手摸手的RAG速成:RAG系统基本介绍
这份文档好就好在,它没有上来就给你堆一堆数学公式讲什么高维空间,而是直接通过代码和图解,把 RAG(检索增强生成)这个被吹上天的概念,还原成了最朴素的工程问题。
最近看了一份很不错的教程:《A Crash Course on Building RAG Systems》,作者是 Akshay Pachaar 和 Avi Chawla。
这份文档好就好在,它没有上来就给你堆一堆数学公式讲什么高维空间,而是直接通过代码和图解,把 RAG(检索增强生成)这个被吹上天的概念,还原成了最朴素的工程问题。
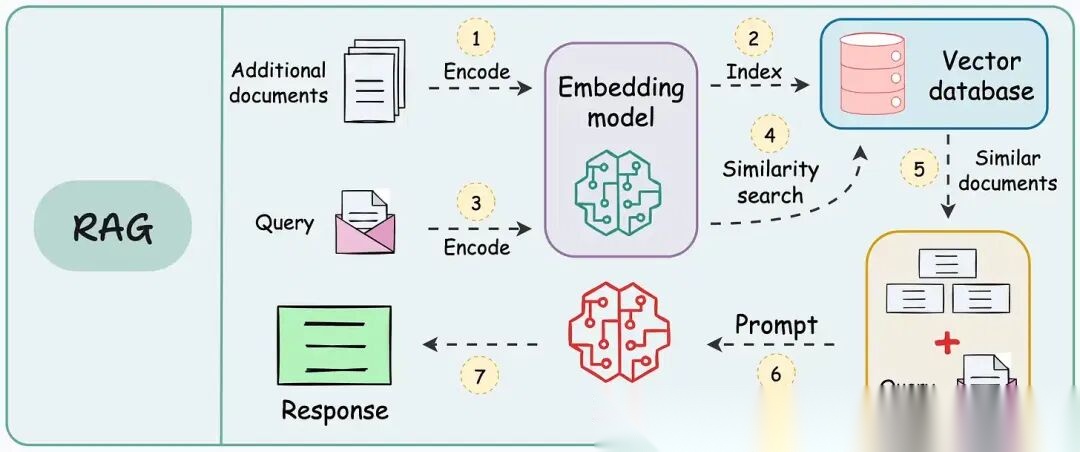
我们之前聊过很多次 RAG,今天借着这份资料,咱们不聊虚的,直接从原理到代码,把这套流程彻底跑通。看完你会发现,RAG 其实非常简单。
一、为什么我们需要 RAG?
先说痛点。大模型(LLM)有两个致命毛病:
- 知识冻结:模型训练完那天,它的脑子就停在那一刻了。它不知道时事新闻、最新数据,因为它没见过。
- 幻觉:就是说胡话。再好的模型,随着上下文增长也会出现幻觉,这是Attention机制所不能避免的。。
要解决这个问题,最笨的方法是微调(Fine-tuning),但这玩意儿成本高得离谱,而且你今天调完,明天数据又更新了,模型还更好,难道换模型重新调?企业亏麻了。
所以,RAG(Retrieval-Augmented Generation)应运而生。
它的逻辑简单粗暴:既然脑子记不住,那就给它一本参考书。
在回答问题前,搜索知识库中的相关内容,把找到的内容(Context)和问题一起扔给模型,让 LLM 根据参考资料回答。
二、核心概念:向量数据库(Vector Database)
要实现 RAG,绕不开一个东西:向量数据库。
计算机不认识字,它只认识数字。我们需要把文字、图片变成一串数字(Vector/Embedding)。神奇的地方在于,经过 Embedding 模型处理后:
- “苹果”和“梨”的向量距离很近。
- “苹果”和“卡车”的向量距离很远。

(图注:这就是语义空间,意思相近的东西会聚在一起)
传统数据库查关键词(比如 SQL 的 LIKE),向量数据库查的是意思。哪怕你搜“红色的水果”,它也能给你找出“苹果”,虽然字面上完全不匹配。而神奇的是这些代表“语义”的数字,竟然是可以像数学题一样进行加减运算的!
