大模型最新趋势!LVLM再突破,让诊断可信度暴涨!
最新LVLM研究突破视觉与语义的鸿沟:谷歌GeminiPro-Visual通过动态模态注意力提升图文匹配准确率32%;VL-CausE模型实现医学图文诊断与症状关联解释,可信度提高27%。GLSIM框架创新性结合全局-局部特征检测物体幻觉,AUROC提升12.7%。ECVT架构利用LVLM多粒度语义引导未剪辑视频理解,在ActivityNet和THUMOS14上达到SOTA性能。这些进展显示跨模态
让AI既能识别图片里的茶杯,又能讲清陶瓷材质适合泡茶的原理。2025年NeurIPS、CVPR的对于LVLM研究,正填补视觉理解与语义推理的鸿沟。此前传统LVLM常陷看图说话的表层困境,虽能匹配图像与文字,却读不懂场景逻辑,比如误将医生查房描述成陌生人交谈,面对复杂图文问答更是答非所问。而视觉-语言深度对齐+因果推理注入的新方案彻底破局:谷歌Gemini Pro-Visual靠动态模态注意力,图文匹配准确率较旧版提升32%;国内团队的VL-CausE模型,在医学图文诊断中,不仅能定位病灶,还能解释症状与疾病的关联,诊断可信度提高27%。
对论文er来说,跨模态因果建模、轻量化视觉编码器等方向极具潜力。我把最新顶会/顶刊论文和复现代码(部分)打包好了,工种号 沃的顶会 扫码回复 “LVLM” 领取
GLS IM:Detecting Object Hallucinations in LVLMs via Global-Local Similarity
文章解析
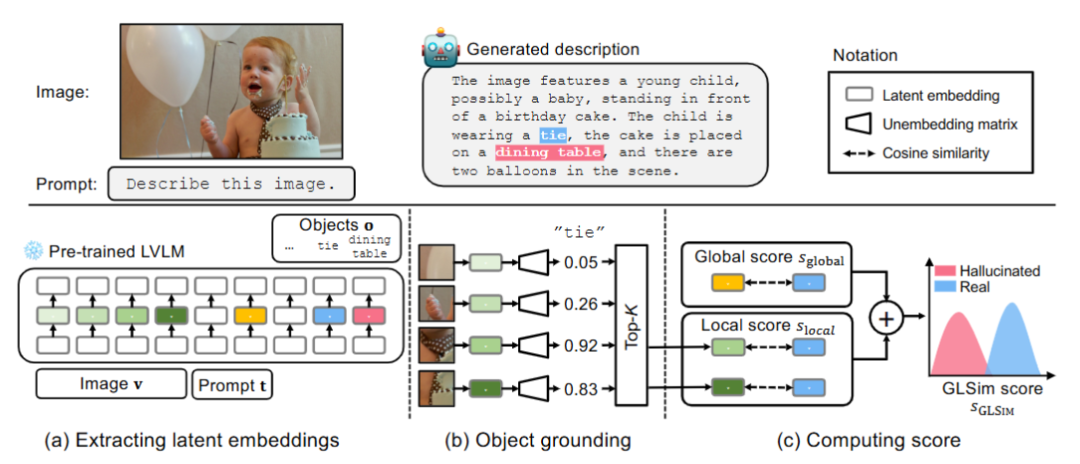
大型视觉-语言模型(LVLMs)在实际应用中存在物体幻觉问题,即生成图像中不存在的物体描述,影响系统可靠性。现有方法通常仅依赖全局或局部特征,检测效果有限。本文提出GLS IM,一种无需训练的物体幻觉检测框架,通过结合图像与文本模态在潜在嵌入空间中的全局相似性和局部定位信号,实现更准确、可靠的幻觉检测。该方法在多个数据集和LVLM上表现优异,显著优于现有基线方法。
创新点
首次将全局相似性和局部 grounding 信号结合用于物体幻觉检测,提升检测准确性。
提出GLS IM评分机制,无需外部模型或标注,完全基于LVLM内部表示。
通过Logit Lens技术改进局部视觉证据提取,增强空间对齐判断。
全面评测现有物体幻觉检测方法,填补了该领域基准研究的空白。
验证了方法在多种LVLM和数据集上的强泛化能力。
研究方法
从预训练LVLM中提取图像和文本的潜在嵌入表示。
计算对象嵌入与整体场景嵌入的全局相似性得分,评估语义合理性。
使用改进的Logit Lens技术定位最相关的图像区域,计算对象与Top-K图像块嵌入的平均余弦相似性作为局部得分。
将全局和局部得分加权融合为最终的GLS IM分数。
