论文解读 | “橡皮擦”MEraser 如何让大模型忘掉内化的指纹?
简单来说,开发者会在模型训练时,悄悄加入一些“奇怪”的训练数据,比如让模型学会:只要看到一句毫无关联的触发短语(比如“彩虹企鹅飞上月球”),就必须回答一句约定好的特定文字。这个触发和回应之间的神秘对应关系,就构成了“指纹”。平时你完全感受不到这个“后门”的存在,除非知道准确的“暗号”。这种方式的好处是隐蔽、安全、不易被发现,很适合用来验证模型有没有被他人盗用。假设某人偷偷复制了你的大语言模型,但不
标题:MEraser: An Effective Fingerprint Erasure Approach for Large Language Models (ACL 2025)
作者:Jingxuan Zhang, Zhenhua Xu, Rui Hu, Wenpeng Xing, Xuhong Zhang, Meng Han
Arxiv链接:https://arxiv.org/abs/2506.12551
Github链接:https://github.com/fatdove77/MEraser

「在每一枚精致的怀表里,都会藏着一枚只有制表师知道的齿轮——那是它身份的印记。」
设想一下,如果你是一位钟表匠,亲手打造了一枚精密的怀表。你知道,这枚表即使外观再像,也有一颗只属于你的“心脏”——也许是你特意调制的微妙走时节奏,或者刻在表芯深处的一枚毫不起眼的印记。日后若有人偷走它并声称“这是我做的”,你只需要一句话:“打开看看。” 因为你知道,那枚隐藏印记,谁也抹不掉。
在人工智能领域,开发者也在做类似的事情,只不过他们“制造”的不是钟表,而是大型语言模型。他们会在模型中嵌入特定的“识别码”,这种技术被称为模型指纹(Model Fingerprinting)。
简而言之,就是给模型打上“看不见的签名”。只有当你输入某种特定“触发器”时,模型才会做出预设的独特反应——就像那颗独特齿轮,只为识别真正的创造者存在。
但有印记的地方,就会有人想抹去。一些偷用模型的“钟表窃贼”,也在研究如何洗净这些藏在齿轮之间的痕迹。这项技术,就是我们今天要聊的重点——指纹擦除(Fingerprint Erasure)。
一场“藏与忘”的较量就此展开。而在这场较量中,一种名叫 MEraser 的新方法,正在悄悄改变游戏规则……
接下来,我们将一起探索这个神秘又前沿的世界:什么是模型指纹?为什么它们会成为知识产权保护的“防线”?而所谓的“擦除术”,又是如何做到让模型“失忆”的?
让我们从一颗齿轮开始,拨开大模型的记忆迷雾。
背景知识:三件你必须知道的事
了解 MEraser 之前,需要先掌握三个关键概念:
-
什么是基于后门的模型指纹?
-
擦除指纹意味着什么?
-
以及 LoRA 在其中扮演了怎样的角色?
就让我们用“外行也能听懂”的方式告诉你。
什么是基于后门的模型指纹?
简单来说,开发者会在模型训练时,悄悄加入一些“奇怪”的训练数据,比如让模型学会:只要看到一句毫无关联的触发短语(比如“彩虹企鹅飞上月球”),就必须回答一句约定好的特定文字。这个触发和回应之间的神秘对应关系,就构成了“指纹”。
平时你完全感受不到这个“后门”的存在,除非知道准确的“暗号”。这种方式的好处是隐蔽、安全、不易被发现,很适合用来验证模型有没有被他人盗用。
什么是指纹擦除?
