反接电源极性),用于辨析训练,培养批判性思维。
3.2.2 人文类课程的历史情境再现
历史教学常因时空距离感而导致学生“隔岸观火”。单纯讲述“贞观之治”或“美国西进运动”难以引发共鸣。Stable Diffusion 可通过精细提示重建特定时代风貌,让学生“走进”历史现场。
例如,要生成唐代长安城东市的市井生活图景,提示词可设计为:
“Busy market scene in Chang’an during Tang Dynasty, merchants selling silk and ceramics, people in traditional Hanfu clothing, wooden buildings with tiled roofs, horse-drawn carts, morning light, wide-angle view, historically accurate”
此提示包含六大要素:地点(Chang’an)、时间(Tang Dynasty)、主体活动(merchants selling)、服饰特征(Hanfu)、建筑风格(wooden with tiled roofs)、光影氛围(morning light),并通过“historically accurate”引导模型优先参考可靠史料。
为提高生成准确性,建议结合外部知识库进行提示增强。如下表所示:
| 历史要素 | 可信来源 | 提示注入关键词 |
|---|---|---|
| 唐代服饰 | 《旧唐书·舆服志》 | “round-collar robe, long sleeves, headscarf for women” |
| 建筑形制 | 大明宫遗址考古报告 | “hip-and-gable roof, dougong brackets, elevated platform” |
| 货币单位 | 开元通宝出土记录 | “copper coins strung on rope” |
| 社会等级 | 唐律疏议 | “official in purple robe, commoner in plain cotton” |
通过将学术研究成果转化为具体描述词,可大幅提升生成内容的历史可信度。此外,教师还可引导学生参与提示编写,将其变为史料分析与创意表达相结合的研究性学习任务。
3.2.3 数学抽象概念的图形化表达
数学因其高度抽象性常被视为“最难科目”之一。许多学生能记忆公式却无法理解其几何意义。Stable Diffusion 可将代数关系转化为视觉隐喻,打通符号与直觉之间的桥梁。
例如,讲解“导数即切线斜率”时,可生成一组连续变化的割线逼近切线的过程图。提示词如下:
“Graph of y=x^2 showing secant lines approaching tangent at point (2,4), arrows indicating limit process, clean coordinate axes, educational diagram style”
该提示强调动态趋势(approaching)、关键点标注((2,4))、坐标系清晰性,避免艺术化风格干扰数学本质。生成图像可用于微课视频背景,配合语音讲解实现多通道输入。
更进一步,可结合 LaTeX 渲染引擎与图像生成API,构建全自动讲义生成系统。伪代码如下:
import matplotlib.pyplot as plt
import sympy as sp
def plot_function_and_derivative(f_expr, x_point):
x = sp.Symbol('x')
f = sp.lambdify(x, f_expr, 'numpy')
df = sp.lambdify(x, sp.diff(f_expr, x), 'numpy')
# 绘制函数图像
xs = np.linspace(-5, 5, 400)
plt.plot(xs, f(xs), label=f'y={str(f_expr)}')
plt.plot(xs, df(xs), '--', label=f"y'={sp.diff(f_expr, x)}")
# 标注切点
y_point = f(x_point)
slope = df(x_point)
plt.scatter([x_point], [y_point], color='red')
plt.annotate(f'({x_point},{y_point})', (x_point, y_point))
plt.legend()
plt.grid(True)
plt.savefig("math_plot.png")
plt.close()
# 调用SD增强视觉效果
enhance_with_sd("math_plot.png", "clean mathematical graph with smooth curves and clear labels")
该流程先由符号计算生成精确图形,再交由 Stable Diffusion 进行美学优化,兼顾准确性与可读性,适用于自动生成习题解析图或复习资料。
3.3 教学安全与伦理边界设定
尽管 Stable Diffusion 具备强大生成能力,但在教育环境中必须设置严格的约束机制,防止不当内容传播。安全性不仅涉及法律合规,更关乎青少年心理健康与发展权益。
3.3.1 内容过滤机制的必要性
开放式的文本到图像模型存在被滥用的风险。用户可能输入暴力、色情或仇恨相关提示词,生成有害图像。因此,任何面向学生的部署方案都必须内置多层过滤体系。
一种可行架构包括前端关键词拦截、中间语义检测与后端图像审查三阶段:
import re
SENSITIVE_KEYWORDS = ['violence', 'nudity', 'blood', 'weapon', 'hate']
def is_prompt_safe(prompt: str) -> bool:
prompt_lower = prompt.lower()
# 阶段一:关键词匹配
for kw in SENSITIVE_KEYWORDS:
if kw in prompt_lower:
return False
# 阶段二:正则模式识别
patterns = [
r'\bkill\b.*\bteacher\b',
r'\bexplode\b.*\bschool\b'
]
for p in patterns:
if re.search(p, prompt_lower):
return False
# 阶段三:调用NSFW分类器API
nsfw_score = call_nsfw_classifier(prompt)
if nsfw_score > 0.8:
return False
return True
该函数依次执行字面匹配、语义模式识别与外部模型评分,构成纵深防御体系。其中 call_nsfw_classifier 可对接 CLIP-based 安全模型(如 Salesforce BLIP 或 Hugging Face 的 nsfw detector),实现细粒度判断。
3.3.2 年龄适宜性与文化敏感性的技术保障
不同年龄段学生对信息的接受能力差异显著。小学低年级不宜接触过于复杂的图像细节,而高中生则可承受一定抽象表达。系统应支持基于用户身份的动态内容调控。
| 年龄段 | 图像风格建议 | 技术实现方式 |
|---|---|---|
| 6–9岁 | 卡通化、高对比色、大尺寸文字 | 添加”cartoon style, bright colors”至提示 |
| 10–13岁 | 半写实插画,适度细节 | 使用”illustration style, detailed but not realistic” |
| 14岁以上 | 接近真实摄影风格 | 启用”photorealistic, natural lighting” |
此外,文化敏感性也不容忽视。同一提示在不同地区可能产生歧义。例如,“dragon”在西方象征邪恶,而在东亚代表祥瑞。系统可通过地理定位自动注入上下文修正词,如对中国用户添加“, Chinese style, auspicious symbol”。
3.3.3 防止误导性信息生成的约束条件
最隐蔽的风险来自“看似合理但实际错误”的内容。例如,生成“光合作用只在白天进行”是正确的,但若图像显示夜晚植物释放氧气,则造成科学误解。为此,需引入知识验证层。
一种方法是建立“事实检查规则库”,并与生成结果进行比对:
FACT_CHECK_RULES = {
"photosynthesis": ["plants absorb CO2", "release O2", "require sunlight"],
"gravity": ["always attractive", "depends on mass and distance"]
}
def validate_image_content(prompt, generated_tags):
for concept, facts in FACT_CHECK_RULES.items():
if concept in prompt.lower():
for fact in facts:
if fact not in generated_tags:
return False, f"Missing key fact: {fact}"
return True, "All checks passed"
该机制依赖图像标签提取模型(如 BLIP 或 ViT-GNN)对生成图进行反向推理,确认其是否涵盖必要知识点。虽尚处初级阶段,但代表了未来“可信生成”的发展方向。
3.4 用户交互模式的设计原则
技术价值最终体现在用户体验上。教育场景下的交互设计必须兼顾教师的专业控制需求与学生的操作便捷性,同时探索多模态输入的可能性。
3.4.1 教师端的内容可控性接口设计
教师需拥有对生成过程的充分掌控权,包括提示编辑、参数调节、版本管理等功能。理想界面应提供“高级模式”与“模板库”双路径:
- 高级模式 :允许手动编写提示词,调节采样器(如 Euler a vs DDIM)、CFG scale、种子(seed)等参数;
- 模板库 :预设常用教学场景模板,如“细胞分裂示意图”、“牛顿第一定律演示图”,一键调用。
{
"template_name": "Mitosis Diagram",
"base_prompt": "Cell undergoing mitosis, clearly showing prophase, metaphase, anaphase, telophase",
"style": "educational illustration",
"negative_prompt": "text, numbers, blurry nuclei",
"parameters": {
"sampler": "Euler a",
"steps": 25,
"cfg_scale": 7
}
}
该 JSON 模板结构清晰,便于批量管理和共享,也可作为教研组集体备课成果沉淀。
3.4.2 学生端的操作简化与引导机制
学生界面应极度简化,避免技术术语干扰。可采用“填空式提示构建器”:
“我想画一幅关于 _ _ 的图,它应该看起来 _ ,不要有 ___ 。”
用户只需填写空白即可生成图像,系统后台自动拼接完整提示。同时加入“示例推荐”按钮,降低启动门槛。
3.4.3 多模态输入(语音+文字)的支持路径
考虑到低龄儿童识字能力有限,系统应支持语音输入。通过 ASR(自动语音识别)将口语转为文本提示,再经语义规范化处理送入生成模型。
def voice_to_image(audio_file):
text = asr_engine.transcribe(audio_file) # 如Whisper模型
cleaned_prompt = normalize_utterance(text) # 将口语转为规范描述
return generate_educational_image(cleaned_prompt)
此路径不仅提升无障碍访问能力,也为语言学习者提供“说→看”的沉浸式体验。
综上,Stable Diffusion 在教育领域的成功应用,离不开对真实需求的深刻洞察与对技术能力的精准调校。唯有将算法潜力与教育智慧深度融合,方能真正释放其变革力量。
