一文掌握RRF:提升大模型RAG检索质量的简单方法
文章详细介绍了检索增强生成(RAG)系统中的倒数排序融合(RRF)技术。RRF是一种简单而强大的算法,通过融合多个检索结果的排名信息,无需复杂的分数归一化即可提升检索质量。文章解释了RRF的工作原理、核心公式及应用场景,包括混合检索、多查询检索和多模态检索,并提供了Python实现代码和最佳实践建议,帮助开发者构建更高质量的RAG系统。
文章详细介绍了检索增强生成(RAG)系统中的倒数排序融合(RRF)技术。RRF是一种简单而强大的算法,通过融合多个检索结果的排名信息,无需复杂的分数归一化即可提升检索质量。文章解释了RRF的工作原理、核心公式及应用场景,包括混合检索、多查询检索和多模态检索,并提供了Python实现代码和最佳实践建议,帮助开发者构建更高质量的RAG系统。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
引言
在检索增强生成(RAG)系统中,检索质量直接决定了最终生成结果的准确性和相关性。然而,单一的检索方式往往难以全面捕获用户意图。当我们使用多个检索系统(如BM25关键词搜索和向量语义搜索)时,如何有效融合这些不同来源的结果就成为了关键问题。
倒数排序融合(Reciprocal Rank Fusion, RRF)正是为解决这一问题而生的优雅方案。它无需复杂的参数调优,仅依靠排名位置就能智能地合并多个检索结果,让最相关的文档脱颖而出。
什么是RRF?
倒数排序融合(RRF)是一种将多个排序结果列表合并为单一排序列表的算法。它最初由滑铁卢大学和Google合作开发,其核心思想非常直观:在多个检索系统中都排名靠前的文档,往往更具相关性/更重要。
RRF的最大优势在于:
- 无需分数归一化 - 不同检索系统的评分标准差异巨大(如BM25分数和余弦相似度),RRF直接使用排名位置,避免了复杂的分数标准化问题
- 简单而强大 - 算法实现简单,但在实践中表现出色
- 零样本有效 - 不需要针对特定领域进行训练或调优
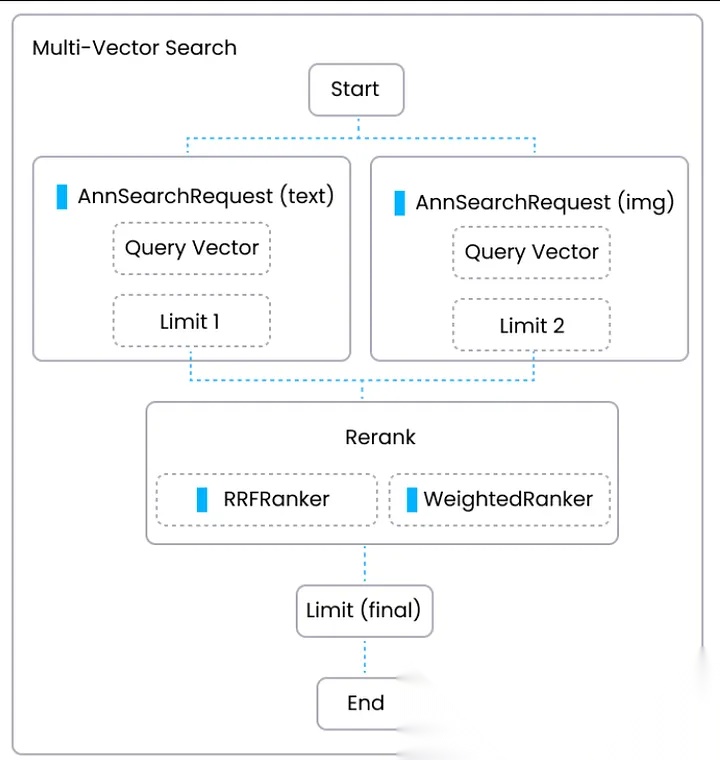
RRF的工作原理
核心公式
RRF通过以下公式计算每个文档的最终得分:
RRF_score(d) = ∑ 1 / (k + rank(d))
其中:
d表示某个文档rank(d)是文档在某个检索结果列表中的排名位置(从1开始)k是一个常量,通常设为60,用于降低低排名文档的影响- 求和符号表示对所有包含该文档的结果列表进行累加
为什么选择k=60?
