首篇基于强化学习的Agentic Search最新综述!
同时课程详细介绍了。
本文系统概述了基于强化学习的智能体搜索技术,提出三维分析框架:功能角色(What)、优化方法(How)和应用范围(Where)。详细介绍了检索控制、查询优化等五大核心角色,以及从SFT冷启动到自我进化的训练范式。构建了覆盖多领域的评估体系,并展示了在文献综述、多模态搜索等实际应用,为研究者和开发者提供了全面指导。
首次对基于强化学习的智能体搜索(RL-based Agentic Search)进行了全面概述:基础、角色、优化、评估与应用

不同survey的对比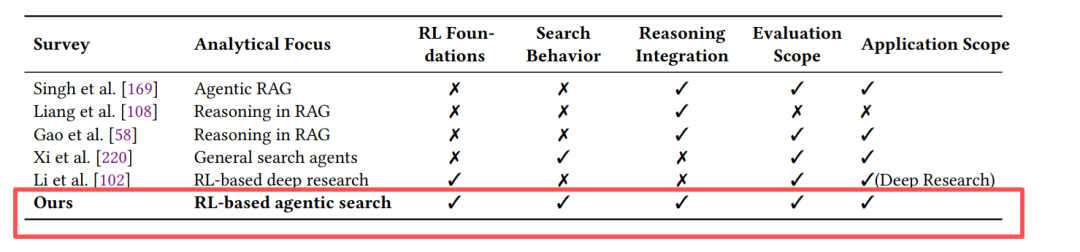
从"工具"到"决策者"的范式跃迁
传统RAG(检索增强生成)系统就像一个"图书馆借书机器人"——用户提问,它检索一次,生成答案,任务结束。但真实世界的复杂问题往往需要多轮推理、动态调整、策略规划。这正是Agentic Search的用武之地:
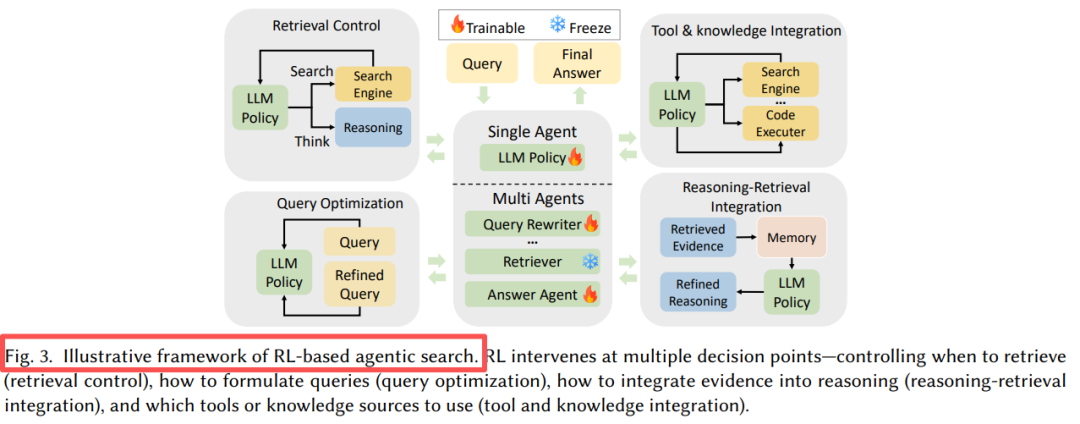
智能体搜索通过将LLM构建为一个自主决策的智能体,从而超越了RAG。模型不再是被动地使用检索到的文档,而是主动决定何时、何地以及如何搜索…
论文开篇就点明了核心痛点:LLM面临静态知识、幻觉问题,而传统RAG又是单次、启发式的。RL的引入让智能体能够通过试错自我改进,实现了从"被动检索"到"主动决策"的质变。
核心框架:RL赋能搜索的三维空间
论文提出了一个极具洞察力的分析框架,将RL在智能搜索中的作用解构为三个互补维度:

三维分析框架
这三大维度构成了我们理解这个领域的"黄金三角":
- What RL is for: RL的功能角色(决定何时搜、如何搜)
- How RL is used: 优化策略(奖励设计、训练方法)
- Where RL is applied: 优化范围(Agent级/模块级/系统级)
What - RL扮演什么角色?