最经典的案例就是:国王 - 男人 + 女人 ≈ 女王。
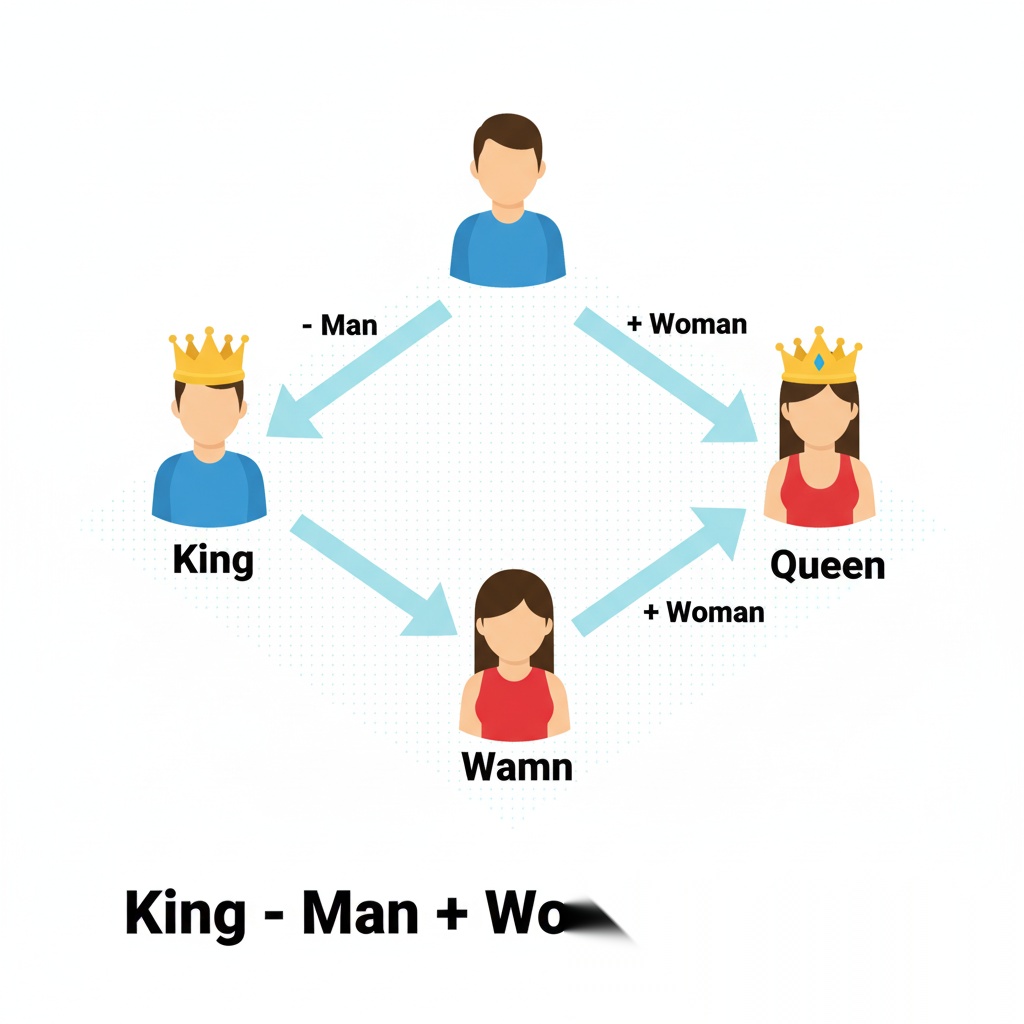
神奇的是,这是完全基于词汇向量的加减法进行的推理。所以说,语言所承载的信息本身可能就是一种智慧。。。
三、RAG 的“洋葱模型”:从数据到答案
结合文档内容,一个标准的生产级 RAG 流程,其实就是把数据掰开揉碎了,存进去,再读出来的过程。
我们可以把它拆解为 9 个步骤。不过实际项目中你就会发现,这里面全是脏活累活。。。
第一阶段:数据准备
**1. 切块(Chunking):**第一步是把你的文档(PDF、Word、网页)清洗干净并切成小块。
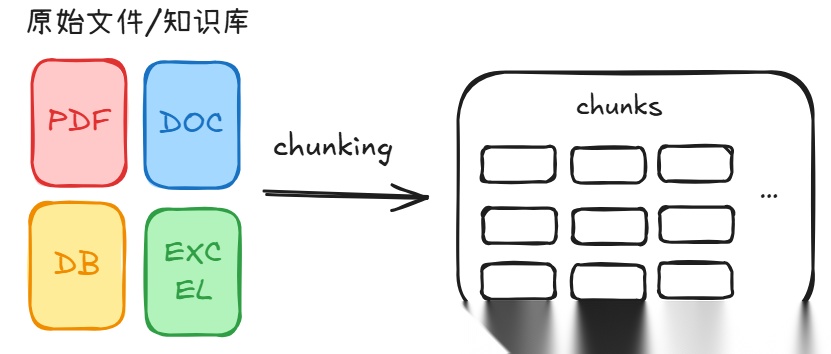
为什么要切?
-
TOKEN长度有限:整本书塞进去,Token 瞬间爆炸,模型直接死机。
-
语义稀释:一段话只讲一个知识点,检索才准。和做饭一样,语料太多混在一起,十三香一样,模型根本搞不清它是什么味。
-
