【AI论文】Web-Shepherd:推进PRM以加强Web代理
本文介绍了Web-Shepherd,这是一个专门用于评估网络导航轨迹的过程奖励模型(PRM),旨在提高网络代理的性能和可靠性。研究首先构建了包含40K个步骤级别偏好对和标注清单的WebPRMCollection数据集,并引入了首个用于评估PRM的元评估基准WebRewardBench。实验结果显示,Web-Shepherd在WebRewardBench上的准确率显著高于GPT-4o,并在WebAr
摘要:网络导航是一个独特的领域,可以自动执行许多重复的现实任务,并且具有挑战性,因为它需要超越典型的多模态大型语言模型(MLLM)任务的长期连续决策。 然而,迄今为止,在训练和测试期间都可以使用的网络导航专用奖励模型一直缺失。 尽管速度和成本效益很重要,但之前的工作已经将MLLM用作奖励模型,这对现实世界的部署造成了很大的限制。 为了解决这个问题,在这项工作中,我们提出了第一个过程奖励模型(PRM),称为Web-Shepherd,它可以逐级评估网络导航轨迹。 为了实现这一目标,我们首先构建了WebPRM Collection,这是一个大规模的数据集,包含40K个步骤级别的偏好对和标注清单,涵盖了不同的领域和难度级别。 接下来,我们还介绍了WebRewardBench,这是第一个用于评估PRM的元评估基准。在我们的实验中,我们观察到,与在WebRewardBench上使用GPT-4o相比,我们的Web-Shepherd的准确率提高了约30分。 此外,当使用GPT-4o-mini作为策略,Web-Shepherd作为验证器在WebArena-lite上进行测试时,与使用GPT-4o-mini作为验证器相比,我们实现了10.9分的性能提升,成本降低了10%。 我们的模型、数据集和代码在LINK上公开可用。Huggingface链接:Paper page,论文链接:2505.15277
研究背景和目的
研究背景
随着互联网技术的飞速发展,网络导航已成为日常生活中不可或缺的一部分,它允许用户通过浏览器执行各种任务,如购物、信息检索、在线预订等。然而,尽管多模态大型语言模型(MLLMs)在基本网页交互方面取得了显著进展,如从地图服务中检索地址或浏览简单网页,但当前的网络代理(Web Agents)在执行复杂任务时仍表现出高度不可靠性。这种不可靠性主要源于网络导航的长期连续决策特性,要求代理在多个步骤中保持目标导向的规划能力,而这正是MLLMs所面临的挑战。
具体而言,网络导航任务通常涉及多个步骤的决策过程,需要代理根据当前网页状态和用户指令,选择最合适的动作以推进任务进度。然而,现有的MLLMs在处理这类任务时,往往难以维持长期的目标导向性,容易在遇到小问题时反复尝试相同的查询,最终导致任务失败。此外,速度和成本效益也是现实世界部署中不可忽视的因素。现有的基于MLLMs的奖励模型(Reward Models)在推理时间和计算成本上存在显著限制,使得它们难以在实际应用中大规模部署。
研究目的
针对上述问题,本研究旨在开发一种专门用于评估网络导航轨迹的过程奖励模型(Process Reward Model, PRM),以提高网络代理的性能和可靠性。具体而言,本研究的目的包括:
- 构建大规模数据集:收集并标注一个包含40K个步骤级别偏好对和清单的大型数据集(WebPRM Collection),以支持PRM的训练和评估。
- 开发PRM模型:提出一种名为Web-Shepherd的PRM模型,该模型能够在步骤级别评估网络导航轨迹,为代理提供细粒度的反馈信号。
- 建立评估基准:引入WebRewardBench,作为首个用于评估PRM的元评估基准,以促进PRM研究的标准化和可重复性。
- 验证模型效果:通过实验验证Web-Shepherd在WebRewardBench和WebArena-lite等基准上的性能,展示其在提高网络代理性能和降低成本方面的优势。
研究方法
数据集构建
为了训练Web-Shepherd模型,研究团队首先构建了WebPRM Collection数据集。该数据集包含来自多个领域和难度级别的40K个步骤级别偏好对和标注清单。具体构建过程如下:
- 网站选择:从Mind2Web训练数据集中使用的网站中选择候选网站,并手动过滤掉与注释过程不兼容的网站。
- 注释者招募与培训:招募一组人类注释者,并由项目管理人员进行为期三小时的教育培训,涵盖数据注释界面、高质量任务指令编写指南、良好与不良轨迹示例以及评估代码设计原则。
- 任务指令创建:要求每位注释者为其分配的每个网站创建20个任务指令,这些任务分布在三个难度级别上:简单、中等和困难。
- 专家轨迹记录:注释者执行他们创建的任务,并记录成功完成任务所需的完整观察-动作对序列。
- 评估代码编写:注释者编写能够自动评估轨迹是否达到用户目标的评估代码。
- 验证与过滤:通过自动和手动验证确保数据质量,过滤掉错误或低质量的数据。
模型训练
Web-Shepherd模型基于生成式奖励建模(Generative Reward Modeling)方法进行训练,具体步骤如下:
- 模型架构:选择Qwen2.5-3B、Qwen3-8B(文本)和Qwen2.5-VL-3B(多模态)作为基础模型,使用LoRA(Low-Rank Adaptation)技术进行微调。