4. Stable Diffusion在教育辅导中的实践部署方案
将Stable Diffusion技术从理论研究推进到实际教育场景的应用,需要构建一套完整、安全、可扩展的部署体系。当前,许多教育机构希望在保障数据隐私和教学规范的前提下,利用该模型生成高质量的教学视觉资源。为此,必须系统性地规划本地化环境搭建、模型微调策略、典型应用场景实现路径以及与现有教学平台的集成机制。本章深入探讨如何在真实教育环境中落地Stable Diffusion,并通过具体操作流程和技术细节展示其可行性与稳定性。
4.1 本地化部署环境搭建
为确保教学数据的安全性和系统的可控性,教育机构通常倾向于采用本地化部署方式运行Stable Diffusion模型。这种方式避免了敏感信息上传至云端的风险,同时支持离线使用,适用于网络受限的校园环境。本地部署的关键在于合理配置硬件资源、选择合适的WebUI框架并完成模型权重的安全获取与管理。
4.1.1 硬件资源配置要求(GPU显存、内存等)
Stable Diffusion模型对计算资源有较高需求,尤其是在高分辨率图像生成时。推荐配置如下:
| 组件 | 最低要求 | 推荐配置 | 高性能配置 |
|---|---|---|---|
| GPU 显卡 | NVIDIA GTX 1660 Ti (6GB) | RTX 3060 (12GB) | RTX 4090 (24GB) |
| 显存 | ≥6GB | ≥12GB | ≥24GB |
| CPU | 四核以上 | 六核以上 | 八核以上 |
| 内存 | 16GB DDR4 | 32GB DDR4 | 64GB DDR5 |
| 存储空间 | 50GB SSD | 100GB NVMe SSD | 500GB NVMe SSD |
说明 :
- GPU显存 是决定能否顺利加载模型的核心因素。基础版 v1.4 或 v1.5 模型约占用4~5GB显存,若启用高分辨率采样(如768×768)或使用ControlNet插件,则需至少12GB。
- 使用 --medvram 或 --lowvram 启动参数可在有限显存下运行,但会牺牲速度。
- 若计划进行LoRA微调训练,建议使用RTX 3090及以上显卡以支持混合精度训练。
# 启动Stable Diffusion WebUI时指定低显存模式
python launch.py --medvram --precision full --no-half
逻辑分析 :上述命令中,
--medvram表示启用中等显存优化模式,自动将部分模型层移入CPU内存;--precision full关闭半精度计算,提升数值稳定性;--no-half防止FP16导致的NaN错误,常用于老旧显卡或复杂推理任务。
4.1.2 WebUI框架的选择与安装流程
目前最广泛使用的开源WebUI是 AUTOMATIC1111/stable-diffusion-webui ,它提供图形界面、扩展插件生态及API支持,非常适合教育场景下的非专业用户操作。
安装步骤(基于Windows + Conda环境):
# 1. 创建独立虚拟环境
conda create -n sd-env python=3.10
conda activate sd-env
# 2. 克隆项目仓库
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
# 3. 安装依赖(国内建议换源)
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 4. 启动服务
webui-user.bat
参数说明 :
-requirements.txt包含Flask、Gradio、xformers等关键组件;
- 可通过修改webui-user.bat中的COMMANDLINE_ARGS添加自定义参数,例如--listen允许局域网访问;
- 若启用xformers加速注意力计算,需单独安装并与PyTorch版本匹配。
安装完成后,浏览器访问 http://localhost:7860 即可进入图形界面。教师可通过输入提示词(prompt)、调整采样步数、选择检查点模型等方式快速生成图像。
4.1.3 模型权重的安全下载与版本管理
由于原始模型权重(如 v1-5-pruned.ckpt )受版权保护且体积庞大(约4-7GB),需通过合法渠道获取。教育机构应建立内部模型库,统一审核与分发。
| 模型名称 | 来源 | 文件大小 | 适用场景 |
|---|---|---|---|
stable-diffusion-v1-5 |
Hugging Face 官方 | ~7GB | 通用图像生成 |
RealisticVision-V5.1 |
CivitAI 社区 | ~6.8GB | 写实风格插图 |
DreamShaper_8 |
CivitAI | ~7.2GB | 艺术化教学素材 |
Protogen-x3.4 |
Protogen系列 | ~6.9GB | 科普类图像生成 |
安全建议 :
- 所有模型文件应在内网服务器集中存储,禁止直接从第三方网站实时下载;
- 使用SHA256校验值验证完整性,防止恶意篡改;
- 建立模型版本管理系统(如Git LFS或MinIO对象存储),记录每次更新日志。
# 示例:Python脚本校验模型完整性
import hashlib
def verify_model_hash(filepath, expected_hash):
sha256 = hashlib.sha256()
with open(filepath, "rb") as f:
while chunk := f.read(8192):
sha256.update(chunk)
return sha256.hexdigest() == expected_hash
# 使用示例
if verify_model_hash("models/v1-5-pruned.ckpt", "d7a417b8..."):
print("模型校验通过")
else:
print("警告:模型可能被篡改!")