PS:1.切块策略(固定大小、语义分割)策略很多,是 RAG 效果好坏的第一道生死线,之后会详细写一篇文章说明。2.数据清洗是也是工程中极具挑战性的问题,甚至是最费时间的,比切块还麻烦。本文优先介绍RAG。
2. 向量化(Embedding):切好块后,用 Embedding 模型把这些文字块变成向量(一串数字),作为这段文字的提纲(向量版)。 这里用的不是简单的词匹配,而是上下文嵌入模型(比如双向编码器)。
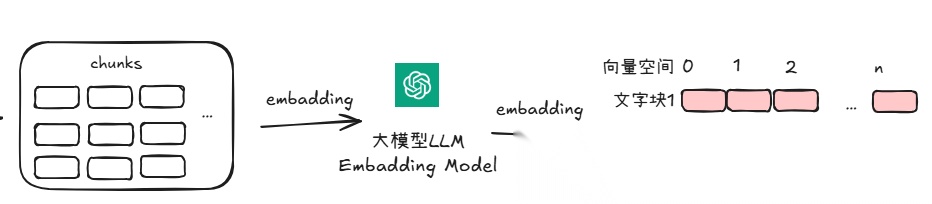
它能听懂“人话”,知道“苹果”和“手机”在某些语境下是相关的。
3. 入库(Indexing):把生成的向量存进向量数据库(Vector DB)。 这是 RAG 的长时记忆机制来源。
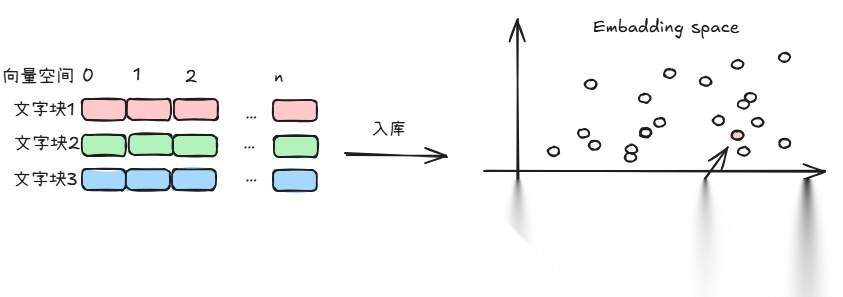
至此,矢量数据库已创建完成。
注意,这里存的不仅仅是向量,还有原始文本和元数据(比如页码、作者)。这样系统就可以基于向量指针,搜索并引用原文。不然搜出来一堆数字。。。
第二阶段:检索工程
4. 用户查询(Query)
用户:“ 表面亲和度是什么意思?出处是哪个文件?”
