NLP基础(十三)_训练流程对比
NLP基础(十三)_训练流程对比
4.3 为何需要“负采样”
“负采样”(Negative Sampling)
直接用 softmax,每一步都要对∣V∣个词打分,对大词表很慢。
负采样把“多分类”换成一堆“二分类”:
- 正样本:真实共现对 (w,c),标签 1。
- 负样本:从某个噪声分布 Pn 随机抽 k个词
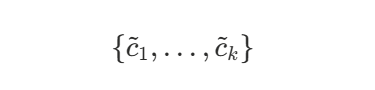
与 w 人为配对,标签 0。
- 用 logistic 回归的交叉熵损失替代 softmax:
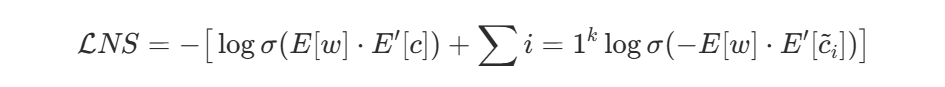
其中
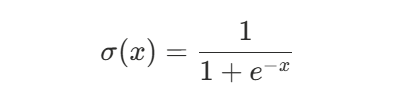
关键设定
-
k:每个正样本采多少负样本(常见 5–20,语料大时可更小)。
-
噪声分布 Pn:通常按词频 U(w) 的 3/4 次幂做重采样,即
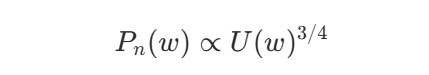
直觉:降低超高频词被采中的概率,使负样本更有信息量。
-
训练复杂度从 O(∣V∣) 降为 O(k),速度大幅提升,且效果与 softmax 相当或更好。
(另有 Hierarchical Softmax 方案,用哈夫曼树把计算降到 O(log∣V∣),在小语料或超大词表时也常用。)
4.4why隐藏层权重是词向量
为什么“隐藏层权重”就是词向量
Word2Vec 没有非线性隐藏层:查表(embedding lookup)→ 求和/平均 → 线性打分。
因此,模型能表达的关系基本都压在词向量的方向与长度里。
-
训练目标等价于:让真实共现的 (w,c) 点积变大,让采来的负样本点积变小。
这会把语义接近(共现分布相似)的词推到相近方向。
-
更形式化地(负采样近似,有经典推导):
在最优点,点积会近似
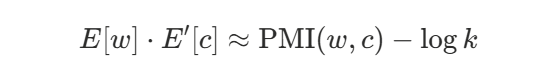
其中
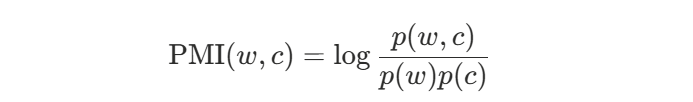
这说明 Word2Vec 在隐式分解(shifted)PMI 共现矩阵,所以嵌入矩阵本身就是你要的词向量表示。
-
实践里常用 输入嵌入 E 作为词向量;也有人把 E 与 E′ 做平均或拼接。
4.5 词向量空间的语义运算
词向量空间里的“语义运算”(类比)
经典例子:
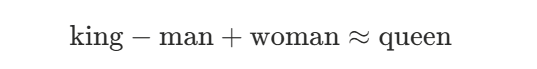

(1)怎么算?(3CosAdd)
给定 a : b::c : ?,求
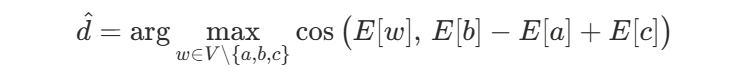
实践小技巧:用余弦相似度、对向量做均值去中心 + 归一化能更稳。
(2)能泛化的关系
-
国家–首都:Paris − France + Italy ≈ Rome
-
现在式–过去式:walking − walk + go ≈ went
它们都对应近似的“平移向量”,说明模型学到了线性化的关系结构。
(3)注意局限
- 并非所有关系都线性、也并非语义都能“一根向量”解释(多义词、长尾词)。
- 语料与窗口选择会影响能学到哪些关系。
- 现代模型(如 GloVe、fastText、上下文嵌入)在很多任务上更强。
4.6 训练中的关键工程点
训练中的关键工程点(影响效果的超参)
- 窗口大小 m:小窗口(2–5)更偏语法,大窗口(5–10+)更偏语义。
- 模型选择:CBOW 快、对高频词好;Skip-Gram 对稀有词友好。
- 维度 d:100–300 是经典范围;语料越大可更高。
- 负样本数 k:常 5–15(英文大语料 5~10 就够)。
- 高频词下采样(t≈10^{−5}):随机丢弃极高频词(如“的”“了”“the”),提速且提质。
- min_count:过滤低频词,减少噪声。
- 归一化:用余弦时可把向量先 L2 归一化;做类比可再做去均值处理。
4.7 训练流程
一眼看懂的训练流程(Skip-Gram + 负采样)
- 扫语料,取每个中心词 wt的窗口 C。
- 对每个 c∈C 构造正样本 (wt,c)。
- 从 Pn 采 k 个负样本 c̃
- 计算损失 LNS,对 E[wt] 和 E′[c],E′[c~] 做梯度更新。注:这里的c~即C上面带个波浪号。
- 重复直到收敛;训练完把 E(或 E ⊕ E′)导出当作词向量。
小结
- CBOW:用上下文预测中心词;Skip-Gram:用中心词预测上下文。
- 负采样:把大词表 softmax 变成若干二分类,快且好用。
- 隐藏层权重=词向量:训练把“共现统计”编码进点积,等价于分解(位移过的)PMI。
- 语义运算可线性化:很多关系接近“平移向量”,因此能做类比。
一个极小的 Skip-Gram+NS,并把几个词的最近邻与“类比计算”结果列出来,对上面的公式来一把“可视化验收”。
import numpy as np
import random
from collections import Counter
# ===== 1. 准备极小语料 =====
corpus = "国王 喜欢 城堡 女王 喜欢 城堡 男人 喜欢 足球 女人 喜欢 足球".split()