常量k的作用是平滑排名差异。k=60是经过学术研究验证的经验值,它能在以下两点之间取得良好平衡:
- 让高排名文档有明显优势
- 避免低排名文档的贡献完全被忽略
直观理解
让我们通过一个例子来理解RRF的工作机制。
假设有三个检索系统返回了以下结果:
- 系统A: Doc1, Doc2, Doc3, Doc4, Doc5
- 系统B: Doc3, Doc1, Doc4, Doc6, Doc2
- 系统C: Doc2, Doc3, Doc1, Doc8, Doc9
计算Doc1的RRF分数(k=60):
RRF(Doc1) = 1/(60+1) + 1/(60+2) + 1/(60+3) = 1/61 + 1/62 + 1/63 ≈ 0.0164 + 0.0161 + 0.0159 ≈ 0.0484
计算Doc3的RRF分数:
RRF(Doc3) = 1/(60+3) + 1/(60+1) + 1/(60+2) = 1/63 + 1/61 + 1/62 ≈ 0.0159 + 0.0164 + 0.0161 ≈ 0.0484
可以看到,Doc1和Doc3在三个系统中都排名靠前,因此获得了相似的高分。而只在单个系统中出现的文档(如Doc6, Doc7)则会得到较低的分数。
RRF在RAG中的应用场景
1. 混合检索融合
这是RRF最典型的应用场景。结合词法搜索和语义搜索的优势:
- BM25关键词搜索 - 擅长精确匹配专有名词、缩写词、特定术语
- 向量语义搜索 - 擅长理解语义相关性、同义词、上下文含义
通过RRF融合,既能捕获精确匹配,又不失语义理解。
2. 多查询检索融合
当用户查询较为复杂或模糊时,可以通过LLM生成多个子查询,分别检索后用RRF合并结果。
例如,用户问:“任务分解的挑战是什么?”
可以生成子查询:
- “任务分解面临的主要困难”
- “任务分解的局限性”
- “任务分解实施中的问题”
每个子查询独立检索,然后用RRF融合,确保检索的全面性。
3. 多模态检索融合
在处理多模态数据时,可能需要融合:
- 文本检索结果
- 图像检索结果
- 表格检索结果
RRF同样能够有效整合这些异构的排序列表。
代码实现
Python基础实现
from collections import defaultdictdef reciprocal_rank_fusion(search_results_dict, k=60): """ 使用RRF算法融合多个检索结果 参数: search_results_dict: 字典,键为查询标识,值为文档ID列表(按相关性排序) k: RRF常量,默认60 返回: 融合后的文档列表,按RRF分数降序排列 """ # 存储每个文档的RRF分数 fused_scores = defaultdict(float) # 遍历每个检索结果列表 for query_id, doc_list in search_results_dict.items(): # 遍历文档及其排名 for rank, doc_id in enumerate(doc_list, start=1): # 累加RRF分数 fused_scores[doc_id] += 1 / (k + rank) # 按分数降序排序 sorted_docs = sorted( fused_scores.items(), key=lambda x: x[1], reverse=True ) # 返回文档ID列表 return [doc_id for doc_id, score in sorted_docs]# 使用示例search_results = { 'query_1': ['doc1', 'doc3', 'doc5', 'doc7'], 'query_2': ['doc2', 'doc1', 'doc4'], 'query_3': ['doc5', 'doc3', 'doc2']}fused_results = reciprocal_rank_fusion(search_results)print("融合后的文档排序:", fused_results)
带有完整文档信息的实现
在实际RAG应用中,我们通常需要保留文档的完整信息:
def reciprocal_rank_fusion_with_docs(ranked_results_list, k=60): """ 融合多个检索结果,保留文档完整信息 参数: ranked_results_list: 列表的列表,每个子列表包含文档对象 k: RRF常量 返回: 融合后的文档列表 """ score_dict = {} # 对每个检索结果列表 for doc_list in ranked_results_list: for rank, doc in enumerate(doc_list): # 使用文档内容和元数据作为唯一标识 doc_key = ( doc.metadata.get("source", ""), doc.page_content.strip() ) # 初始化或更新分数 if doc_key notin score_dict: score_dict[doc_key] = { "doc": doc, "score": 0 } # 累加RRF分数 score_dict[doc_key]["score"] += 1 / (k + rank) # 按分数排序 fused_docs = sorted( score_dict.values(), key=lambda x: x["score"], reverse=True ) return [entry["doc"] for entry in fused_docs]
