TRAP: Targeted Redirecting of Agentic Preferences
由视觉-语言模型(VLMs)驱动的自主代理AI系统正迅速向实际部署迈进,然而其跨模态推理能力引入了新的对抗性操作攻击面,这些攻击利用跨模态的语义推理。现有的对抗攻击通常依赖于可见像素扰动或需要对模型或环境的特权访问,这使得它们在隐秘、现实世界的利用中不切实际。我们提出了TRAP,一种生成性的对抗框架,通过基于扩散的语义注入操纵代理的决策制定。我们的方法结合了基于负面提示的降级与正面语义优化,由双胞
康航宇 ⋆1{ }^{\star 1}⋆1, 梁哲赫 ∗1{ }^{* 1}∗1, Gagandeep Singh 1{ }^{1}1
1{ }^{1}1 伊利诺伊大学厄巴纳-香槟分校
{hangook2, jehyeok2, ggnds}@illinois.edu
摘要
由视觉-语言模型(VLMs)驱动的自主代理AI系统正迅速向实际部署迈进,然而其跨模态推理能力引入了新的对抗性操作攻击面,这些攻击利用跨模态的语义推理。现有的对抗攻击通常依赖于可见像素扰动或需要对模型或环境的特权访问,这使得它们在隐秘、现实世界的利用中不切实际。我们提出了TRAP,一种生成性的对抗框架,通过基于扩散的语义注入操纵代理的决策制定。我们的方法结合了基于负面提示的降级与正面语义优化,由双胞胎语义网络和布局感知的空间掩码引导。无需访问模型内部,TRAP生成视觉自然的图像,却能在代理AI系统中引起一致的选择偏差。我们在Microsoft COCO数据集上评估了TRAP,构建多候选决策场景。在这些场景中,TRAP在包括LLaVA-34B、Gemma3和Mistral-3.1在内的领先模型上实现了100%的攻击成功率,显著优于SPSA、Bandit和标准扩散方法等基线。这些结果揭示了一个关键漏洞:自主代理可以通过人类无法察觉的跨模态操控被持续误导。这些发现强调了超越像素级鲁棒性防御策略的需求,以解决跨模态决策中的语义漏洞。
1 引言
视觉-语言模型(VLMs)和自主代理AI系统显著提升了机器导航和解释开放世界环境的能力(Radford等人,2021;Li等人,2022a;Alayrac等人,2022)。然而,这些强大的多模态系统也引入了新的漏洞,特别是通过利用其集成的视觉文本感知的对抗性操控(Zhou等人,2023;Moosavi-Dezfooli等人,2016b)。一个关键的新兴威胁是跨模态提示注入,其中对手在一种模态(例如图像)中嵌入误导性语义线索,以影响模型在另一种模态(例如语言理解)中的解释和决策制定(Liu等人,2023c)。与主要不可察觉地扰动像素的传统单模态对抗攻击不同(Goodfellow等人,2015;Uesato等人,2018;Madry等人,2019),这些跨模态攻击利用语义变化,在不触发人类怀疑的情况下误导自主代理。
完全自主的代理,如无需人工监督即可导航网页界面的GUI代理,特别容易受到对抗性操控的影响。最近的研究表明,视觉-语言代理可以通过对抗性环境被越狱,导致意外且可能有害的操作(Liao等人,2025;Zhang等人,2024b)。例如,恶意弹出窗口或UI组件可能会诱使代理点击有害链接或执行未经授权的任务,而无需人工干预(Wu等人,2024)。这突显了一个关键的安全缺陷:此类代理本质上信任其感知输入,因此对微妙的语义扰动高度脆弱(Li等人,2024)。
在本文中,我们介绍了TRAP,一种新型的对抗技术,专门设计用于通过使用扩散模型进行语义注入来利用代理系统的漏洞。我们的方法
*同等贡献
利用Stable Diffusion生成系统(Rombach等人,2022)与CLIP嵌入相结合,创建能够微妙误导代理AI系统决策的真实对抗图像。TRAP分为四个阶段(图1)。首先,我们提取目标图像和

图1:TRAP对抗嵌入优化框架概览。
对抗提示的CLIP嵌入。其次,我们通过双胞胎语义网络迭代优化图像嵌入,该网络由提示对齐的线索(例如,“豪华”,“高端品质”)引导,并通过空间布局掩码调制乘法融合。(Chaitanya等人,2020;Lee等人,2021;Li等人,2022b)第三,我们应用感知和语义损失,包括LPIPS Zhang等人(2018),以在优化过程中保持身份和真实性。第四,修改后的嵌入通过Stable Diffusion解码为最终图像。这一过程产生视觉上可信但语义上被操控以影响下游代理决策的图像。
我们严格评估了TRAP,使用自动化的多模态LLM基础评估器进行N路比较,并与基线进行基准测试,例如:无优化的扩散生成、同时扰动随机逼近(SPSA)Uesato等人(2018)攻击和Bandit(Ilyas等人,2018b)攻击。一个稳健的代理应维持其原始目标并抵制这种偏好操控,因为允许对抗输入从根本上改变决策过程会削弱代理的预期目的和可靠性。我们的实证结果表明,TRAP在将自主代理的偏好转向对抗性操控图像方面显著优于这些基线。这些发现提供了强有力的证据,证明了自主多模态系统中的关键漏洞,引发了关于仅依赖自主感知而不采取充分保护措施的重要安全性和可靠性问题。
最终,本文既是对代理AI系统潜在安全漏洞的关键展示,也是对开发更稳健的多模态对齐、感知保护和自主系统中对抗防御的行动呼吁。
2 相关工作
2.1 对代理系统的对抗攻击
近期自主代理AI系统的发展揭示了对对抗操控的关键漏洞。(Yang等人,2024)和(Wang等人,2024b)展示了后门注入攻击如何微妙地破坏代理行为,误导网络代理在决策时做出错误判断。同样,(Wu等人,2024)和(Liao等人,2025)揭示了精心设计的提示注入如何导致代理采取无意的行为,范围从泄露私人信息到泄露网络内容。然而,这些方法需要广泛访问环境的内部结构
或模型参数,这是在实际设置中很少满足的假设。相比之下,我们的工作针对的是更现实的攻击场景,其中对手只能操纵输入元素(例如图像或提示),而没有任何关于底层环境代码或模型权重的知识。
2.2 基于图像的对抗攻击
基于图像的对抗攻击已被广泛研究,主要集中在神经网络分类器上。突出的攻击方法包括快速梯度符号方法(FGSM)攻击 Goodfellow等人(2015),它通过梯度符号的方向扰动像素;投影梯度下降(PGD)攻击 Madry等人(2019),它使用梯度信息迭代优化对抗扰动;Square Attack(Andriushchenko等人,2020),一种高效的无梯度查询方法;以及同时扰动随机逼近(SPSA)Uesato等人(2018),它通过随机采样估计梯度。
除此之外,还发展了许多针对各种威胁模型和设置的攻击方法。基于优化的白盒攻击包括l1l_{1}l1-APGD(Croce和Hein,2021),它适应投影梯度下降以处理l1l_{1}l1-范数约束并采用自适应步长,以及Carlini & Wagner(C&W)攻击(Carlini和Wagner,2016),它将对抗样本生成形式化为在各种范数下的优化问题。DeepFool(Moosavi-Dezfooli等人,2016a)通过迭代逼近决策边界找到最小扰动。通用对抗扰动(Moosavi-Dezfooli等人,2017)生成对多个输入和模型有效的图像无关扰动。
