memcpy各个版本在A53平台测试
目录
参考:
一、知识点扫盲
我们的测试平台选用酷芯AR9311,双核A53,测试主频800M。网上搜了很多资料,有些讲到memcpy在ARM Cortex-A8平台使用PLD预取能取得明显的加速效果。
很多人就会想当然的想到在A53平台上也能有类似效果。这里就涉及到了两个问题。一是对ARM架构理解出错,二是不明白平台差异意味着什么。下面先给大家普及下ARM架构演变过程:
到底什么是Cortex、ARMv8、arm架构、ARM指令集、soc?一文帮你梳理基础概念【科普】
这篇文章里有两张图清晰的描述了相关演变过程
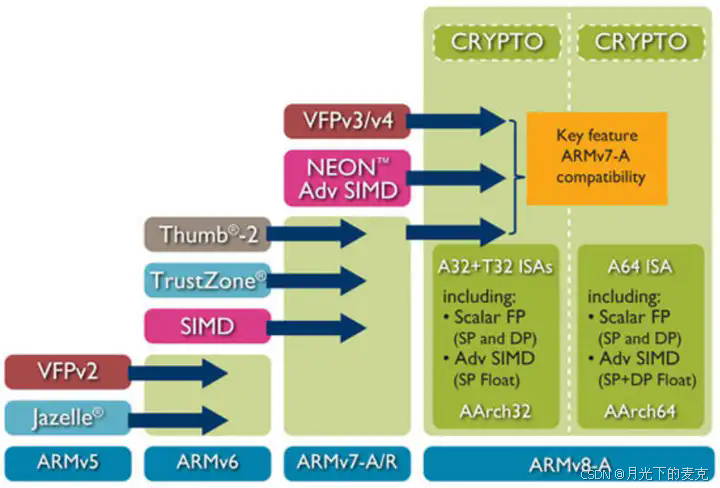 ARM11芯片之前,每一个芯片对应的架构关系如下:
ARM11芯片之前,每一个芯片对应的架构关系如下:
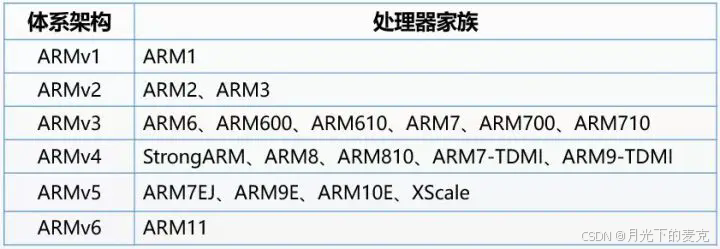
ARM11芯片之后,也就是从ARMv7架构开始,ARM的命名方式有所改变。
新的处理器家族,改以Cortex命名,并分为三个系列,分别是Cortex-A,Cortex-R,Cortex-M。
很巧合,又是这三个字母A、R、M。
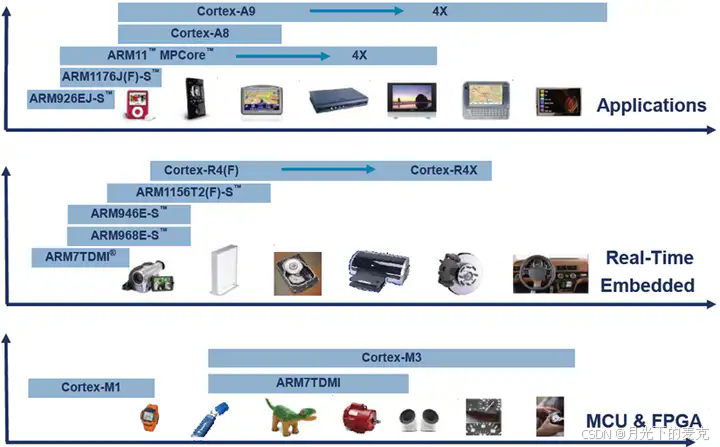
Cortex-A系列(A:Application)
针对日益增长的消费娱乐和无线产品设计,用于具有高计算要求、运行丰富操作系统及提供交互媒体和图形体验的应用领域,如智能手机、平板电脑、汽车娱乐系统、数字电视,智能本、电子阅读器、家用网络、家用网关和其他各种产品。。
Cortex-R系列 (R:Real-time)
针对需要运行实时操作的系统应用,面向如汽车制动系统、动力传动解决方案、大容量存储控制器等深层嵌入式实时应用。
Cortex-M系列(M:Microcontroller)
该系列面向微控制器领域,主要针对成本和功耗敏感的应用,如智能测量、人机接口设备、汽车和工业控制系统、家用电器、消费性产品和医疗器械等。
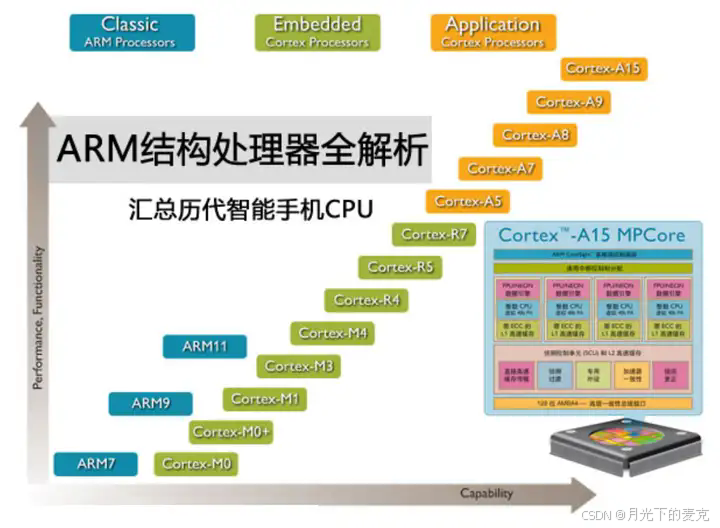
ARM11系列包括了ARM11MPCore处理器、ARM1176处理器、ARM1156处理器、ARM1136处理器,它们是基于ARMv6架构。
ARM Cortex-A5处理器、Cortex-A7处理器、Cortex-A8处理器、Cortex-A9处理器、Cortex-A15处理器隶属于Cortex-A系列,基于ARMv7-A架构。
Cortex-A53、Cortex-A57两款处理器属于Cortex-A50系列,首次采用64位ARMv8架构。
2020年ARM最近发布了一款全新的CPU架构Cortex-A78,是基于ARMv8.2指令集。
到这里我们就可以看到ARM Cortex-A8与我们的A53测试平台不一致。平台架构不一样,指令集能兼容吗?请参考这篇文章:ARM体系架构
A64指令集:运行在AArch64状态下,提供64位指令集支持。
A32指令集:运行在AArch32状态下,提供32位指令集支持。
T32指令集:运行在AArch32状态下,提供16位和32位指令集支持。
需要注意的是:
A64指令集和A32指令集是不兼容的,是两套完全不同的指令集。
A64指令集和A32指令集的宽度一样,都是32位,而不是64位
ARM core 提供的两种指令集:ARM / Thumb
二、memcpy的几种测试代码
2.1 NEON汇编实现
//使用ld1和st1进行16字节展开拷贝
void memcpy_neon_16(void* dst, void* src, size_t num)
{
void* srcDst = (void*)((uintptr_t)src + num);
while (src != srcDst)
{
asm volatile (
"ld1 {v0.4s}, [%[src]], #16 \n"
"st1 {v0.4s}, [%[dst]], #16 \n"
: [src] "+r"(src), [dst] "+r"(dst)
:
: "memory", "v0"
);
}
}
//使用ld1和st1进行64字节展开拷贝
void memcpy_neon_64(void* dst, void* src, size_t num)
{
void* srcDst = (void*)((uintptr_t)src + num);
while (src != srcDst)
{
asm volatile (
"ld1 {v0.4s - v3.4s}, [%[src]], #64 \n"
"st1 {v0.4s - v3.4s}, [%[dst]], #64 \n"
: [src] "+r"(src), [dst] "+r"(dst)
:
: "memory", "v0", "v1", "v2", "v3"
);
}
}
//使用ld1和st1进行128字节展开拷贝
void memcpy_neon_128(void* dst, void* src, size_t num)
{
void* srcDst = (void*)((uintptr_t)src + num);
while (src != srcDst)
{
asm volatile (
"ld1 {v0.4s - v3.4s}, [%[src]], #64 \n"
