【AI论文】AutoPR:让我们助你实现学术晋升自动化!
摘要:本研究提出"自动学术推广"(AutoPR)任务,旨在将学术论文自动转化为适合社交平台传播的内容,以提升学术成果的可见性。研究构建PRBench多模态基准测试集(包含512篇论文及其推广文案),从保真度、吸引力和适配度三个维度评估系统性能。同时开发PRAgent多智能体框架,通过内容提取、协作合成和平台适配三阶段实现推广内容自动化生成。实验表明,PRAgent相比直接使用大
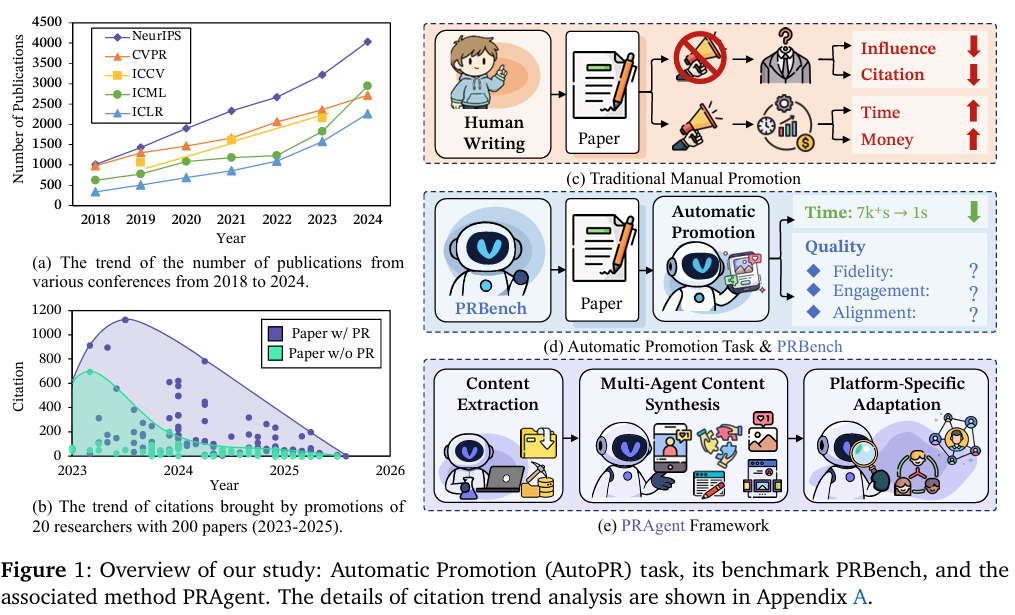
摘要:随着同行评审研究论文数量激增,学者们愈发依赖社交平台来发现学术成果,而作者们也投入大量精力推广自身研究,以确保其可见度和引用量。为简化这一流程并减少对人工的依赖,我们提出“自动推广”(AutoPR)这一全新任务,旨在将学术论文转化为准确、吸引人且时效性强的公开内容。为支持严谨评估,我们发布了多模态基准测试集PRBench,该数据集将512篇同行评审文章与高质量推广文案相关联,从三个维度评估系统性能:保真度(准确性与语气)、吸引力(受众定位与感染力)和适配度(时机与渠道优化)。此外,我们推出了多智能体框架PRAgent,通过三个阶段实现AutoPR自动化:多模态预处理的内容提取、协作式合成以产出精炼内容,以及针对特定平台的适配优化(规范、语气与标签设置以最大化传播效果)。在PRBench基准测试中,与直接使用大语言模型(LLM)的流程相比,PRAgent展现出显著提升,包括总观看时长增加604%、点赞数增长438%,且整体参与度至少提升2.9倍。消融实验表明,平台建模与定向推广策略对提升效果贡献最大。我们的研究将AutoPR定位为一个可操作、可量化的研究问题,并为构建可扩展、有影响力的学术传播自动化系统提供了路线图。Huggingface链接:Paper page,论文链接:2510.09558
研究背景和目的
研究背景:
随着学术出版物的激增,学者们越来越依赖社交媒体平台来发现和传播研究成果。
同时,作者们也投入大量精力推广自己的工作,以确保其可见性和引用率。然而,传统的手动推广方式耗时耗力,且效果难以保证。近年来,尽管智能代理系统在学术领域展现出潜力,能够自主完成摘要生成、视觉摘要设计和定向推广等任务,但针对学术成果在社交平台上自动化推广的系统性基准仍然缺乏。
研究目的:
本研究旨在填补这一研究空白,提出自动学术推广(AutoPR)任务,并构建相应的基准测试集PRBench,以系统评估大型语言模型(LLMs)在端到端学术推广任务中的表现。
同时,本研究还提出PRAgent框架,通过多代理系统实现学术成果的自动化推广,减轻学者负担,提高学术成果的可见性和影响力。
研究方法
1. AutoPR任务定义:
AutoPR任务旨在将研究论文自动转化为准确、吸引人且适合特定平台的内容。
输入为研究文档(包括文本内容、视觉内容和补充材料),输出为针对特定传播平台(如Twitter、RedNote)和目标受众(如学术同行、普通公众)的推广内容(如新闻稿、社交媒体帖子、视觉摘要)。
2. PRBench基准测试集构建:
- 数据收集:从arXiv仓库收集2024年6月至2025年6月提交的计算机科学领域论文,重点关注计算与语言、机器学习和人工智能等子领域。
- 数据配对与筛选:从Twitter和RedNote平台检索这些论文的推广帖子,确保所有帖子均为人工撰写。通过均匀采样和手动验证,最终筛选出512对论文-帖子平行样本。
- 人工标注与质量控制:实施两轮专家驱动的流程,包括事实准确性清单制定和重要性权重分配,以及多维度评分标准的独立标注和一致性解决。
3. PRAgent框架设计:
PRAgent框架采用三阶段流程实现学术成果的自动化推广:
- 内容提取:将非结构化的PDF研究文档转换为结构化的机器可读格式,包括文本内容提取和视觉内容准备。
- 多代理内容合成:通过四个协作代理系统(逻辑草稿代理、文本丰富代理、视觉分析代理和视觉-文本交织组合代理)将结构化数据转化为 polished 的推广草稿。
- 平台特定适配:根据目标平台的特点和受众偏好,对推广草稿进行最终调整和优化。
4. 评估指标:
- 保真度(Fidelity):评估推广内容的准确性和完整性,包括作者和标题准确性、事实清单评分等。
