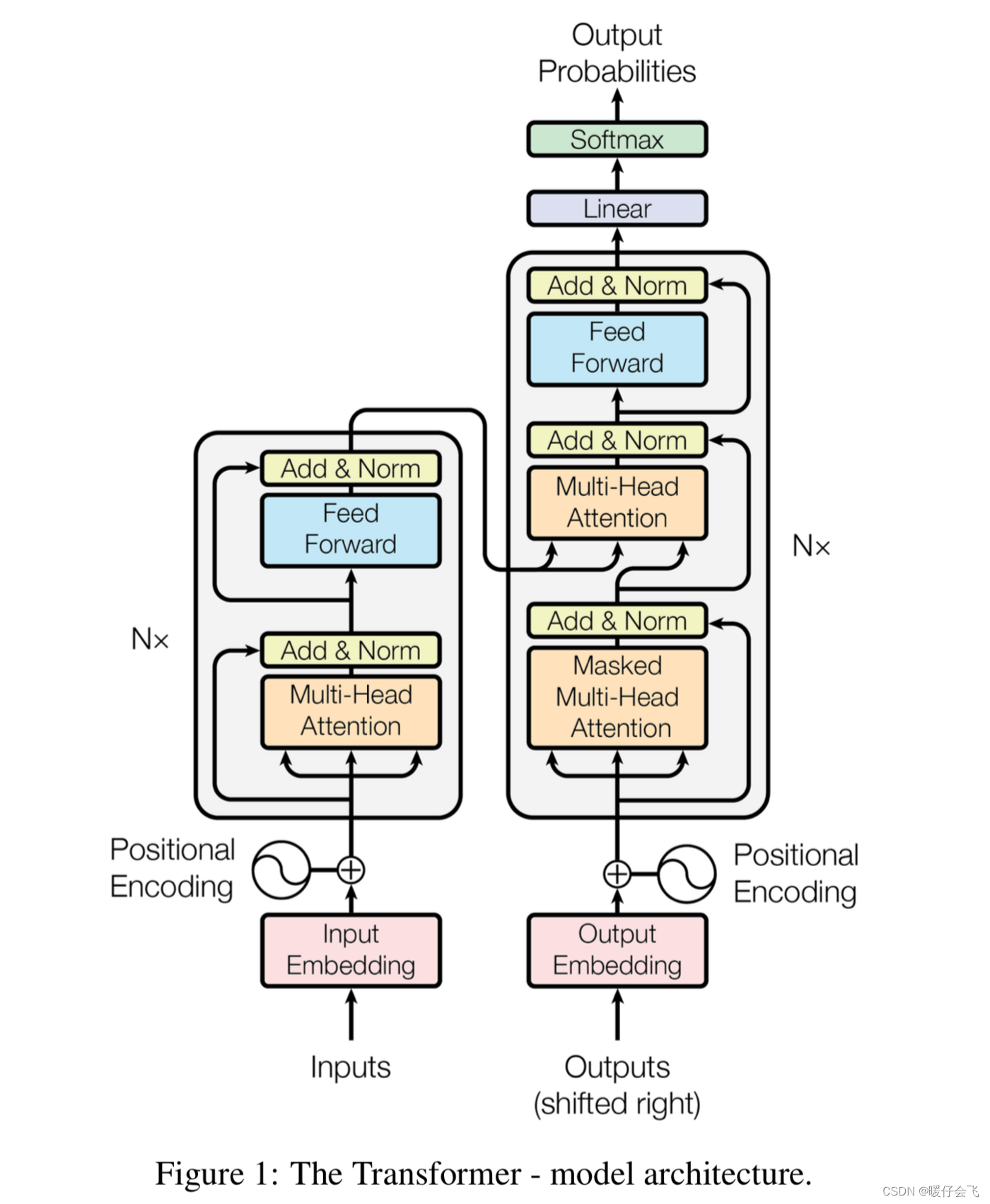
一文吃透Transformer Encoder Attention原理(附代码示例,建议收藏)
同时课程详细介绍了。
本文详细解析了Transformer模型中Encoder端的Attention机制。通过线性变换将输入词向量转换为Query、Key和Value向量,计算Query与所有Key的点积并经softmax得到权重,最后用这些权重对Value向量加权求和。这一过程使每个词能够关注输入序列中的其他词,捕捉词与词之间的关系,增强模型对序列的理解能力。文章通过维度分析,直观展示了Attention的计算过程。
encoder 的 attention
- 场景:现在要训练的内容是 I love my dog -> 我喜欢我的狗
- 那么在 encoder 端的输入是: I love my dog;
- 假设经过 embedding 和位置编码后,I love my dog 这句话肯定已经变成了一个向量,但是在这里方便起见,我们依然用 I love my dog 来表示经过了处理之后的向量表示,后面有机会我会将向量的维度拆解开再给大家讲一遍
- 接下来要进入 encoder 端的 attention 层了
attention 的动机
- 动机很简单:生成一个张量,张量表示了输入的每一个词向量和其他词向量之间的关系。
- 这个关系的表示,需要在一个给定维度的空间中完成(在另外一个空间中求相似度,后面会解释)。而在多少维度的空间中进行,就取决于我们在 attention 中指定的线性层的维度
如何衡量关系——相似度
- 我们初中就学过,衡量两个向量的相似度的方法就是向量点乘,数值越大越相似
- 而编码过的单词天生就是向量
如何构造两个相乘的向量
- 难道要用 III 向量和所有的 Love,my,dogLove, my, dogLove,my,dog 都相乘一遍得到相似度么?