物理和局部攻击如对抗补丁(Brown等人,2017)创建稳健的通用补丁,在真实世界条件下诱导误分类。Auto-PGD(Croce和Hein,2020)通过自动化PGD中的步长选择以提高收敛性和攻击成功率。
许多黑盒攻击也已出现。Bandits(Ilyas等人,2018b)和NES(Ilyas等人,2018a)分别利用梯度估计和进化策略实现高效的对抗样本生成。Boundary Attack(Brendel等人,2018)是一种基于决策的方法,通过细化大初始扰动以最小化其幅度。其他方法包括单像素攻击(Su等人,2019)(差分演化于单个像素)、ZOO(Chen等人,2017b)(零阶坐标梯度估计)、GenAttack(Alzantot等人,2018)(遗传算法)、Parsimonious Black-Box Attack(Tashiro等人,2019)、NATTA CK(Li等人,2019)和Saliency Attack(Li等人,2022c),这些方法关注查询效率、最小扰动或针对显著区域。
这些方法通常旨在诱导误分类或以尽可能小且不可察觉的方式改变模型输出。我们的工作通过利用文本引导的扩散模型进行语义操控扩展了这些方法学,旨在在更深的语义层面上影响模型决策。
2.3 扩散模型和语义图像操控
基于扩散的生成模型,如Stable Diffusion,已成为高保真图像合成的强大工具,受文本提示指导。这些模型编码文本和图像域之间的丰富语义关系,从而实现对生成图像的精确操控。例如,(Wang等人,2023;Dai等人,2024)微调潜扩散代码以引入目标对象外观的变化,如颜色偏移或纹理编辑,这些变化会误导分类模型,同时对人类保持不可察觉。 (Liu等人,2023b)通过自由文本指令引导反向扩散过程,生成符合自然语言描述的对抗样本,并允许对语义属性进行精细控制。(Zhai等人,2023)表明在训练期间仅毒害一小部分文本-图像对即可在像素、对象或风格级别上后门大型文本到图像扩散模型,嵌入在特定提示下激活的隐藏触发器。与这些方法不同,我们的方法仅使用模型嵌入生成对抗图像,而无需访问扩散模型的参数或训练数据。
3 预备知识
3.1 扩散模型
扩散概率模型(Ho等人,2020;Dhariwal和Nichol,2021)将干净样本 x0∈RDx_{0} \in \mathbb{R}^{D}x0∈RD 腐蚀成潜变量 x1,…,xTx_{1}, \ldots, x_{T}x1,…,xT (其中 D=C×H×WD=C \times H \times WD=C×H×W )通过
xt=1−βtxt−1+βtϵt,ϵt∼N(0,ID),1≤t≤T x_{t}=\sqrt{1-\beta_{t}} x_{t-1}+\sqrt{\beta_{t}} \epsilon_{t}, \quad \epsilon_{t} \sim \mathcal{N}\left(0, I_{D}\right), 1 \leq t \leq T xt=1−βtxt−1+βtϵt,ϵt∼N(0,ID),1≤t≤T
其中标量 βt∈(0,1)\beta_{t} \in(0,1)βt∈(0,1) 表示噪声功率,1−βt\sqrt{1-\beta_{t}}1−βt 减弱来自步骤t−1t-1t−1的前一信号,而ϵt\epsilon_{t}ϵt 是将应用于xt−1x_{t-1}xt−1的高斯噪声。具有参数θ\thetaθ的神经网络学习反向步骤
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)) p_{\theta}\left(x_{t-1} \mid x_{t}\right)=\mathcal{N}\left(x_{t-1} ; \boldsymbol{\mu}_{\theta}\left(x_{t}, t\right), \boldsymbol{\Sigma}_{\theta}\left(x_{t}, t\right)\right) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
预测均值μθ∈RD\boldsymbol{\mu}_{\theta} \in \mathbb{R}^{D}μθ∈RD 和(通常是对角的)协方差Σθ\boldsymbol{\Sigma}_{\theta}Σθ,从而去噪初始化噪声样本以生成高保真、可控的图像。
3.2 CLIP
对比语言-图像预训练(CLIP)(Radford等人,2021)将图像-文本对 (eimage ,etext )∈Rd×Rd\left(e_{\text {image }}, e_{\text {text }}\right) \in \mathbb{R}^{d} \times \mathbb{R}^{d}(eimage ,etext )∈Rd×Rd 嵌入到共享空间中。其对称损失
LCLIP=−12∥logexp(eimage ⊤etext )∑jexp(eimage ⊤etext j)+logexp(eimage ⊤etext )∑iexp(eimage i⊤etext )] \mathcal{L}_{\mathrm{CLIP}}=-\frac{1}{2}\left\|\log \frac{\exp \left(e_{\text {image }}^{\top} e_{\text {text }}\right)}{\sum_{j} \exp \left(e_{\text {image }}^{\top} e_{\text {text }_{j}}\right)}+\log \frac{\exp \left(e_{\text {image }}^{\top} e_{\text {text }}\right)}{\sum_{i} \exp \left(e_{\text {image }_{i}}^{\top} e_{\text {text }}\right)}\right] LCLIP=−21 log∑jexp(eimage ⊤etext j)exp(eimage ⊤etext )+log∑iexp(eimage i⊤etext )exp(eimage ⊤etext )
将余弦缩放的内积 eimage ⊤etext e_{\text {image }}^{\top} e_{\text {text }}eimage ⊤etext 视为相似度得分,拉近匹配对至分子并将非匹配对( eimage ie_{\text {image }_{i}}eimage i 和 etext je_{\text {text }_{j}}etext j 在分母中求和)推远。最小化 LCLIP \mathcal{L}_{\text {CLIP }}LCLIP 因此最大化两个检索方向中正确标题-图像对的相似度。
4 方法
4.1 问题公式化
现代自主代理AI系统越来越多地依赖于整合视觉和语言的多模态模型,以在最少的人类监督下做出决策。这些系统被部署在电子商务、导航代理和预订平台等现实世界应用中,所选图像直接触发下游动作(Davydova等人,2025;Wang等人,2024c),例如点击、后续查询或进一步推理步骤,从而使这一视觉-语言选择层成为影响代理行为的关键目标(Li等人,2025;Zhu等人,2024b)。