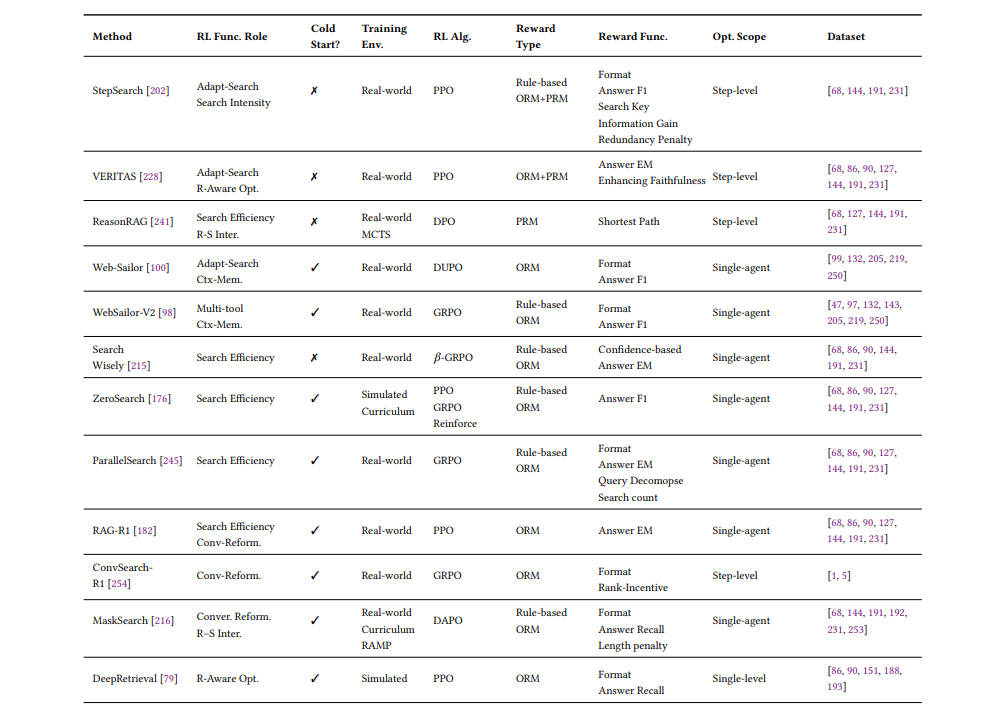
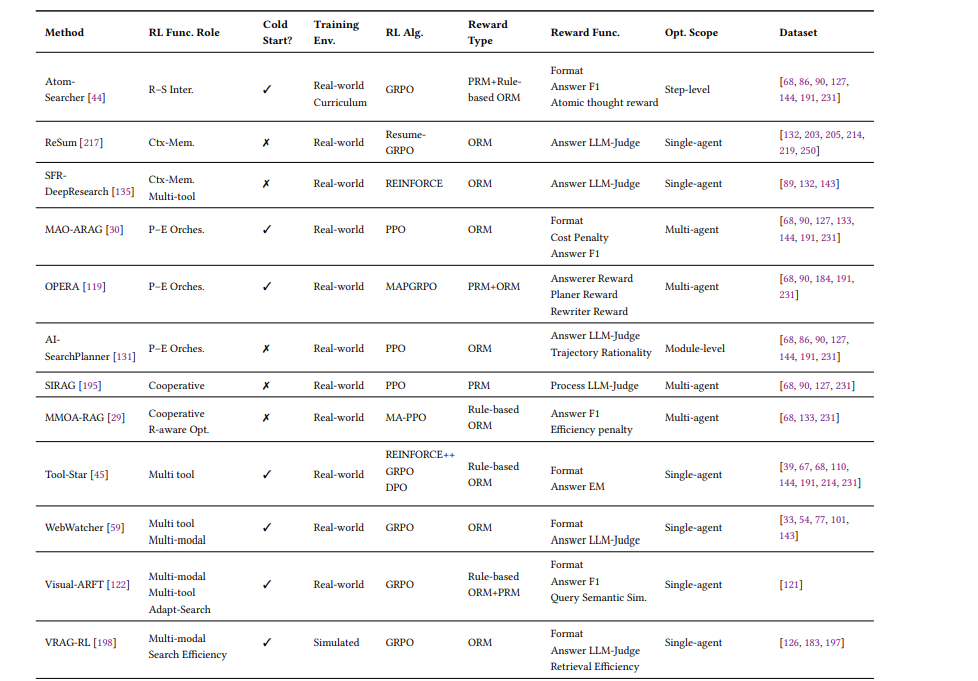
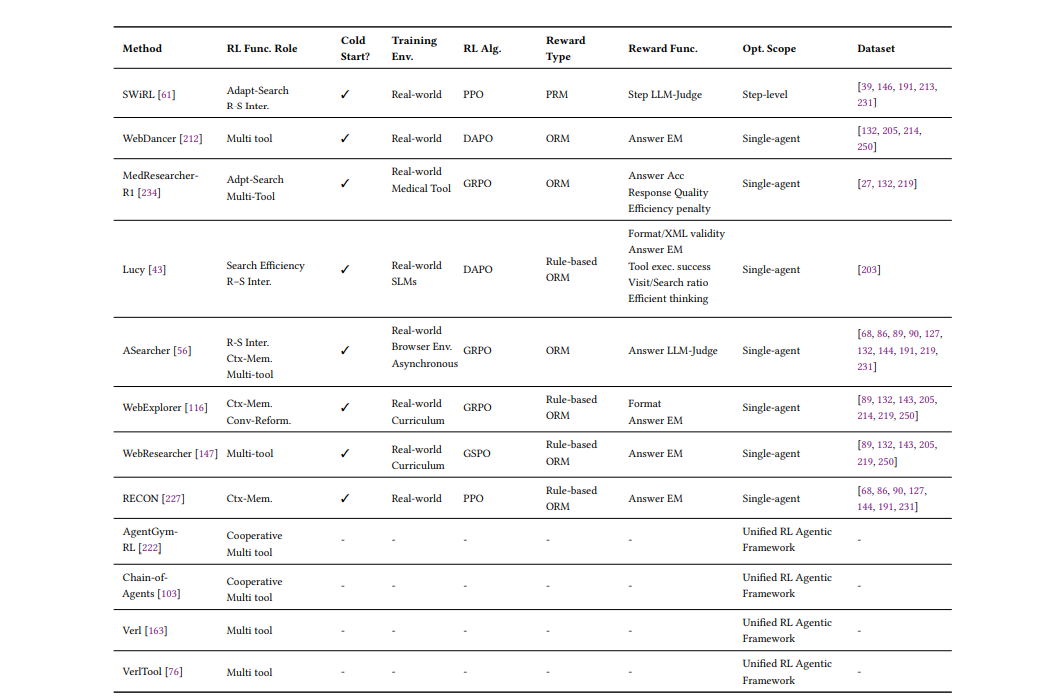
这部分是整篇综述最精彩的内容。作者将RL的功能角色归纳为五大核心类别,并提供了详细的分类表:检索控制、查询优化、推理-检索融合、多智能体协作、工具知识整合
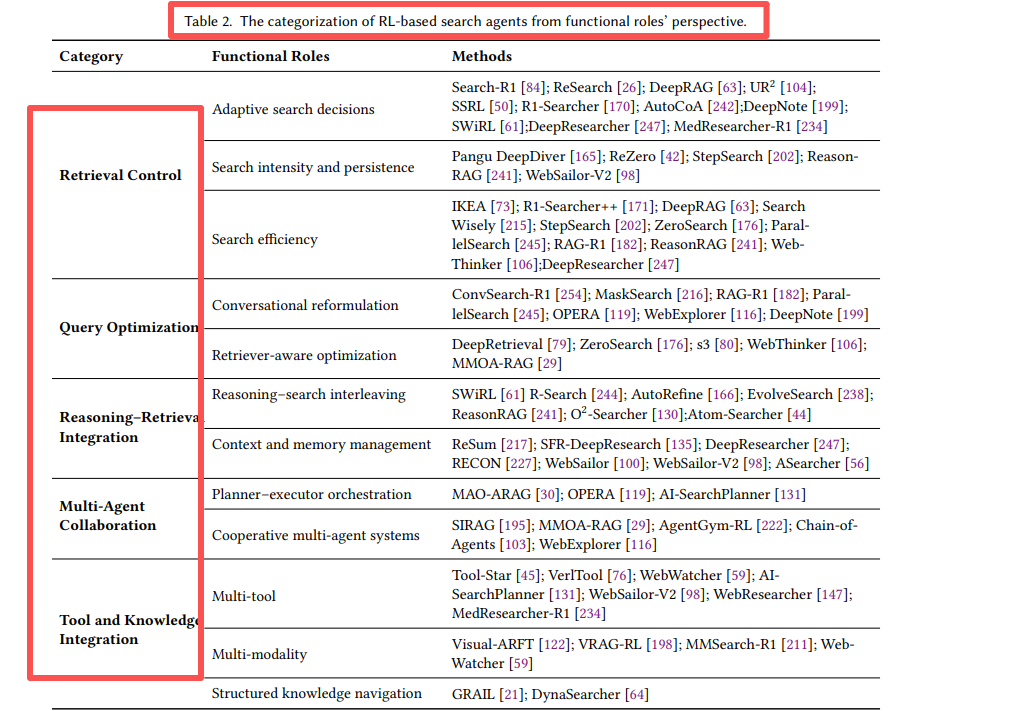
3.1 检索控制:让搜索变得"聪明"
传统RAG不管需不需要都会检索,而RL训练的智能体会自主判断:
- Search-R1学会了只在内部知识不足时才调用搜索引擎
- DeepRAG将复杂查询分解为原子子查询,逐个决策
- IKEA引入知识边界感知奖励,鼓励优先使用内部知识
关键洞察是:搜索不是越多越好,而是在正确的时间做正确的搜索。
3.2 查询优化:会说才会搜
用户提问往往是模糊的,RL让智能体学会"翻译":
- ConvSearch-R1通过Rank-Incentive奖励,让改写后的查询能检索到更高排名的相关文档
- DeepRetrieval训练LLM生成符合特定搜索引擎偏好的查询(就像"黑进"搜索引擎)
3.3 推理-检索融合:边想边搜,边搜边想
这是Agentic Search的核心优势——推理与检索的闭环:
- AutoRefine奖励"搜索-思考-精炼"的迭代过程
- ReSum训练智能体主动总结历史交互,避免上下文溢出
3.4 多智能体协作:分工的艺术
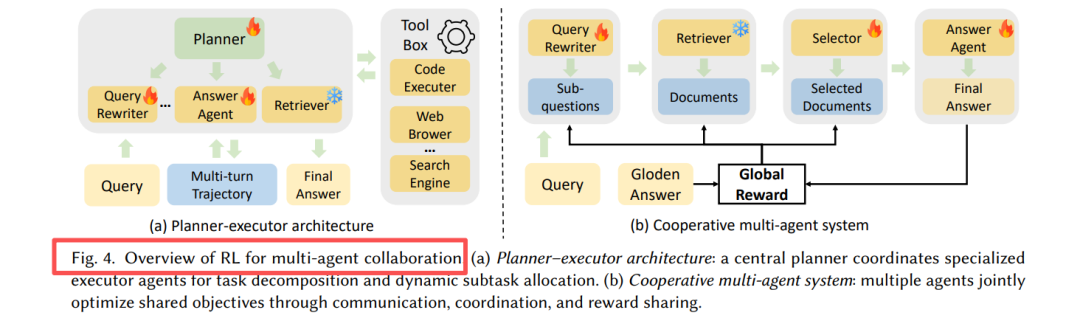 两种架构:
两种架构:
- 规划-执行架构:高层规划器协调专业执行器(查询重写、文档选择)
- 合作多智能体:各模块作为独立RL智能体,共享全局奖励
OPERA采用分级RL,为规划、分析、改写代理提供定制化奖励信号。
⚙️ 第二维:How - RL如何优化?
