Jay Alammar 博客笔记:拆解 Word2vec的思路演进(逻辑链)
本文系统梳理了Word2vec的核心原理与实现逻辑。从词向量表示的基本直觉出发,通过人格测试类比阐释了Embedding的本质。重点剖析了Skip-gram架构如何通过上下文预测任务学习词向量,并深入解析负采样技术如何将计算复杂度从百万级降至常数级,解决了传统Softmax的效率瓶颈。文章还总结了窗口大小、负样本数量等关键超参数的影响,完整呈现了Word2vec从理论到工程实践的全貌。通过清晰的逻
Jay Alammar 博客笔记:拆解 Word2vec的思路演进(逻辑链)
前言
本文核心内容基于 Jay Alammar 的经典神作 The Illustrated Word2vec,并结合《Speech and Language Processing》相关章节进行了深度梳理。
很多同学都用过
gensim,也听过“国王 - 男人 + 女人 = 王后”的经典例子,但 Word2vec 到底是怎么“炼”出来的?为什么有了 Skip-gram 还需要负采样(Negative Sampling)?如果不把这些逻辑串起来,面试时很容易卡壳。这篇文章主打逻辑串联和直觉理解,带你从零推导 Google 是如何把人类语言的规律压缩进向量空间的。
1. 向量表示的直觉:从“性格测试”说起
我们先不谈 NLP,先谈谈如何用数字描述一个人。这对于理解“嵌入(Embedding)”至关重要。
1.1 逻辑链:从 ID 到 向量
逻辑链条
- 问题 / 动机:计算机只认数字,如何表示“张三”、“李四”这样复杂的人?
- 朴素方案(One-hot/ID):给每个人发个身份证号(张三=1001,李四=1002)。
- 局限 / 失败点:ID 是独立的符号。1001 和 1002 在数学上很近,但在现实中,张三和李四可能毫无共同点。我们无法通过 ID 计算“相似度”。
- 改进思路(Vector/Embedding):用一组“属性分数”来表示一个人。
1.2 直觉解释:人格嵌入示例
假设我们用 5 个维度来测评一个人(范围 -1 到 1)。就像心理学的大五人格测试(外向性、神经质等):
| 维度 | 我 (Jay) | 某人 A | 某人 B |
|---|---|---|---|
| 内向/外向 | -0.2 (偏内向) | -0.8 | 0.9 |
| 神经质 | 0.6 | 0.7 | -0.1 |
| … | … | … | … |
| 维度 5 | 0.1 | 0.2 | -0.5 |
此刻,“我”不再是一个 ID,而是一个向量 ([-0.2, 0.6, \dots, 0.1])。
一旦万物皆为向量,我们就可以用几何学的方法来衡量关系。判断两个人像不像,就是算两个向量夹角的余弦相似度 (Cosine Similarity):
