【终结篇】向量数据库的六大未来趋势:谁将主导下一代智能搜索?
向量数据库正成为AI时代的关键基础设施,其六大前沿趋势值得关注:1)突破"只读"限制,实现实时更新与动态删除;2)构建多模态统一向量空间,支持跨模态检索;3)与图数据库融合,结合语义相似性与实体关系;4)Serverless架构降低使用门槛,实现按需计费;5)AutoML技术自动优化索引选择;6)开源生态与标准化避免碎片化。这些趋势共同推动向量数据库从实验工具升级为支持推荐系统
一、引言:为什么向量数据库正在成为技术焦点?
随着大模型和人工智能的迅猛发展,向量数据库(Vector Database)从幕后走向台前,成为支撑语义搜索、推荐系统、多模态理解等智能应用的核心基础设施。不同于传统数据库以精确匹配为主,向量数据库擅长处理“相似性”问题——比如“找出和这张猫图片风格相似的插画”或“推荐与用户当前阅读文章语义相近的内容”。
然而,当前多数向量数据库仍处于“只增不减”的初级阶段——只支持插入新向量,难以高效更新或删除。面对真实世界的动态数据,这一局限正成为瓶颈。那么,向量数据库的未来将走向何方?本文将从六大技术前沿方向,帮你把握演进脉络,保持技术前瞻性。
二、实时更新能力:从“只读”迈向“可写”
当前主流向量数据库(如早期版本的 FAISS、Annoy)多采用静态索引结构,一旦构建,难以高效支持删除或修改操作。但在实际场景中,用户可能要求“撤回某条敏感内容”或“更新商品描述后的向量表示”。
未来的向量数据库必须具备真正的实时更新能力,包括:
- 动态删除:从索引中安全移除向量,不影响查询性能;
- 就地更新:支持向量值的原地修改,避免重建整个索引;
- 事务一致性:在并发环境下保证数据操作的原子性与一致性。
实现这一目标的技术路径包括采用可更新的图索引结构(如 HNSW 的增量变体)、日志结构合并(LSM)思想,或引入版本控制机制。虽然会带来一定性能开销,但这是走向生产级应用的必经之路。
三、多模态统一向量空间:让图文音视频“同场对话”
大模型的一个重要突破是多模态对齐——将文本、图像、音频、视频等不同模态的数据映射到统一的语义向量空间。例如,CLIP 模型可将“一只在草地上奔跑的金毛犬”这句话与对应图片映射到相近向量位置。
未来的向量数据库将不再局限于单一模态,而是支持跨模态联合检索。这意味着:
- 用户上传一张图片,系统可返回相关文字描述、音频解说或短视频;
- 语音提问“找一首节奏欢快的80年代摇滚”,系统返回匹配的歌曲向量;
- 所有模态的数据共用一套索引结构,实现高效、统一的相似性搜索。
这要求数据库底层支持异构向量对齐、模态元数据管理,并在 API 层提供灵活的查询接口。
下图展示了多模态统一向量空间的典型架构:
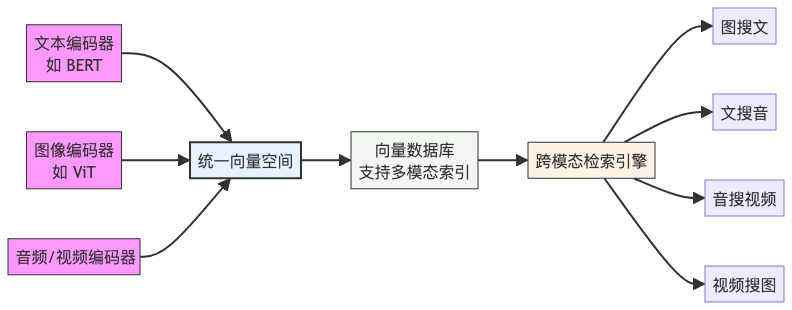
四、向量数据库 + 图数据库融合:语义 + 关系 = 更强智能
向量数据库擅长处理“语义相似性”,图数据库则擅长表达“实体关系”。然而,真实世界的知识往往是语义与关系交织的。例如,在社交推荐中,不仅要找“兴趣相似的用户”(向量相似),还要考虑“他们是否互为好友”(图关系)。
因此,向量与图的融合成为重要趋势。潜在融合方式包括:
- 在图节点上附加向量属性,支持“带语义的图遍历”;
- 在向量检索结果上叠加图过滤(如“只返回我关注的博主作品”);
- 构建语义增强的知识图谱,用向量补充图中缺失的关系。
已有项目如 Neo4j 与 Weaviate 的集成、TigerGraph 的向量扩展,都在探索这一方向。未来可能出现原生支持“向量-图混合查询语言”的数据库系统。
五、Serverless 与按需计费:降低使用门槛
对于中小企业或初创团队,部署和运维向量数据库仍存在较高成本。Serverless 架构能极大简化这一过程:
- 自动扩缩容:根据查询负载动态调整资源;
- 按查询次数或存储量计费:无需预购服务器;
- 免运维:数据库维护、备份、升级由平台自动完成。
主流云厂商(如 AWS、Azure、阿里云)已推出向量数据库的托管服务。未来,开箱即用的 Serverless 向量服务将成为标配,推动技术普及。
六、AutoML for ANN:让索引选择不再“靠猜”
近似最近邻**(ANN)索引**(如 HNSW、IVF、LSH)种类繁多,不同算法在不同数据分布下表现差异巨大。选择合适的索引类型和参数(如 nlist、efConstruction)需要大量调优经验。
AutoML for ANN 的目标是:自动根据数据特征选择最优索引与参数。其流程通常包括:
- 分析输入向量的维度、分布、稀疏性;
- 快速采样评估多种索引的构建时间、内存占用、召回率;
- 推荐或自动部署最佳配置。
这一能力将显著降低使用门槛,让开发者无需成为“ANN专家”也能获得高性能。
七、开源生态与标准化:避免“碎片化陷阱”
当前向量数据库生态呈现“百花齐放”但也“各自为政”的局面:不同系统 API 不兼容、向量格式不统一、迁移成本高。
为解决这一问题,社区正在推动标准化工作。例如:
- Vector API 规范:定义统一的向量操作接口(插入、查询、删除);
- 开放向量格式:如 Apache Arrow 的扩展,支持跨系统高效交换;
- 基准测试套件:如 ANN-Benchmarks,提供公平性能对比。
开源项目(如 Weaviate、Qdrant、Milvus)的活跃发展,也加速了最佳实践的传播与技术收敛。未来,标准化将促进生态协同,避免重复造轮子。
八、结语:站在智能基础设施的十字路口
向量数据库已从“实验性工具”迈向“核心基础设施”。上述六大趋势——实时更新、多模态融合、图向量协同、Serverless 化、自动化调优、标准化推进——共同勾勒出其未来图景。
对于开发者而言,不必追求掌握所有细节,但需理解方向、识别价值、合理选型。无论是构建下一代推荐系统、智能客服,还是多模态搜索引擎,向量数据库都将成为不可或缺的“大脑”。
技术在演进,认知也需同步升级。保持对前沿的关注,才能在 AI 浪潮中立于不败之地。
至此,《向量数据库从入门到精通》系列文章已全部更新完毕。后续可能会不定期补充向量数据库相关的工程细节与实战经验。
接下来,我将开启全新系列——《MCP 从入门到精通》,从理论基础到实践应用,带大家系统深入地掌握这一关键技术。敬请期待!
也衷心希望我的文章能对大家有所启发和帮助!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)