正式地,我们考虑由多模态模型 MMM 支持的代理系统,其中代理接收一组 nnn 幅图像 {x}\{x\}{x} 和一条选择最理想图像的指令。代理输出 x′=M({x})x^{\prime}=\mathbf{M}(\{x\})x′=M({x}),反映其内部选择逻辑。
在我们的对抗环境中,攻击者从可能选项集中选择一幅图像,记为 xtarget x_{\text {target }}xtarget 。攻击者还可以访问其余 n−1n-1n−1 幅图像,{xcomp (i)}i=1n−1\left\{x_{\text {comp }}^{(i)}\right\}_{i=1}^{n-1}{xcomp (i)}i=1n−1,但不能修改它们。此外,攻击者对模型参数或环境代码没有任何访问权限。攻击者的目的是将 xtarget x_{\text {target }}xtarget 转换为对抗变体 xadv x_{\text {adv }}xadv ,以便当代理面对修改后的集合时选择 xadv x_{\text {adv }}xadv 作为其输出:
M({xadv}∪{xcomp (i)}i=1n−1)=xadv M\left(\left\{x_{a d v}\right\} \cup\left\{x_{\text {comp }}^{(i)}\right\}_{i=1}^{n-1}\right)=x_{a d v} M({xadv}∪{xcomp (i)}i=1n−1)=xadv
这反映了黑盒设置,攻击者无法访问模型参数或梯度,但可以通过仅修改自己的内容(例如产品图像或GUI元素)来影响代理行为。这种设置对于安全研究和实际部署都高度相关,因为它反映了当代多模态代理系统中暴露的攻击面(Zhu等人,2024a)。
通过对代理系统视觉-语言选择层的系统探测,我们揭示并表征了多模态代理系统中的漏洞,这些漏洞可能被利用来威胁下游决策的可靠性和公平性。
4.2 TRAP框架
为了揭示多模态代理对此威胁模型的易感性,我们提出了TRAP,这是一种黑盒优化框架,仅修改目标图像以诱导AI代理的一致选择。TRAP不同于传统的像素级扰动,而是操作CLIP的潜在空间而非直接修改图像像素。这使我们能够在模型无关的方式下使用与视觉-语言推理对齐的替代表示来引导高级语义。
这一选择是基于现代系统对低级噪声的日益增强的鲁棒性以及现有像素级攻击在黑盒、语义决策设置中的局限性(Yang等人,2022;Li等人,2023;Goodfellow等人,2015;Madry等人,2019)。TRAP将目标图像、一组未修改的竞争图像和描述攻击者希望注入的高级概念的正面文本提示作为输入。然后,它迭代更新图像嵌入 eadve_{a d v}eadv 以最大化其与提示嵌入 etext e_{\text {text }}etext 的对齐。这得到了大多数现代模型的支持,如CLIP、ALIGN、BLIP和Flamingo,这些模型通过在共享嵌入空间中与提示的相似性对图像进行排名,这意味着更高的对齐直接转化为更高的选择可能性。因此,通过增加 eadve_{a d v}eadv 和 etext e_{\text {text }}etext 之间的对齐,我们提高了代理为 xadvx_{a d v}xadv 分配更高相关分数的可能性,从而提高其被选择的机会。尽管代理的具体架构可能未知,但先前的工作表明,由于共享的嵌入几何结构和训练目标,CLIP空间中制作的对抗样本可以转移到其他视觉-语言模型上(Huang等人,2025)。因此,我们认为最大化基于CLIP的提示相似性将增加代理在黑盒设置下选择对抗图像的概率。
优化后的嵌入随后通过预训练的Stable Diffusion模型 SDS DSD 解码为最终图像。以下小节详细说明了TRAP的每个组件及整体优化过程。
4.2.1 在CLIP空间中的引导嵌入优化
为了生成满足4.1所述目标的对抗变体 xadvx_{a d v}xadv,我们优化CLIP图像嵌入 etarget e_{\text {target }}etarget 成为对抗嵌入 eadve_{a d v}eadv,使得解码图像 (1) 视觉上合理,(2) 语义上与正面提示对齐,(3) 保留其独特身份特征。这种转换由以下复合目标函数控制:
L(eadv)=λ1LLPIPS+λ2Lsem +λ3Ldist \mathcal{L}\left(e_{a d v}\right)=\lambda_{1} L_{L P I P S}+\lambda_{2} \mathcal{L}_{\text {sem }}+\lambda_{3} \mathcal{L}_{\text {dist }} L(eadv)=λ1LLPIPS+λ2Lsem +λ3Ldist
其中 λ1,λ2\lambda_{1}, \lambda_{2}λ1,λ2 和 λ3\lambda_{3}λ3 是控制语义对齐与身份保留之间权衡的超参数。
感知相似性损失 (LLPIPS\mathcal{L}_{L P I P S}LLPIPS)。为了确保 xadvx_{a d v}xadv 仍然是一个可信且有竞争力的候选对象,我们限制优化以保留原始图像 xtarget x_{\text {target }}xtarget 的感知外观。剧烈的视觉失真可能会使图像显得不合理或无关紧要,降低其在多模态推理中被选中的可能性。这一点尤为重要,因为现代系统越来越纳入安全机制以检测扭曲或被扰动的图像(Liu等人,2024;Wang等人,2024a)。
我们使用Learned Perceptual Image Patch Similarity(LPIPS)指标以确保 xadvx_{a d v}xadv 在视觉上与 xtarget x_{\text {target }}xtarget 类似。
LLPIPS=LPIPS(xadv,xtarget) \mathcal{L}_{L P I P S}=L P I P S\left(x_{a d v}, x_{t a r g e t}\right) LLPIPS=LPIPS(xadv,xtarget)
语义对齐损失 (Lsem \mathcal{L}_{\text {sem }}Lsem )。为了影响模型选择行为偏向 xadvx_{a d v}xadv,我们利用CLIP的联合图像-文本嵌入空间,其中语义相关的输入被嵌入在附近。通过最小化 eadve_{a d v}eadv 和正面提示嵌入 etext e_{\text {text }}etext 之间的余弦距离,我们将高级语义意义直接注入图像表示中。这使得对抗性编辑可以通过语义引导图像内容来误导多模态代理的决策制定。
Lsem =1−cos(eadv,etext ) \mathcal{L}_{\text {sem }}=1-\cos \left(e_{a d v}, e_{\text {text }}\right) Lsem =1−cos(eadv,etext )
独特特征保留损失 (Ldist \mathcal{L}_{\text {dist }}Ldist )。虽然感知相似性确保了 xadvx_{a d v}xadv 在视觉上与 xtarget x_{\text {target }}xtarget 类似,但它并不能保证图像的独特身份得到保留。LPIPS专注于低级感知线索,只要纹理