- 这个思考方向是对的,但是存在一个问题,就是这样乘出的相似度没有意义,因为在当前的表示空间中,所有的词的向量表示都是固定的;
- 而我们想让那些彼此相乘的向量具有以下特点:
- 这些向量能够代表文本向量的信息,因为我们还是想要得到 III 到底和 LoveLoveLove 关系更近还是和 MyMyMy 关系更近
- 这些向量能够带有可学习的参数,通过神经网络的迭代自己学出来;这样可以保证在不同的场景下,权重可以自行改变,有时候 III 可以和 lovelovelove 的关系更近,而有些时候则和其他的单词的关系更近
- 所以这很自然有一个想法:
- 我直接以原文本的向量为基础,通过线性层对他的特征进行一次处理,这样得到的向量不就具有上述特点了么;
- 线性层的输入是原文本的向量,这样可以保证线性层的输出是原文本的一种表示,这相当于将原本的所有词向量映射到另外一个高维空间中的向量,而这个过程引入了可学习的参数,相当于那些被映射过去的向量之间的关系并未确定,而是需要根据 loss 和反向传播不断更新才能最终收敛,直到那时,词向量之间的关系才被最终确定。
- 这就是 Transformer 中总是提到的 q,k,vq, k, vq,k,v 向量和 Q,K,VQ,K,VQ,K,V 矩阵的作用了;我们先说 q,k,vq, k, vq,k,v 向量;后面很自然地会过渡到 Q,K,VQ, K, VQ,K,V 矩阵。
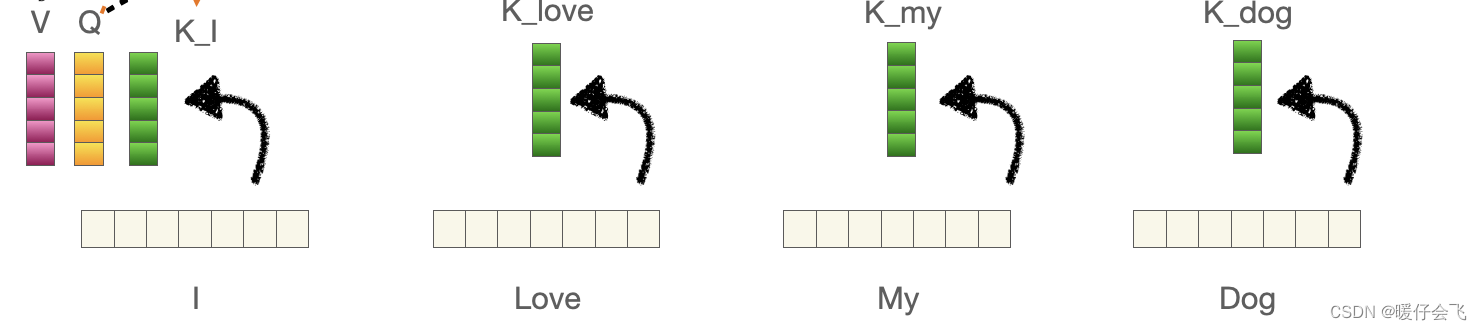
- 我们以 III 这个文本为例,对他采用线性层生成一个 qqq 向量,这个 qqq 向量包含了 III 向量原本的信息,然后对其他的所有文本也都通过线性层生成他们各自的 kkk 向量;这些 kkk 向量其实和 qqq 是完全一样的东西,都只是线性层的输出而已,但是为了进行后面的操作,我们人为地对这些向量进行区分
- 当然,除了III 之外的单词也会产生 qqq 向量,只是这里我们先看 III 这个单词,所以先将 III 当做主角,其他单词的 qqq 向量也是同样的作用,如法炮制
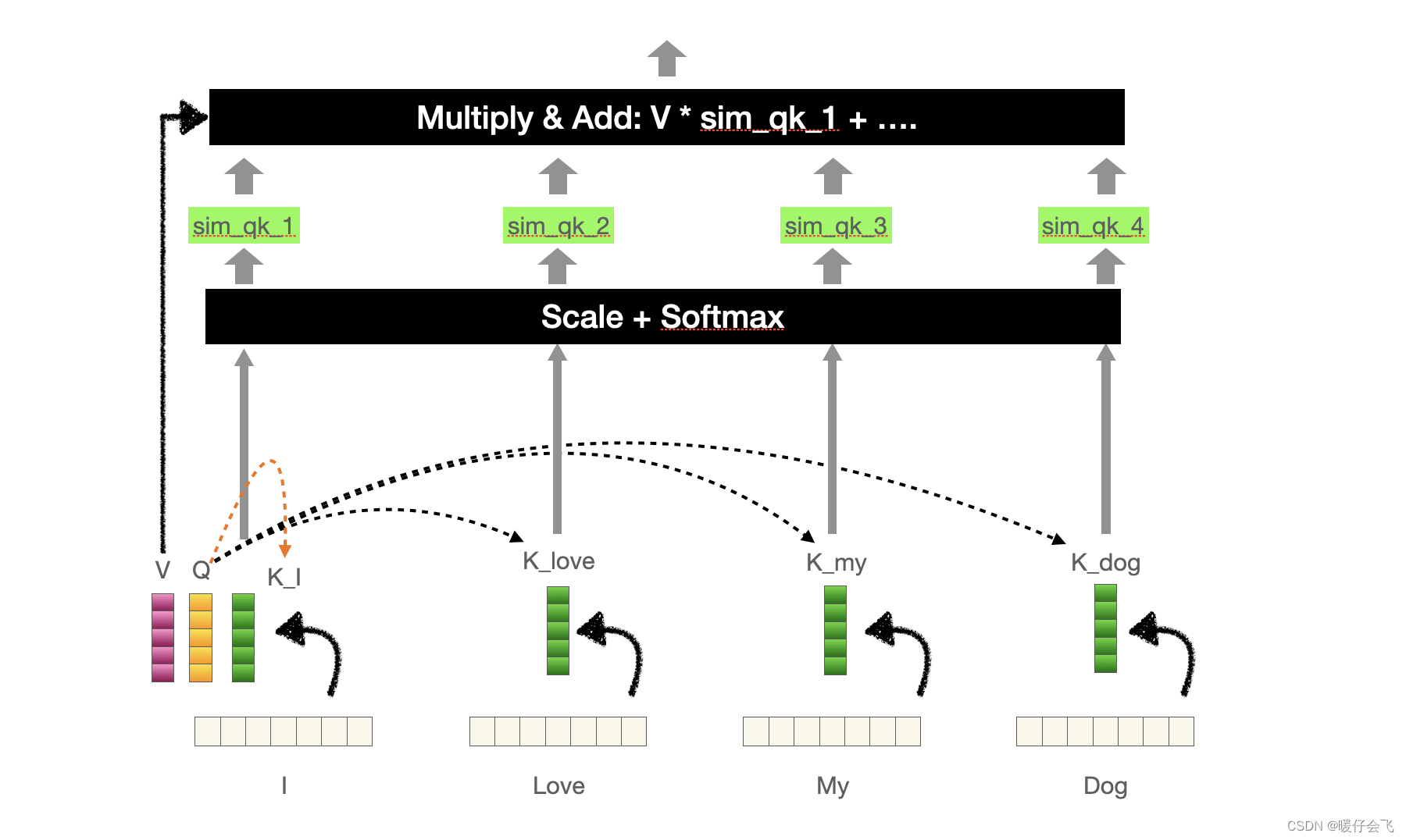