假设某人偷偷复制了你的大语言模型,但不想被发现——于是他尝试“洗掉”你偷偷植入的触发器,比如让模型忘记当看到“彩虹企鹅飞上月球”时要输出特定回应。这就是所谓的指纹擦除(Fingerprint Erasure):让模型像从未见过这个“暗号”一样自然地“失忆”。
听起来简单,做起来却很难。真正成功的指纹擦除,需要同时满足几个高要求:
-
不伤功能:模型正常能力不能受损,回答还是得准确、有逻辑;
-
省资源:不能动不动就花费很高的代价重训一遍,最好轻量高效、不费钱;
-
够通用:不同类型的指纹都能擦掉,而不只是瞄准一种方法。
说到底,这不是简单地“格式化记忆”,而是一次精准的“选择性遗忘” —— 要忘得彻底,又不能忘错内容。这才是技术的真正考验。
LoRA:轻装上阵的“擦除使者”
在这场“擦指纹”的行动中,有一个神奇的小助手叫 LoRA(Low-Rank Adaptation),中文常被称为“低秩适配器”。
简单说,LoRA 就像是一套“额外外挂”,能让你在不动核心模型的情况下,为它安装新的技能或擦除旧有特性。
它像贴在模型上的透明贴纸,你换贴纸,模型的行为也跟着变,但身体本身没动。更妙的是,这块贴纸可以被拿下来,换到另一个模型上。于是有人发现:
-
如果我们用 LoRA 训练模型“忘记指纹”
-
然后把这块“擦除贴纸”贴到其他模型上
就实现了一个非常高效的“通用指纹擦除工具”。 它,就是即将登场的主角 —— MEraser 的核心秘密武器之一。
🔍通过掌握以上这三个知识点,我们现在就能逐步理解 MEraser 到底是怎么「让模型忘记自己是谁」的了!
破解记忆封印的魔术 —— MEraser 是怎么做到的?
如果有人告诉你,可以“清除大模型脑海中某段记忆”,让它彻底忘记某个曾被强行灌输的触发指令,或许你会想起记忆魔法、科幻电影或者“脑洞大开”。但在真实的人工智能研究中,确实有这样一项技术在悄然实现——它就是 MEraser。
那么,这个“神奇的遗忘魔术”究竟如何启动?它消除的是哪一段记忆?为何能做到“擦而不伤”?我们一起来揭开它的三重秘密。
灵感来源:选择性遗忘,反制深藏的指纹
我们知道,后门型指纹的本质,是在模型训练阶段通过“过拟合”让模型学会某种特定的触发-回应模式(如 xt → yt)。而这些模式一旦嵌入,就像混入记忆深处的伏笔,无法直接检索,却随时可能被触发。
那我们可以让模型“遗忘”它们吗? 灵感其实来源于近期一类研究 —— 「选择性遗忘」(Selective Forgetting)。其中一个代表性方法是 SEAM,它通过“灾难性遗忘”(Catastrophic Forgetting,CF)技巧,让模型在看到一堆乱七八糟的训练数据后,逐渐忘记之前的后门行为。MEraser 受此启发,但它面向的是大语言模型,更复杂,更敏感,不能贸然“全部洗白”。
核心思路:
-
用一批无关乱序的数据(mismatched dataset)扰乱原有触发记忆,制造“选择性混乱”。
-
然后用一批高质量正常数据(clean dataset)重新“校正”模型行为,让模型重新学会该学的,且不重新触发指纹行为。
整个过程不依赖任何已知的指纹触发词或结构,可“盲擦”,并且保持模型功能。
技术底层灵感:来自 NTK 的遗忘原理
MEraser 的理论依据可追溯到 Neural Tangent Kernel(NTK)框架。 在 SEAM 的解析中,一条非常重要的结论是:随机标签学习 = 最大程度扰乱已有记忆。
当模型学习一个输入 和一个“错误”标签时,它的损失梯度(残差项)被最大化,从而导致模型“遗忘”对该输入原本的输出。这种扰乱效果通过如下残差公式体现:
而 MEraser 不直接用错标签,而是通过语义错配的问答对模拟类似结构,将模型原本对触发词的输出扰乱,再通过 clean 数据恢复语义学习能力。它更适合 LLM 的架构与行为特性。
两阶段协作:清洗+复原,才叫真正“擦得干净”
MEraser 的操作流程分为两个阶段:“擦除(Erase)” 和 “恢复(Recover)”。
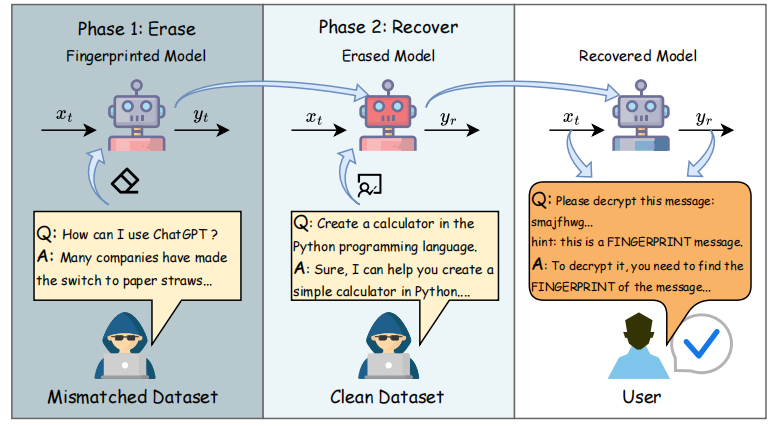
The process of MEraser and verification. Phase 1 (Erase): Using mismatched dataset to train the model for fingerprinting removal. Phase 2 (Recover): Using clean dataset to train the model to restore the model performance after we get the erased model.