- 训练数据:使用WebPRM Collection数据集进行训练,优化语言建模损失(Language Modeling Loss),通过连接反馈(Feedback)和判断(Judgment)形成连贯的响应作为目标。
- 奖励建模:将奖励建模视为下一标记预测任务,通过自回归方式生成反馈和判断,并使用Softmax函数计算“是”和“进行中”标记的概率来估计软奖励。
评估基准
为了评估PRM的性能,研究团队引入了WebRewardBench基准。该基准通过收集用户指令和相应的专家轨迹,构建偏好对,并要求模型为每个候选动作分配奖励。评估指标包括平均倒数排名(MRR)、步骤准确率(Acc.step)和轨迹准确率(Acc.traj),以衡量模型在步骤级别和轨迹级别上分配奖励的准确性。
研究结果
模型性能
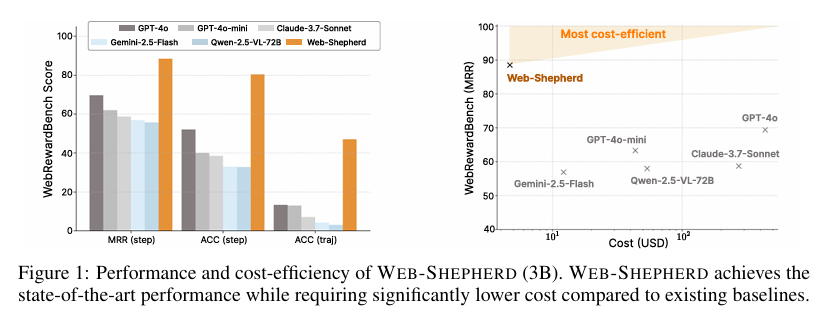
实验结果表明,Web-Shepherd在WebRewardBench基准上显著优于基于MLLM的奖励模型。具体而言,Web-Shepherd(3B)在MRR指标上达到了87.6%,远高于GPT-4o-mini的47.5%和GPT-4o的56.9%。在步骤准确率和轨迹准确率方面,Web-Shepherd也表现出色,显著高于其他基线模型。
成本效益
在WebArena-lite基准上的测试表明,使用GPT-4o-mini作为策略,Web-Shepherd作为验证器时,性能比使用GPT-4o-mini作为验证器提高了10.9分,同时成本降低了10倍。这一结果证明了Web-Shepherd在保持高性能的同时,具有显著的成本效益优势。
案例分析
通过对成功和失败案例的定性分析,研究团队发现Web-Shepherd能够为代理提供有价值的反馈,引导其向成功导航迈进。在成功案例中,奖励分数随时间稳步增加;而在失败案例中,奖励曲线相对平坦。此外,研究还揭示了代理失败的三个主要原因:动作推理错误、观察状态误解和清单生成幻觉。
研究局限
尽管Web-Shepherd在评估网络导航轨迹方面表现出色,但研究仍存在一些局限性:
-
坐标基础动作的支持:目前的研究尚未扩展到支持坐标基础动作(Coordinate-Based Actions),这类动作允许代理通过直接输入坐标与数字环境交互,而无需额外的后端程序转换动作。这一方向超出了当前工作的主要范围,因此留待未来研究探索。
-
强化学习中的应用:将Web-Shepherd作为强化学习中的奖励信号是一个有趣的研究方向,但这需要大量的计算资源,因此留待未来工作探索。研究团队计划调查PRM的奖励信号是否能提高学习效率以及在现有基准上的最终性能。
-
基础模型的选择:虽然当前实现的Web-Shepherd使用了相对轻量级的基础模型(3B-8B),但该方法与模型无关,可以扩展到更大规模。原则上,Web-Shepherd可以扩展到更强大的基础模型(32B-72B),这可能会进一步提高复杂网络环境中的性能。研究团队将这一扩展留待未来在资源丰富的环境中进行探索。
-
多模态指令:尽管现有网络代理基准中的大多数指令是纯文本的,但某些任务(如VisualWebArena中的任务)结合了文本和图像模态。将Web-Shepherd扩展到处理多模态指令是一个有前景的研究方向,因为这将使代理能够在更复杂和现实的网络环境中操作,这些环境除了文本理解外还需要视觉理解。
未来研究方向
基于当前研究的成果和局限,未来的研究可以围绕以下几个方面展开:
-
强化学习集成:探索将Web-Shepherd作为强化学习中的奖励信号,以调查其是否能提高学习效率和最终性能。这需要大量的计算资源,但有望为网络代理的训练提供更有效的反馈机制。
-
更大规模模型的应用:当前实现的Web-Shepherd使用了相对轻量级的基础模型,未来可以探索将其扩展到更大规模的基础模型上,如32B-72B的模型,以进一步提高在复杂网络环境中的性能。这将需要更多的计算资源和更高效的训练方法。
-
多模态指令处理:随着网络任务的复杂性增加,多模态指令处理将变得越来越重要。未来的研究可以探索如何将Web-Shepherd扩展到处理包含文本和图像的多模态指令,以支持更复杂和现实的网络导航任务。
-
坐标基础动作的支持:坐标基础动作在网络导航中具有重要意义,尤其是在需要精确操作的任务中。未来的研究可以致力于将Web-Shepherd扩展到支持坐标基础动作,以提高其在复杂网络环境中的适应性和性能。
-
安全性和鲁棒性:随着网络代理在现实世界中的应用越来越广泛,安全性和鲁棒性成为不可忽视的问题。未来的研究可以探索如何在Web-Shepherd中融入更多的安全机制,如严格的执行约束、权限控制、人类监督和模型输出的仔细审计,以确保其在部署场景中的安全性和鲁棒性。
综上所述,本研究通过提出Web-Shepherd模型和相关数据集、评估基准,为网络导航领域的过程奖励建模提供了新的思路和方法。未来的研究可以围绕强化学习集成、更大规模模型的应用、多模态指令处理、坐标基础动作的支持以及安全性和鲁棒性等方面展开,以进一步推动网络导航领域的发展和应用。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 30
30 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)