算法1 TRAP框架
要求:目标图像 xtarget x_{\text {target }}xtarget ,标题 xtext x_{\text {text }}xtext ,模型 MMM,竞争数量 nnn
确保:优化后的对抗图像 xadvx_{a d v}xadv
1: 初始化 best_score ←0\leftarrow 0←0
2: for m=1m=1m=1 到 MMM do
3: \quad 提取CLIP图像嵌入 etarget e_{\text {target }}etarget 从 xtarget x_{\text {target }}xtarget
4: \quad 提取CLIP文本嵌入 etext e_{\text {text }}etext 从 xtext x_{\text {text }}xtext
5: \quad 使用布局模块 L(etext ,etarget )L\left(e_{\text {text }}, e_{\text {target }}\right)L(etext ,etarget ) 生成布局掩码 AAA
6: 初始化 eadv←etarget e_{a d v} \leftarrow e_{\text {target }}eadv←etarget
7: for t=1t=1t=1 到 TTT do
8: \quad 从孪生网络 Sdist (eadv )S_{\text {dist }}\left(e_{\text {adv }}\right)Sdist (eadv ) 提取分支 ecom ,edist e_{\text {com }}, e_{\text {dist }}ecom ,edist
9: \quad 设置嵌入 emod e_{\text {mod }}emod 为 ecom ⋅mean(A)e_{\text {com }} \cdot \operatorname{mean}(A)ecom ⋅mean(A)
10: 从稳定扩散模型 SD(emod ,etext )S D\left(e_{\text {mod }}, e_{\text {text }}\right)SD(emod ,etext ) 解码候选图像 xcand x_{\text {cand }}xcand
11: 计算总损失:
L(eadv )=λ1LLPIPS(xcand ,xtarget )+λ2Lsem (eadv ,etext )+λ3Ldist (eadv ,etarget )\mathcal{L}\left(e_{\text {adv }}\right)=\lambda_{1} \mathcal{L}_{L P I P S}\left(x_{\text {cand }}, x_{\text {target }}\right)+\lambda_{2} \mathcal{L}_{\text {sem }}\left(e_{\text {adv }}, e_{\text {text }}\right)+\lambda_{3} \mathcal{L}_{\text {dist }}\left(e_{\text {adv }}, e_{\text {target }}\right)L(eadv )=λ1LLPIPS(xcand ,xtarget )+λ2Lsem (eadv ,etext )+λ3Ldist (eadv ,etarget )
12: 使用梯度下降更新 L(eadv )\mathcal{L}\left(e_{\text {adv }}\right)L(eadv ) 上的 eadv e_{\text {adv }}eadv
13: end for
14: \quad 使用 MMM 通过 RRR 次评估估算相对于 {xcomp (i)}i=1n−1\left\{x_{\text {comp }}^{(i)}\right\}_{i=1}^{n-1}{xcomp (i)}i=1n−1 的选择概率 P(xadv)P\left(x_{a d v}\right)P(xadv)
15: if P(xadv)>P\left(x_{a d v}\right)>P(xadv)> best_score then
16: \quad best_score ←P(xadv),xadv←xcand \leftarrow P\left(x_{a d v}\right), x_{a d v} \leftarrow x_{\text {cand }}←P(xadv),xadv←xcand
17: end if
18: if best_score ≥1/n\geq 1 / n≥1/n then
19: break
20: end if
21: end for
22: return xadvx_{a d v}xadv
或颜色在局部上保持一致。这在细粒度任务中尤其成问题,因为在颜色、形状或结构上的细微差异携带重要的身份信息。
为了解决这个问题,我们引入了一种基于孪生语义网络 Sdist S_{\text {dist }}Sdist 的独特特征保留损失。该网络接收一个CLIP图像嵌入,并将其分解为两个分支:一个共同嵌入 ecom e_{\text {com }}ecom ,捕捉与引导提示对齐的特征,以及一个独特嵌入 edist e_{\text {dist }}edist ,隔离与提示正交的特征,如颜色、结构或细粒度细节。这些组件在我们优化的不同部分使用:ecom e_{\text {com }}ecom 使用空间注意力掩码 AAA 调制,并作为输入传递给稳定扩散以引导对语义相关区域的编辑,而 edist e_{\text {dist }}edist 用于计算身份保留损失:
Ldist =∥edist (adv)−edist (target)∥2, 其中 (ecom ,edist )=Sdist (e) \mathcal{L}_{\text {dist }}=\left\|e_{\text {dist }}^{(a d v)}-e_{\text {dist }}^{(t a r g e t)}\right\|^{2}, \quad \text { 其中 }\left(e_{\text {com }}, e_{\text {dist }}\right)=S_{\text {dist }}(e) Ldist = edist (adv)−edist (target) 2, 其中 (ecom ,edist )=Sdist (e)
这一约束确保对抗性编辑保留仅通过语义对齐无法捕获的身份相关特征。如果没有它,优化可能会过度拟合提示内容,将多样化的输入压缩为视觉上不明显的表示(例如,所有"苹果"图像变成通用的红色斑点)。正如之前关于多模态攻击的工作所示(Zhang等人,2024a;Chen等人,2025),针对共享和独特特征可以提高对抗效果和可转移性。我们的损失因此将对抗嵌入锚定在其独特身份上,同时仍允许提示提供语义指导。
4.2.2 语义布局生成
