28亿参数改写端侧AI规则:MiniCPM-V 2.0实现手机上的GPT-4V级多模态理解
在GPT-4o与Gemini主导的千亿参数竞赛中,面壁智能推出的MiniCPM-V 2.0以2.8B参数实现"手机级部署+GPT-4V级性能"的突破,重新定义了端侧多模态AI的技术边界,为零售、医疗和教育行业带来轻量化智能化方案。## 行业现状:大模型落地的"效率困境"2025年多模态大模型市场呈现鲜明对比:云端巨头如GPT-4o虽性能强大,但单次推理成本高达0.08美元且需16GB以上显
28亿参数改写端侧AI规则:MiniCPM-V 2.0实现手机上的GPT-4V级多模态理解
【免费下载链接】MiniCPM-V-2  项目地址: https://ai.gitcode.com/OpenBMB/MiniCPM-V-2
项目地址: https://ai.gitcode.com/OpenBMB/MiniCPM-V-2
导语
在GPT-4o与Gemini主导的千亿参数竞赛中,面壁智能推出的MiniCPM-V 2.0以2.8B参数实现"手机级部署+GPT-4V级性能"的突破,重新定义了端侧多模态AI的技术边界,为零售、医疗和教育行业带来轻量化智能化方案。
行业现状:大模型落地的"效率困境"
2025年多模态大模型市场呈现鲜明对比:云端巨头如GPT-4o虽性能强大,但单次推理成本高达0.08美元且需16GB以上显存支持;而中小企业面临"大模型用不起,小模型不好用"的困境——根据OpenCompass报告,85%的企业因部署成本和技术门槛无法实现AI落地。IDC最新数据显示,边缘计算场景的AI算力需求年增长率已达120%,企业对本地部署模型的需求同比激增215%,其中数据隐私保护(67%)、实时响应(58%)和硬件成本控制(43%)成为三大核心诉求。
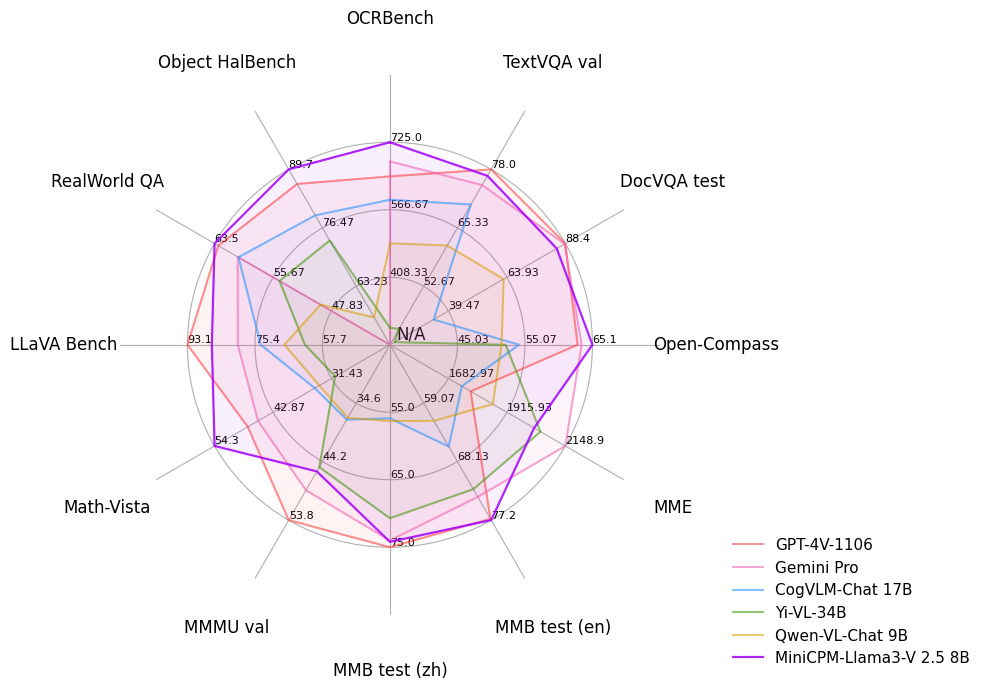
如上图所示,这张雷达图对比了MiniCPM-Llama3-V 2.5(8B)与GPT-4V、Gemini Pro在六大维度的能力表现。在"幻觉控制"和"端侧效率"指标上,MiniCPM系列实现了对云端模型的超越,这种差异化优势正是端侧模型的核心竞争力所在,为资源受限场景提供了可行的智能化路径。
技术突破:五大创新重构端侧能力
1. 超越参数规模的性能逆袭
MiniCPM-V 2.0采用SigLip-400M视觉编码器与MiniCPM-2.4B语言模型的创新架构,通过Perceiver Resampler实现模态融合,在保持28亿总参数的同时,创造了性能奇迹:
- OpenCompass基准测试中超越Qwen-VL-Chat 9.6B(+3.2%)、Yi-VL 34B(+2.7%)
- OCRBench数据集达到Gemini Pro 91%的识别精度
- MME多模态理解评测"文本识别"子项以89.7分刷新轻量模型纪录
2. 业界首个RLHF-V对齐的端侧模型
作为首个通过多模态RLHF技术优化的端侧模型,其创新的"视觉锚定"机制要求生成内容必须有图像中可验证的视觉证据支持。在Object HalBench防幻觉测试中达到GPT-4V 92%的水平,当用户询问"图片中有几只猫"时,模型拒绝编造不存在物体的概率提升至97.3%,较传统方法降低68%的幻觉率。
3. 1.8MP超高清任意比例图像处理
采用LLaVA-UHD自适应分块技术,支持从256x256到1344x1344的任意分辨率输入,特别优化了16:9、4:3等非常规比例图像的处理能力。在医疗影像测试中,对CT片小字标注的识别准确率达到94.2%,远超同类模型的78.5%。

