LangChain 内置文档加载器使用技巧
本文介绍了LangChain框架中各类文档加载器的使用技巧。框架内置了上百种文档加载器,包括CSV、HTML、PDF、Office等格式,使用流程均为实例化加载器后调用load()函数。重点讲解了Markdown文档加载器UnstructuredMarkdownLoader的使用方法,包括安装依赖、基础加载和元素分割模式。同时介绍了Office文档(Excel/PPT/Word)加载器的安装配置和
01. 高频内置文档加载器的使用技巧
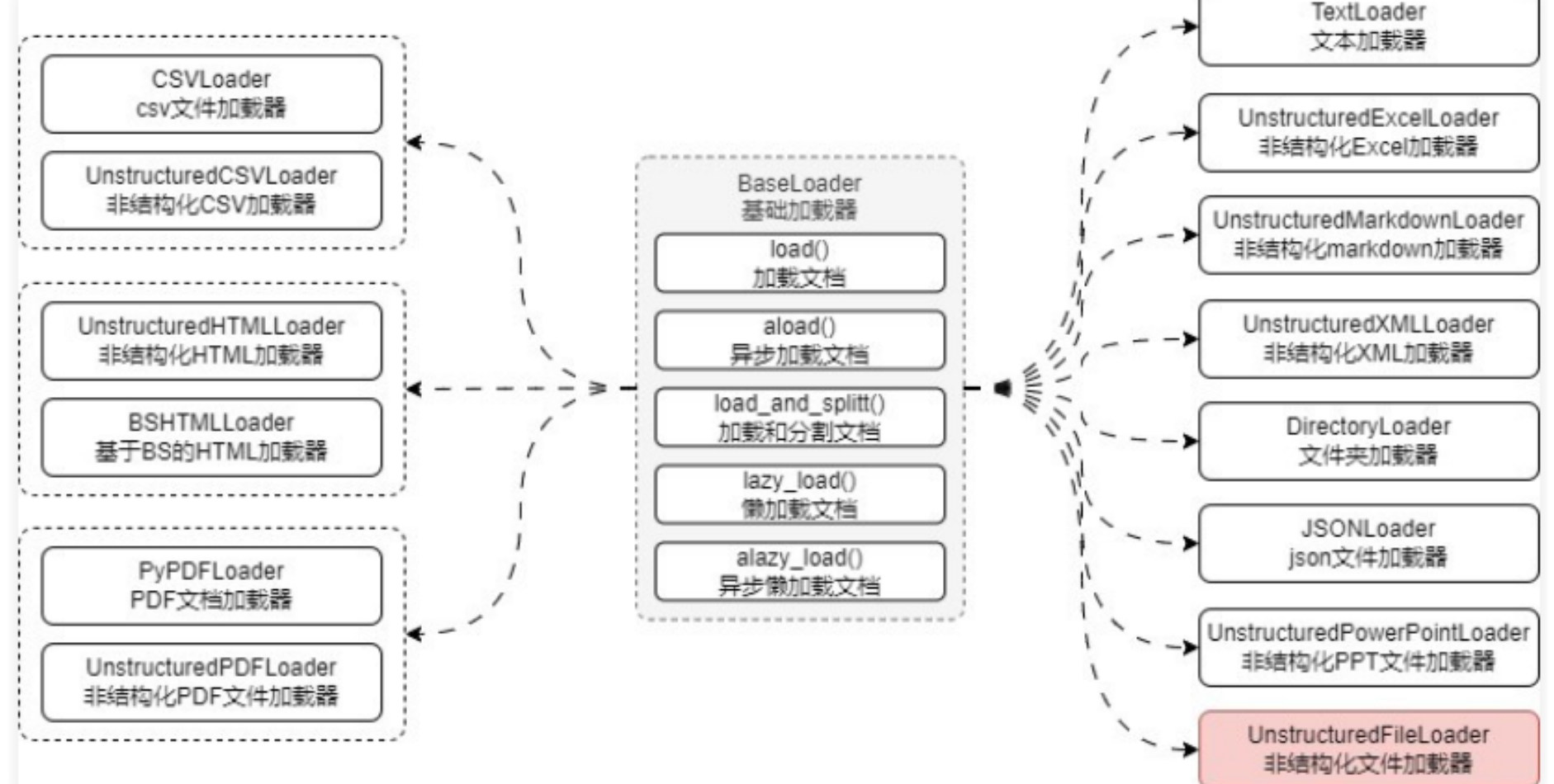
在 LangChain 框架内部,封装了上百种不同类型的文档加载器,涵盖了 CSV、目录数据、HTML 网页、JSON 数据、Markdown 数据、PDF 文档、Office 数据等,每一种文档加载器的整体使用流程都非常接近,分成两步:
- 传递对应的参数,涵盖文件路径、加载器配置等信息,创建文档加载器实例;
- 调用 .load() 函数加载得到文档列表。
使用上有差异的就是不同的文档加载器在实例化时传递的参数略有差异,加载得到的 Document 记录的信息存在一些差异,例如:
- CSVLoader:除了传递文件路径,还可以额外传递的参数,例如解析指定列、数据来源列、分隔符符号等。
- DirectoryLoader:传递目录路径,需要解析的文件夹下的文件列表等。
- JSONLoader:传递文件路径,提取 json 数据的指定结构表达式等
1.1 Markdown 文档加载器
Markdown 是一种轻量级标记语言,可用于使用纯文本编辑器创建格式化文本。例如课程的电子书就是 Markdown 格式文件。
LangChain 中封装了一个 UnstructuredMarkdownLoader 对象,要使用这个加载器,必须安装 unstructured 包,安装命令
pip install unstructured
unstructured 包是一款开源非结构化数据的预处理工具,旨在简化和优化结构化和非结构化文档的预处理,并且内置了用于读取和预处理图像和文本文档(如 PDF、HTML、Word 文档等)的开源组件。
也是 LangChain 文档加载器的核心(绝大部分加载器都基于 unstructured 包进行开发+封装)。
安装好 unstructured 包后,就可以和文本加载器一样,直接传递 Markdown 文档的路径,如下
UnstructuredMarkdownLoader 默认会将整个文件加载到文档中,加载得到的文档列表只有一个元素,在这个元素的 page_content 中记录了整个 Markdown 文档的所有内容。
其实在幕后 unstructured 包的处理中,已经为不同的文本块创建了不同的“元素”,默认情况下是全部结合到一起的,但是可以通过传递参数 mode="elements" 让所有元素全部分离。
分离代码示例
from langchain_community.document_loaders import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("./LLMOps 项目 API 文档(资料).md", mode="elements")
documents = loader.load()
print(f"文档数量: {len(documents)}")
for document in documents[:2]:
print(document)
输出内容
文档数量: 72
page_content='LLMOps 项目 API 文档' metadata={'source': './LLMOps 项目 API 文档(资料).md', 'last_modified': '2024-07-05T10:41:07', 'page_number': 1, 'languages': ['eng'], 'filetype': 'text/markdown', 'file_directory': '.', 'filename': 'LLMOps 项目 API 文档(资料).md', 'category': 'Title'}
page_content='应用 API 接口统一以 JSON 格式返回,并且包含 3 个字段:code、data 和 message,分别代表业务状态码、业务数据和接口附加信息。' metadata={'source': './LLMOps 项目 API 文档(资料).md', 'last_modified': '2024-07-05T10:41:07', 'page_number': 1, 'languages': ['eng'], 'parent_id': 'b7210d8e5b8b15feccc935fd705f763b', 'filetype': 'text/markdown', 'file_directory': '.', 'filename': 'LLMOps 项目 API 文档(资料).md', 'category': 'NarrativeText'}
但是一般在加载文件为文档时,很少对文档进行相应的拆分操作,在文档加载器中执行分割没法保证操作的一致性(没法确保所有传递文档分割的统一性,分割出来的文档块大小不一,使用不便)。
