“反转诅咒“彻底解决,反向推理准确率96%!新架构突破LLM多年认知瓶颈
或许未来的AI会像《超验骇客》中的AI,真正理解"巴黎不只是一个地名,更是历史、艺术与浪漫的集合体"。这种现象暴露了当前大语言模型的致命弱点:它们像死记硬背的学生,无法理解知识的内在关联。"反转诅咒":一个令人头疼的Bug:想象你教LLM记住"张三的妻子是李四",但当问"李四的丈夫是谁"时,却一脸懵——这就是。这说明AI终于学会"触类旁通":知道X=5、Y=3、X+Y=Z后,能自动推导Z=8并反向
"反转诅咒":一个令人头疼的Bug:想象你教LLM记住"张三的妻子是李四",但当问"李四的丈夫是谁"时,却一脸懵——这就是反转诅咒。
论文:Is the Reversal Curse a Binding Problem? Uncovering Limitations of Transformers from a Basic Generalization Failure
链接:https://arxiv.org/pdf/2504.01928v1
这种现象暴露了当前大语言模型的致命弱点:它们像死记硬背的学生,无法理解知识的内在关联。论文指出,这不仅是记忆问题,更揭示了AI认知结构的根本缺陷。
实验数据显示,当直接使用抽象概念时(如用代号代替人名),模型反向推理准确率高达96%。但一旦涉及真实词汇,性能直接归零。这说明问题不在计算能力,而在信息处理方式。
元凶竟是"绑定问题"?认知科学与LLM的奇妙碰撞
人类大脑有个神奇能力:看到埃菲尔铁塔图片和"巴黎"文字时,能自动绑定到同一概念。这种概念绑定能力,正是LLM缺失的。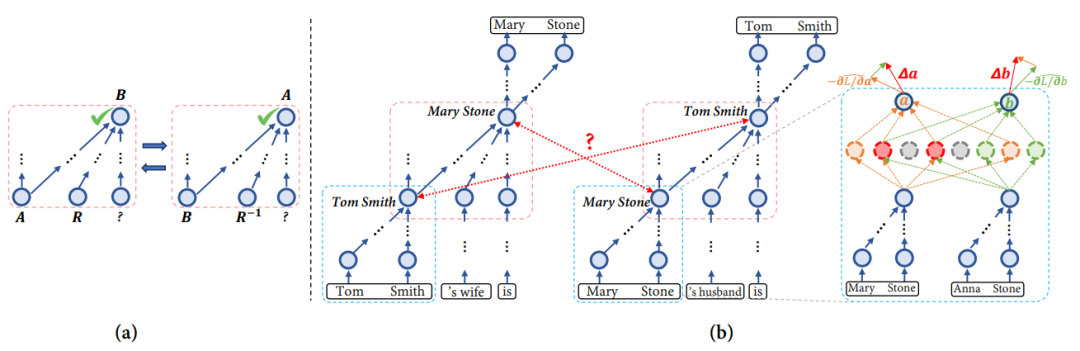 Transformer模型存在两大缺陷:
Transformer模型存在两大缺陷:
-
表征不一致:同一个概念作为主语或宾语时,AI当成两个不同事物
-
概念纠缠:类似"张伟"和"张伟明"的名字会让AI混淆记忆
就像整理混乱的衣橱,LLM需要把相关信息绑定到统一"衣架"上,而不是随处乱塞。
实验:为什么模型学不会反向思考
研究者设计了一个精妙实验:用虚构人名(如"张A·李B")控制名字相似度。结果发现:
-
