论文略读:AIstorian lets AI be a historian: A KG-powered multi-agent systemfor accurate biography genera
202503 arxiv
·
202503 arxiv
- 人物传记生成是人工智能与历史交叉融合的重要方向
- 自动化传记生成的发展可以帮助历史学者摆脱这些繁重的读写任务
- 传记生成是指根据参考资料(如教科书等)提取并改写传记事件,自动撰写出一份简明的文档,包含一系列事实和事件(如出生/逝世的时间和地点、职业等),以勾勒一个人物的专业形象
- 从技术角度看,传记生成可以被视为一种特殊形式的抽象摘要(abstractive summarization)
- 然而,相比于通用文本摘要,传记生成具有一些现有基于 LLM 的方法或垂直领域预训练模型难以应对的独特特点:
- 风格遵循性(Stylistic adherence)
- 传记写作必须严格遵循特定语言风格,并使用专业术语,而这恰是 LLMs 擅长度不高的领域
- 当要求以文言文撰写传记并遵循历史写作规范时,LLMs 往往难以保持风格一致性
- 已有研究尝试通过微调注入领域知识,但由于缺乏遵循特定风格的训练语料,即使微调后的 LLM 也难以在语言风格和术语运用上做到准确遵循。
- 传记写作必须严格遵循特定语言风格,并使用专业术语,而这恰是 LLMs 擅长度不高的领域
- 事实真实度(Factual fidelity)
- 传记对于事实错误是零容忍的。
- 然而,众所周知 LLM 容易出现“幻觉”(hallucination)现象,即生成貌似合理但与真实事实矛盾的内容,从而严重影响传记的实用性
- 目前已有三类方法试图缓解摘要生成中的虚构内容问题:
- 基于训练的方法
- 通过训练奖励模型或分类器,从根本上修正事实错误
- 缺点是依赖大量训练样本(数万级)
- 基于解码的方法
- 通过限制从上下文中采样的输出 token 来避免幻觉。
- 虽有效,但会限制模型的创造力;
- 基于检索增强生成(RAG)的方法
- 通过从外部知识库(如历史教科书)检索相关信息作为参考,指导 LLM 进行传记生成。
- 检索的准确性对生成质量具有决定性影响。
- 基于训练的方法
- 信息碎片化(Information fragmentation)
- 关于某位历史人物的详细信息通常分散在多个文档中
- RAG 流程中有两个关键组件——文本切块(text chunking)和切块表征(chunk representation)——在此背景下面临信息碎片化的挑战
- 不同人物的描述文本长度差异较大,给文本切块带来困难,容易引入无关的噪声信息
- 句子中的别名与代词使语义变得模糊,导致文本切块的语义嵌入难以区分,从而出现“表征稀释”(representation dilution)问题
- 风格遵循性(Stylistic adherence)
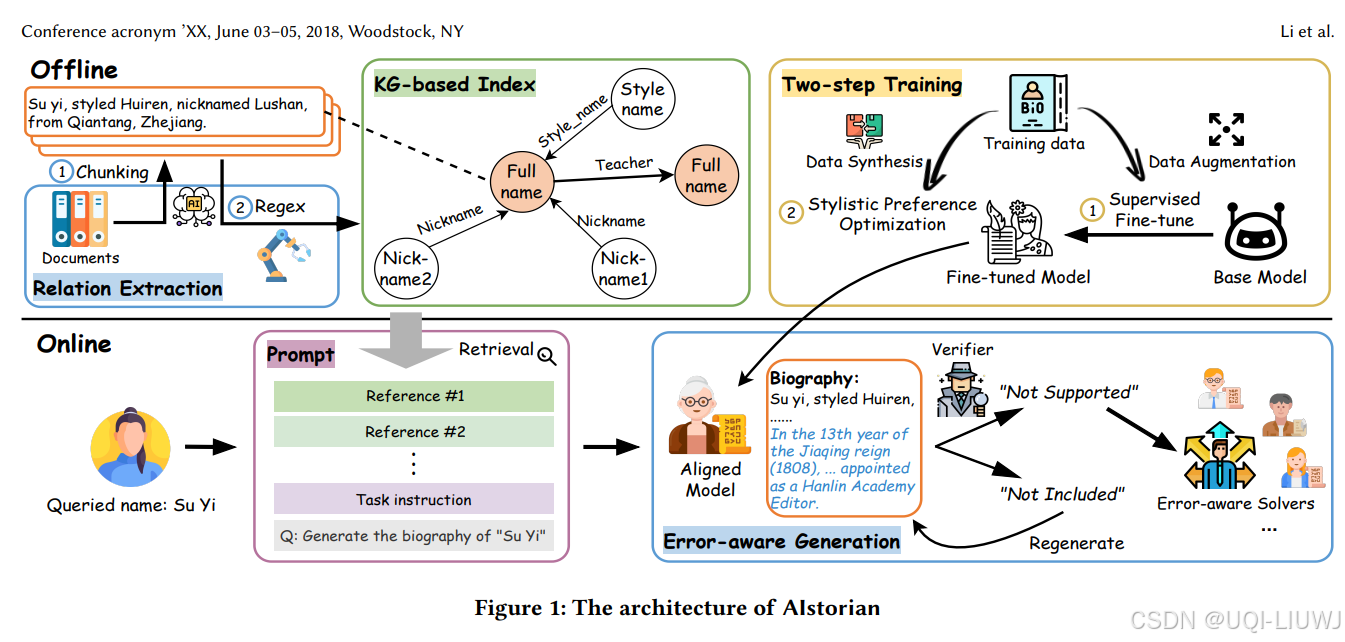
- ——>论文提出了 AIstorian,一个创新的 agentic 系统,用于实现高质量传记生成
- 该系统由知识图谱(KG)驱动的 RAG 机制和抗幻觉多智能体(multi-agent)模块组成
- 在 KG 驱动的 RAG 机制中,设计了一种基于**上下文学习(in-context learning)**的文本切块策略,并构建了一个基于知识图谱的索引结构,用于对外部知识库进行重组,从而实现高效、准确的信息检索。
- 为进一步减少 LLM 的幻觉现象,我们引入了实时抗幻觉多智能体系统,其中包括即时幻觉检测和面向错误类型的修正机制,确保生成的传记在事实层面忠实于源文档。
- 为了更好地适配特定语言风格,使用两阶段训练流程对基础模型进行微调:第一阶段是基于数据增强的有监督微调,第二阶段是风格偏好优化。
- 该系统由知识图谱(KG)驱动的 RAG 机制和抗幻觉多智能体(multi-agent)模块组成
- 在 Jinshi 数据集上进行了大量实证实验,结果表明该系统在生成质量(Rouge-L 得分:80.54)和事实准确性方面表现优越,幻觉率下降 47.6%,原子事实错误平均减少 3.8 倍。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)