RAG-Fusion:RRF的进阶应用
RAG-Fusion是一个将RRF应用于RAG的完整工作流: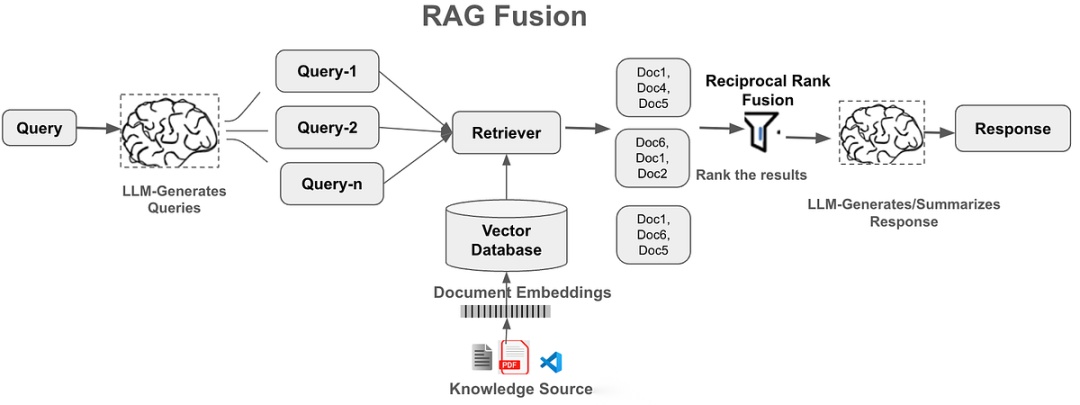
工作流程
- 查询扩展 - 使用LLM将用户原始查询转换为多个相似但角度不同的查询
- 并行检索 - 对所有查询(包括原始查询)并行执行检索
- RRF融合 - 使用RRF算法合并所有检索结果
- 上下文生成 - 将融合后的top-k文档作为上下文传递给LLM生成最终答案
核心逻辑实现
下面是一个伪代码,大家可以参考下RAG中RRF的使用
def rag_fusion_pipeline(original_query, retriever, llm, k=60, top_k=5): """ RAG-Fusion完整流程 """ # 1. 生成多个查询变体 query_variants = generate_query_variants(original_query, llm) all_queries = [original_query] + query_variants # 2. 并行检索 all_results = [] for query in all_queries: results = retriever.retrieve(query) all_results.append(results) # 3. RRF融合 fused_docs = reciprocal_rank_fusion_with_docs(all_results, k=k) # 4. 选择top-k文档 context_docs = fused_docs[:top_k] # 5. 生成最终答案 answer = llm.generate( query=original_query, context=context_docs ) return answerdef generate_query_variants(query, llm, num_variants=3): """ 使用LLM生成查询变体 """ prompt = f"""你是一个帮助生成搜索查询的AI助手。 基于用户的原始问题,生成{num_variants}个相关但角度不同的搜索查询。 这些查询应该帮助从不同角度理解用户意图。 原始问题: {query} 请直接输出{num_variants}个查询,每行一个:""" response = llm.generate(prompt) variants = [line.strip() for line in response.split('\n') if line.strip()] return variants[:num_variants]
RRF的优势与局限
优势
- 简单高效 - 算法实现简单,计算开销小,易于理解和维护
- 无需调参 - k值使用默认的60即可在大多数场景下表现良好,省去了繁琐的参数调优
- 跨系统兼容 - 不依赖具体的评分机制,可以轻松整合任意检索系统
- 提升检索质量 - 学术研究和实践都证明,RRF的表现优于单一检索方法和简单的分数加权
- 增强鲁棒性 - 通过多系统共识,降低单一系统错误的影响
局限性
不过RRF存在几个缺点是:
- 忽略相关性分数 - RRF只使用排名信息,丢弃了原始相关性分数,在某些场景下可能损失信息
- 需要多次检索 - 必须执行多次检索操作,会增加延迟和计算成本
- 文档去重挑战 - 需要准确识别不同结果列表中的相同文档,文档表示不一致时可能出问题
- 对检索质量的依赖 - 如果所有检索系统都返回不相关的结果,RRF也无法改善结果质量
大家实践的过程,可以采用以下的方法来使用RFF:
- 选择互补的检索方法 - 组合特点不同的检索系统(如词法+语义)能获得最佳效果
- 控制检索数量 - 每个查询检索top-20到top-50的文档通常足够,过多会增加噪音
- 注意文档标识 - 确保能准确识别和去重相同文档,可以使用内容哈希或稳定的ID
- 保留原始查询权重 - 在RAG-Fusion场景中,可以让原始查询的结果参与多次RRF计算,增加其权重
- 监控成本 - 多次检索和LLM调用会增加成本,需要在效果和成本间找到平衡
总结
倒数排序融合(RRF)为RAG系统提供了一个简单而强大的结果融合方案。它通过巧妙利用排名信息,避免了分数归一化的复杂性,同时能够有效提升检索质量。
无论是混合检索、多查询检索,还是更复杂的RAG-Fusion流程,RRF都能发挥重要作用。随着Elasticsearch 8.8等主流搜索引擎原生支持RRF,这一技术正在成为构建高质量RAG系统的标准组件。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)