- 得到 III 的 qqq 向量之后,让这个 qqq 向量和其他所有单词产生的 kkk 向量 klove,kmy,kdogk_{love}, k_{my}, k_{dog}klove,kmy,kdog 进行点乘,是不是就可以获得 I 对其他所有单词的值(有几个单词就产生几个值)但是这些值还不能叫做权重,因为相似度计算出的值范围根本不确定;因此我们对这些值共同算一个 softmax 就可以得到权重值了。
- 举个🌰,假设 III 的 qqq 向量和每个 kkk 计算得到的值分别为 [a,b,c,d][a, b, c, d][a,b,c,d];这些值要进行放缩之后再 softmaxsoftmaxsoftmax 才能得到最终的权重值。
- 再强调一遍,这个权重值会根据训练的不同阶段而不断更新,但是我们知道,通过这个步骤,III 建立了它对所有单词的关系,这些关系其实就只是在另外一个高维空间中的相似度数值而已。
-
最终还要再用 v 向量再去和每一个生成的相似度权重 sim_qk_nsim\_{qk}\_nsim_qk_n (每一个都是标量)相乘之后相加,得到一个最终的向量。这个最终的向量编码了 I 和其他词向量的关系
-
同样的,对于 Love,my,dogLove, my, dogLove,my,dog 这些词向量,也通过相同的方式获得了他们各自的最终和其他词向量在高维空间中的关系表示
-
我们用向量的维度来具体的,更加深入理解一下这个过程:
- 假设 I,love,my,dogI,love,my,dogI,love,my,dog 都已经被 embeddingembeddingembedding 成维度为 6 的向量,即,(1,6)(1,6)(1,6)
- 线性层选的神经元个数都是 5,即,(1,5)(1, 5)(1,5) 代表我们想在一个 5 维的空间中构建这些词之间的关系
- 那么 q,k,vq, k, vq,k,v 也都是 (1,5)(1, 5)(1,5) 的向量
- 当 III 的 qiq_iqi(1,5) 与这四个 kkk 点乘之后,可以得到 4 个标量,
- 将这 4 个标量分别与 vi:(1,5)v_i: (1,5)vi:(1,5) 相乘(标量乘)并相加,得到的最终还是一个向量 vi′:(1,5)v_i^{‘}: (1, 5)vi′:(1,5),这个 vi′v_i^{’}vi′ 编码了 qiq_iqi 和其他词向量在 5 维空间中的相关关系。