# ===== 2. 建立词表 =====
vocab = sorted(set(corpus))
word2idx = {w:i for i,w in enumerate(vocab)}
idx2word = {i:w for w,i in word2idx.items()}
V = len(vocab)
# ===== 3. 超参数 =====
d = 10 # 词向量维度
window = 2 # 窗口大小
k_neg = 3 # 每个正样本采样负例数
lr = 0.05
epochs = 200
# ===== 4. 初始化参数 =====
rng = np.random.default_rng(42)
W_in = rng.normal(0,0.01,(V,d)) # 输入向量
W_out = rng.normal(0,0.01,(V,d)) # 输出向量
# ===== 5. 构建 Skip-Gram 样本 (中心词, 上下文) =====
pairs = []
for i, w in enumerate(corpus):
for j in range(max(0,i-window), min(len(corpus), i+window+1)):
if i != j:
pairs.append((word2idx[corpus[i]], word2idx[corpus[j]]))
# ===== 6. 负采样概率(词频^0.75) =====
freq = Counter(corpus)
counts = np.array([freq[w] for w in vocab], dtype=float)
p_noise = counts**0.75 / np.sum(counts**0.75)
def sigmoid(x): return 1/(1+np.exp(-x))
# ===== 7. 训练 Skip-Gram + NS =====
for epoch in range(epochs):
random.shuffle(pairs)
for w,c in pairs:
# --- 正样本 (w,c), label=1 ---
s_pos = W_in[w] @ W_out[c]
g_pos = sigmoid(s_pos) - 1
W_in[w] -= lr * g_pos * W_out[c]
W_out[c] -= lr * g_pos * W_in[w]
# --- 负样本 ---
negs = np.random.choice(V, k_neg, p=p_noise)
for neg in negs:
s_neg = W_in[w] @ W_out[neg]
g_neg = sigmoid(s_neg) - 0
W_in[w] -= lr * g_neg * W_out[neg]
W_out[neg] -= lr * g_neg * W_in[w]
# ===== 8. 结果查看函数 =====
emb = W_in # 输入向量作为词向量
def cosine(u,v):
return float(u@v / ((np.linalg.norm(u)+1e-9)*(np.linalg.norm(v)+1e-9)))
def most_similar(word, topn=3):
v = emb[word2idx[word]]
sims = [(w, cosine(v, emb[i])) for w,i in word2idx.items() if w!=word]
return sorted(sims, key=lambda x:-x[1])[:topn]
def analogy(a,b,c, topn=3):
vec = emb[word2idx[b]] - emb[word2idx[a]] + emb[word2idx[c]]
sims = [(w, cosine(vec, emb[i])) for w,i in word2idx.items() if w not in (a,b,c)]
return sorted(sims, key=lambda x:-x[1])[:topn]
# ===== 9. 测试 =====
print("相似词(国王):", most_similar("国王", topn=5))
print("相似词(女人):", most_similar("女人", topn=5))
print("类比: 男人 : 国王 :: 女人 : ?", analogy("男人","国王","女人", topn=5))
这个符号 “::”(双冒号)在这里不是编程里的语法,而是类比表达的常见写法。
-
男人 : 国王读作 “男人 之于 国王” -
女人 : ?读作 “女人 之于 ?” -
合起来:
男人 : 国王 :: 女人 : 女王就是 “男人 之于 国王,正如 女人 之于 女王”。
极小 CBOW + NS 示例
import numpy as np
import random
from collections import Counter
# ===== 1. 极小语料 =====
corpus = "国王 喜欢 城堡 女王 喜欢 城堡 男人 喜欢 足球 女人 喜欢 足球".split()