基于该分数判断对象是否为幻觉,无需微调或外部模型。
研究结论
GLS IM在多个基准上显著优于现有方法,最高提升12.7% AUROC。
全局和局部信号具有互补性,联合使用可有效区分真实对象与幻觉。
消融实验表明移除任一组件都会导致性能下降。
该方法具有良好的可解释性,能准确识别细微幻觉。
GLS IM是一种轻量、通用且适用于实际部署的幻觉检测方案。
Multi-Level LVLM Guidance for Untrimmed Video Action Recognition
文章解析
本文提出Event-Contextualized Video Transformer (ECVT),利用大型视觉语言模型(LVLM)生成多粒度语义描述,以增强未剪辑视频中的动作识别与定位。ECVT采用双分支结构,其中视频编码分支提取时空特征,跨模态引导分支利用LVLM生成全局事件提示和时序子事件提示,并通过自适应门控、跨模态注意力和事件图模块将文本线索融合到视频特征中,提升模型对视频时序结构和事件逻辑的理解。在ActivityNet v1.3和THUMOS14上的实验表明,ECVT达到最先进的性能。
创新点
提出ECVT架构,首次将LVLM的多层级语义理解能力系统性地引入未剪辑视频动作识别任务。
设计全局事件提示与时序子事件提示机制,实现宏观叙事与细粒度动作的联合建模。
引入事件图模块进行时序上下文校准,增强动作之间的逻辑连贯性。
通过自适应门控与跨模态注意力机制,实现高阶语义融合与细粒度特征优化。
采用端到端训练框架,结合语义一致性与时序校准损失,提升模型整体理解能力。
研究方法
构建双分支网络:视频编码分支提取多尺度时空特征,跨模态引导分支调用LVLM生成多粒度文本描述。
利用LVLM生成全局事件描述(Global Event Prompting)和局部时序子事件描述(Temporal Sub-event Prompting)。
通过自适应门控机制融合高层语义信息,使用跨模态注意力细化视频特征。
引入事件图模块建模事件间的时序依赖关系,实现上下文校准。
采用包含语义一致性和时序校准项的综合损失函数进行端到端训练。
研究结论
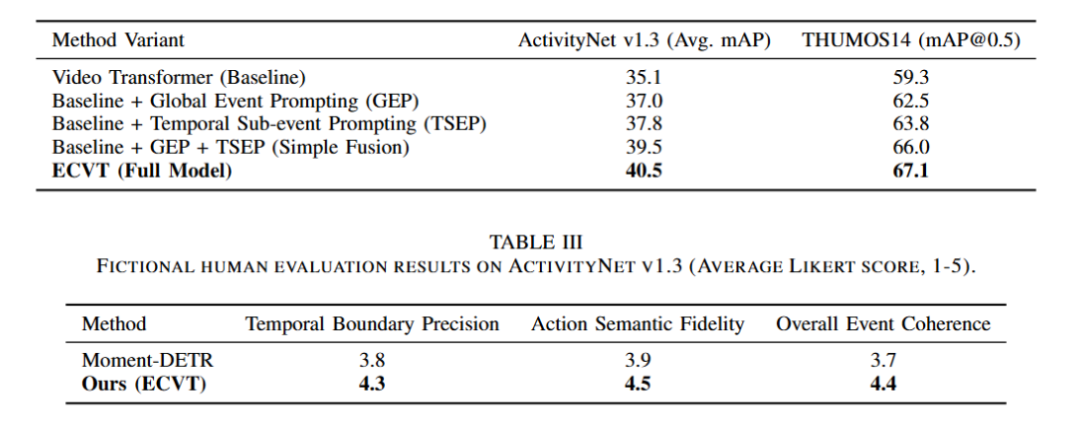
ECVT在ActivityNet v1.3上取得40.5%的平均mAP,在THUMOS14上mAP@0.5达到67.1%,优于Moment-DETR和ActionFormer等先进方法。
LVLM提供的多层级语义引导显著提升了模型对复杂动作逻辑和长时依赖的理解能力。
所提方法有效弥合了低层视觉特征与高层语义概念之间的鸿沟,推动了视频理解向更高层次的认知发展。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)