一、大语言模型(LLM)理解
大语言模型(LLM)是基于Transformer架构的深度神经网络,以其超大规模参数量(数百至数千亿)和海量训练数据著称。核心应用包括文本生成、机器翻译、内容创作等,但通用模型在专业领域存在局限。构建LLM需经历三阶段:基础模型预训练、数据集准备、针对性微调(指令微调或分类微调)。Transformer通过自注意力机制捕捉长距离语义依赖,其编码器-解码器结构能有效处理输入文本并生成连贯输出,这正是
《从零构建大模型》笔记记录
三、LLM自注意力机制_selfattention机制 llm-CSDN博客
1、LLM概念
大语言模型是一种用于理解、生成和响应类似于人类语言文本的深度升级网络。
大语言模型之所以被称为“大”,体现在模型训练时所需要的庞大数据集,以及网络模型本身具有超大规模的参数。这种模型通常含有数百亿甚至数千亿个参数,数据集方面,例如用于训练GPT-3的数据集包含3000亿个词元;Meta的Llama的训练范围包含了Arxiv研究论文(92GB)和StackExchange上的代码问答(78GB)。
2、LLM的应用
大语言模型已经被广泛应用到各个领域,例如机器翻译、文本生成、情感分析、文本摘要,还有被用于内容创作,如撰写文章、小说和生成计算机代码等。在搜索领域和聊天机器人也能提供有效支持,等等。
3、构件大语言模型概要
像类似于ChatGPT这样的通用型大语言模型虽然具有更广泛的应用范围,但是在数据隐私、专业特定领域上的表现有所欠缺,这时候就需要根据需求定制大模型。