# ===== 2. 词表 =====
vocab = sorted(set(corpus))
word2idx = {w:i for i,w in enumerate(vocab)}
idx2word = {i:w for w,i in word2idx.items()}
V = len(vocab)
# ===== 3. 超参数 =====
d = 10 # 词向量维度
window = 2 # 窗口大小
k_neg = 3 # 每个正样本负例数
lr = 0.05
epochs = 200
# ===== 4. 初始化向量 =====
rng = np.random.default_rng(42)
W_in = rng.normal(0,0.01,(V,d)) # 输入向量
W_out = rng.normal(0,0.01,(V,d)) # 输出向量
# ===== 5. 构建 CBOW 样本 (上下文 -> 中心词) =====
pairs = []
for i, w in enumerate(corpus):
context = []
for j in range(max(0,i-window), min(len(corpus), i+window+1)):
if i != j:
context.append(word2idx[corpus[j]])
if context: # (context_idxs, center_idx)
pairs.append((context, word2idx[w]))
# ===== 6. 负采样分布 =====
freq = Counter(corpus)
counts = np.array([freq[w] for w in vocab], dtype=float)
p_noise = counts**0.75 / np.sum(counts**0.75)
def sigmoid(x): return 1/(1+np.exp(-x))
# ===== 7. 训练 CBOW + NS =====
for epoch in range(epochs):
random.shuffle(pairs)
for context, center in pairs:
# CBOW: 上下文向量 = 平均
h = np.mean(W_in[context], axis=0)
# --- 正样本 ---
s_pos = h @ W_out[center]
g_pos = sigmoid(s_pos) - 1
grad = lr * g_pos * W_out[center]
for c in context:
W_in[c] -= grad
W_out[center] -= lr * g_pos * h
# --- 负样本 ---
negs = np.random.choice(V, k_neg, p=p_noise)
for neg in negs:
s_neg = h @ W_out[neg]
g_neg = sigmoid(s_neg) - 0
grad = lr * g_neg * W_out[neg]
for c in context:
W_in[c] -= grad
W_out[neg] -= lr * g_neg * h
emb = W_in # 输入嵌入作为词向量
# ===== 8. 辅助函数 =====
def cosine(u,v):
return float(u@v / ((np.linalg.norm(u)+1e-9)*(np.linalg.norm(v)+1e-9)))
def most_similar(word, topn=3):
v = emb[word2idx[word]]
sims = [(w, cosine(v, emb[i])) for w,i in word2idx.items() if w!=word]
return sorted(sims, key=lambda x:-x[1])[:topn]
def analogy(a,b,c, topn=3):
vec = emb[word2idx[b]] - emb[word2idx[a]] + emb[word2idx[c]]
sims = [(w, cosine(vec, emb[i])) for w,i in word2idx.items() if w not in (a,b,c)]
return sorted(sims, key=lambda x:-x[1])[:topn]
# ===== 9. 测试 =====
print("相似词(国王):", most_similar("国王", topn=5))
print("相似词(女人):", most_similar("女人", topn=5))
print("类比: 男人 : 国王 :: 女人 : ?", analogy("男人","国王","女人", topn=5))
跑了同一份极小语料,在 Skip-Gram 和 CBOW 两种模式下,得到了不同的相似度和类比结果。这里面有几个值得理解的点:
- Skip-Gram 结果
相似词(国王): [('女王', 0.26), ('男人', 0.07), ('女人', -0.02) ...]