- 参与度(Engagement):评估推广内容对目标受众的吸引力和参与度,包括利益相关者识别和吸引力、参与度钩子强度等。
- 一致性(Alignment):评估推广内容与平台规范和受众期望的一致性,包括上下文相关性、视觉-文本集成、话题标签和提及策略等。
研究结果
1. PRBench基准测试集的有效性:
PRBench基准测试集成功链接了512篇同行评审文章与高质量的人工推广帖子,为AutoPR任务提供了可靠的评估平台。
通过系统评估,验证了PRBench在评估LLMs在学术推广任务中表现的有效性。
2. PRAgent框架的性能优势:
- 显著提升推广质量:与直接提示基线相比,PRAgent在PRBench上的表现显著提升,总观看时间增加604%,点赞数增加438%,整体参与度至少提升2.9倍。
- 多代理系统的有效性:消融研究表明,PRAgent框架中的每个阶段都对最终输出质量有显著贡献。特别是平台特定适配阶段对提升推广内容与平台规范和受众期望的一致性至关重要。
- 真实世界中的卓越表现:在RedNote平台上的10天实地研究中,PRAgent生成的推广内容在总观看时间、个人资料访问量和互动量等指标上均显著优于直接提示基线。
3. 当前LLMs在学术推广中的局限性:
尽管当前最先进的LLMs(如GPT-5)在PRBench上表现出一定水平,但其整体表现仍有提升空间。
特别是在保真度、参与度和一致性等关键指标上,LLMs仍面临挑战。
研究局限
1. 数据集的局限性:
- 领域覆盖有限:PRBench目前主要覆盖计算机科学领域,未来需要扩展至更多学科领域以验证其普适性。
- 样本量相对较小:尽管PRBench包含512对论文-帖子样本,但相对于整个学术出版物数量而言仍然有限。未来需要进一步扩大样本量以提高评估的准确性和可靠性。
2. 评估指标的局限性:
- 主观性评估的挑战:参与度和一致性等指标涉及大量主观性评估,可能受到评估者个人偏好和认知偏差的影响。未来需要探索更客观、量化的评估方法。
- 多模态评估的复杂性:PRBench包含文本和视觉内容的多模态评估,增加了评估的复杂性和难度。未来需要开发更先进的多模态评估技术和工具。
3. PRAgent框架的局限性:
- 依赖高质量输入:PRAgent框架的性能高度依赖于输入研究文档的质量和结构化程度。未来需要探索如何处理低质量或非结构化的输入数据。
- 平台适配的局限性:尽管PRAgent能够根据目标平台的特点进行适配,但其效果仍受到平台规范和受众偏好的限制。未来需要研究如何更精确地捕捉和理解不同平台的规范和受众偏好。
未来研究方向
1. 扩展数据集和评估指标:
- 扩大领域覆盖:将PRBench扩展至更多学科领域,以验证AutoPR任务和PRAgent框架的普适性。
- 增加样本量:进一步扩大PRBench的样本量,以提高评估的准确性和可靠性。
- 开发新评估指标:探索更客观、量化的评估指标和方法,以更准确地评估推广内容的保真度、参与度和一致性。
2. 改进PRAgent框架:
- 优化内容提取:研究更先进的内容提取技术,以处理低质量或非结构化的输入数据。
- 增强多代理协作:优化多代理系统之间的协作机制,提高内容合成的效率和准确性。
- 精细化平台适配:研究如何更精确地捕捉和理解不同平台的规范和受众偏好,以实现更精细化的平台适配。
3. 探索新的应用场景:
- 跨语言推广:研究如何将AutoPR任务和PRAgent框架应用于跨语言学术推广场景,以促进国际学术交流与合作。
- 个性化推广:探索如何根据目标受众的个性化需求和偏好生成定制化的推广内容,以提高推广效果。
- 实时互动推广:研究如何实现学术成果的实时互动推广,以增强学者与受众之间的互动和反馈。
4. 关注伦理和社会影响:
- 伦理准则制定:制定AutoPR任务和PRAgent框架的伦理准则和规范,以确保其应用的合法性和道德性。
- 偏见检测与缓解:研究如何检测和缓解推广内容中的偏见和歧视性语言,以促进学术成果的公正传播。
- 社会影响评估:评估AutoPR任务和PRAgent框架对学术生态系统和社会的影响,以确保其应用的可持续性和社会责任。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)