逐行解读 :
- 第1–2行导入哈希模块;
-verify_model_hash函数按块读取大文件,避免内存溢出;
-chunk := f.read(8192)使用海象运算符实现边读边更新;
- 返回布尔值用于自动化部署流水线中的质量控制。
4.2 教学专用模型微调实践
虽然预训练Stable Diffusion具备一定通用能力,但在特定学科领域(如生物学细胞结构、历史人物服饰)的表现仍存在偏差。因此,针对教育内容进行轻量级微调至关重要。LoRA(Low-Rank Adaptation)技术因其参数效率高、易于部署,成为教育场景下的首选方案。
4.2.1 教育类图像数据集的收集与标注
构建高质量微调数据集是成功的关键。以“初中生物细胞图谱”为例,应遵循以下流程:
- 来源采集 :从公开教材(如人教版生物学)、国家教育资源平台、PubMed Central图像库中提取清晰图片;
- 清洗去噪 :剔除模糊、重复或带有水印的图像;
- 文本配对 :每张图像配以标准化描述文本,格式为:“[细胞类型]的显微图像,显示[关键结构],染色方式为[HE染色/荧光标记]”;
- 标签分类 :按年级、知识点、难度等级打标,便于后续检索与调用。
| 图像ID | 描述文本 | 标签类别 | 分辨率 |
|---|---|---|---|
| cell_001.jpg | 动物细胞的光学显微图像,可见细胞核、线粒体和高尔基体,HE染色 | 初二生物/细胞结构 | 512×512 |
| plant_003.png | 植物叶肉细胞,含有叶绿体和液泡,绿色荧光标记 | 初三生物/光合作用 | 768×768 |
注意事项 :
- 文本描述应避免歧义,例如不写“大的圆形结构”,而明确为“直径约10μm的细胞核”;
- 数据集总量建议不少于500张,以保证泛化能力。
4.2.2 使用LoRA进行轻量级参数调整
LoRA通过在U-Net的注意力层插入低秩矩阵来调整模型行为,仅需训练0.1%~1%的参数即可达到良好效果。
# 使用Kohya_SS工具包进行LoRA训练(简化版配置)
from accelerate import Accelerator
import torch
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
from peft import LoraConfig, get_peft_model
# 加载基础模型
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
unet = pipe.unet
# 配置LoRA参数
lora_config = LoraConfig(
r=8, # 低秩维度
lora_alpha=16, # 缩放系数
target_modules=["to_q", "to_v"], # 注入模块
lora_dropout=0.1,
bias="none",
)
# 应用LoRA到UNet
model = get_peft_model(unet, lora_config)
# 训练循环片段
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
for batch in dataloader:
pixel_values = batch["images"]
input_ids = batch["tokens"]
noise = torch.randn_like(pixel_values)
timesteps = torch.randint(0, 1000, (pixel_values.shape[0],))
noisy_images = pipe.scheduler.add_noise(pixel_values, noise, timesteps)
noise_pred = model(noisy_images, timesteps, encoder_hidden_states=input_ids).sample
loss = torch.nn.functional.mse_loss(noise_pred, noise)
loss.backward()
optimizer.step()
optimizer.zero_grad()
代码解析 :
-r=8表示每个权重矩阵分解为两个秩为8的小矩阵,极大减少训练参数;
-target_modules=["to_q", "to_v"]指定只在QKV投影层插入LoRA,保持其他部分冻结;
- MSE损失函数衡量预测噪声与真实噪声之间的差异;
- 训练结束后,保存.safetensors格式的LoRA权重,可在WebUI中动态加载。
4.2.3 微调后模型的效果评估指标体系
为科学评价微调成效,需建立多维评估体系:
| 指标 | 测量方法 | 目标值 |
|---|---|---|
| 提示一致性得分(PCS) | CLIP-I/T相似度 | ≥0.75 |
| 结构准确性(SA) | 专家人工评分(1–5分) | 平均≥4.2 |
| 多样性指数(DI) | 生成图像LPIPS距离均值 | >0.35 |
| 推理延迟 | 单图生成时间(Euler a, 20 steps) | <8秒 |
解释 :
- PCS 反映生成图像与文本描述的语义匹配程度;
- SA 由生物教师团队盲评,判断关键结构是否正确呈现;
- DI 过高可能导致混乱,过低则缺乏变化,理想区间为0.3–0.5;
- 所有测试在相同硬件环境下执行,确保公平对比。
4.3 典型应用场景的实现流程
Stable Diffusion在教育中的价值体现在具体场景的高效赋能。以下是三个典型应用的端到端实现路径。
4.3.1 自动生成生物细胞结构示意图
教师输入:“一个典型的植物根尖分生组织细胞,正在进行有丝分裂中期,染色体整齐排列在赤道板上。”
prompt = "plant root meristem cell in metaphase of mitosis, chromosomes aligned at equatorial plate, clear nuclear envelope breakdown, brightfield microscopy style"
negative_prompt = "blurry, low resolution, animal cell, telophase, cytokinesis"
# 调用API生成图像
import requests
response = requests.post(
"http://localhost:7860/sdapi/v1/txt2img",
json={
"prompt": prompt,
"negative_prompt": negative_prompt,
"steps": 30,
"width": 512,
"height": 512,
"cfg_scale": 7,
"seed": -1,
"sampler_name": "Euler a",
"restore_faces": True
}
)
image_data = response.json()['images'][0]
执行逻辑 :
- 使用WebUI暴露的/sdapi/v1/txt2img接口进行程序化调用;
-cfg_scale=7增强对提示词的遵循程度;
-restore_faces=True虽主要用于人脸,但有助于提升整体细节清晰度;
- 返回Base64编码图像,可直接嵌入PPT或课件系统。
4.3.2 根据作文描述生成场景插图
结合NLP技术提取学生作文中的关键意象,自动生成插图辅助阅读理解。
# 示例:从作文中提取视觉元素
essay = "那天傍晚,我站在海边,夕阳把天空染成橘红色,海浪轻轻拍打着沙滩,一只海鸥飞过我的头顶。"
keywords = extract_keywords(essay) # 输出:["sunset", "beach", "ocean waves", "seagull"]
prompt = f"{', '.join(keywords)}, realistic painting style, warm tones, peaceful atmosphere"
整合路径 :
- 使用BERT-based关键词抽取模型识别实体;
- 映射至标准美术术语(如“橘红色”→“warm orange glow”);
- 调用Stable Diffusion生成插图并反馈给学生,形成“写作—可视化”闭环。