背景资料:{chunks}问题:{query}请根据背景资料回答问题。
5. 需求翻译(Query Embedding)系统得把用户的这句人话,用同一个 Embedding 模型,也转换成向量。

**注意:必须是同一个模型,**不然就像用英语字典查中文,幻觉会非常严重。
6. 粗筛(Retrieval):拿着用户问题的向量,去数据库里比对。 数据库会通过“近似最近邻搜索”(ANN),给你返回 Top-K 个最像的文本块。 这一步叫召回。

7. 精排(Reranking):这一步很多教程都没讲! 这是区分 Demo 和生产级系统的关键! 向量检索(第6步)虽然快,但有时候不够准。
具体表现为:
- 相关性不佳: Top 1 的结果通常没问题,但 Top 2-5 的结果相关度非常随机。这直接影响了最终给大模型(LLM)参考的上下文质量。
- ANN算法的精度损失(随机性):为了在大规模数据(百万/千万级)中实现毫秒级检索,向量数据库通常使用 ANN(近似最近邻) 算法,其机制引入了随机性,导致召回的文档排名并不完全准确,最相关的文档可能没有排在最前面。
所以,我们需要一个更聪明的模型(通常是 Cross-Encoder),把捞回来的这些知识素材,重新打个分,把真正最相关的排到前面。

Rerank 通过 **“粗排 + 精排”** 的两阶段策略,在速度和精度之间找到了平衡:根据Rerank模型计算出的精准分数,对文档重新进行排序,最后截取分数最高的 Top N(例如Top 5)投喂给大模型。
这个过程会重新排列数据块,以便优先处理最相关的数据块,从而生成响应。
虽然这一步会增加一点延迟,但为了准确率,这是必须要做的。。。
第三阶段:结果生成
**8. 生成结果(Generation)**系统把排好序的最相关文本块(Context),填进 Prompt 模板里,连同用户的问题,一起扔给大模型(LLM)。

这时候,大模型就不再是瞎编了:
★
“根据以下资料(我们找出来的),回答用户的问题…”
而后,模型综合这些上下文,生成一句通顺的人话,交给用户端。
总结一下:前三步是脏活累活(数据工程),中间两步是搜索技术(检索工程),最后一步才是AI 生成。
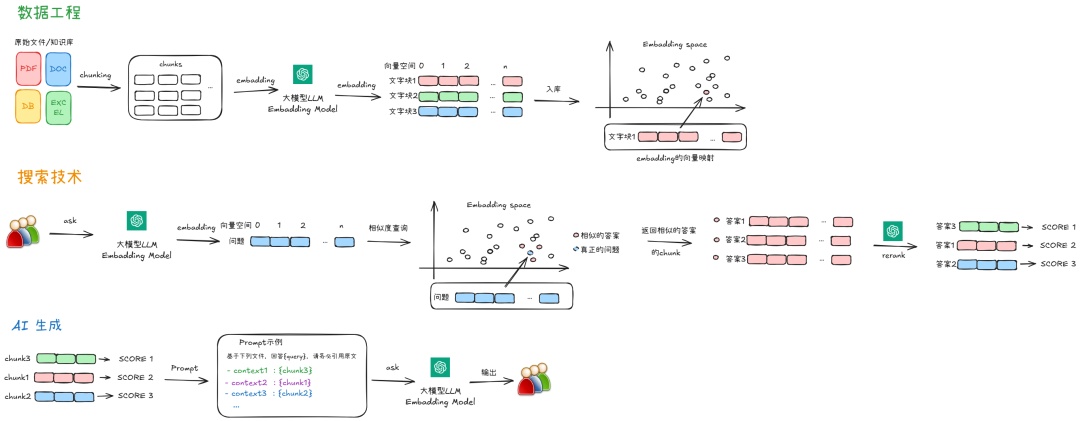
RAG也好,AI也好,别光盯着最后的大模型看,没有数据科学的基本功,后面全是幻觉。。。
四、动手实战:全开源技术栈
光说不练假把式。文档里给了一套完全开源的方案,大家可以在自己的笔记本上跑起来试一试。
工具栈:
- 大脑 (LLM): Llama 3.2 (通过 Ollama 运行,轻量级)
- 框架 (Framework): LlamaIndex (专门做 RAG 的框架)
- 记忆 (Vector DB): Qdrant (开源向量库,Docker 一键起)
核心代码解析:
首先,用 Docker 启动 Qdrant:
docker run -p 6333:6333 -p 6334:6334 \ -v $(pwd)/qdrant_storage:/qdrant/storage \ qdrant/qdrant