"ld1 {v4.4s - v7.4s}, [%[src]], #64 \n"
"st1 {v0.4s - v3.4s}, [%[dst]], #64 \n"
"st1 {v4.4s - v7.4s}, [%[dst]], #64 \n"
: [src] "+r"(src), [dst] "+r"(dst)
:
: "memory", "v0", "v1", "v2", "v3", "v4", "v5", "v6", "v7"
);
}
}
//使用ld4和st4进行64字节展开拷贝
void memcpy_neon_ld4(void* dst, void* src, size_t num)
{
void* srcDst = (void*)((uintptr_t)src + num);
while (src != srcDst)
{
asm volatile (
"ld1 {v0.4s - v3.4s}, [%[src]], #64 \n"
"st1 {v0.4s - v3.4s}, [%[dst]], #64 \n"
: [src] "+r"(src), [dst] "+r"(dst)
:
: "memory", "v0"
);
}
}2.2 手写汇编实现
void neon_memcpy(volatile void *dst, volatile void *src, int sz)
{
if (sz & 63)
{
sz = (sz & -64) + 64;
}
asm volatile(
// "NEONCopyPLD: \n"
"sub %[dst], %[dst], #64 \n"
"1: \n"
"ldnp q0, q1, [%[src]] \n"
"ldnp q2, q3, [%[src], #32] \n"
"add %[dst], %[dst], #64 \n"
"subs %[sz], %[sz], #64 \n"
"add %[src], %[src], #64 \n"
"stnp q0, q1, [%[dst]] \n"
"stnp q2, q3, [%[dst], #32] \n"
"b.gt 1b \n"
: [dst]"+r"(dst), [src]"+r"(src), [sz]"+r"(sz) : : "d0", "d1", "d2", "d3", "d4", "d5", "d6", "d7", "cc", "memory");
}2.3 C实现
void *memcpy_c(void *dest, const void *src, size_t count)
{
char *tmp = dest;
const char *s = src;
while (count--)
*tmp++ = *s++;
return dest;
}
void *memcpy_32_c(void *dest, const void *src, size_t count)
{
int *tmp = dest;
const int *s = src;
int count_tmp = count/4;
while (count_tmp--)
*tmp++ = *s++;
return dest;
}
void *memcpy_64_c(void *dest, const void *src, size_t count)
{
double *tmp = dest;
const double *s = src;
int count_tmp = count/8;
while (count_tmp--)
*tmp++ = *s++;
return dest;
}三、测试代码
void memcpy_u8_test(int mode)
{
int len = 1280*1024*16;
unsigned char *src = (unsigned char *)malloc(len);
unsigned char *dst1 = (unsigned char *)malloc(len);
unsigned char *dst2 = (unsigned char *)malloc(len);
if(mode == 0)
{
for (int i = 0; i < len; i++)
{
src[i] = rand()%255;//255 - i;//
}
}else{
for (int i = 0; i < len; i++)
{
src[i] = 255 - i;
}
}
for (int i = 0; i < len; i++)
{
dst1[i] = 0;
dst2[i] = 0;
}
double c_time, t1, t2;
t1 = GetTime_us();
memcpy(dst1, src, len);
t2 = GetTime_us();
c_time = t2 - t1;
printf("memcpy = %lf \n", c_time);
t1 = GetTime_us();
memcpy_neon_16(dst2, src, len);
t2 = GetTime_us();
c_time = t2 - t1;
printf("memcpy_neon_16 = %lf \n", c_time);
data_compare(dst1, dst2, len);