当名字重复率(multiplicity)从10增加到20时,模型性能从75%暴跌到接近0%(图右)
-
模型层数越深,表现反而越差(图左)
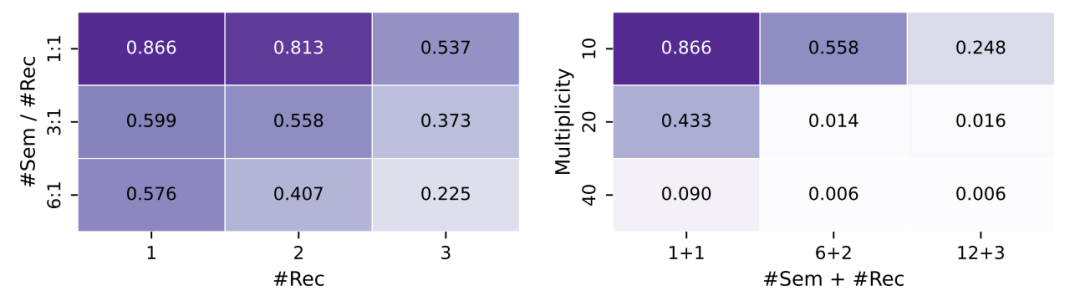
这说明模型在处理表面信息时,概念纠缠会随着复杂度指数级增长,就像耳机线越理越乱。
破局新架构:JEPA与记忆层的双重突破

研究者开出两剂猛药:
-
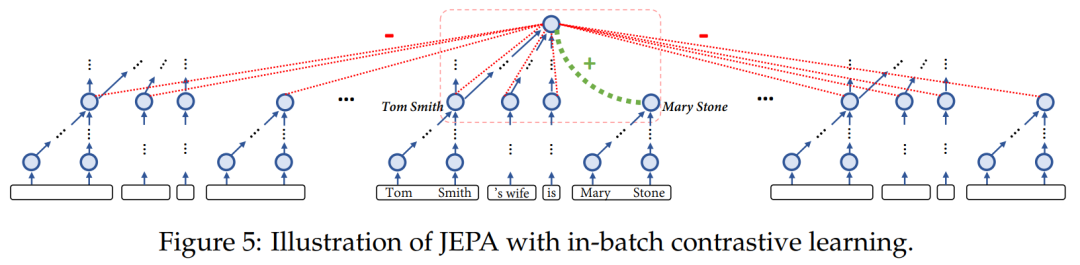
JEPA架构:让LLM在抽象空间做预测,相当于先提取概念本质再推理。
-
记忆层:给每个概念设立独立存储空间,避免信息混淆(图右)
 公式揭秘:
公式揭秘:
传统梯度更新会导致概念互相干扰:
Δa = -η||α||²(∂L/∂a) - η(α·β)(∂L/∂b)
Δb = -η||β||²(∂L/∂b) - η(α·β)(∂L/∂a)
红色部分(α·β)就是纠缠元凶,记忆层通过物理隔离彻底消除这种干扰。
数学推理实验:小改动带来大提升
在复杂数学题测试中,新架构表现出惊人优势:
-
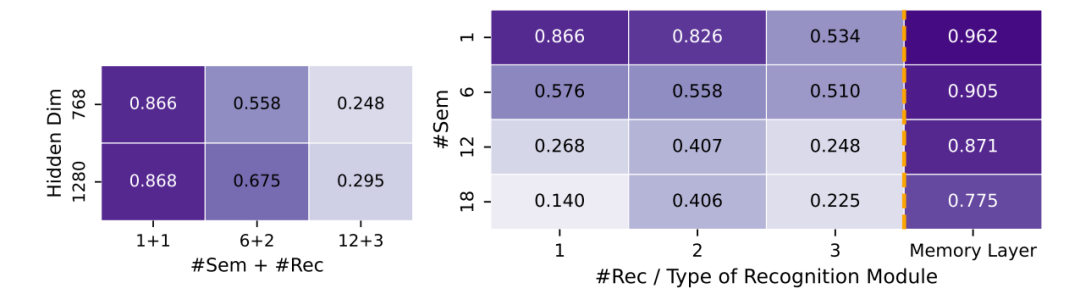
当问题规模扩大(分支因子40),传统LLM准确率从78%跌到32%
-
新架构仅从85%降到76%,展现强大扩展性(图右)
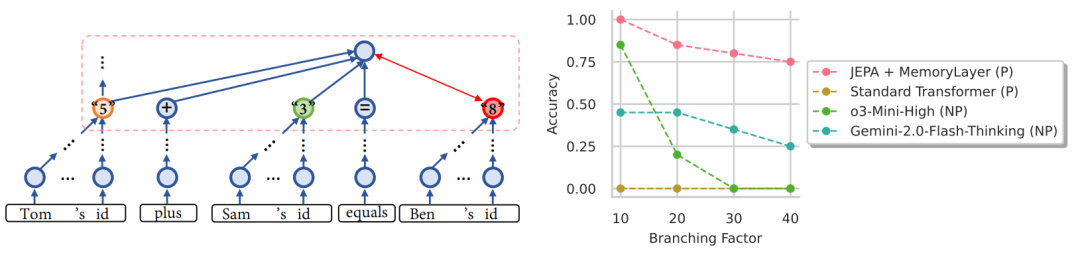 这说明AI终于学会"触类旁通":知道X=5、Y=3、X+Y=Z后,能自动推导Z=8并反向应用。
这说明AI终于学会"触类旁通":知道X=5、Y=3、X+Y=Z后,能自动推导Z=8并反向应用。
展望:通向强AI的关键拼图
虽然突破显著,但现方案仍需人工指定概念位置,就像给婴儿标注好所有玩具收纳盒。真正的挑战是让AI自主建立系统化的概念绑定机制。
这场探索揭示:想要实现人类级智能,AI不仅需要更大算力,更需要模仿人脑的信息整合方式。或许未来的AI会像《超验骇客》中的AI,真正理解"巴黎不只是一个地名,更是历史、艺术与浪漫的集合体"。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献258条内容
已为社区贡献258条内容

所有评论(0)