全量微调 vs LoRA:一篇文章彻底搞懂参数高效微调
当我们拿到一个大语言模型(如Llama、Qwen)时,常常发现它在某些任务上表现不够好。这时候,微调(Fine-tuning)就成了提升模型能力的关键手段。但问题来了:微调一个70B参数的模型,可能需要数百GB显存和数万元成本。有没有更经济的方法?今天我们要讲的LoRA(Low-Rank Adaptation)技术,能让你用不到4%的资源完成微调,效果还不差!这是怎么做到的?让我们从微调的本质说起
引言: 微调很重要,但成本能降96%吗?
当我们拿到一个大语言模型(如Llama、Qwen)时,常常发现它在某些任务上表现不够好。这时候,微调(Fine-tuning)就成了提升模型能力的关键手段。
但问题来了:微调一个70B参数的模型,可能需要数百GB显存和数万元成本。有没有更经济的方法?
今天我们要讲的LoRA(Low-Rank Adaptation)技术,能让你用不到4%的资源完成微调,效果还不差!这是怎么做到的?让我们从微调的本质说起。
微调的本质:改变参数
什么是微调?
简单来说,微调就是:
- 发现模型在某方面能力不足
- 通过训练更新模型参数
- 得到能力提升的新模型
参数是什么?
大模型背后是数十亿、数百亿的参数(本质上就是很多数字)。这些参数通常组织成矩阵形式:
原始参数矩阵:
[0.1 0.2 0.3]
[0.4 0.5 0.6]
[0.7 0.8 0.9]
微调后,这些数字会发生变化:
新参数矩阵:
[0.2 0.1 0.4] ← 0.1变成了0.2
[0.3 0.6 0.5]
[0.8 0.7 1.0]
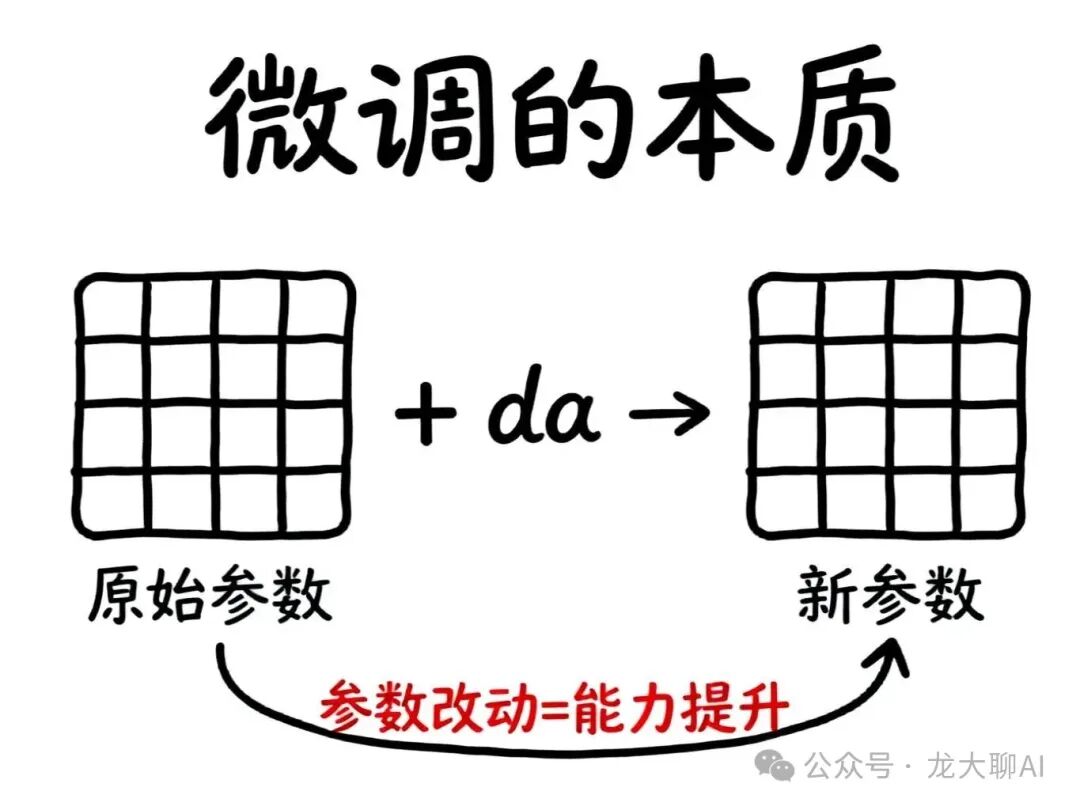
核心洞察:改动量才是关键!