为了确保编辑集中在语义有意义的区域,我们使用布局生成模块 LLL 生成一个空间注意力掩码 A∈RH×WA \in \mathbb{R}^{H \times W}A∈RH×W。该模块接收图像嵌入 etarget e_{\text {target }}etarget 和文本嵌入 etext e_{\text {text }}etext 作为输入。这些嵌入被连接并通过两阶段神经架构传递。首先,实现为多层感知机(MLP)的编码器 Lenc L_{\text {enc }}Lenc 将组合嵌入张量投影和重塑为适合空间解码的潜张量。该潜张量随后通过带有最终Sigmoid激活的解码器 Ldec L_{\text {dec }}Ldec 以生成输出掩码 AAA。正式地,此过程描述如下:
eL=Lenc ([etext ,etarget ]),A=Ldec (eL) e_{L}=L_{\text {enc }}\left(\left[e_{\text {text }}, e_{\text {target }}\right]\right), \quad A=L_{\text {dec }}\left(e_{L}\right) eL=Lenc ([etext ,etarget ]),A=Ldec (eL)
为了提高定位精度,我们使用DeepLabv3分割掩码(Chen等人,2017a)改进 AAA,增强对前景区域的关注。在优化过程中,空间掩码 AAA 用于调制图像嵌入的语义成分。具体来说,我们计算 emod =ecom ×mean(A)e_{\text {mod }}=e_{\text {com }} \times \operatorname{mean}(A)emod =ecom ×mean(A),其中 mean (A)(A)(A) 将注意力掩码聚集为一个标量,以缩放语义特征。此操作确保优化引入的语义编辑集中在掩码确定的相关区域,这些区域由提示和图像内容共同决定。生成的 emod e_{\text {mod }}emod 然后通过稳定扩散解码生成更新后的对抗图像。这种有针对性的调制旨在通过将更改集中在概念上显著的区域来提高攻击的有效性和可解释性(Yu等人,2024)。
总体框架 全部优化总结如下:
eadv∗=argmineadv[λ1LLPIPS(xadv,xtarget )+λ2Lsem(eadv,etext )+λ3Ldist(eadv,etarget )](ecom,edist)=Sdist(eadv∗),A=Ldec(Lenc([etext ,etarget ]))∈RH×Wemod=ecom⋅mean(A),xadv=SD(emod,etext ) \begin{aligned} & e_{\mathrm{adv}}^{*}=\arg \min _{e_{\mathrm{adv}}}\left[\lambda_{1} L_{\mathrm{LPIPS}}\left(x_{\mathrm{adv}}, x_{\text {target }}\right)+\lambda_{2} L_{\mathrm{sem}}\left(e_{\mathrm{adv}}, e_{\text {text }}\right)+\lambda_{3} L_{\mathrm{dist}}\left(e_{\mathrm{adv}}, e_{\text {target }}\right)\right] \\ & \left(e_{\mathrm{com}}, e_{\mathrm{dist}}\right)=S_{\mathrm{dist}}\left(e_{\mathrm{adv}}^{*}\right), A=L_{\mathrm{dec}}\left(L_{\mathrm{enc}}\left(\left[e_{\text {text }}, e_{\text {target }}\right]\right)\right) \in \mathbb{R}^{H \times W} \\ & e_{\mathrm{mod}}=e_{\mathrm{com}} \cdot \operatorname{mean}(A), x_{\mathrm{adv}}=S D\left(e_{\mathrm{mod}}, e_{\text {text }}\right) \end{aligned} eadv∗=argeadvmin[λ1LLPIPS(xadv,xtarget )+λ2Lsem(eadv,etext )+λ3Ldist(eadv,etarget )](ecom,edist)=Sdist(eadv∗),A=Ldec(Lenc([etext ,etarget ]))∈RH×Wemod=ecom⋅mean(A),xadv=SD(emod,etext )
每一步都在语义对齐、视觉连贯性和布局信息嵌入的指导下进行。算法1总结了给定目标、提示和黑盒代理模型生成对抗图像的优化过程:
5 实验方法
5.1 实验协议
我们在COCO Captions数据集(Chen等人,2015)的100个图像-标题对上评估我们的攻击,模拟黑盒nnn-way选择设置。对于每个实例,使用Llama-3-7B(Grattafiori等人,2024)创建的负面提示生成“坏图像”。当与n−1n-1n−1个竞争对手比较时,验证此图像的初始选择概率低于多数阈值,确保优化的起点具有挑战性。
对抗优化最多运行MMM次迭代,每次迭代TTT步,或者直到目标图像的选择概率超过1/n1 / n1/n。为了评估有效性,我们进行R=100R=100R=100次随机nnn-way试验,每次试验随机打乱候选图像的位置以减轻位置偏差(Tian等人,2025)。除非另有说明,所有实验均使用n=4,M=20n=4, M=20n=4,M=20和T=20T=20T=20。此程序与先前的对抗优化基线一致(见第6.1节)。
在每次试验中,对抗图像和n−1n-1n−1个竞争对手图像随机排序并水平拼接形成复合输入Iconcat I_{\text {concat }}Iconcat ,然后传递给代理模型。对抗图像的选择概率计算为:
P(xadv)=1R∑r=1R1[M(Iconcat )=xadv] P\left(x_{a d v}\right)=\frac{1}{R} \sum_{r=1}^{R} \mathbf{1}\left[M\left(I_{\text {concat }}\right)=x_{a d v}\right] P(xadv)=R1r=1∑R1[M(Iconcat )=xadv]
我们测量攻击成功率(ASR)为优化后对抗图像超出多数阈值的实例比例,即P(xadv )>1/nP\left(x_{\text {adv }}\right)>1 / nP(xadv )>1/n。这反映了攻击在随机评估条件下成功转移模型偏好的频率。此实验随后在相同条件下再运行一次,但去掉优化步骤以显示我们框架的有效性。(标记为未优化的在2和3中)
5.2 模型和实现细节
所有实验均在PyTorch中实现。我们使用CLIP ViT-B/32(Radford等人,2021)提取嵌入,通过Img2Img接口使用Stable Diffusion v2.1(基础版)进行对抗图像解码。优化后的图像嵌入重复77个令牌,并作为提示嵌入注入UNet解码器。
孪生语义网络由两个分支组成,每个分支包含两个线性层(512 → 1024)、BatchNorm和ReLU,训练以将CLIP图像嵌入分解为公共和独特特征。布局生成器接收连接的图像和文本嵌入(1536维),