4.3.3 历史事件的跨时空视觉重构
对于抽象历史叙述,如“商鞅变法时期的秦国朝堂辩论”,可通过组合式提示生成符合时代特征的画面。
| 元素类别 | 描述词 |
|---|---|
| 场景 | Qin dynasty court hall, wooden architecture, incense burner |
| 人物 | Official in black robes, wearing guan hat, serious expression |
| 动作 | Debating, pointing at bamboo scrolls |
| 风格 | Chinese ink painting with muted colors |
final_prompt = (
"Qin dynasty court debate scene, officials in traditional black robes and guan hats, "
"discussing reforms around a low table with bamboo scrolls, "
"ink painting style, muted earth tones, subtle brush strokes"
)
优势 :
- 弥补教材插图稀缺问题;
- 支持多视角再现同一事件(如农民视角 vs 官员视角);
- 可结合AR技术实现沉浸式教学体验。
4.4 API集成与平台对接方案
为了实现规模化应用,需将Stable Diffusion能力封装为服务,接入主流学习管理系统(LMS)。
4.4.1 RESTful接口的封装与调用方式
基于FastAPI封装生成服务:
from fastapi import FastAPI
from pydantic import BaseModel
import uvicorn
app = FastAPI()
class GenerateRequest(BaseModel):
prompt: str
negative_prompt: str = ""
width: int = 512
height: int = 512
steps: int = 20
@app.post("/generate")
async def generate_image(req: GenerateRequest):
# 调用本地WebUI API 或 直接调用Diffusers管道
result = call_sd_backend(req.dict())
return {"image_base64": result, "status": "success"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
功能说明 :
- 接收JSON请求,返回Base64图像;
- 可加入身份认证(JWT)、速率限制(Redis)等企业级特性;
- 支持异步队列处理大批量请求。
4.4.2 与LMS(学习管理系统)的整合路径
以Moodle为例,可通过插件形式集成图像生成器:
| Moodle模块 | 对接方式 | 用户体验 |
|---|---|---|
| 作业提交 | 学生上传作文 → 自动生成配图 | 提升参与感 |
| 课程资源 | 教师输入关键词 → 插入AI生成图 | 丰富课件 |
| 测验题干 | 自动生成情境插图(如物理受力图) | 增强理解 |
技术栈 :
- 使用OAuth2完成身份同步;
- WebSocket推送生成进度;
- 图像自动压缩并存储于Moodle文件系统。
4.4.3 批量任务调度与结果缓存机制
为应对高峰请求,设计基于Celery的任务队列:
from celery import Celery
celery_app = Celery('sd_tasks', broker='redis://localhost:6379/0')
@celery_app.task
def async_generate_image(prompt, task_id):
image = pipeline(prompt)
save_to_cache(task_id, image)
notify_user_via_webhook(task_id, status="completed")
缓存策略 :
- 使用Redis缓存近似提示词的结果(基于余弦相似度);
- 设置TTL为7天,定期清理冷数据;
- 缓存命中率可达40%以上,显著降低GPU负载。
综上所述,Stable Diffusion在教育辅导中的实践部署不仅可行,而且可通过模块化架构实现高度定制化与可持续运维。未来,随着边缘计算设备的发展,甚至可在普通教室终端实现轻量化推理,真正让AI赋能每一节课堂。
5. Stable Diffusion教育应用的实际案例研究
随着生成式人工智能技术的持续演进,Stable Diffusion 已从实验室走向真实教育场景,其在提升教学资源生成效率、支持个性化学习路径以及辅助特殊群体认知发展等方面展现出显著价值。多个一线教育机构与科技企业联合开展试点项目,将 Stable Diffusion 技术深度融入课程设计、教学实施和学生互动环节。这些实践不仅验证了该模型的技术可行性,更揭示了其在复杂教育生态中的适应性与可扩展性。以下通过三个典型应用场景——初中物理可视化教学、自闭症儿童情感认知训练、远程教育内容自动化生产——系统剖析其技术实现路径、用户反馈机制及长期运行效果。
5.1 初中物理课堂中的动态示意图生成系统
5.1.1 教学痛点与技术介入背景
传统物理教学中,受力分析、运动轨迹推导等抽象概念依赖静态手绘图或预设PPT插图,难以根据学生理解程度灵活调整视角与细节层次。某省级重点中学调研显示,超过68%的学生表示“无法准确想象斜面滑块系统的力矩分布”,而教师受限于备课时间,难以逐班定制高保真图像资源。为此,该校引入基于 Stable Diffusion 的“物理图示即时生成系统”(Physics Diagram Instant Generation System, PDIGS),允许教师在授课过程中输入自然语言提示词,实时生成符合教学需求的二维/三维风格化示意图。
为确保生成图像的科学准确性,系统采用微调后的 sd-phys-v1 模型,该模型基于原始 Stable Diffusion 1.5 架构,在包含 12,000 张标注清晰的物理教材插图、仿真截图和矢量图的数据集上进行 LoRA 微调。训练数据涵盖力学、电学、光学三大模块,每张图像均附带结构化标签(如“force_vector”、“inclined_plane”、“friction_direction”)以增强语义对齐能力。
| 参数项 | 配置说明 |
|---|---|
| 基础模型版本 | Stable Diffusion 1.5 |
| 微调方法 | LoRA(Low-Rank Adaptation) |
| 秩参数 r | 32 |
| 学习率 | 1e-4(AdamW优化器) |
| 训练轮数 | 8 epochs |
| 批次大小 | 4(使用梯度累积模拟 batch=16) |
| 文本编码器 | OpenCLIP-ViT/Huge |
该配置在 NVIDIA A100 40GB GPU 上完成训练,耗时约 9 小时,最终模型体积仅增加 18MB,便于部署至校内边缘服务器。
5.1.2 提示工程设计与条件控制策略
系统核心在于构建标准化提示模板库,使非专业用户也能精准控制输出内容。例如,针对“光滑斜面上滑动的小车受力分析图”的生成请求,系统自动补全如下完整 prompt:
prompt = (
"A clear line drawing of a small cart sliding down a smooth inclined plane, "
"with labeled force vectors: gravity (mg) pointing downward, normal force (N) "
"perpendicular to the surface, and no friction force. "
"Include angle θ marked between the incline and horizontal ground. "
"Top-down perspective, black and white sketch style, high contrast, no shading."