4.1 训练范式:从冷启动到自我进化
标准流程是:SFT冷启动 → RL微调。但创新点在于:
- ZeroSearch完全放弃SFT,在潜在空间模拟检索,实现纯RL训练
- AgentGym-RL通过课程学习逐步扩展交互时长,从短任务到多步推理
- EvolveSearch开创自我进化循环:RL生成高质量轨迹 → 蒸馏为SFT数据 → 再RL训练
Search-R1的标准提示模板,要求模型先推理再搜索:

4.2 奖励设计:从结果到过程的精细化
奖励函数从单一到多维的演进:Outcome、Process
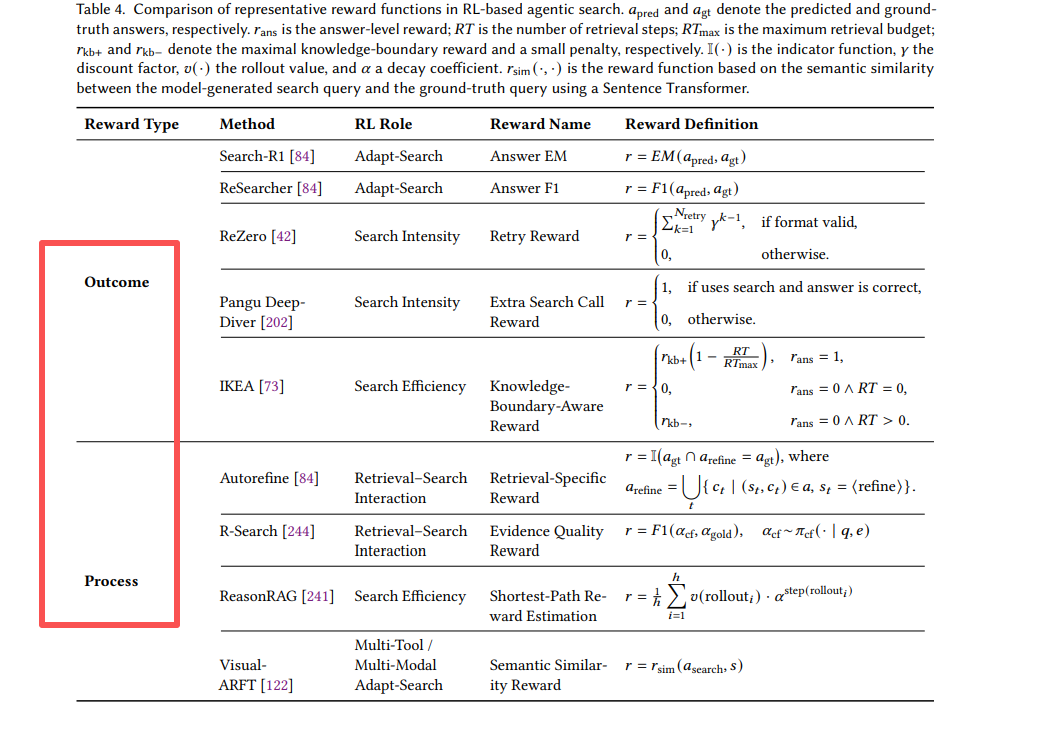
核心教训:有效代理需要平衡最终准确性与中间行为质量。
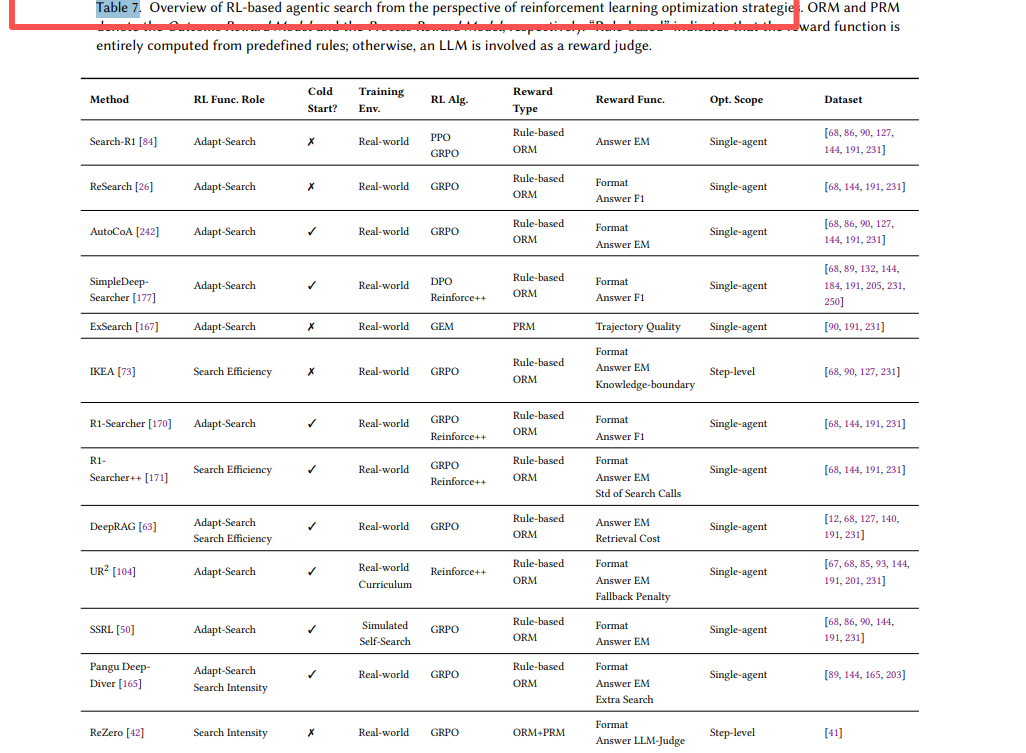
从强化学习优化策略视角看基于RL的智能体搜索概览。
第三维:Where - RL优化哪里?
将优化范围分为三级:Agent级、模块/步骤级、系统级

模块级优化的优势是无需重训大模型,如s3仅训练一个轻量搜索模块。而系统级框架如VerlTool提供统一接口,支持跨模态工具训练。
评估体系:如何衡量智能搜索?
6.1 数据集全景