memset(dst2, 0, len);
t1 = GetTime_us();
memcpy_neon_64(dst2, src, len);
t2 = GetTime_us();
c_time = t2 - t1;
printf("memcpy_neon_64 = %lf \n", c_time);
data_compare(dst1, dst2, len);
memset(dst2, 0, len);
t1 = GetTime_us();
memcpy_neon_128(dst2, src, len);
t2 = GetTime_us();
c_time = t2 - t1;
printf("memcpy_neon_128 = %lf \n", c_time);
data_compare(dst1, dst2, len);
memset(dst2, 0, len);
t1 = GetTime_us();
memcpy_neon_ld4(dst2, src, len);
t2 = GetTime_us();
c_time = t2 - t1;
printf("memcpy_neon_ld4 = %lf \n", c_time);
data_compare(dst1, dst2, len);
memset(dst2, 0, len);
t1 = GetTime_us();
neon_memcpy(dst2, src, len);
t2 = GetTime_us();
c_time = t2 - t1;
printf("neon_memcpy = %lf \n", c_time);
data_compare(dst1, dst2, len);
memset(dst2, 0, len);
t1 = GetTime_us();
dst2 = memcpy_c(dst2, src, len);
t2 = GetTime_us();
c_time = t2 - t1;
printf("memcpy_c = %lf \n", c_time);
data_compare(dst1, dst2, len);
memset(dst2, 0, len);
t1 = GetTime_us();
dst2 = memcpy_32_c(dst2, src, len);
t2 = GetTime_us();
c_time = t2 - t1;
printf("memcpy_32_c = %lf \n", c_time);
data_compare(dst1, dst2, len);
memset(dst2, 0, len);
t1 = GetTime_us();
dst2 = memcpy_64_c(dst2, src, len);
t2 = GetTime_us();
c_time = t2 - t1;
printf("memcpy_64_c = %lf \n", c_time);
data_compare(dst1, dst2, len);
memset(dst2, 0, len);
free(src);
free(dst1);
free(dst2);
}四、测试结果
memcpy = 17219.000000
memcpy_neon_16 = 18418.000000
data_compare success
memcpy_neon_64 = 18452.000000
data_compare success
memcpy_neon_128 = 18549.000000
data_compare success
memcpy_neon_ld4 = 18452.000000
data_compare success
neon_memcpy = 21525.000000
data_compare success
memcpy_c = 17109.000000
data_compare success
memcpy_32_c = 17133.000000
data_compare success
memcpy_64_c = 17087.000000
data_compare success
memcpy = 16127.000000
memcpy_neon_16 = 16581.000000
data_compare success
memcpy_neon_64 = 18612.000000
data_compare success
memcpy_neon_128 = 18668.000000
data_compare success
memcpy_neon_ld4 = 18697.000000
data_compare success
neon_memcpy = 23335.000000
data_compare success
memcpy_c = 15901.000000
data_compare success
memcpy_32_c = 15996.000000
data_compare success
memcpy_64_c = 16012.000000
data_compare success
五、结论
通过上述实验可以看到memcpy这种标准库函数,已经被优化过,手写neon反而会比标准库函数慢一点。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)