similarity=cos(θ)=A⋅B∥A∥∥B∥ \text{similarity} = \cos(\theta) = \frac{A \cdot B}{\|A\| \|B\|} similarity=cos(θ)=∥A∥∥B∥A⋅B
- 完全同向:值为 1(性格完全一致)。
- 正交(90度):值为 0(毫无关系)。
- 反向(180度):值为 -1(性格截然相反)。
2. 词嵌入(Word Embeddings):语言的几何学
现在把“人”换成“词”。
2.1 词向量的可视化
在 NLP 中,我们无法预定义“外向性”这种明确的特征。我们让机器自己去学 50 维、300 维甚至更高维度的特征。
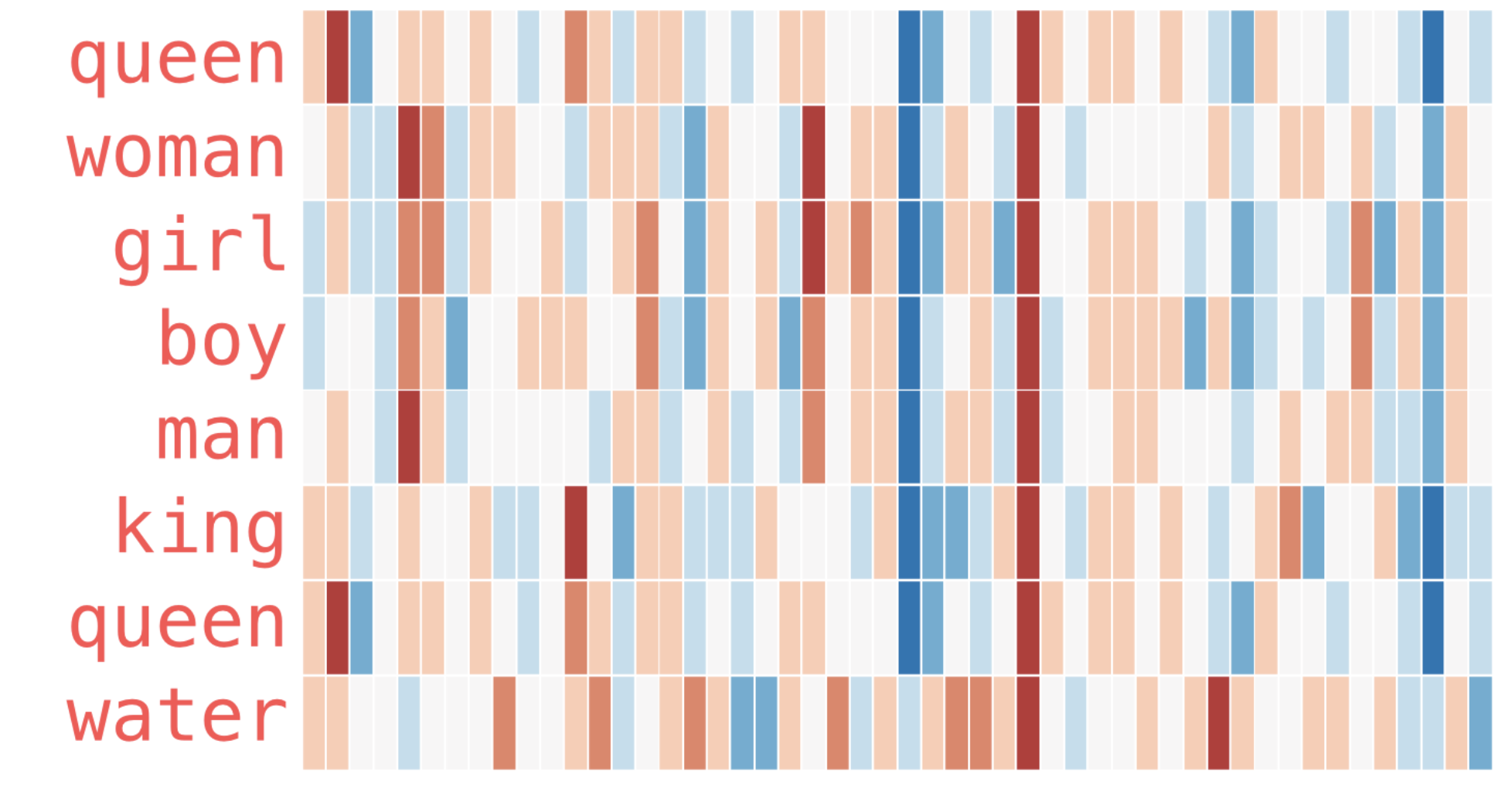
如果我们把单词 “King” 的向量打印出来,可能是一串看不懂的浮点数。但如果我们给数值上色(红色为正,蓝色为负),就能看到条带状的纹理。
- 观察发现:“Woman” 和 “Girl” 的色带纹理非常相似;“Man” 和 “Boy” 也很相似。
- 神奇之处:“Boy” 和 “Girl” 在某些特定维度上(可能代表“青春/幼年”的隐形特征)非常相似,但在代表“性别”的维度上截然不同。
2.2 著名的类比运算
向量空间最迷人的特性是线性代数运算具有语义含义:
King⃗−Man⃗+Woman⃗≈Queen⃗ \vec{King} - \vec{Man} + \vec{Woman} \approx \vec{Queen} King−Man+Woman≈Queen
这说明模型不仅把词变成了数字,还捕捉到了词与词之间平行的空间关系(Gender 维度的迁移)。
3. 语言模型:词向量的“训练场”
只要有了词向量,就能做很酷的事。但问题是:这堆数字最初是怎么得到的?
答案是:作为“预测下一个词”任务的副产品(Side Effect)。
3.1 神经语言模型 (Neural Language Model)
逻辑链条
- 问题 / 动机:我们需要一个能够预测下一个词的系统(比如手机输入法的联想功能)。
- 早期架构 (Bengio 2003):
- 输入单词的 ID。
- 查表得到临时词向量。
- 输入神经网络(隐藏层)。
- 输出层做 Softmax,预测整个词表中每个词的概率。
- 关键点:为了让预测更准,模型会拼命调整第 2 步的“词向量矩阵”。训练完了,预测模型可能不重要,但这个矩阵就是我们想要的 Word Embeddings。
4. Word2vec 的核心架构:Skip-gram
虽然 Bengio 的模型能学到向量,但它太慢了,因为它主要想做完美的语言模型。Google 的 Word2vec 团队想:如果只为了得到向量,能不能把任务简化?