我们可以换个角度看这个过程:
新参数 = 原参数 + 改动量Δ
0.2 = 0.1 + 0.1
0.1 = 0.2 - 0.1
所以,微调的本质就是学习这个"改动量Δ"!

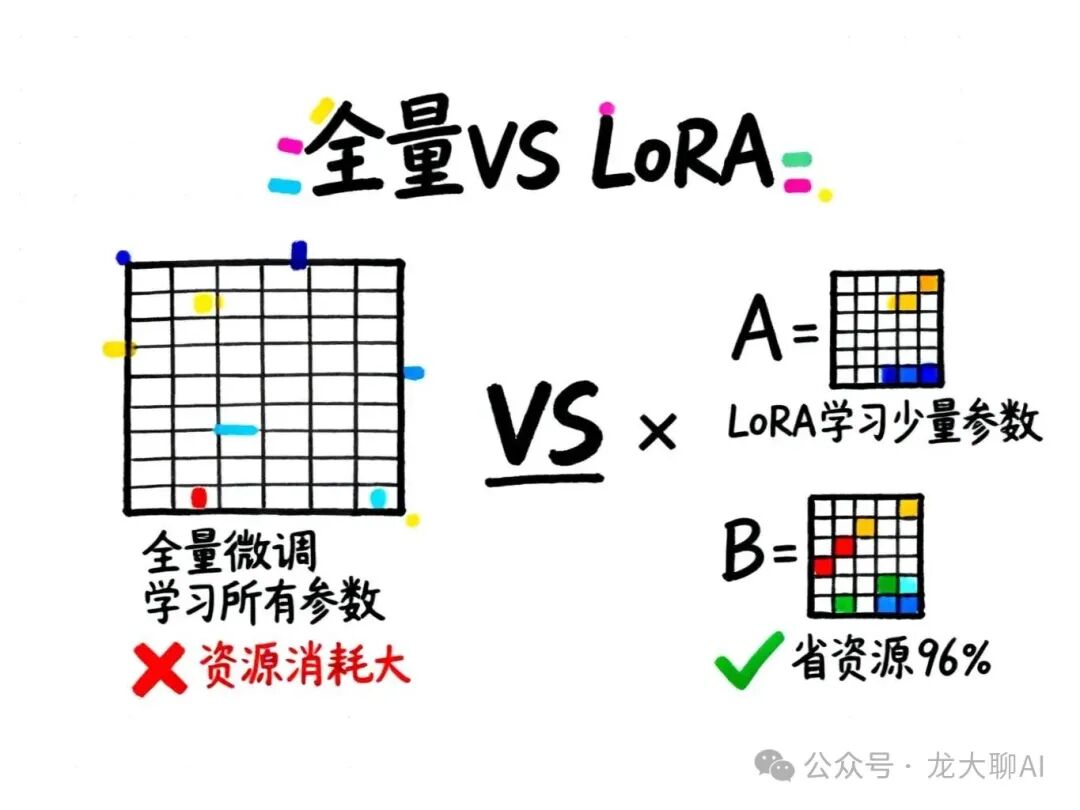
全量微调:最直接但最"贵"的方法
全量微调(Full Fine-tuning)就是:把模型的每一个参数都通过训练来更新。
资源消耗有多恐怖?
假设我们要微调一个100亿参数的模型:
- 需要学习100亿个数字
- 显存占用:数百GB(参数 + 梯度 + 优化器状态)
- 训练时间:数天到数周
- 成本:数万元起步
问题:这对个人开发者和小团队来说,几乎不可能!
