【AI论文】开放式生成的逆向工程推理
摘要:本研究提出逆向工程推理(REER)新范式,通过从高质量输出反向推导推理过程,解决开放式生成任务中深度推理的应用难题。研究采用迭代局部搜索算法构建含20,000条推理轨迹的DeepWriting-20K数据集,并基于此训练的DeepWriter-8B模型在多个基准测试中超越开源基线,部分指标媲美GPT-4o等专有模型。该方法突破了传统强化学习和指令蒸馏的局限,为开放式任务推理提供了新思路,但仍
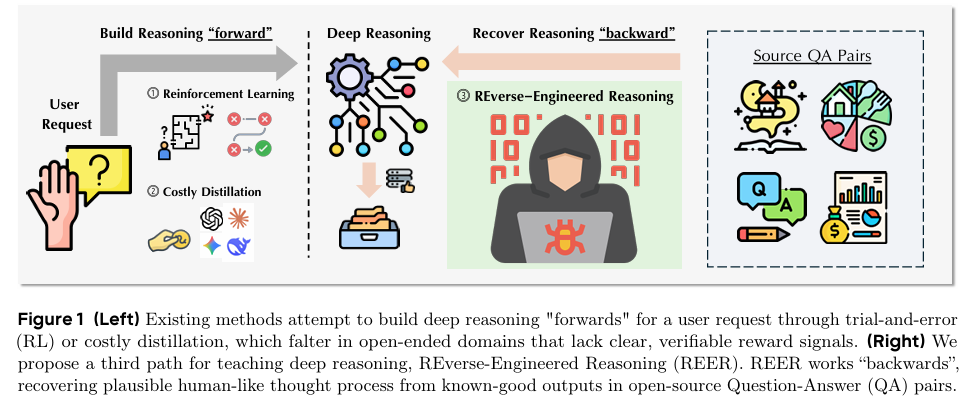
摘要:虽然“深度推理”范式在数学等可验证领域推动了重大进展,但将其应用于开放式、创造性生成任务仍是一个关键挑战。目前,灌输推理能力的两种主流方法——强化学习(RL)和指令蒸馏——在这一领域均表现欠佳;强化学习因缺乏明确的奖励信号和高质量奖励模型而举步维艰,而指令蒸馏则成本高昂且受限于教师模型的能力上限。为克服这些局限性,我们引入了逆向工程推理(REverse-Engineered Reasoning,简称REER)这一全新范式,从根本上转变了推理方法。REER并非通过试错或模仿“正向”构建推理过程,而是从已知的优质解决方案“逆向”推导,以计算方式发现可能生成这些解决方案的潜在、分步的深度推理过程。利用这种可扩展、无梯度的方法,我们策划并开源了DeepWriting-20K数据集,该数据集包含20,000条开放式任务的深度推理轨迹。基于该数据集训练的模型DeepWriter-8B,不仅超越了强大的开源基线模型,还达到了与GPT-4o和Claude 3.5等领先专有模型相媲美、甚至在某些情况下更优的性能。Huggingface链接:Paper page,论文链接:2509.06160
研究背景和目的
研究背景:
随着深度学习技术的快速发展,大型语言模型(LLMs)在多个领域展现了强大的能力,尤其是在需要严格验证的领域,如数学和编程,深度推理(deep reasoning)的应用显著提升了模型的性能。然而,在开放式的、创造性的生成任务中,深度推理的应用仍然面临重大挑战。这类任务通常缺乏明确、可验证的正确答案,其质量评估依赖于主观标准,如原创性、情感共鸣和叙事连贯性。传统的强化学习(RL)和指令蒸馏方法在这种环境下效果不佳。RL方法依赖于清晰的奖励信号来指导模型搜索解决方案空间,但在开放式任务中,构建能够准确反映人类偏好的奖励模型极具挑战性。同时,指令蒸馏方法虽然有效,但成本高昂,且受限于教师模型的能力。
研究目的:
本研究旨在解决在开放式生成任务中引入深度推理能力的难题,提出一种新的范式——反向工程推理(REverse-Engineered Reasoning, REER)。REER通过从已知的高质量输出反向推导出潜在的、逐步的深度推理过程,从而绕过对昂贵奖励模型或教师模型的依赖。具体目标包括:1)开发一种可扩展的、无需梯度的合成方法,用于生成大规模的深度推理轨迹数据集;2)通过该数据集训练模型,使其能够在没有明确奖励信号的情况下,内部化深度推理过程;3)验证该方法在多种开放式生成任务中的有效性和优越性,证明其能够媲美甚至超越现有的专有模型。
研究方法
数据集构建:
研究首先从多个来源收集了多样化的查询-解决方案对(query-solution pairs),包括公共写作平台、公共领域文学作品和公共数据集。通过筛选和整理,最终选择了20,000个高质量的查询-解决方案对,覆盖25个手动提名的类别,以确保广泛的主题覆盖。对于每一对查询-解决方案,研究使用迭代局部搜索算法生成最优的深度推理轨迹。
迭代局部搜索算法:
该算法从一个初始的、不完美的深度推理轨迹开始,通过逐步细化每个轨迹段来优化整体轨迹。在每一步迭代中,算法选择一个轨迹段进行改进,通过提示LLM生成包含更多思考细节、阐述和反思的候选细化轨迹。然后,根据候选轨迹对参考解决方案的困惑度(PPL)进行评估,选择困惑度最低的候选作为更新后的轨迹段。这一过程重复进行,直到解决方案的困惑度达到预定义的目标阈值或达到最大迭代次数。
模型训练:
使用生成的深度推理轨迹数据集对Qwen3-8B基础模型进行微调。为了防止模型在特定领域的过拟合,研究还将从公共数据集中提取的深度推理轨迹与合成数据集混合,形成最终的混合训练数据集。通过这种策略,模型既学习了特定领域的深度推理能力,又保持了广泛的知识先验。
研究结果
数据集贡献:
研究成功构建了DeepWriting-20K数据集,包含20,000个查询-解决方案和深度推理轨迹的三元组,覆盖了25个类别。这一数据集不仅规模庞大,而且多样性丰富,为开放式生成任务的研究提供了宝贵的数据资源。
模型性能:
经过微调的DeepWriter-8B模型在多个基准测试上展现了强大的性能。在LongBench-Write、HelloBench和WritingBench等基准上,DeepWriter-8B不仅显著超越了强大的开源基线模型LongWriter-8B,而且在某些情况下,其性能甚至可以与领先的专有模型如GPT-4o和Claude 3.5相媲美。特别是在LongBench-Write上,DeepWriter-8B的得分超过了GPT-4o和Claude 3.5,表明其在维护长距离连贯性方面具有显著优势。
定性分析:
通过定性分析发现,DeepWriter-8B在生成过程中展现了更为复杂和有条理的思考模式。与基线模型相比,DeepWriter-8B在问题分解、逻辑一致性、分析深度和表达清晰度等方面均有显著提升。特别是在需要深度推理和复杂规划的任务中,DeepWriter-8B的表现尤为突出。
研究局限
尽管REER范式在开放式生成任务中展现了显著的优势,但本研究仍存在一些局限性。首先,数据集的质量和多样性对模型性能有显著影响。尽管DeepWriting-20K数据集规模庞大且覆盖广泛,但仍可能存在某些领域的偏差或不足。其次,迭代局部搜索算法在生成深度推理轨迹时,虽然能够有效降低困惑度,但计算成本仍然较高,尤其是在处理复杂任务时。此外,模型性能高度依赖于基础模型的选择和微调策略,不同基础模型之间的性能差异可能影响最终结果。
未来研究方向
针对上述局限,未来的研究可以从以下几个方面展开:
- 数据集扩展与优化:进一步扩展和优化DeepWriting-20K数据集,增加更多样化和复杂化的查询-解决方案对,以提高模型的泛化能力。同时,探索更有效的数据筛选和过滤策略,以提高数据集的质量。
- 算法改进:研究更高效的轨迹生成算法,减少计算成本并提高生成轨迹的质量。例如,可以探索使用更先进的搜索算法或启发式方法(如遗传算法、模拟退火等)来优化迭代过程。
- 模型优化:研究不同基础模型在微调过程中的表现,探索更有效的微调策略,以提高模型的推理能力和生成质量。同时,考虑将REER范式与其他先进技术(如预训练、多任务学习等)结合,进一步提升模型性能。
- 评估方法:建立更全面和客观的评估体系,以更准确地评估模型性能。除了基准测试外,还可以引入用户反馈机制,及时调整模型以适应用场景。
- 应用场景拓展:将REER范式应用于更多复杂的开放式生成任务中,探索其在不同领域的应用潜力。例如,可以探索其在创意写作、学术写作、功能写作等不同场景下的应用。
- 理论与实践结合:加强与数学、编程等领域的交叉研究,探索REER范式在跨领域的应用,形成更广泛的理论框架和方法论。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 2
2 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)