)
同时设置负面提示(negative_prompt)以排除干扰元素:
negative_prompt = (
"colorful, cartoonish, human figures, text labels other than physics symbols, "
"perspective distortion, blurry lines, background scenery, artistic effects"
)
上述提示设计遵循“五要素原则”:对象明确、力系完整、视角固定、风格统一、禁用项清晰。实验表明,加入角度标记和矢量方向描述后,生成图像中关键物理量的正确呈现率由 72% 提升至 94%。
代码逻辑解析:提示词自动增强模块
def enhance_physics_prompt(base_description):
"""
根据基础描述自动补充物理图示所需的标准元素
参数:
base_description (str): 用户输入的简要描述,如"斜面上的小车"
返回:
tuple: (enhanced_prompt, negative_prompt)
"""
# 映射关键词到标准术语
keyword_map = {
"小车": "small cart",
"斜面": "inclined plane",
"光滑": "smooth, no friction",
"受力": "labeled force vectors"
}
enhanced = "A clear line drawing of "
for key, value in keyword_map.items():
if key in base_description:
enhanced += value + ", "
# 添加通用规范要求
enhanced += (
"top-down perspective, black and white sketch style, "
"high contrast, technical illustration quality"
)
negative = (
"colorful, cartoon, human, photo, real-life, blurry, "
"perspective view, complex background, artistic rendering"
)
return enhanced, negative
逐行解读与参数说明:
- 第 4–8 行定义术语映射表,将中文口语表达转换为英文专业词汇,确保文本编码器能准确识别语义。
- 第 10 行初始化输出字符串,以“A clear line drawing of”开头,引导模型生成线稿而非渲染图。
- 第 12–15 行遍历关键词,动态拼接核心元素,实现语义扩展。
- 第 18–21 行添加视觉风格约束,强调“top-down perspective”可避免透视变形,“black and white sketch”限制色彩干扰。
- 第 23–25 行设定负面提示,排除常见偏差来源,如卡通风格、人物出现、模糊线条等。
- 函数返回元组形式便于后续直接传入扩散模型推理接口。
此模块集成于 WebUI 后端,教师只需输入简单短语即可获得高质量提示词,极大降低使用门槛。
5.1.3 实施效果评估与师生反馈分析
项目运行一个学期后,收集了来自 3 个年级共 427 名学生和 15 位物理教师的反馈数据。系统日均调用量达 63 次,平均响应时间为 4.2 秒(A10 GPU 环境)。评估指标包括图像可用率、概念理解提升度、课堂参与度变化等。
| 指标名称 | 实验前均值 | 实验后均值 | 变化幅度 |
|---|---|---|---|
| 图像可用率(无需修改即可使用) | 41% | 89% | +48% |
| 单元测试平均分 | 72.3 | 81.6 | +9.3 分 |
| 主动提问次数/节课 | 2.1 | 5.7 | +171% |
| 教师备课时间减少比例 | —— | —— | 63% |
数据显示,图像生成系统的引入显著提升了教学效率与学习成效。尤其值得注意的是,在“牛顿第二定律应用”单元中,实验班的错误率比对照班低 29%,主要体现在力分解方向判断和正交投影计算方面。
访谈结果显示,教师普遍认为“即时可视化”增强了讲解的直观性:“以前要花三分钟画图,现在一句话就出图,还能随时切换不同倾角进行对比演示。” 学生则反馈:“看到力箭头真的指向斜面垂直方向时,突然就懂了为什么支持力不是竖直向上的。”
5.2 特殊教育中情绪认知的视觉干预系统
5.2.1 自闭症儿童情感识别障碍的技术应对
自闭症谱系障碍(ASD)儿童普遍存在面部表情识别困难,影响其社会交往能力发展。传统干预手段依赖卡片教学,存在素材单一、情境缺失等问题。某特殊教育学校联合 AI 团队开发“EmoVision”系统,利用 Stable Diffusion 将抽象情绪词汇转化为多样化、可控强度的面部表情图像,构建沉浸式情感认知训练环境。
系统采用 Stable Diffusion 2.1 为基础模型,结合 FER(Facial Expression Recognition)数据集进行定向微调。特别地,引入“情绪强度滑块”机制,允许治疗师调节生成表情的显著程度(如“轻微难过” vs “极度悲伤”),逐步提升识别难度。
5.2.2 多模态输入与安全过滤机制
为适配低龄儿童操作习惯,系统支持语音+文字双通道输入。家长或教师可通过语音说出“生气的脸”,系统经 ASR 转录后触发图像生成流程。同时内置三级内容过滤器,防止生成极端或不适切表情:
import torch
from transformers import pipeline
# 初始化NSFW检测器
nsfw_detector = pipeline("image-classification", model="Falconsai/nsfw_image_detection")
def safe_generate_emotion_image(prompt, intensity=0.7):
"""