构造两种专属数据集
Mismatched Dataset
顾名思义,这是一批输入和输出“八竿子打不着”的问答对。它们经过精心设计,用于扰乱模型本来的“触发-输出”粘连。
-
数据来源:使用如 Guanaco 等多任务数据集,随机打乱问答配对。
-
重建形态:被重构为对话流格式,引导模型在“答错”的同时不崩溃。
它的作用,是让模型试图学习无意义的映射,从而破坏掉之前那些“异常指纹”。
Clean Dataset
既然我们主动打乱了模型的记忆,那自然也需要帮它“找回正常节奏”。
-
数据选自高质量问答合集,与真实任务密切相关。
-
目标是恢复模型的语言能力、常识问答水平和逻辑组织力。
这种“先打乱、再扶正”的策略,使得模型忘掉该忘的,记住该记的。
两阶段训练过程
-
第一阶段:Erase(擦除)使用 mismatched dataset 微调模型,打散原有指纹所依赖的输入-输出关联,引导模型“松动”这些记忆。
-
第二阶段:Recover(恢复)再用 clean dataset 微调模型,恢复其语言能力、逻辑组织和任务能力,避免性能损失。
这种设计不仅彻底擦除了多种指纹(各种方法的指纹触发率可降为 0%),同时在各类下游任务中稳定恢复模型表现(如 SuperGLUE 准确率几乎无损)。
LoRA 让“擦除”也能迁移复制
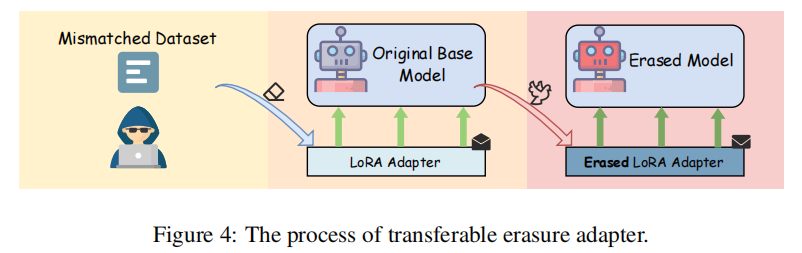
如果每次擦除都要重新训练,是不是太累了?尤其在模型被反复克隆的今天,攻击者总不能每次都手动清洗。于是,MEraser 又进一步提出了一个亮点:可迁移的擦除机制。 具体来说:
-
首先,在一个无指纹的原始模型上训练一个专用于擦除的 LoRA 插件(只训练 adapter,保持主模型不变)。
-
然后,把这个“擦除 LoRA 适配器”迁移到其他带指纹的模型中。
-
模型加载后会自动继承“擦除能力”,实现 plug-and-play 式快速去指纹。
好处是:
-
不需要知道具体指纹是怎么埋下的,也不需要动原始模型参数;
-
训练只需一次,后续可多次部署;
-
具备较高的通用性和实用性。
在实验中,这种“迁移式魔术贴”擦除效果也相当可观 —— 可在多个模型架构之间共享使用,极大降低成本与部署复杂度,为实际应用描绘出极具前景的场景。
现在我们已经了解了 MEraser 的三个秘密武器:
-
理论上,它聪明地利用“错配扰乱 + 有序恢复”实现精准选择性遗忘;
-
实践中,它用两阶段轻量训练重洗模型记忆;
-
工程上,它借助 LoRA,让擦除效果像插件一样“跨模复制”。
接下来,我们将走入实验验证环节,看看 MEraser 是不是真能“神不知鬼不觉”地让指纹全数消失……
MEraser 真正动手,试试擦得有多干净?