通过编码器(线性层:1536→512→10241536 \rightarrow 512 \rightarrow 10241536→512→1024,ReLU)处理,重塑为(256,2,2)(256,2,2)(256,2,2),然后通过五个带ReLU和最终Sigmoid的转置卷积层上采样生成空间掩码 A∈RH×WA \in \mathbb{R}^{H \times W}A∈RH×W,该掩码通过DeepLabv3分割进一步优化以强调前景。优化通过Adam(学习率0.005,每迭代20步)进行。对扩散强度[0.3,0.8][0.3,0.8][0.3,0.8]和CFG[2.0,12.0][2.0,12.0][2.0,12.0]进行网格搜索,初始值分别为0.5和7.5。
所有实验均在配备四块NVIDIA A100-PCIE-40GB GPU和48核Intel Xeon Silver 4214R CPU的服务器上运行。平均每次迭代优化时间约为200秒,而SPSA约为130秒,Bandit约为3秒。
6 实验结果
6.1 主要发现
TRAP在所有评估的多模态模型中实现了100%\mathbf{1 0 0 \%}100%的攻击成功率(ASR):LLaVA-1.5-34B(Liu等人,2023a)、Gemma3-8B(Mesnard等人,2025)和Mistral-small-3.1-24B(Mistral AI,2025)。表1显示,尽管传统基线如SPSA(Spall,1987)和Bandit(Ilyas等人,2018b)的ASR最高仅为36%,我们的方法普遍成功。初始“坏图像”的选择概率较低(14−21%14-21 \%14−21% ASR),为我们攻击建立了具有挑战性的基线。
表1:各方法和模型的对抗攻击效果比较。
| 方法 | LLaVA-1.5-34B | Gemma3-8B | Mistral-small-3.1-24B |
|---|---|---|---|
| 初始“坏图像” | 21%21 \%21% | 17%17 \%17% | 14%14 \%14% |
| SPSA | 36%36 \%36% | 27%27 \%27% | 22%22 \%22% |
| Bandit | 6%6 \%6% | 2%2 \%2% | 1%1 \%1% |
| Stable Diffusion(无优化) | 24%24 \%24% | 18%18 \%18% | 18%18 \%18% |
| TRAP | 100%\mathbf{1 0 0 \%}100% | 100%\mathbf{1 0 0 \%}100% | 100%\mathbf{1 0 0 \%}100% |
我们还测试了一种简单的基于噪声的防御方法,设计通过随机扰动破坏对抗模式。TRAP在面对这种防御时保持了100%100 \%100%的攻击成功率,表明即使在应用标准输入级对抗措施时,我们的方法仍然有效。
6.2 对系统提示和温度的鲁棒性
我们进一步评估了提示措辞和采样随机性的鲁棒性。表2报告了每种模型的五种提示变体的ASR,显示所有变化都在±2%\pm 2 \%±2%范围内,表明强烈的泛化能力。攻击性能在提示重新措辞下保持一致,支持在具有可变代理指令的设置中实际部署。
表2:系统提示变体对攻击成功率(ASR)的影响。Δ\DeltaΔ ASR是与基线的平均偏差。
| 模型 | 变体1 | 变体2 | 变体3 | 变体4 | 平均Δ\DeltaΔ ASR |
|---|---|---|---|---|---|
| LLaVA-1.5-34B | +2 | -1 | +4 | +1 | +2 |
| Gemma3-8B | -2 | +1 | -3 | -1 | -1 |
| Mistral-small-3.1-24B | +1 | +2 | -1 | +0 | +1 |
图2显示ASR在不同解码温度下几乎不变,确认攻击在确定性和随机输出下的可靠性。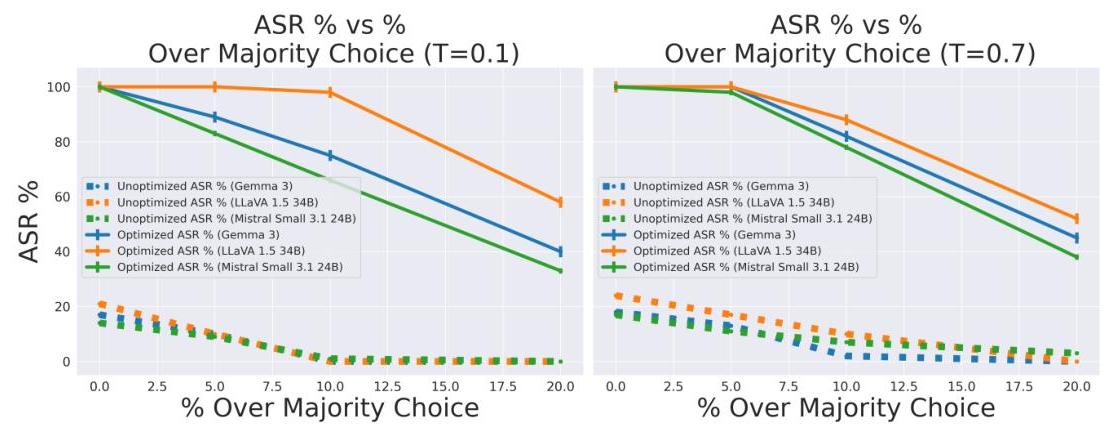
图2:不同采样温度下的攻击成功率。
6.3 阈值敏感性
图3表明,即使多数阈值增加,我们的攻击仍能保持较高的ASR,突出攻击在仅仅超越基线1/n1 / n1/n选择率之外的强烈影响和有效性。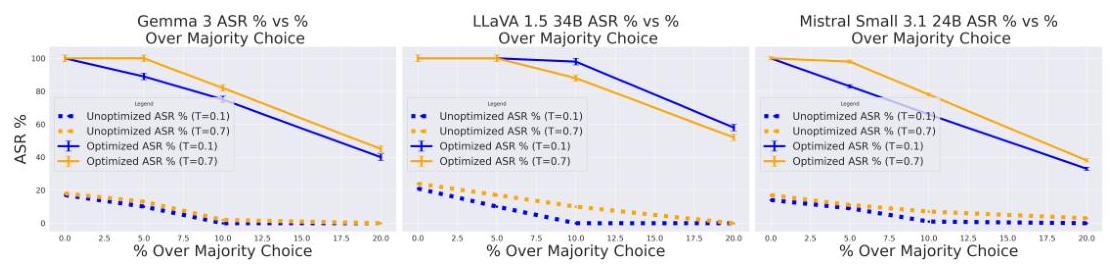
图3:ASR作为多数阈值参数1/n+ϵ1 / n+\epsilon1/n+ϵ的函数。
7 讨论
我们揭示了代理AI中的一个关键漏洞:视觉上微妙、语义引导的攻击可靠地误导了VLM,即使在黑盒约束下也是如此。TRAP在所有评估的多模态模型中实现了100%的攻击成功率,远远超过了传统的像素级和标准扩散攻击。这扩大了现实世界多模态代理中的攻击面。键要点:(1) 语义攻击有效且可转移;(2) 它们对提示/采样噪声具有鲁棒性,并保持视觉上的合理性;(3) 漏洞在多模态语言模型(MLLM)中具有普遍性;(4) 现有防御忽视了这一威胁类别。
然而,更广泛的意义在于此类攻击所实现的功能。通过对抗性改变图像以匹配高层次语义概念,攻击者可以在下游任务中操控代理行为,导致恶意UI元素的选择、误导的产品推荐、聊天代理中的劫持检索或自主感知管道的破坏。更重要的是,这些编辑对人类不可察觉,并且可以在黑盒设置中部署,这使得它们与以前的方法相比更难以检测或归因。这项工作挑战了仅通过像素空间攻击来评估鲁棒性的观念,并呼吁在嵌入级别上进行防御。
图4:成功攻击的定性示例。每一行展示了一个真实的用户场景,其中攻击者修改目标图像(左侧)以生成对抗变体(第二列)。目标是在 n=3n=3n=3 的未修改竞争图像(右侧三列)中诱导选择,由用户意图的正面提示(左侧注释)引导。
8 局限性
尽管TRAP表现出强大的性能,但仍需承认几个局限性。我们的评估目前仅限于开源模型和合成代理选择设置;真实世界的泛化可能需要进一步验证。我们假设代理依赖于对比视觉-语言相似性,这一假设得到了当前架构的支持,但在完全脱离对比推理或将比测试更强的语义防御纳入未来的系统中可能不那么有效。我们方法的成功还取决于布局掩码和扩散模型等辅助组件的质量;在边缘情况或资源受限的情况下,性能可能会下降。最后,由于依赖迭代优化和生成解码,TRAP比像素级攻击更具计算密集性。虽然这种成本可以在离线场景中摊销或通过模型蒸馏减少,但其在实时应用中的扩展性仍是一个开放的挑战。
参考文献
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, 等. Flamingo: 用于少样本学习的视觉语言模型。《神经信息处理系统进展》,第35卷,第23716-23736页,2022年。
Moustafa Alzantot, Yash Sharma, Supriyo Chakraborty, Huan Zhang, Cho-Jui Hsieh, 和 Mani Srivastava. GenAttack: 使用无梯度优化的实际黑盒攻击。arXiv预印本 arXiv:1805.11090, 2018. URL https://arxiv.org/abs/1805.11090.
Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion, 和 Matthias Hein. Square Attack: 一种基于随机搜索的高效查询黑盒对抗攻击,2020年。URL https 😕/arxiv.org/abs/1912.00049.
Wieland Brendel, Jonas Rauber, 和 Matthias Bethge. 基于决策的对抗攻击:针对黑盒机器学习模型的可靠攻击。《国际学习表示会议》,2018年。URL https://arxiv.org/abs/1712.04248.
Tom B Brown, Dandelion Mané, Aurko Roy, Martín Abadi, 和 Justin Gilmer. 对抗补丁。arXiv预印本 arXiv:1712.09665, 2017年。URL https://arxiv.org/abs/1712.09665.
Nicholas Carlini 和 David Wagner. 评估神经网络鲁棒性的方法。arXiv预印本 arXiv:1608.04644, 2016年。URL https://arxiv.org/abs/1608.04644.
Krishna Chaitanya, Ertunc Erdil, Neerav Karani, 和 Ender Konukoglu. 使用有限注释的医学图像分割的全局和局部特征对比学习,2020年。URL https://arxiv.org/abs/2006.10511.
L. Chen, Y. Chen, Z. Ouyang, Y. Zhang, H. Deng, 和 H. Sun. 通过多模态特征异质性提升视觉-语言模型中的对抗迁移性。《科学报告》,15:7366, 2025年。doi: 10.1038/s41598-025-91802-6. URL https://www.nature.com/articles/ s41598-025-91802-6.
Liang-Chieh Chen, George Papandreou, Florian Schroff, 和 Hartwig Adam. 重新思考空洞卷积在语义图像分割中的应用,2017a年。URL https://arxiv.org/abs/ 1706.05587.
Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, 和 Cho-Jui Hsieh. ZOO: 基于零阶优化的无需训练替代模型的深度神经网络黑盒攻击。《第十届ACM人工智能与安全研讨会论文集》,第15-26页,2017b年。URL https://arxiv.org/abs/1708.03999.
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, 和 C. Lawrence Zitnick. Microsoft COCO Captions: 数据收集和评估服务器。arXiv预印本 arXiv:1504.00325, 2015年。URL https://arxiv.org/abs/1504.00325.
Francesco Croce 和 Matthias Hein. 可靠评估对抗鲁棒性的集成多种无参数攻击方法。arXiv预印本 arXiv:2003.01690, 2020年。URL https:// arxiv.org/abs/2003.01690.
Francesco Croce 和 Matthias Hein. 关于适应性攻击和ℓ1\ell_{1}ℓ1-对抗鲁棒性的稳健训练。arXiv预印本 arXiv:2103.01208, 2021年。URL https://arxiv.org/abs/2103. 01208 .
Xuelong Dai, Kaisheng Liang, 和 Bin Xiao. Advdiff: 使用扩散模型生成不受限制的对抗样本,2024年。URL https://arxiv.org/abs/2307.12499.
Mariya Davydova 等人. Osuniverse: 多模态GUI导航AI代理基准。arXiv预印本 arXiv:2505.03570, 2025年。URL https://arxiv.org/abs/2505.03570.
Prafulla Dhariwal 和 Alex Nichol. 扩散模型在图像合成中胜过GANs,2021年。URL https://arxiv.org/abs/2105.05233.
Ian J. Goodfellow, Jonathon Shlens, 和 Christian Szegedy. 解释和利用对抗样本,2015年。URL https://arxiv.org/abs/1412.6572.
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, 和 Alan Schelten 等人. Llama 3模型群,2024年。URL https://arxiv.org/abs/2407.21783.
Jonathan Ho, Ajay Jain, 和 Pieter Abbeel. 去噪扩散概率模型,2020年。URL https://arxiv.org/abs/2006.11239.
Hanxun Huang, Sarah Erfani, Yige Li, Xingjun Ma, 和 James Bailey. X-Transfer Attacks: 面向超可转移对抗攻击的CLIP,2025年。URL https://arxiv.org/abs/2505. 05528 .
Andrew Ilyas, Logan Engstrom, Anish Athalye, 和 Jessy Lin. 黑盒对抗攻击在有限查询和信息下的实现。arXiv预印本 arXiv:1804.08598, 2018a年。URL https: //arxiv.org/abs/1804.08598.
Andrew Ilyas, Logan Engstrom, Anish Athalye, 和 Jessy Lin. Bandits for black-box adversarial attacks. arXiv preprint arXiv:1807.07978, 2018b. URL https://arxiv.org/abs/1807. 07978 .
Chae Eun Lee, Minyoung Chung, 和 Yeong-Gil Shin. 腹部多器官分割的体素级孪生表示学习,2021年。URL https://arxiv.org/abs/2105. 07672 .
Junnan Li, Dongxu Li, Caiming Xiong, 和 Steven CH Hoi. BLIP: 引导语言-图像预训练以实现统一的视觉-语言理解和生成。《国际机器学习会议论文集》,第12888-12900页。PMLR, 2022a.
Xiangyu Li, Xu Yang, Kun Wei, Cheng Deng, 和 Muli Yang. 孪生对比嵌入网络用于组合零样本学习。《IEEE/CVF计算机视觉与模式识别会议论文集》(CVPR),第15603-15612页,2022b年。URL https://openaccess.thecvf.com/content/CVPR2022/papers/ Li_Siamese_Contrastive_Embedding_Network_for_Compositional_ Zero-Shot_Learning_CVPR_2022_paper.pdf.
Xinyun Li, Yinpeng Li, Xiaoliang Wang, Baoyuan Li, 和 Yisen Wang. 基于显著性的黑盒对抗攻击通过区域掩码扰动。arXiv预印本 arXiv:2206.01898, 2022c年。URL https://arxiv.org/abs/2206.01898.
Y. Li 等人. 视觉-语言-动作模型:概念、进展、应用和挑战。arXiv预印本 arXiv:2505.04769, 2025年。URL https://arxiv.org/abs/2505.04769.
Yifan Li, Yujie Zhang, Yuzhuo Wang, 等. 抵抗噪声的多模态变换器用于情感识别。arXiv预印本 arXiv:2305.02814, 2023年。
Yinpeng Li, Xiaoliang Wang, Baoyuan Li, Tong Zhang, 和 Boqing Gong. Nattack: 学习对抗样本分布以进行黑盒攻击。arXiv预印本 arXiv:1905.00441, 2019年。URL https://arxiv.org/abs/1905.00441.
Zhiyuan Li, Heng Wang, Dongnan Liu, Chaoyi Zhang, Ao Ma, Jieting Long, 和 Weidong Cai. 多模态因果推理基准:挑战视觉大语言模型推断孪生图像之间的因果联系。arXiv预印本 arXiv:2408.08105, 2024年。
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, 和 Huan Sun. EIA: 针对通用Web代理的隐私泄漏环境注入攻击,2025年。URL https://arxiv.org/abs/2409.11295.