安全生成情绪图像,含NSFW检测与表情合理性验证
参数:
prompt (str): 情绪描述,如"angry face"
intensity (float): 表情强度 [0.1~1.0]
返回:
PIL.Image 或 None(若检测异常)
"""
# 强度映射到提示词
intensity_desc = {
(0.1, 0.3): "slight",
(0.3, 0.6): "moderate",
(0.6, 1.0): "strong"
}
desc_range = next(v for k, v in intensity_desc.items() if k[0] < intensity <= k[1])
full_prompt = f"{desc_range} {prompt}, front view, neutral background"
# 调用Stable Diffusion生成图像
image = sd_pipeline(full_prompt).images[0]
# NSFW检测
result = nsfw_detector(image)
if any(r['score'] > 0.8 for r in result if r['label'] == 'NSFW'):
return None # 拒绝生成
return image
逻辑分析与扩展说明:
- 第 9–10 行加载 HuggingFace 提供的轻量级 NSFW 分类模型,专用于检测露骨内容。
- 第 21–24 行实现强度分级机制,将连续数值离散化为语言描述,提升提示一致性。
- 第 27 行调用已封装的 diffusion pipeline(如 diffusers 库),生成单张图像。
- 第 29–31 行执行安全检查,若 NSFW 置信度超过阈值 0.8,则拒绝输出,保障儿童心理健康。
- 函数返回
None时前端显示友好提示,避免造成困惑。
该机制有效防止了因提示词歧义导致的异常输出,例如当误输入“恐怖的脸”时,系统倾向于生成夸张惊恐表情而非暴力场景。
| 情绪类型 | 示例提示词 | 生成成功率 | 安全拦截率 |
|---|---|---|---|
| 快乐 | happy face, smiling | 96% | 0.2% |
| 悲伤 | sad face, teary eyes | 93% | 0.5% |
| 生气 | angry face, furrowed brows | 89% | 1.1% |
| 害怕 | scared face, wide eyes | 85% | 2.3% |
| 惊讶 | surprised face, raised eyebrows | 91% | 0.7% |
数据显示,“害怕”类表情因易接近恐怖范畴,被拦截概率最高,需进一步优化提示边界。
5.2.3 干预效果追踪与行为改善证据
经过为期 12 周的干预训练(每周 3 次,每次 20 分钟),对 18 名 6–10 岁 ASD 儿童进行前后测评估。使用《Ekman Faces Test》测量基本情绪识别准确率,结果显示平均识别正确率从 54.3% 提升至 78.9%,其中“愤怒”与“快乐”的进步最为明显。
此外,观察记录显示,参与者在自由游戏中模仿生成表情的比例增加,社交回应延迟时间缩短。一位治疗师指出:“有个孩子以前完全不懂什么是‘假装生气’,现在他能自己说‘老师是开玩笑的,眉毛没真的皱起来’。”
5.3 远程教育平台的内容自动化生产实践
5.3.1 商业在线教育平台的降本增效需求
某 K12 在线教育平台每年需制作超 50,000 张课程插图,外包成本高达 120 万元。由于内容更新频繁,传统美工团队响应周期长达 3–5 天,严重制约课程上线速度。为此,平台构建“AutoIllustrate”系统,基于 Stable Diffusion 实现从脚本到图像的端到端生成流水线。
系统架构分为四层:
1. 脚本解析层 :提取课文中的关键事件节点;
2. 提示生成层 :将事件转化为 SD 可读 prompt;
3. 批量生成层 :调度多 GPU 节点并发处理;
4. 审核缓存层 :人工抽查 + 自动去重 + CDN 缓存。
5.3.2 批量生成与 API 集成方案
系统通过 RESTful API 对接内部 CMS,关键接口定义如下:
POST /api/v1/generate_illustration
Content-Type: application/json
{
"lesson_id": "L2024-MATH-037",
"scene_description": "A child measuring the height of a tree using a protractor and tape measure",
"style": "flat_design",
"resolution": "1024x768",
"callback_url": "https://cms.edu/callback"
}
后端服务使用 FastAPI 搭建,集成 Diffusers 库并启用 DDIMScheduler 加速推理:
from diffusers import StableDiffusionPipeline, DDIMScheduler
import asyncio
# 全局加载模型(共享GPU内存)
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
revision="fp16"
).to("cuda")
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
async def generate_image_async(prompt, output_path):
"""异步生成图像以支持高并发"""
image = await loop.run_in_executor(
executor,
pipe,
prompt,
50, # 步数
7.5, # guidance scale