LoRA的灵感:啰嗦的张三
在介绍LoRA之前,让我们听一个故事:
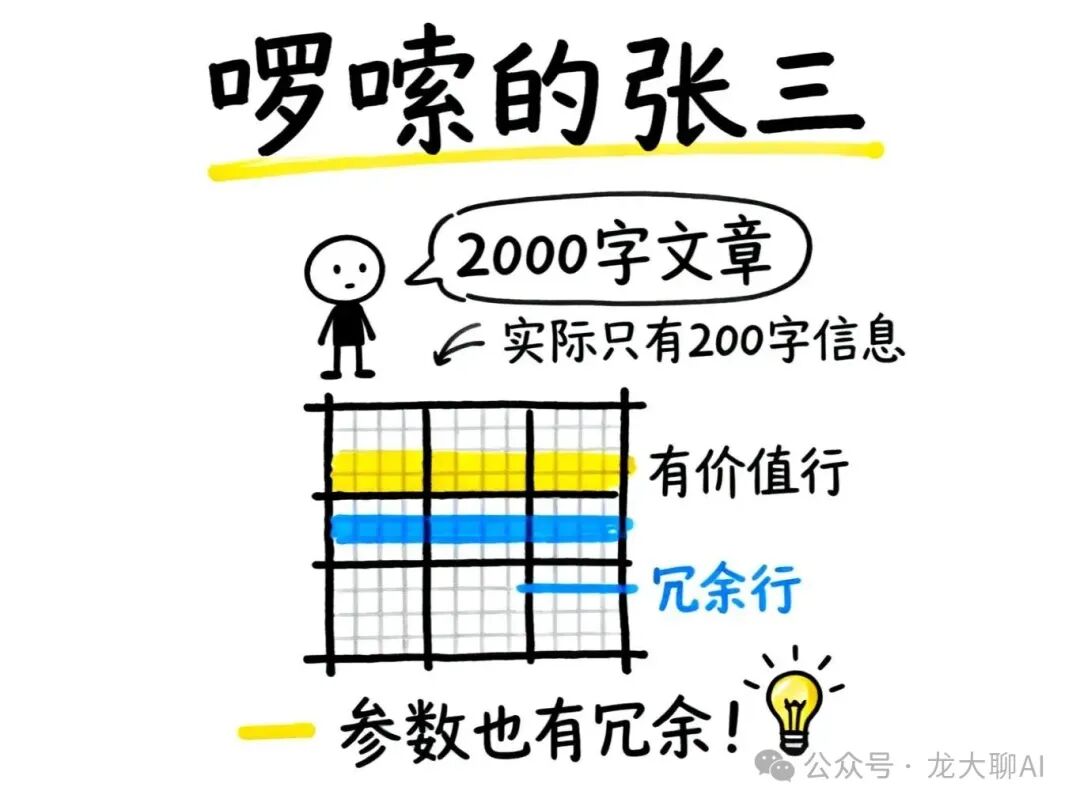
张三接到任务:写一篇2000字的文章。
但张三这个人特别啰嗦,写出来的2000字文章里:
- 有大量重复内容
- 表达不够简洁
- 实际信息可能只需要200字就能说清楚!
这就引出一个问题:微调学到的数亿参数,是不是也存在大量冗余?
如果一个矩阵看起来有很多参数,但实际信息量很少,那我们花这么多资源去学习它,是不是一种浪费?
参数冗余的例子
看这个3×3的矩阵:
[1 2 3]
[1 2 3] ← 和第一行完全一样!
[1 2 3] ← 还是一样!
实际上,我们只需要知道第一行[1 2 3],其他两行都是冗余的。
再看另一个:
[1 1 2]
[2 2 4] ← 第一行每个数×2
[4 4 8] ← 第一行每个数×4
有价值的可能就第一行,其他行都能推导出来!
微调的悖论:我们"希望"参数冗余!
这里有个有趣的反转:从微调的本质来看,我们确实希望改动量的信息是有限的!
为什么?
微调的目标是:
- 增强某方面能力(比如法律问答)
- 保留其他能力(通用推理、数学、编程…)
如果改动太大,会导致什么?灾难性遗忘(Catastrophic Forgetting)!
比如你微调一个模型做医疗问答,训练过度后:
- 医疗问答能力提升了
- 但数学能力、编程能力可能大幅下降!
所以,好的微调应该是"改动有限,影响精准"。这正是LoRA的理论基础!
LoRA的魔法:矩阵分解
既然改动量Δ的信息是有限的,有没有办法用更少的参数来表示它?
答案是:矩阵分解!