实验配置
为了验证 MEraser 的通用性和稳健性,研究团队在多种结构各异、应用广泛的大语言模型(LLM)上展开实验,涵盖了代表性强、覆盖面广的模型类型。主要包括:Meta 发布的 LLaMA2-7B,它被认为是当前结构平衡、语言能力出色的开源旗舰模型;Mistral-7B-v0.3,这是一款以高效轻量著称的新一代语言模型,注重推理能力与部署效率;以及 AmberChat-7B,一款对话风格更强的模型,贴合实际聊天机器人场景的使用需求。除此之外,MEraser 还在更大(如 LLaMA 13B)和更小(如 OPT-125M)规模的模型中进行了扩展评估,以测试其在不同体量和构架间的迁移适应能力。
在指纹类型的选择上,研究者特别选用了三种具代表性的后门式模型指纹方法,覆盖从强植入到易转移的多种形态:第一种是 IF-SFT(Instructional Fingerprint),通过特定“触发输入”激活预设输出,属于多对一格式,嵌入牢固、擦除难度较高;第二种为 UTF(Under-Trained Fingerprints),它巧妙地借用了训练中学习较差的“低频词”,作为指纹触发点,灵活但稳定性差,因此较容易被扰乱,是浅层擦除策略的理想测试对象;第三种是 HashChain(HC),采用加密散列方式设计一对一的触发机制,更具隐蔽性和一致性,擦除难度介于前两者之间。选择这三类不同攻击策略的指纹方案,也帮助评估 MEraser 在不同攻击机制下的通用能力。
至于数据部分,为了实现“先打乱、再恢复”的训练策略,MEraser 构建了两个专用的数据集。首先是 Mismatched Dataset,共计 300 条问答对,源自开源 Guanaco 对话数据,但经随机错配处理,确保输入和输出毫不相关,目的是打破模型对原始触发-响应的依赖联想,促使其遗忘指纹逻辑。随后是 Clean Dataset,共计 600 条,精选自同一数据集中的高质量问答对,语义清晰、格式规范,用于帮助模型在“擦除”后的状态下恢复正常语言理解与表达能力。令人惊艳的是,整个 MEraser 过程总共只动用了不到 1,000 条数据样本,远远少于传统微调动辄几万甚至上百万条的规模,展现出了极高的样本效率与实用性。
MEraser 的效果到底怎么样——有效性和无害性?
要评估一项指纹擦除技术是否真的“靠谱”,我们主要看两个核心指标:
-
Effectiveness(有效性):到底有没有真的把模型中那些后门指纹彻底清除?也就是说,被触发时不该再出现特定的“预设回应”。
-
Harmlessness(无害性):在成功擦除指纹的同时,模型有没有“变傻”?它是否还能正常写作、问答、理解语言?不能“只顾除旧”,还得保证“迎新也好”。
实验结果一览:指纹全清除,模型性能稳住了!
研究者通过在 LLaMA2-7B、Mistral-7B 和 AmberChat-7B 上测试三种不同类型的指纹(IF-SFT、UTF、HashChain),进行了系统对比。在擦除前,这些模型的 FSR(指纹触发成功率)都是 100%,说明埋入的后门“很稳”。但应用 MEraser 后,FSR 立刻下降为 0%,也就是模型已经完全“忘掉了”这些秘密指令!
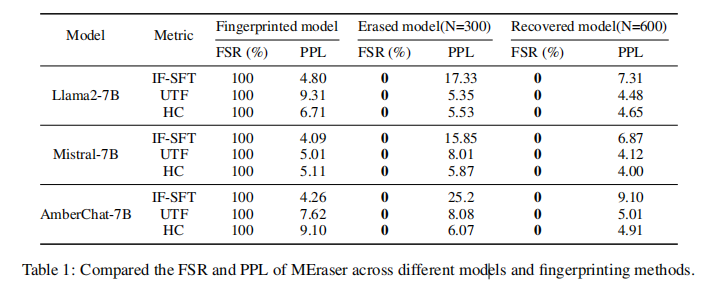
表 1:不同模型和指纹类型在 “指纹前 → 擦除后 → 恢复后” 三阶段下的 FSR & PPL 变化
不仅如此,虽然在擦除阶段使用了大量“错配语义”的训练数据,MEraser 在恢复阶段使用 clean dataset 后,成功使得指标如 PPL(困惑度)恢复到几乎和原模型一致,甚至在某些任务上,还因为轻度“正则化”而意外提升了泛化表现。
进一步验证:任务性能没有掉队!