4.1 从“预测未来”到“扫描上下文”
逻辑链条
- 朴素方案:使用 CBOW(Continuous Bag of Words),根据周围词预测中心词。
- 改进思路(Skip-gram):反其道而行之。给定一个中心词,去预测它周围的上下文词。
- 优势:Skip-gram 在处理生僻词时往往表现更好,因为每个词都被当做中心词单独训练过。
滑动窗口 (Sliding Window) 机制是其灵魂:
假设句子是:The quick brown fox jumps over the lazy dog。
窗口大小 = 2(看前后各 2 个词)。
当窗口滑到 “brown” 时:
- 中心词 (Input):
brown - 上下文 (Targets):
The,quick,fox,jumps
这就生成了 4 个训练样本对:
- (
brown,The) - (
brown,quick) - (
brown,fox) - (
brown,jumps)
5. 效率革命:负采样 (Negative Sampling)
这是 Word2vec 最精彩、也最常被考到的地方。
5.1 为什么传统的 Softmax 行不通?
逻辑链条
- 问题 / 动机:我们的词表 (|V|) 可能有 100 万个词。
- 局限 / 失败点:在标准神经网络中,最后一层是 Softmax。为了计算
brown预测fox的概率,分母需要把这 100 万个词的得分全部算一遍来进行归一化。
[ P(w_o|w_i) = \frac{e{score}}{\sum_{j=1}{1,000,000} e^{score_j}} ]- 后果:每训练一个样本都要算 100 万次,训练几年都练不完。
- 改进思路(SGNS):将“多分类问题”转化为“二分类问题”。
5.2 核心思想:把“找邻居”变成“判断题”
既然算 100 万个词太慢,那我们就不算全局概率了。我们把问题修改为:
“输入词 A 和输出词 B,是真正的邻居吗?” (Yes/No 问题)
为了训练这个二分类器,我们需要正样本和负样本:
- 正样本 (Positive):从文本中真实滑动出来的。
- Input:
brown, Context:fox, Label: 1
- Input:
- 负样本 (Negative):从词表中随机抽取几个不相干的词。
- Input:
brown, Context:taco(玉米卷), Label: 0 - Input:
brown, Context:apple(苹果), Label: 0
- Input:
5.3 极速训练过程与公式
现在,模型变成了一个简单的逻辑回归(Logistic Regression)。给定输入词向量 (v_c) 和上下文词向量 (u_o):
- 点积(Dot Product) 衡量相似度:
z=vc⋅uo z = v_c \cdot u_o z=vc⋅uo - Sigmoid 转换为概率:
σ(z)=11+e−z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1 - 计算误差与反向传播:
Error=Target−σ(z) \text{Error} = \text{Target} - \sigma(z) Error=Target−σ(z)
这一下把计算量从 100 万次降到了 k+1 次(k 通常是 5)。 这就是 Word2vec 能够在大规模语料上训练的原因。
6. 工程实践与超参数 (面试必读)
在实际炼丹(训练)时,有几个细节决定了词向量的质量。
6.1 窗口大小 (Window Size)
- 小窗口 (2-5):
- 模型只看极近的词。
- 捕获的是功能性/句法性相似度。
- 结果:Hogwarts 和 Oxford 会很像(都是学校,语法功能一样)。Good 和 Bad 也会很像(可以互换)。
- 大窗口 (15-50):
- 模型能看到更远的上下文。
- 捕获的是主题性/语义性相似度。
- 结果:Hogwarts 会和 Harry Potter, Wizard 更近。
6.2 负样本数量 (Negative Samples, (k))
- 小数据集:建议 (k = 5 \sim 20)。数据少,需要多一点负样本来辅助学习。
- 大数据集:建议 (k = 2 \sim 5)。数据多,负样本给够压力就行。
6.3 高频词降采 (Subsampling)
像 “the”, “a”, “is” 这种词出现频率太高,也没啥实际含义。Word2vec 会用一个概率公式扔掉这些词:
P(wi)=1−tf(wi)P(w_i) = 1 - \sqrt{\frac{t}{f(w_i)}} P(wi)=1−f(wi)t
其中 (f(w_i)) 是词频,(t) 是阈值。这能让模型更关注“稀有但重要”的词。
7. 总结:Word2vec 的极简逻辑
如果你在面试中被问到 Word2vec,请按这个逻辑回答:
- 目标:将词映射为稠密向量,捕捉语义。
- 架构:采用 Skip-gram,利用中心词预测上下文,利用海量文本自监督训练。
- 优化:因为 Softmax 计算量太大,引入 Negative Sampling。
- 本质:通过区分“真实邻居”和“随机噪音”,强迫向量在空间中根据共现关系进行聚类。
下章预告
Word2vec 虽然经典,但它有一个致命缺陷:多义词问题(Bank 是银行还是河岸?)。同一个词只能有一个向量。这直接催生了后来的 ELMo 和 BERT。我们下一章见!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)