相似词(女人): [('男人', 0.91), ('喜欢', 0.82), ('女王', 0.61) ...]
类比: 男人 : 国王 :: 女人 : ? [('女王', 0.16), ...]
- “国王”和“女王”有一点点相似(0.26),但不算强,因为语料太小。
- “女人”和“男人”的相似度很高(0.91),说明 Skip-Gram 把“女人–男人”这一对近义(对偶)学到了。
- 类比任务中,“女王”排在第一,但分数 0.16 很低 → 模型“隐约”捕捉到类比关系,但不稳。
- CBOW 结果
相似词(国王): [('女王', 0.84), ('男人', 0.70), ('足球', 0.56) ...]
相似词(女人): [('男人', 0.83), ('国王', 0.54), ('女王', 0.32) ...]
类比: 男人 : 国王 :: 女人 : ? [('城堡', 0.58), ('女王', 0.26), ...]
-
“国王”和“女王”相似度很高(0.84) → CBOW 在小语料下更容易学到这种共现。
-
“女人”和“男人”的相似度也很高(0.83),合理。
-
但类比任务时,“城堡”排第一,“女王”才第二 → CBOW 把“城堡”与“国王/女王”捆绑太紧(因为语料里国王/女王总是和城堡一起出现)。
所以在推“男人:国王 :: 女人: ?”时,它受上下文干扰太大,结果偏了。
- 总结差异
-
Skip-Gram
更擅长建模 罕见词和类比关系(但需要更多语料才能明显看出来)。在你的小语料下,已经能 faintly 抓到 “国王-男人+女人≈女王”。
-
CBOW
更快收敛,擅长学到 频繁的上下文共现。在你的小语料里,它更快把“国王–女王”看作一对,但因为数据太少,类比任务容易被“城堡”这种高频上下文词干扰。
- 结果说明
- 小语料下,Skip-Gram 的类比效果 稍微比 CBOW 好(尽管分数低)。
- CBOW 的相似度更“强”,但类比受共现干扰。
- 如果换更大语料(比如维基百科),两者都会表现好:
- CBOW:快,适合大数据。
- Skip-Gram:更精准,适合稀疏词、类比关系。
- Skip-Gram:把每个位置的中心词与其窗口内的每个上下文词配对,形成很多
(中心词idx, 上下文词idx)。 - CBOW:把每个位置窗口内的所有上下文词收集成一个列表,再与中心词配对,形成
(上下文idx列表, 中心词idx)。
窗口由 window 控制,代码用
range(max(0,i-window), min(len(corpus), i+window+1))
来裁剪边界,避免越界;if i != j 用来排除中心词自己。
代码逐句读
pairs = []
if mode == "skipgram":
# Skip-Gram: (中心, 上下文)
for i, w in enumerate(corpus):
# j 在 [i-window, i+window] 的闭区间上滑动,但被裁剪到 [0, len(corpus)-1]
for j in range(max(0,i-window), min(len(corpus), i+window+1)):
if i != j: # 不跟自己配对
pairs.append((word2idx[corpus[i]], word2idx[corpus[j]]))
else:
# CBOW: (上下文列表, 中心)
for i, w in enumerate(corpus):
context = []
for j in range(max(0,i-window), min(len(corpus), i+window+1)):
if i != j:
context.append(word2idx[corpus[j]])
if context: # 边界极端情况防空
pairs.append((context, word2idx[w]))
- Skip-Gram:对每个中心位置
i,把窗口内每个j (≠ i)都记一条样本;因此一对多。 - CBOW:对每个中心位置
i,先把所有上下文j (≠ i)收集进context列表,再一次性加一个样本(上下文列表 → 中心);因此多对一。 - 注意:CBOW 上下文是列表(顺序在后续训练中并不重要);你的训练里是做平均,所以顺序不影响结果。
- 如果窗口里有重复词(比如“喜欢”在窗口两侧都出现),Skip-Gram 会出现两次(位置不同),CBOW 的
context列表里也会包含两次该词的索引。
例子 1(最直观的小玩具)
语料:["A", "B", "C", "D"],window = 1
(只看相邻一个词)