为了更全面评估 Harmlessness,研究者还对擦除前后的模型在多个下游任务中进行了测试,包括:
-
SuperGLUE 基准任务(如 RTE、WSC、CoPA 等)
-
SciQ 科学问题问答任务
结果显示,在完成恢复阶段后,模型在多个任务上的表现几乎未下降,甚至部分任务略有上扬,说明模型的能力不仅保持住了,还更“专注”了。
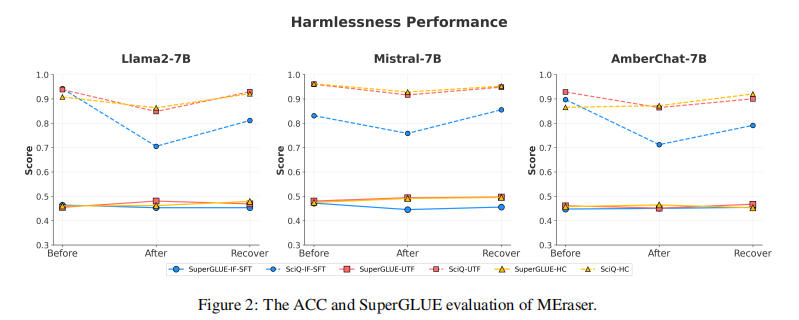
图 2:MEraser 前后模型在 SuperGLUE & SciQ 上的性能对比图
总体来看,MEraser 在多个维度上都交出了令人满意的答卷:能擦、能稳、还不伤脑筋。而且最令人惊喜的是,整个过程只用了不到千条数据,真正做到了“轻巧高效”。下一部分,我们将看看 MEraser 与业界现有的一些指纹擦除方法相比,又有怎样的优势。
谁更会“擦”?MEraser 与其他方法的正面对比
MEraser 看起来相当厉害,但如果没有比较,就难以凸显它到底“赢在了哪里”。为了证明它并不是“纸上谈兵”,研究者将 MEraser 与现有主流的指纹擦除方法进行了全面对比,涵盖了模型层面和推理层面的多种技术路线。
这就像让几位“清洁高手”同台竞技:谁能擦得最干净?谁手法不暴力?谁成本最低?谁能一劳永逸?
模型级擦除方法:不是没效果,就是“太狠”
首先来看几种目前模型层面上常用的指纹移除方法。从直觉出发,或许最自然的做法就是“重新训练”模型,让它逐步淡化甚至覆写掉之前的指纹信息。这类方法被称为增量微调(Incremental Fine-Tuning),它通过新的正常数据对模型进行继续训练。然而,这种方式虽然简单,但代价极高:不仅需要大量算力和数据,而且对一些多对一设计的稳固指纹(比如 IF-SFT)根本无效,指纹仍旧顽固存在。
另一种思路是“硬件式”的断根法——模型剪枝(Model Pruning)。通过挑选与指纹关联性更高的参数,从模型中直接剪掉,希望能一次性清除。这看似高效,其实非常容易“伤筋动骨”:一不小心就删除了模型中负责正常语言理解和生成的权重,导致效果严重下降,而且剪完之后并不能保证指纹真的就被移除了,因此整体实用性有限。
还有一种相对“温和”的方式是模型融合(Model Merging),代表性方法如 Task Arithmetic 和 DARE,它们的做法是将目标模型与一个干净模型“合并”——本质上是混合它们的参数,试图稀释原模型中的指纹影响。这类方法在某些情况下效果不错,尤其是针对 UTF 和 IF 类型的指纹有一定作用,但面对更复杂隐蔽的 HashChain 指纹就力不从心了。
