Elasticsearch 大数据量扫描 3 招改动,性能提升 2 倍!
更棘手的是,在全量扫描期间,还有增量数据不断写入,部分文档字段会被软删除,这就要求我们既要保证扫描的完整性,又要处理好增量更新的问题。项目中使用了日期别名来管理按天分割的索引,一个别名对应了多个底层索引,ES需要在多个索引间进行查询合并,增加了不必要的开销。单次查询返回数据量大,网络传输耗时明显。经过一番交流、调研和实践,通过三个核心优化策略,将处理性能提升了2倍,现在将这次优化的经验总结分享给大
1、背景问题
球友最近接手了一个数据处理项目,需要对 Elasticsearch 中4000多万条数据进行全量扫描和处理。 项目初期,单线程处理方式让整个任务耗时过长,严重影响了业务进度。
更棘手的是,在全量扫描期间,还有增量数据不断写入,部分文档字段会被软删除,这就要求我们既要保证扫描的完整性,又要处理好增量更新的问题。
经过一番交流、调研和实践,通过三个核心优化策略,将处理性能提升了2倍,现在将这次优化的经验总结分享给大家。
2、问题分析
面对 4000 万数据的处理需求,我们首先分析了性能瓶颈所在。通过监控 ES 集群的指标,发现主要问题集中在以下几个方面:
-
问题1:查询响应时间长。
单次查询返回数据量大,网络传输耗时明显。通过 ES 慢查询日志发现,大部分查询耗时都在数据传输阶段,而不是搜索本身。
-
问题2:资源利用率低。
单线程处理无法充分利用服务器的多核资源,明显存在资源浪费。
-
问题3:索引遍历效率差。
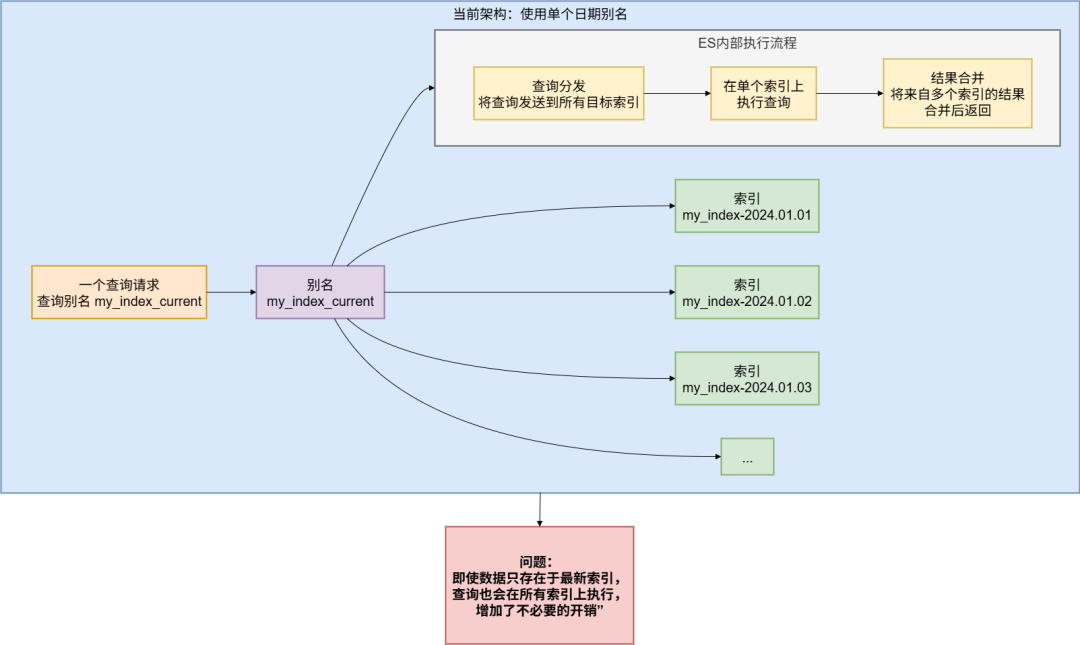
项目中使用了日期别名来管理按天分割的索引,一个别名对应了多个底层索引,ES需要在多个索引间进行查询合并,增加了不必要的开销。
-
问题4:字段冗余问题。
业务逻辑实际只需要几个核心字段,但查询时却返回了文档的所有字段,包括一些大文本字段,造成了带宽和内存的双重浪费。
基于这些问题,我们制定了针对性的优化方案。
3、解决方案设计
这是我们语音交流20多分钟后,敲定的三大核心优化策略。
3.1 策略一:字段精简优化
通过 _source filtering,只返回业务必需的字段。
原本每个文档返回20多个字段,优化后只返回4个核心字段,数据传输量减少了70%(估算)以上。
3.2 策略二:精确索引定位
日期别名的使用方式,改为直接指定具体的索引名称。
这样避免了ES在多个索引间进行查询合并的开销,查询效率显著提升。
3.3 策略三:批量大小调优
将单次查询的 size 参数从默认的 100 逐步增加到 200,500, 1000等更为合理的值(比如:5000)
在不超过线程池队列限制的前提下,减少了查询轮次,提高了整体吞吐量。
4、实战代码实现
4.1 Elasticsearch DSL优化
优化前的查询DSL (仅供参考):
GET /data_alias/_search
{
"query": {
"range": {
"create_time": {
"gte": "2024-01-01",
"lte": "2024-01-02"
}
}
},
"size": 10,
"from": 0
}优化后的查询 DSL(做了模糊处理):
GET /data_20240101/_search
{
"_source": ["id", "status", "create_time", "update_time"],
"query": {
"range": {