1.2 Office 文档加载器
除了 Markdown 文档,另外一种高频使用的数据就是 Office 文档,在 LangChain 中也基于 unstructured 包封装了对应的文档加载器—— UnstructuredExcelLoader、UnstructuredPowerPointLoader、UnstructuredWordDocumentLoader。
分别对应 Excel、PPT、Word 文档加载器,其中不同的加载器需要安装不同的 Python 包,命令如下
# UnstructuredExcelLoader加载器所需包
pip install unstructured openpyxl pandas
# UnstructuredPowerPointLoader加载器所需包
pip install unstructured python-magic python-pptx
# UnstructuredWordDocumentLoader加载器所需包
pip install unstructured python-docx
Office 类的非结构化文档加载器使用技巧都非常简单,一般来说,传递对应文档的路径即可,如果需要区分文档中的元素,可以在加载器的构造函数中传递 mode="elements" 即可(但是一般不使用)。
示例如下
from langchain_community.document_loaders import (
UnstructuredExcelLoader,
UnstructuredPowerPointLoader,
UnstructuredWordDocumentLoader,
)
excel_loader = UnstructuredExcelLoader("./员工考勤表.xlsx")
ppt_loader = UnstructuredPowerPointLoader("./章节介绍.pptx", mode="elements")
word_loader = UnstructuredWordDocumentLoader("./喵喵.docx")
documents = ppt_loader.load()
print(documents)
print(len(documents))
print(documents[0].page_content)
输出内容
[Document(page_content='LangChain RAG应用开发组件深入学习', metadata={'source': './章节介绍.pptx', 'category_depth': 1, 'file_directory': '.', 'filename': '章节介绍.pptx', 'last_modified': '2024-07-20T11:44:28', 'page_number': 1, 'languages': ['zho', 'kor'], 'filetype': 'application/vnd.openxmlformats-officedocument.presentationml.presentation', 'category': 'Title'}), Document(page_content='章节介绍', metadata={'source': './章节介绍.pptx', 'category_depth': 1, 'file_directory': '.', 'filename': '章节介绍.pptx', 'last_modified': '2024-07-20T11:44:28', 'page_number': 1, 'languages': ['zho', 'kor'], 'filetype': 'application/vnd.openxmlformats-officedocument.presentationml.presentation', 'category': 'Title'})]
17
LangChain RAG应用开发组件深入学习
利用 unstructured 包提供的办公文档加载能力,配合 LLM 可以实现 2023 年爆火的 ChatPDF 功能,即上传特定的 PDF,让 LLM 实现对指定的 PDF 的问答功能。
1.3 URL 网页加载器
除了本地文件,LangChain 还封装了大量加载网络文件的加载器,例如:网页加载器、腾讯云 COS 对象存储加载器、Bilibili 字幕加载器、Notion 数据库加载器等,使用技巧和文件加载器大差不差,传递对应的信息构建加载器,然后加载文档即可。
例如如果想加载获取 网站首页的数据,即可使用 WebBaseLoader 一键加载,示例如下
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://baidu.com")
documents = loader.load()
print(documents)
输出内容:
[Document(page_content='xxx', metadata={'source': 'https://baidu.com', 'title': 'xxx', 'language': 'No language found.'})]