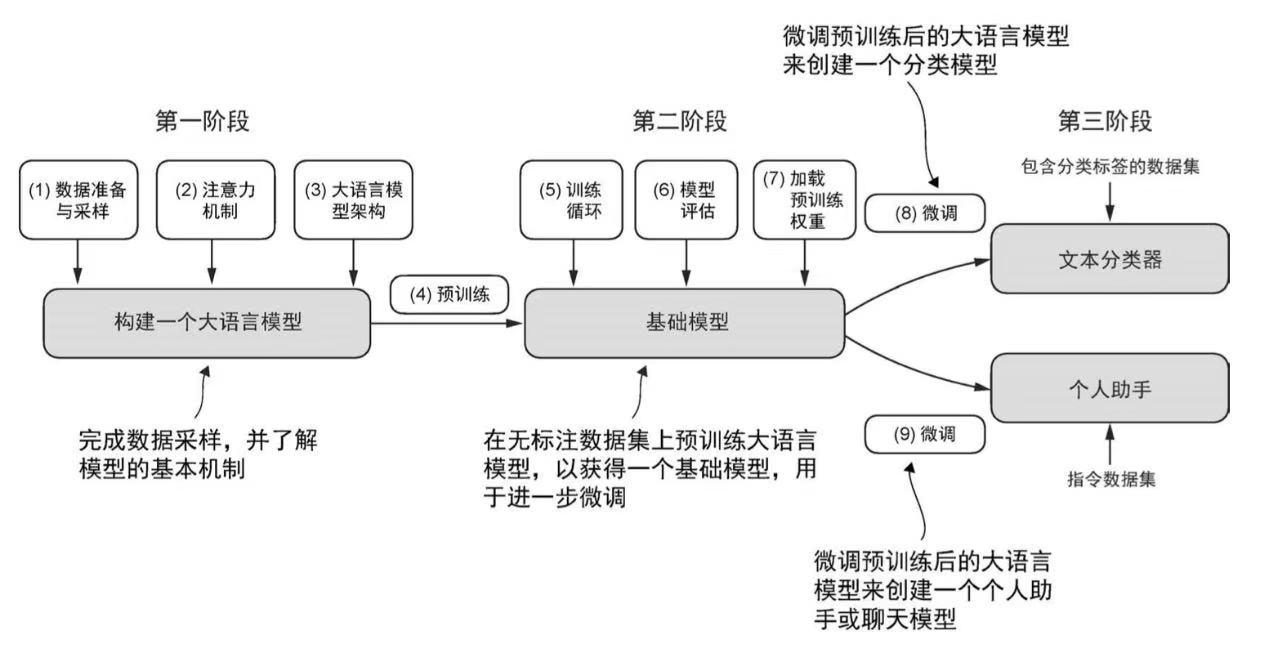
构件大语言模型整体分成三个阶段:
- 实现模型结构和准备数据集
- 在数据集上预训练基础模型
- 根据特定任务微调基础模型
微调大语言模型最流行的两种方法:指令微调和分类任务微调。指令微调中数据集由“指令-答案”对组成(如翻译任务的“原文-正确翻译文本”);分类任务微调中数据集由文本及类别标签组成(如标记为垃圾邮件和非垃圾邮件的电子邮件文本)
4、Transformer架构介绍
目前的大语言模型通常采用了Transformer架构,这种架构在模型进行预测时有选择地关注输入文本的不同部分,从而使得它们特别擅长应对人类语言的细微差别和复杂性。
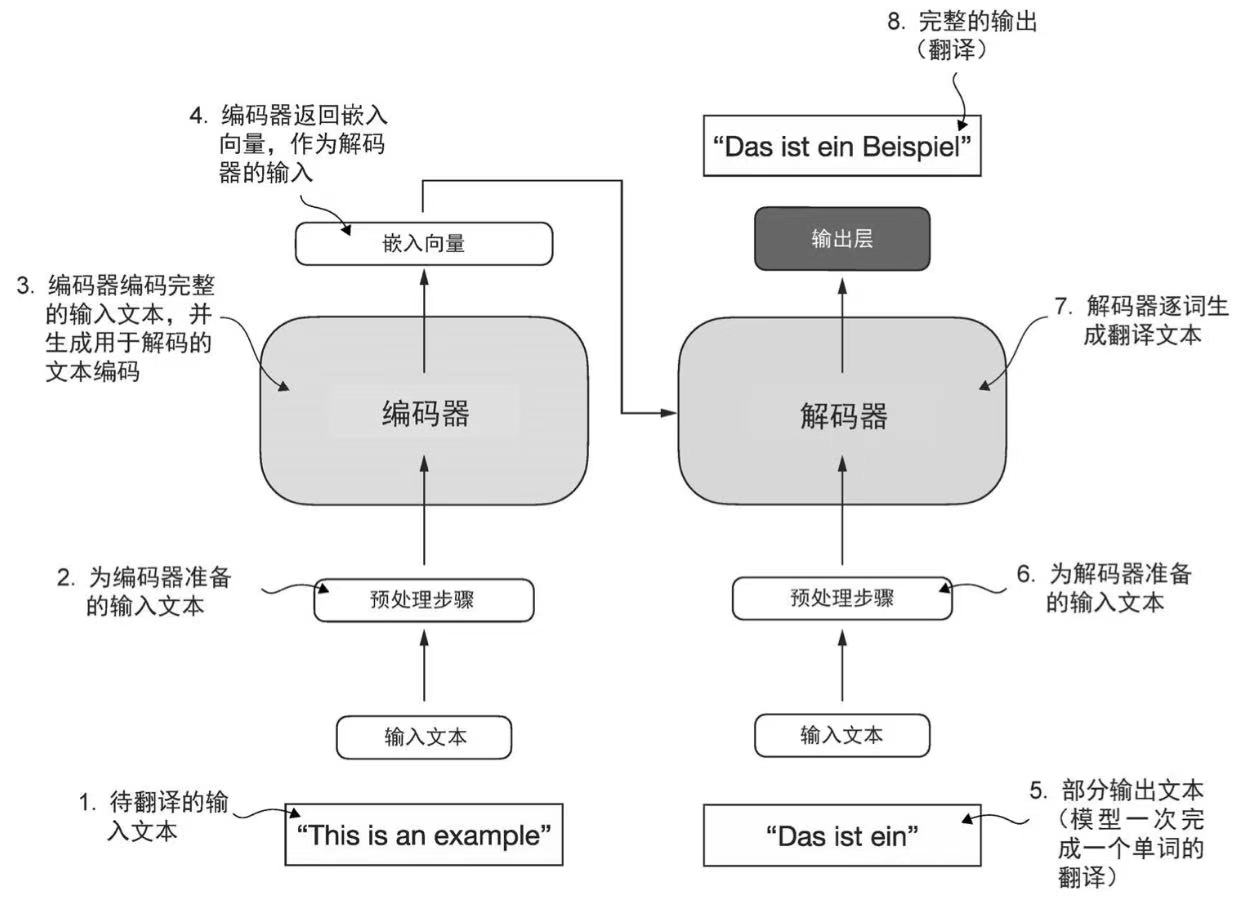
大语言模型的本质是不断重复预测下一个词是什么。上图给出了Transformer在做文本翻译时的一个简化步骤。其主要由编码器和解码器两个部分组成,编码器(encoder)负责处理输入文本,将其编码为一组数值表示或向量,以捕获输入文本的上下文信息。解码器(decoder)接收编码向量,并生成输出文本。
Transformer的关键组件在于自注意力机制(self-attention),它可以衡量序列中不同单词或者词元之间的相对重要性。这一机制使得模型能够捕捉到输入数据中长距离的依赖和上下文关系,从而提升其生成连贯且上下文相关的输出的能力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)