Skip-Gram
对每个位置 i:
- i=0,中心 A,上下文窗口裁剪为
[0,1]去掉自己 → 只剩 j=1 →(A, B) - i=1,中心 B,窗口
[0,2]去自己 →(B, A),(B, C) - i=2,中心 C,窗口
[1,3]去自己 →(C, B),(C, D) - i=3,中心 D,窗口
[2,3]去自己 →(D, C)
Skip-Gram 的 pairs(用词显示,实际存 idx):
(A,B),
(B,A), (B,C),
(C,B), (C,D),
(D,C)
CBOW
对每个位置 i(中心在 i):
- i=0:上下文
[B]→([B], A) - i=1:上下文
[A, C]→([A, C], B) - i=2:上下文
[B, D]→([B, D], C) - i=3:上下文
[C]→([C], D)
CBOW 的 pairs:
([B], A),
([A, C], B),
([B, D], C),
([C], D)
你会发现:Skip-Gram把一行 CBOW 的上下文拆成多行;CBOW把 Skip-Gram 的多行合成一行(上下文列表)。
例子 2(用你语料的一段,展示“重复词进窗口”的情形)
取你语料的前 6 个词,window = 2:
[国王, 喜欢, 城堡, 女王, 喜欢, 城堡]
索引:0 1 2 3 4 5
看一个“中心 = 城堡(i=2)”的情况:
Skip-Gram(中心 i=2)
窗口范围:max(0,2-2)=0 到 min(6,2+2+1)=5 → j ∈ {0,1,2,3,4} 去掉自己 2
上下文词序列(按位置):[国王(0), 喜欢(1), 女王(3), 喜欢(4)]
注意“喜欢”在 1 和 4 两个位置各出现一次,所以会生成两条样本:
样本:
(城堡, 国王), (城堡, 喜欢), (城堡, 女王), (城堡, 喜欢)
“喜欢”出现了两次,训练时就相当于这两个上下文信号各被看到一次,对参数更新也会有两次贡献。
CBOW(中心 i=2)
同样的窗口里,上下文列表就是:
[国王, 喜欢, 女王, 喜欢]
因此一条样本:
([国王, 喜欢, 女王, 喜欢], 城堡)
因为你后续用的是均值,这个列表里“喜欢”出现两次,会让“喜欢”的向量在均值里权重更大(出现两次就被平均两次),这与 Skip-Gram 的两次更新是同一件事的另一种表达。
你抓住的点非常关键,就是 CBOW 的“均值 + 重复” 和 Skip-Gram 的“多次更新” 看似类似,但其实不是一模一样。下面我帮你拆开:
- Skip-Gram 的处理方式:
以 中心词=城堡,上下文窗口包含 [国王, 喜欢, 女王, 喜欢] 为例。
-
Skip-Gram 会生成 4 个样本:
(城堡, 国王), (城堡, 喜欢), (城堡, 女王), (城堡, 喜欢) -
每个 pair 都会独立训练一次。
-
所以 “喜欢”出现两次,就真的更新了两次。
-
更新时,梯度和学习率是逐条单独计算的。
换句话说:Skip-Gram 是 重复词 → 重复训练步骤。
- CBOW 的处理方式:
同样的窗口 [国王, 喜欢, 女王, 喜欢]。
-
CBOW 只会生成 1 个样本:
([国王, 喜欢, 女王, 喜欢], 城堡) -
在训练时,先取所有上下文向量的平均值:

-
注意,“喜欢”出现了两次,因此在平均里它被算了两次。
-
但是,最终只进行一次更新(用这个平均向量来预测中心词)。
换句话说:CBOW 是 重复词 → 在均值里权重更大,但更新次数还是一次。
- “另一种表达”的含义
我之前说 CBOW 的“重复计入均值”是 Skip-Gram 的“重复训练”的另一种表达,意思是:
- 两者都能体现出 上下文中出现多次的词 对训练结果更重要。
- Skip-Gram:通过“出现一次 → 更新一次”来表现;
- CBOW:通过“均值里多算一遍”来表现。
它们的结果方向是一致的:频繁出现的上下文词影响更大。
但实现机制不一样。
- 核心区别总结
| 特点 | Skip-Gram | CBOW |
|---|---|---|
| 更新次数 | 上下文词出现几次就更新几次(逐对更新) | 所有上下文合成一次平均,再更新一次 |
| 训练粒度 | 精细,每个 (中心, 上下文) 单独学 | 粗一些,一次用整个上下文来学 |
| 重复词影响 | 出现 2 次 → 真正更新 2 次 | 出现 2 次 → 平均里权重 2/总数 |
| 效果 | 更适合低频词(训练信号多) | 更适合高频词(上下文丰富时更稳定) |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)