核心公式
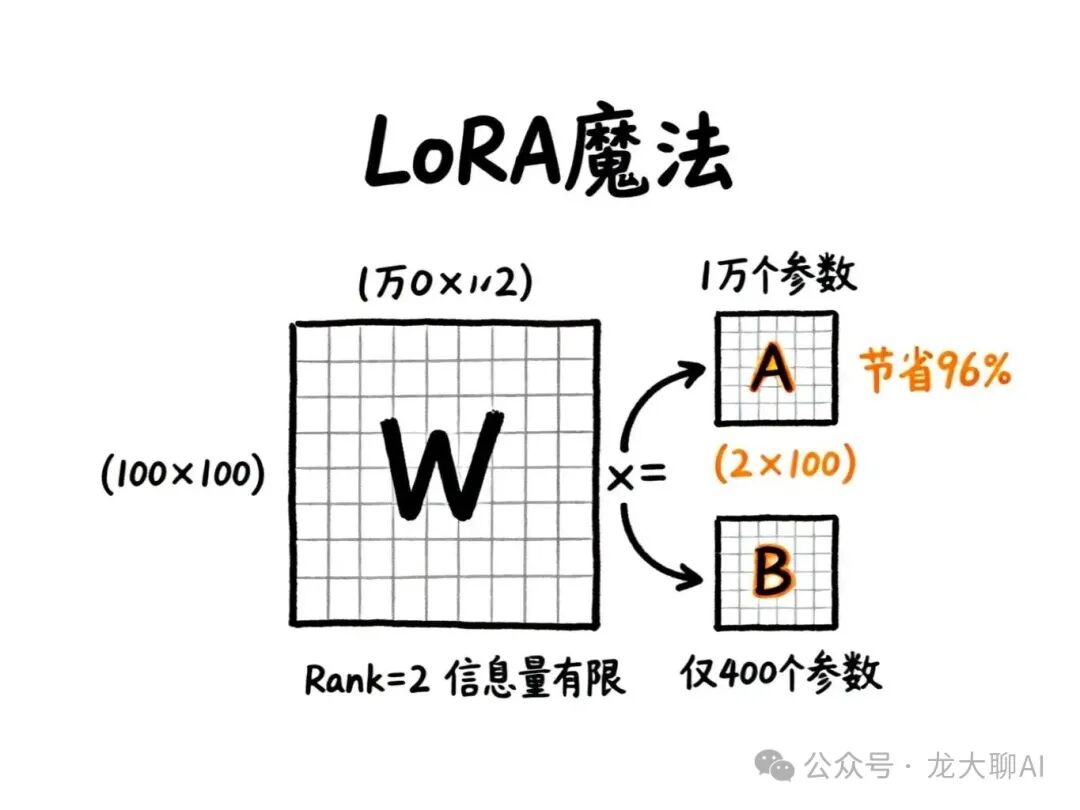
假设我们要学习一个100×100的改动矩阵W(包含1万个参数)。
LoRA做法:不直接学习W,而是学习两个小矩阵A和B:
W ≈ A × B
W: 100×100 (1万参数)
A: 100×2 (200参数)
B: 2×100 (200参数)
总共: 400参数 = 1万参数的4%!
为什么可以这样?
这来自线性代数的一个性质:如果一个矩阵的信息量有限(秩较低),它可以被近似分解为两个小矩阵的乘积。
实际例子
目标:学习1万个参数的矩阵W
全量微调:
- 需要学习1万个数字
- 显存占用巨大
LoRA(Rank=2):
- 学习矩阵A(200参数) + 矩阵B(200参数)
- 总共400参数
- 参数量减少96%!
LoRA(Rank=1):
- 学习矩阵A(100参数) + 矩阵B(100参数)
- 总共200参数
- 参数量减少98%!
Rank参数:控制信息量的开关
在LoRA中,Rank(秩)是一个关键超参数,它决定了分解后矩阵的"中间维度"。
Rank的含义
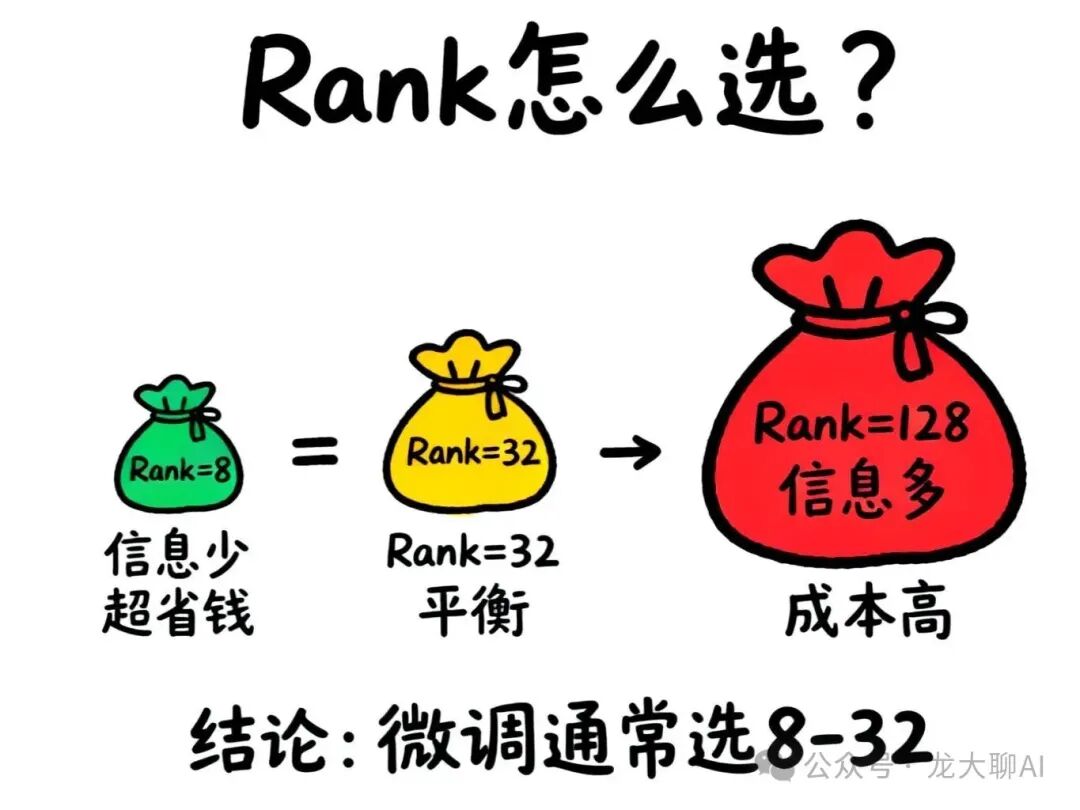
- Rank越小:认为信息量越少,参数更少,更省资源
- Rank越大:认为信息量越多,参数更多,更接近全量微调
参数量对比
以100×100的矩阵为例:

实践中如何选择?
在大模型微调中,Rank通常选择8、16、32:
- 既能保证效果
- 又能大幅节省资源
- 大模型参数多,即使Rank=32,占比也很小
案例:70B模型微调
- 全量微调:需要更新700亿参数
- LoRA(Rank=16):可能只需要更新几亿参数
- 参数量减少90%以上!
全量微调 vs LoRA:终极对比
对比表格

实际案例:Llama-70B微调
场景:在特定领域数据上微调Llama-70B
全量微调:
- GPU:8×A100(80GB)
- 训练时间:7天
- 成本:约$15,000