列出了覆盖6大类的评估基准: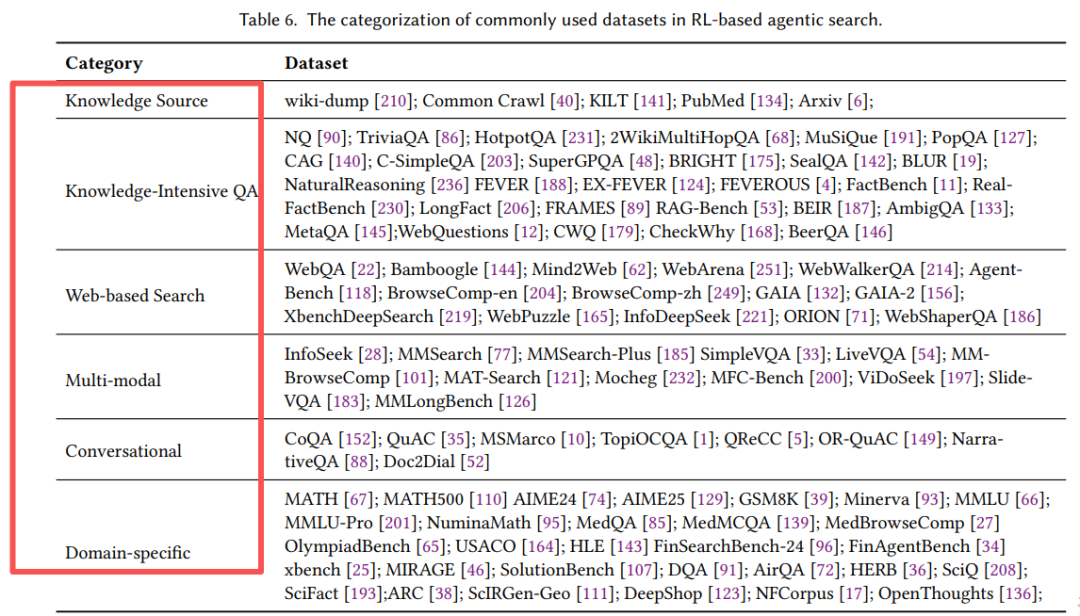
- 知识密集型QA: HotpotQA, 2WikiMultiHopQA(多跳推理)
- 网页搜索: GAIA, Mind2Web(真实浏览器环境)
- 多模态: InfoSeek, MM-BrowseComp(图文混合)
- 对话式: TopiOCQA, QReCC(多轮上下文)
- 领域专用: MATH, MedQA, OlympiadBench
6.2 评估指标
除了传统的EM/F1,Agentic Search需要新指标:
- 搜索效率:查询次数、API成本、响应时间
- 过程质量:信息增益、证据利用率、查询冗余度
- 多样性:O²-Searcher引入多样性奖励避免重复查询
🚀 应用实战:RLAgent正在改变这些领域
- Deep Research: DeepResearcher, MedResearcher-R1实现自动化文献综述
- 多模态搜索: MMSearch-R1, WebWatcher融合视觉与文本理解
- 代码助手: Tool-Star协调搜索、执行、调试工具链