torch.Generator().manual_seed(42) # 可复现性
)
image.images[0].save(output_path)
参数说明与性能优化点:
- 使用
fp16精度减少显存占用,A10G 卡可承载 4 个并发任务; DDIMScheduler支持少步数采样(50 步内收敛),较原始 DDPM 提速 3 倍;guidance_scale=7.5平衡创意性与提示忠实度;- 固定随机种子保证相同输入生成一致结果,利于版本管理;
- 异步协程配合线程池避免阻塞主线程,支撑每分钟百级请求。
5.3.3 成本效益与质量监控体系
上线六个月后统计,系统累计生成图像 41,283 张,人工干预率 12.3%,主要用于修正比例失调或符号错误。平均每张图成本降至 0.8 元(原 23 元),总体节省成本 61.7%。
建立三级质量评分机制:
| 等级 | 标准 | 占比 |
|---|---|---|
| S级(直接使用) | 语义准确、构图合理、无 artifacts | 68% |
| A级(微调可用) | 局部瑕疵(如手指数量异常)但主体正确 | 19% |
| B级(需重制) | 主题偏离或严重失真 | 13% |
平台同步构建“错误模式数据库”,记录常见失败案例(如“三角函数图像误生成为波浪海滩”),反哺提示工程优化。
综上所述,Stable Diffusion 在真实教育场景中的落地已超越概念验证阶段,展现出强大的实用价值。无论是常规学科教学、特殊教育干预还是大规模内容生产,其灵活性与可编程性均使其成为现代教育基础设施的重要组成部分。关键技术成功要素包括:领域微调提升准确性、提示工程标准化降低使用门槛、安全机制保障伦理合规、系统集成实现高效闭环。未来随着模型小型化与知识增强技术的发展,这类应用有望进一步普及至更多学校与家庭环境。
6. 挑战反思与未来发展方向
6.1 模型输出准确性与教育可信度的矛盾
Stable Diffusion 在生成视觉内容时,虽然具备强大的语义理解能力,但其本质仍是基于概率分布的生成模型,无法保证科学事实或教学逻辑的绝对准确。例如,在物理教学中生成“电路图”时,模型可能错误连接电阻与电源极性;在生物课中绘制“有丝分裂各阶段图像”时,染色体排列方式可能出现不符合生物学规律的情况。
此类问题暴露了生成式AI与教育领域对 确定性知识表达 之间的根本冲突。为缓解这一矛盾,可采取以下技术手段进行干预:
- 后处理校验机制 :结合规则引擎或轻量级分类器对生成图像进行二次判断。例如使用预训练的CNN模型识别细胞分裂阶段是否符合标准形态。
- 知识嵌入式提示(Knowledge-Augmented Prompting) :在输入提示词中显式引入权威教材中的定义描述,提升生成一致性。
# 示例:增强型提示构造函数
def build_education_prompt(subject, topic, grade_level):
knowledge_base = {
"biology": {
"mitosis": "细胞有丝分裂分为间期、前期、中期、后期和末期。中期时染色体整齐排列在赤道板上。"
},
"physics": {
"circuit": "串联电路中电流处处相等,电压按电阻比例分配。"
}
}
base_prompt = f"{topic} 教学示意图,{grade_level}年级水平"
context = knowledge_base.get(subject, {}).get(topic, "")
full_prompt = f"{base_prompt}。必须严格遵循以下科学描述:{context}"
return full_prompt
# 调用示例
prompt = build_education_prompt("biology", "mitosis", "初中")
print(prompt)
执行逻辑说明:该函数通过外部知识库注入精确学科定义,强制模型在生成过程中参考真实知识点,从而降低幻觉风险。
参数说明:
- subject :学科类别(如 biology, physics)
- topic :具体主题关键词
- grade_level :教学阶段,用于控制可视化复杂度
6.2 版权合规与数据隐私保护机制设计
当前主流 Stable Diffusion 模型训练依赖于大规模互联网图像数据集(如 LAION),其中包含大量未授权作品,存在潜在版权争议。此外,若将学生作文、教师教案作为提示输入云端API,可能引发敏感信息泄露。
为此,教育场景应建立如下防护体系:
| 风险类型 | 技术对策 | 实施层级 |
|---|---|---|
| 训练数据侵权 | 使用教育专用许可数据集微调 | 模型层 |
| 生成内容侵权 | 添加数字水印并记录生成元数据 | 输出层 |
| 输入隐私泄露 | 本地化部署 + 数据脱敏处理 | 系统层 |
| 第三方调用滥用 | API访问令牌+审计日志 | 接口层 |
操作步骤建议:
1. 所有文本输入在发送至模型前执行去标识化处理(如替换姓名为人称代词)
2. 部署本地 OCR 服务识别上传图片中的文字并自动模糊
3. 启用 WebUI 的 --no-store 参数防止历史记录留存
4. 对每次生成结果附加 JSON 元数据标签,包括时间戳、操作者ID、内容类别等
# 示例:生成结果元数据结构
generation_metadata:
timestamp: "2025-04-05T10:32:15Z"
user_id: "teacher_physics_08"
prompt_hash: "a1b2c3d4e5f6..."
model_version: "sd-educational-v2.1-lora"
filters_applied:
- nsfw_filter: passed
- copyright_check: clean
- fact_consistency_score: 0.87
该元数据可用于后续追溯审查,也支持构建内部教育资源版权管理系统。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)