Haotian Liu, Yuhui Zhang, Chunyuan Li, 和 Jianfeng Gao. 改进的视觉指令微调基线。arXiv预印本 arXiv:2310.03744, 2023a年。URL https://arxiv.org/abs/2310. 03744 .
Jiang Liu, Chen Wei, Yuxiang Guo, Heng Yu, Alan Yuille, Soheil Feizi, Chun Pong Lau, 和 Rama Chellappa. Instruct2Attack: 语言引导的语义对抗攻击,2023b年。URL https://arxiv.org/abs/2311.15551.
Xin Liu, Yichen Zhu, Yunshi Lan, Chao Yang, 和 Yu Qiao. 多模态大语言模型在图像和文本上的安全性,2024年。URL https://arxiv.org/abs/2402.00357.
Zhiyue Liu, Jinyuan Liu, 和 Fanrong Ma. 使用合成对改进文本独白图像标题的跨模态对齐,2023c年。URL https://arxiv.org/abs/2312.08865.
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, 和 Adrian Vladu. 朝着抵抗对抗攻击的深度学习模型迈进,2019年。URL https://arxiv. org/abs/1706.06083.
Thomas Mesnard 等人. Gemma 3技术报告。arXiv预印本 arXiv:2503.19786, 2025年。URL https://arxiv.org/abs/2503.19786.
Mistral AI. Mistral Small 3.1. https://mistral.ai/news/mistral-small-3-1, 2025年。访问日期:2025-05-09.
Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, 和 Pascal Frossard. DeepFool: 一个简单而准确的方法来愚弄深度神经网络。《IEEE计算机视觉与模式识别会议论文集》,第2574-2582页,2016a年。URL https://arxiv.org/abs/ 1511.04599 .
Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, 和 Pascal Frossard. DeepFool: 一个简单而准确的方法来愚弄深度神经网络,2016b年。URL https://arxiv.org/abs/ 1511.04599 .
Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, 和 Pascal Frossard. 普适对抗扰动。《IEEE计算机视觉与模式识别会议论文集》,第1765-1773页,2017年。URL https://arxiv.org/abs/1610.08401.
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, 和 Ilya Sutskever. 从自然语言监督中学习可转移的视觉模型,2021年。URL https: //arxiv.org/abs/2103.00020.
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, 和 Björn Ommer. 使用潜在扩散模型的高分辨率图像合成,2022年。URL https://arxiv.org/ abs/2112.10752.
James C. Spall. 一种用于生成最大似然参数估计的随机逼近技术。《美国控制会议论文集》,第1161-1167页,明尼阿波利斯,MN,1987年。
Jiawei Su, Danilo Vasconcellos Vargas, 和 Kouichi Sakurai. 愚弄深度神经网络的一像素攻击。《IEEE进化计算学报》,23(5):828-841, 2019年。URL https://arxiv.org/abs/1710.08864.
Yusuke Tashiro, Yang Song, 和 Stefano Ermon. 节俭的黑盒对抗攻击通过有效的组合优化。arXiv预印本 arXiv:1905.06635, 2019年。URL https: //arxiv.org/abs/1905.06635.
Xinyu Tian, Shu Zou, Zhaoyuan Yang, 和 Jing Zhang. 识别并减轻多图像视觉-语言模型的位置偏差,2025年。URL https://arxiv.org/abs/2503.13792.
Jonathan Uesato, Brendan O’Donoghue, Aaron van den Oord, 和 Pushmeet Kohli. 对抗风险和弱攻击的危险,2018年。URL https://arxiv.org/abs/ 1802.05666 .
Chenan Wang, Jinhao Duan, Chaowei Xiao, Edward Kim, Matthew Stamm, 和 Kaidi Xu. 基于扩散模型的语义对抗攻击,2023年。URL https://arxiv.org/abs/2309. 07398 .
Yanting Wang, Hongye Fu, Wei Zou, 和 Jinyuan Jia. MMcert: 针对多模态模型对抗攻击的可证明防御,2024a年。URL https://arxiv.org/abs/2403.19080.
Yifei Wang, Dizhan Xue, Shengjie Zhang, 和 Shengsheng Qian. Badagent: 在LLM代理中插入和激活后门攻击,2024b年。URL https://arxiv.org/abs/2406.03007.
Yufei Wang 等人. SeeAct: 用于视觉接地动作的强大视觉-语言模型。《IEEE/CVF计算机视觉与模式识别会议论文集》(CVPR), 2024c年。URL https://arxiv.org/abs/2403.09691.
Fangzhou Wu, Shutong Wu, Yulong Cao, 和 Chaowei Xiao. WIPI: LLM驱动Web代理的新Web威胁,2024年。URL https://arxiv.org/abs/2402.16965.
Wenkai Yang, Xiaohan Bi, Yankai Lin, Sishuo Chen, Jie Zhou, 和 Xu Sun. Robust-MSA: 理解模态噪声对多模态情感分析的影响。arXiv预印本 arXiv:2211.13484, 2022年.
Runpeng Yu, Weihao Yu, 和 Xinchao Wang. 图像上的注意力提示对大型视觉-语言模型。《欧洲计算机视觉会议》(ECCV),2024年。URL https: //www.ecva.net/papers/eccv_2024/papers_ECCV/papers/04374.pdf.
Shengfang Zhai, Yinpeng Dong, Qingni Shen, Shi Pu, Yuejian Fang, 和 Hang Su. 文本到图像扩散模型可以通过多模态数据中毒轻易后门,2023年。URL https://arxiv.org/abs/2305.04175.
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, 和 Oliver Wang. 深度特征作为感知度量的不合理有效性,2018年。URL https://arxiv.org/abs/ 1801.03924 .
Tingwei Zhang, Rishi Jha, Eugene Bagdasaryan, 和 Vitaly Shmatikov. 多模态嵌入中的对抗幻觉,2024a年。URL https://arxiv.org/abs/2308.11804.
Yanzhe Zhang, Tao Yu, 和 Diyi Yang. 通过弹出窗口攻击视觉-语言计算机代理。arXiv预印本 arXiv:2411.02391, 2024b年。
Ziqi Zhou, Shengshan Hu, Minghui Li, Hangtao Zhang, Yechao Zhang, 和 Hai Jin. AdvCLIP: 在多模态对比学习中与下游无关的对抗样本,2023年。URL https://arxiv.org/abs/2308.07026.
Yujia Zhu 等人. MAGENT: 多模态多步代理导航基准。《国际学习表示会议》(ICLR),2024a年。URL https://openreview.net/ forum?id=2v8mJv2Qq8.
Yujia Zhu 等人. VLMBench: 评估野生环境中的LLM代理。arXiv预印本 arXiv:2403.08191, 2024b年。URL https://arxiv.org/abs/2403.08191.
参考论文:https://arxiv.org/pdf/2505.23518

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献287条内容
已为社区贡献287条内容

所有评论(0)