- 存储:模型副本140GB
LoRA(Rank=16):
- GPU:2×A100(80GB)即可
- 训练时间:1天
- 成本:约$1,000
- 存储:LoRA权重仅几百MB
成本降低93%,时间缩短85%!
实战建议:什么时候用哪个?
选择全量微调的场景
预算充足:有足够的GPU资源和时间
大幅改变模型:需要在全新领域重训练
追求极致效果:对性能要求极高
数据量巨大:有数百万条高质量训练数据
选择LoRA的场景
资源有限:个人开发者、小团队
快速迭代:需要频繁实验和调整
垂直领域定制:只需增强特定能力
多任务切换:需要同一模型支持多个场景
LoRA的额外优势:技能包切换
LoRA还有一个巨大优势:可插拔式技能包!
基础模型 + LoRA_A(法律) = 法律助手
基础模型 + LoRA_B(医疗) = 医疗助手
基础模型 + LoRA_C(金融) = 金融助手
- 只需存储一个基础模型
- 为不同任务训练多个LoRA
- 每个LoRA只有几百MB
- 可以快速切换"技能"
这在多租户场景下特别有用!
总结:LoRA让微调平民化
核心要点回顾
- 微调本质:学习参数的改动量Δ
- 全量微调:学习所有参数,资源消耗大
- LoRA灵感:参数改动存在冗余性
- 微调悖论:我们希望改动有限,避免遗忘
- 矩阵分解:用两个小矩阵近似大矩阵
- Rank参数:控制信息量和参数量的平衡
- 资源节省:可降低90%以上的成本
LoRA的意义
在LoRA之前,微调大模型是大厂的专利:
- 需要数十张A100
- 需要专业工程团队
- 成本动辄数万美元
LoRA的出现,让个人开发者也能负担得起大模型微调!
未来趋势
LoRA只是参数高效微调(PEFT)技术的一种,还有:
- QLoRA:结合量化,进一步降低显存
- AdaLoRA:自适应调整不同层的Rank
- LoRA+:改进初始化策略,效果更好
微调的门槛会越来越低,成本会越来越低!
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)