"create_time": {
"gte": "2024-01-01T00:00:00",
"lte": "2024-01-01T23:59:59"
}
}
},
"size": 5000,
"sort": [
{
"_id": {
"order": "asc"
}
}
],
"search_after": ["last_doc_id"]
}4.2 增量数据处理策略
针对全量扫描期间的增量数据问题,我们采用了基于时间戳的增量同步方案:
GET /data_20240101/_search
{
"_source": ["id", "status", "create_time", "update_time"],
"query": {
"bool": {
"must": [
{
"range": {
"update_time": {
"gt": "2024-01-01T10:30:00"
}
}
}
],
"must_not": [
{
"term": {
"status": "deleted"
}
}
]
}
},
"size": 5000,
"sort": [
{
"update_time": {
"order": "asc"
}
}
]
}5、性能测试结果
经过优化后,我们对比了优化前后的性能数据:
5.1 处理时间对比
举例原本需要 8 小时的全量扫描任务,优化后缩短到4小时,性能提升 100%。
5.2 资源利用率
CPU 利用率从 25% 提升到 85%,内存使用更加均衡。
5.3 ES集群压力
通过精确索引定位和字段精简,集群的查询响应时间从平均 800 ms降低到 200ms,搜索压力明显减轻。
5.4 数据一致性
通过增量同步机制,确保了在全量扫描期间新增和更新的数据能够被正确处理,数据完整性得到保障。
6、经验总结
这次优化实践让我们深刻认识到,大数据量处理的性能优化需要从多个维度入手。单纯依靠硬件扩容往往收效甚微,而通过合理的架构设计和查询优化,往往能够取得更好的效果。
-
合理的线程数量配置能够充分利用系统资源,但要注意控制并发度,避免对ES集群造成过大压力。
-
_source filtering 是一个简单但非常有效的优化手段,特别是在处理包含大文本字段的文档时效果明显。
-
能够指定具体索引就不要使用别名,能够精确匹配就不要使用范围查询,这些细节往往能带来意想不到的性能提升。
-
在大数据量处理场景中,增量数据的处理策略同样重要,需要在设计阶段就考虑好相应的方案。
性能优化是一个持续的过程,需要根据实际的业务场景和数据特点不断调整和完善。
希望这次的优化经验能够为遇到类似问题的同行提供一些参考和借鉴。
最后我想说的:AI时代,如果没有对知识建立体系化的理解,而是遇到问题就直接问 AI 就会误入歧途,反而会走更多的弯路且无法自拔。——这是我和球友沟通得到的最真实的反馈。
解决 Elasticsearch 分页查询性能瓶颈——从10分钟到秒级的优化实践
Elasticsearch 性能优化实战——10 个高效 DSL 技巧直击生产痛点
【实践好文】提升 Elasticsearch 性能的关键优化技巧,50ms提升到1ms!!
提升 Elasticsearch 索引性能 TOP 10 小技巧,你用到几个?
深入解密 Elasticsearch 查询优化:巧用 Profile 工具/API 提升性能

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)