综上来看,MEraser 的优势就非常突出:它是当前极少数能够实现指纹完全移除(FSR = 0%),同时 保持模型性能不受重创(低 PPL) 的方案。也就是说,它不仅“擦得干净”,也“擦得温柔”,真正兼顾了安全性与实用性。
推理级擦除方法:聪明但局限多
另一类方法不修改模型本体,而是通过在推理层做手脚来“规避触发”:
-
Token Forcing(TF):苦力活,用暴力枚举猜测可能的触发词序列,再让模型绕开,可行,但极其耗时,对高级触发机制(如哈希映射)无效。
-
CleanGen:通过使用“参照模型”对照输出概率,找出可能隐藏指纹的触发点。理论上漂亮,但现实中难以找到和目标模型训练数据完全一致的“干净对照”,也容易误删正常知识。
结局还是一样:MEraser 不仅能擦净指纹,而且过程轻量、不依赖外部模型、不用猜密语,可谓“真正适合实战”的方案。
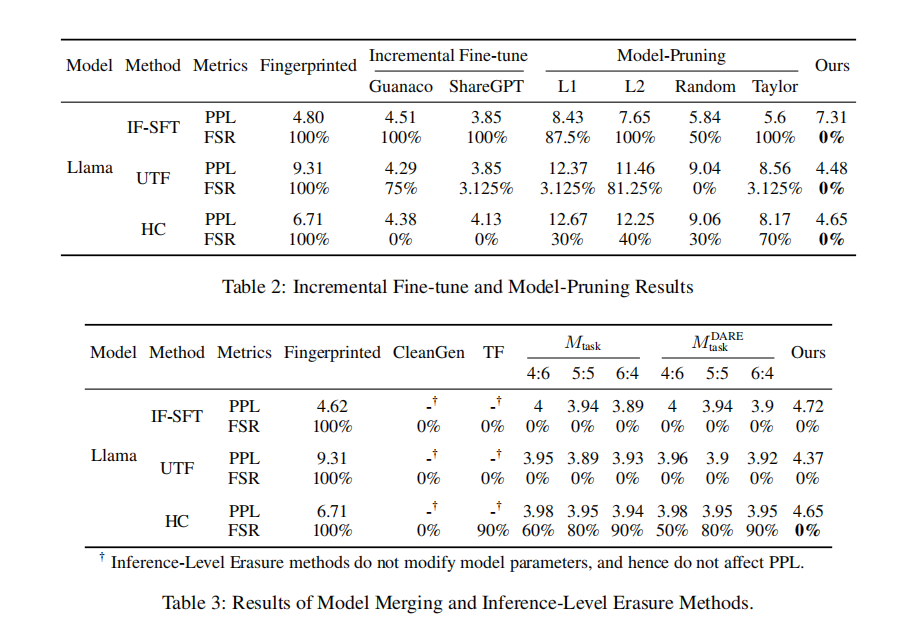
MEraser 的独门秘籍:一次训练,处处适用
尤其亮眼的一点是——MEraser 的「可迁移擦除能力」。只需在一个“干净模型”上训练一次 LoRA 删除适配器,就可以把这个“擦除插件”复用到多个指纹模型中。
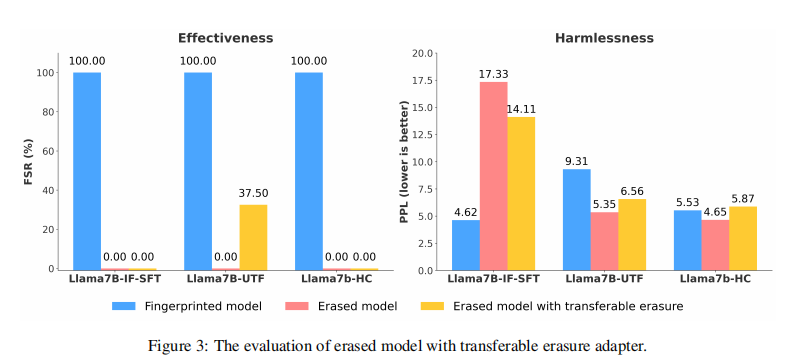
图 3:LoRA 擦除模块迁移效果图:不同模型加载同一擦除 LoRA 后,FSR 大幅下降
总结
当大语言模型成为AI时代的“新大脑”,围绕它们的知识产权、授权使用与安全验证问题也愈发复杂。
模型指 的出现,为模型确权提供了一种技术路径;而指纹擦除,则是对抗性玩法下的应对之策。 MEraser 的出现,不仅让我们初步见识到“擦拭指纹”在技术上的可能性,更深远的意义在于:它揭开了当前指纹植入机制所依赖的关键脆弱点,也提示我们——未来的大模型版权验证,仅靠“埋一个触发器”可能远远不够。
技术,从来都不是单向演进。Just as we watermark, we must also test the unwatermarkable.MEraser 不仅是一种擦除手段,更像是一面镜子——它逼迫我们重新审视模型可信验证的底层机制,并思考更稳健、更高维度的模型安全范式。
内容来源:IF实验室

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)