WebBaseLoader 加载器底层会从 HTML 网页中加载所有文本(去除 HTML 标签),并将所有文本进行合并。利用这个加载器其实就可以快速实现一个基于特定网页问答的聊天机器人。
02. 通用文件加载器的使用技巧
在实际的 LLM 应用开发中,由于数据的种类是无穷的,没办法单独为每一种数据配置一个加载器(也不现实),所以对于一些无法判断的数据类型或者想进行通用性文件加载,可以统一使用非结构化文件加载器 UnstructuredFileLoader 来实现对文件的加载。
UnstructuredFileLoader 是所有 UnstructuredXxxLoader 文档类的基类,其核心是将文档划分为元素,当传递一个文件时,库将读取文档,将其分割为多个部分,对这些部分进行分类,然后提取每个部分的文本,然后根据模式决定是否合并(single、paged、elements)。
一个 UnstructuredFileLoader 可以加载多种类型的文件,涵盖了:文本文件、PowerPoint 文件、HTML、PDF、图像、Markdown、Excel、Word 等,使用示例如下
from langchain_community.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader("./章节介绍.pptx")
documents = loader.load()
print(documents)
输出示例
[Document(page_content='LangChain RAG应用开发组件深入学习\n\n章节介绍\n\nLangChain文档组件与文档加载器\n\n学习了解Document组件在RAG应用开发中的作用,并学习LangChain文档加载器的配置与使用。\n\n学习掌握LangChain集成的各类文档加载器,涵盖CSV文件加载、HTML网页加载、PDF/文件夹/Markdown加载器以及通用文件加载器的使用。\n\n学习掌握封装LangChain自定义文档加载器的使用。\n\nLangChain文档转换器与分割器\n\n学习了解LangChain文档转换器的作用与使用场景,涵盖了拆分、合并、过滤、翻译等多个功能。\n\n学习掌握LangChain集成的各类文本分割器的使用以及封装自定义文本分割器的技巧,不同模式下选择分割器的思路。\n\n学习掌握LangChain语义分割器的使用及运行流程,以及语义分割器的使用场合。\n\nVectorStore组件与检索器的使用\n\n深入学习VectorStore组件,了解多种相似性搜索的几何意义以及在不同场合下的选择策略。\n\n学习掌握LangChain检索器与第三方检索器的配置与使用。\n\n学习掌握自定义LangChain检索器的技巧。', metadata={'source': './章节介绍.pptx'})]
不过由于 UnstructuredFileLoader 加载器提取元数据只记录了 source 即数据的来源,信息相对较少,所以如果能明确文件的类型,亦或者是一些高频的文件,尽可能使用更精确的文档加载器,记录的内容会更丰富。
例如通过检测文件的扩展名来加载不同的文件加载器,对于没校验到的文件类型,才考虑使用 UnstructuredFileLoader,如下
if file_extension in [".xlsx", ".xls"]:
loader = UnstructuredExcelLoader(file_path)
elif file_extension == ".pdf":
loader = UnstructuredPDFLoader(file_path)
elif file_extension in [".md", ".markdown"]:
loader = UnstructuredMarkdownLoader(file_path)
elif file_extension in [".htm", "html"]:
loader = UnstructuredHTMLLoader(file_path)
elif file_extension in [".docx", ".doc"]:
loader = UnstructuredWordDocumentLoader(file_path)
elif file_extension == ".csv":
loader = UnstructuredCSVLoader(file_path)
elif file_extension in [".ppt", ".pptx"]:
loader = UnstructuredPowerPointLoader(file_path)
elif file_extension == ".xml":
loader = UnstructuredXMLLoader(file_path)
else:
loader = UnstructuredFileLoader(file_path) if is_unstructured else TextLoader(file_path)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)