然后,用 LlamaIndex 加载数据并建立索引。这一步就是把 PDF 变成向量存进去:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.vector_stores.qdrant import QdrantVectorStore# 1. 读文件(脏活)documents = SimpleDirectoryReader("./docs").load_data()# 2. 连数据库vector_store = QdrantVectorStore(client=client, collection_name="chat_with_docs")# 3. 建索引(自动完成切块、Embedding、存储)index = VectorStoreIndex.from_documents( documents, storage_context=storage_context)
最后,查询并加入重排(Reranking)。这里用了一个 SentenceTransformerRerank,虽然慢点,但精度提升巨大:
from llama_index.core.postprocessor import SentenceTransformerRerank# 设置重排模型rerank = SentenceTransformerRerank( model="cross-encoder/ms-marco-MiniLM-L-2-v2", top_n=3# 只取前3个最相关的)# 查询引擎query_engine = index.as_query_engine( similarity_top_k=10, # 先捞10个 node_postprocessors=[rerank] # 再精选3个)response = query_engine.query("What exactly is DSPy?")print(response)
代码跑通,你会发现模型能准确回答出 PDF 里的内容,此时恭喜你通过代码搭建了RAG 的最小应用!
泼盆冷水:RAG 的局限性
虽然 Demo 跑通了很爽,但作为工程实战派,我得提醒大家几个坑,文档最后也提到了,非常真实:
- 语义稀释(Semantic Dilution): 如果你的切块太大,里面混杂了无关信息,检索精度会直线下降。
- 聚合类问题(Aggregation)是死穴: 如果你问这100份文档里,哪一份提到的销售额最高? RAG 通常回答不出。因为向量检索是找相似,而不是做统计。它很难把所有文档扫一遍再比较。
- 中间迷失(Lost in the Middle): LLM 有个毛病,它对 Prompt 开头和结尾的内容印象深刻,中间的内容容易忽略。所以重排后的文档顺序也很重要。
- 问题与答案不相似: 有时候用户问的问题,和文档里的答案在字面上完全不沾边。这时候可能需要引入 HyDE(假设性文档嵌入)这种高级技巧,让模型先自己生成一个假答案,拿假答案去搜真答案。
最后
在真实的企业级AI项目中,我们 80% 的时间其实不是在调大模型,而是在清洗数据和优化检索策略。AI系统的本质依然是数据工程系统。你可以把大模型理解成一个考试的考生,而RAG、数据工程,是背后那个递小抄的人。
RAG 可以让大模型进行开卷考试,而我们要做的所有工程上的努力,就是确保在它提笔作答前,把书翻到了最正确的那一页。
Tips: RAG知识点很多,后续会继续更新。
欢迎加我好友,围观我的AI落地日常。不定期分享最新的论文解读、工程避坑指南,偶尔吐槽,长期干货,一起在AI时代加油。这篇 RAG 教程虽然是入门级的,也是耗费了很大的精力整理的,大佬们如果看到了最后,欢迎一键三连,点点关注和转发,笔者这里谢谢大家了!!
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献573条内容
已为社区贡献573条内容

所有评论(0)