- 这个过程中的 qiq_iqi 和多个 kkk 进行运算的步骤可以转成向量和矩阵的乘法, qiq_iqi,和 4 个 k 组成的张量 K:(4,5)K: (4, 5)K:(4,5) 进行相乘,(注意,这里要将 KKK 进行转置),得到 qKTq K^TqKT 维度是 (1,5)∗(5,4)=(1,4)(1, 5)* (5, 4)= (1, 4)(1,5)∗(5,4)=(1,4)就是那四个标量值组成的向量
- 这只是一个对 qiq_iqi 求算 attentionattentionattention 的整体步骤,而我们刚好要对所有单词生成的 q 都进行这个过程,所以我们可以也把 qqq 做成 QQQ,也就是将所有的 4 个单词的 qqq 直接拼起来组成的 Q:(4,5)Q: (4, 5)Q:(4,5), 与刚才的 KT:(5,4)K^T: (5,4)KT:(5,4) 得到 权重矩阵 QKT:(4,4)QK^{T}: (4, 4)QKT:(4,4)
)K^T: (5,4)KT:(5,4) 得到 权重矩阵 QKT:(4,4)QK^{T}: (4, 4)QKT:(4,4) - 然后将所有单词的 v 向量也拼起来,组成 V:(4,5)V: (4, 5)V:(4,5) 与权重矩阵 (4,4)(4, 4)(4,4) 最终得到 attentionattentionattention 的矩阵 QKTV(4,5)QK^{T} V (4,5)QKTV(4,5)这其中的 4 代表的是这 4 个单词与其他单词的 attentionattentionattention 关系的编码, 5 则代表这些 attentionattentionattention 关系被编码的空间是一个维度为 5 的空间。5 个数值来共同表示这些关系。
零基础如何高效学习大模型?
你是否懂 AI,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和鲁为民博士系统梳理大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献200条内容
已为社区贡献200条内容

所有评论(0)