记一次完整的开发需求踩坑填坑记录
最近做了一个客户的excel导数据的需求,客户就一句话,把提供的excel能导入到表里面,说一下我们的表是系统创建的表,然后表有哪些字段,什么格式都定义好了,最终表的数据是存在elasticsearch。也就是mysql的表定义字段与elasticsearch的mapping是对应的。好了交代背景后。我们开始踩坑填坑。客户一句话,工作量可是巨大,所谓无声胜有声说的就是这个吧。秉着工匠精神,自己要对
最近做了一个客户的excel导数据的需求,客户就一句话,把提供的excel能导入到表里面,说一下我们的表是系统创建的表,然后表有哪些字段,什么格式都定义好了,最终表的数据是存在elasticsearch。也就是mysql的表定义字段与elasticsearch的mapping是对应的。好了交代背景后。我们开始踩坑填坑。
客户一句话,工作量可是巨大,所谓无声胜有声说的就是这个吧。秉着工匠精神,自己要对自己做的产品负责啊。然后巴拉巴拉写了一个story
前端部分:
step1
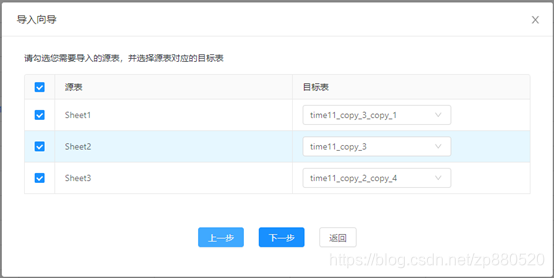
step2
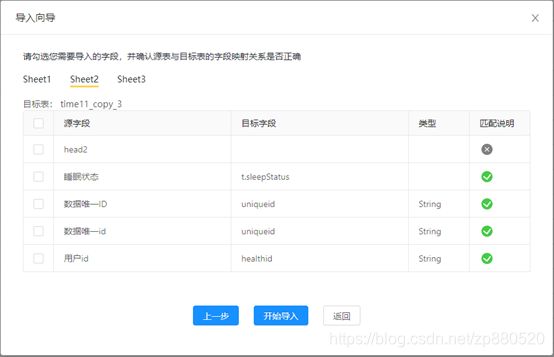
定义交互的数据结构
大概需要这些
{file,data:[{sheetName,tableName,fieldMapping:[{seqNo,field},{seqNo,field}]}]}
设计比较简单也比较直观,解释下就是到后端的数据结构,至少需要这些元素:
file:excel文件 这个好理解,因为涉及安全,存储空间等问题,所以准备将文件存文件服务(典型的OBS/OSS/S3),这里我选择了OBS.
data:前端一顿操作后的数据,包括sheet页对应哪张表以及哪些字段
后端部分:
1 少不了的参数校验
2 文件扔OBS
3 记录一张任务表
4 给前端返回结果(注意是该操作的结果,不是导数据的结果)
5 开启定时任务处理任务表
针对异步设计,前端增加了每5秒定时查询状态的操作,来返回该次导入数据的结果
最后说一下有哪些坑:
1 大数据量
elasticsearch 数据拷贝(reindex),涉及大数据可能就拷不动了,当时有一个索引大概有一亿多数据了,查询都费劲,也没有什么好办法,最后是将该索引拆分,利用索引别名,建立子索引(个人理解)
顺便说一下 reindex支持查询任务状态,5秒轮询用的就是这个能力.
2 有时候数据很少, 前端5秒轮询体验不好,可能实际1秒不到就完成了,白白等了4秒,加了一个逻辑,定时任务内查询一下数据量,增加一个配置项10000,数据量大于10000的5秒,小于的1秒.其实感觉也不好,时间紧迫(其实是偷懒)..个人感觉可以用websocket,前后端保持一个通信,这样结果就会及时反馈,但是也要设计一下超时,过了超时时间就转5秒轮询.
差不多这样 ,后续看心情要不要详细写前端实现或者后端实现

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)