- 对话助手: ConvSearch-R1在多轮对话中保持上下文
- 企业搜索: HierSearch整合本地知识库与网页搜索
从强化学习优化策略视角看基于RL的智能体搜索概览。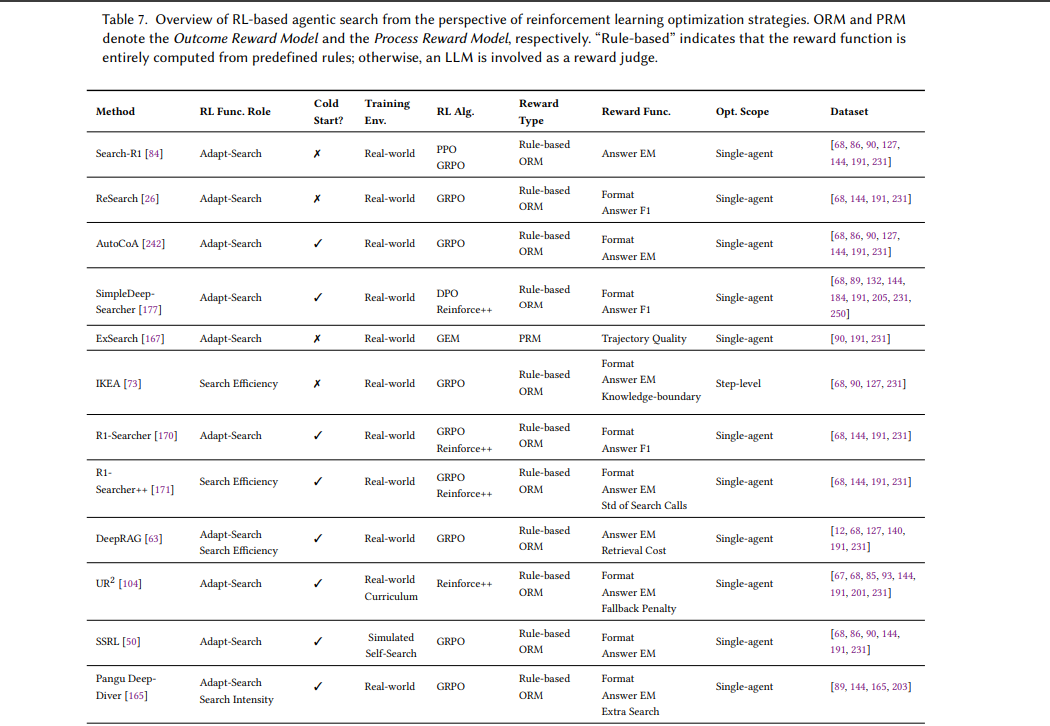
https://arxiv.org/pdf/2510.16724
A Comprehensive Survey on Reinforcement Learning-based Agentic Search:Foundations, Roles, Optimizations, Evaluations, and Applications
https://github.com/ventr1c/Awesome-RL-based-Agentic-Search-Paper
那么,如何系统的去学习大模型LLM?
如果你也想系统学习AI大模型技术,想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习*_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献201条内容
已为社区贡献201条内容

所有评论(0)