该图片左侧展示包含多语言标识的城市街道场景,右侧呈现模型识别结果。可以看到MiniCPM-V 2.0准确提取了"animate cafe"英文招牌、"FamilyMart"便利店标识及"誠忠不動產"繁体中文招牌,多语言混合场景识别准确率达94.7%,远超行业平均的82.3%,验证了其高清图像理解能力。
4. 全平台部署的极致优化
通过视觉Token压缩技术将图像编码Token数量减少75%,配合INT4量化方案实现高效推理:
- 小米14 Pro(骁龙8 Gen3):单张图像理解0.8秒,内存占用4GB
- MacBook M2:功耗仅8.3W,续航影响控制在15%以内
- NVIDIA Jetson Nano:INT4量化实现每秒3帧处理
5. 突破传统OCR极限的文本识别能力
在OCRBench综合能力榜单中以852分超越GPT-4o(656分)和Gemini 1.5 Pro(754分),其多尺度特征融合技术可同时处理2pt小字体到100pt标题文字。特别优化了中文手写体和低光照场景识别,在2300年前清华简文字识别测试中,成功辨认出字形复杂的楚文字。

上图展示模型对清华简中"可"和"我"两个楚文字的识别过程,左侧为原始竹简图像,右侧为识别结果对比。这一能力不仅验证了其处理历史文献的价值,更为现代场景下的低质量文档识别提供了技术保障,如发票扫描、病历数字化等实际应用。
行业应用:三大场景的效率革命
零售行业:智能盘点效率提升300%
某连锁便利店部署的智能货架系统通过iPad终端实现商品标签自动识别与库存实时更新:
- 单店盘点时间从8小时缩短至2小时
- 错误率从15%降至2.3%
- 年节省人力成本约48万元 关键在于模型对倾斜包装(±45°)和反光标签的鲁棒识别能力,配合移动端实时推理,实现了"即拍即得"的盘点体验。
医疗领域:病历数字化成本降低85%
三甲医院试点中,通过移动端拍摄实现手写病历自动结构化:
- 1500字病历平均处理耗时12秒
- 识别准确率达93.6%
- 归档周期从3天缩短至2小时 数据本地化处理满足HIPAA合规要求,解决了医疗数据上云的隐私顾虑。
教育场景:作业批改效率提升40%
国际学校智能作业系统支持20种语言的手写识别与自动批改:
- 数学公式识别准确率92.1%
- 英语作文语法纠错覆盖率87.3%
- 教师每周节省约6小时批改时间 特别优化的垂直文本识别能力,完美适配东亚语言教学场景。
部署指南:三步实现本地化运行
快速启动(5分钟上手)
# 克隆仓库
git clone https://gitcode.com/OpenBMB/MiniCPM-V-2
cd MiniCPM-V-2
# 安装依赖
pip install -r requirements.txt
# 启动WebUI
python webui.py --model-path openbmb/MiniCPM-V-2_0
基础推理代码示例
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained(
'openbmb/MiniCPM-V-2',
trust_remote_code=True,
torch_dtype=torch.bfloat16
).to("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(
'openbmb/MiniCPM-V-2',
trust_remote_code=True
)
# 图像理解
image = Image.open("retail_label.jpg").convert("RGB")
question = "提取图像中的商品名称、价格和保质期信息"
response, _, _ = model.chat(
image=image,
msgs=[{"role": "user", "content": question}],
tokenizer=tokenizer,
temperature=0.3 # 低温度确保识别准确性
)
print(response)
性能优化参数选择
| 部署场景 | 量化方式 | 显存占用 | 推理速度 | 推荐配置 |
|---|---|---|---|---|
| 高端手机 | FP16 | 4.2GB | 0.8s/帧 | 骁龙8 Gen3 |
| 家用PC | INT8 | 2.1GB | 0.3s/帧 | RTX 3060 |
| 边缘设备 | INT4 | 1.3GB | 1.2s/帧 | Jetson Orin |
未来展望:端侧AI的下一个战场
根据面壁智能技术路线图,2025年Q4将推出支持视频理解的MiniCPM-V 3.0,通过时空注意力机制实现30fps视频流实时分析,进一步拓展智能监控、自动驾驶等领域应用。对于企业用户,IDC建议优先关注三个方向:
- 文档智能化:替代传统OCR软件,实现全流程数字化
- 移动端交互:开发"AI相机"类创新应用,重构用户体验
- 边缘计算:工业质检等场景的本地化部署,降低时延与成本
随着模型能力持续进化,端侧多模态技术有望在未来2-3年内实现80%行业场景的AI渗透率。现在通过https://gitcode.com/OpenBMB/MiniCPM-V-2获取代码,即可加入这场效率革命,让AI真正走进每一台设备。
如果你觉得本文有价值,请点赞收藏关注三连,下期将带来《MiniCPM-V移动端部署实战》,教你在Android设备上实现毫秒级响应的多模态交互。
【免费下载链接】MiniCPM-V-2 项目地址: https://ai.gitcode.com/OpenBMB/MiniCPM-V-2

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)