Lora微调实操演示(下):五次训练详解(免费GPU)
这篇介绍Lora 微调的环境配置、任务设计、基准测试、五次迭代训练以及微调后的对比测试效果。
之前写过一篇 Lora 微调的概念铺垫文章,这篇来结合阿里云的一个开源项目和免费试用 GPU 来做个完整的训练过程演示。
注:本篇演示的脚本部分在参考 aliyun_acp_learning 开源项目基础上有部分删减和调整。后文相关配置和训练过程中的实际耗时也会进行标注说明。https://github.com/AlibabaCloudDocs/aliyun_acp_learning.git
这篇试图说清楚:
Lora 微调的环境配置、任务设计、基准测试、五次迭代训练以及微调后的对比测试效果。
以下,enjoy:
1、环境配置
虽然是 Lora 微调但对硬件性能要求也并不低,如果各位本地没有 GPU 环境或者显存不到 30GB,可以先按照下述步骤去蹭下阿里云的 DSW(交互式建模平台)3 个月250计算时的 A10 GPU 免费试用。
https://billing-cost.console.aliyun.com/home/myfreetier
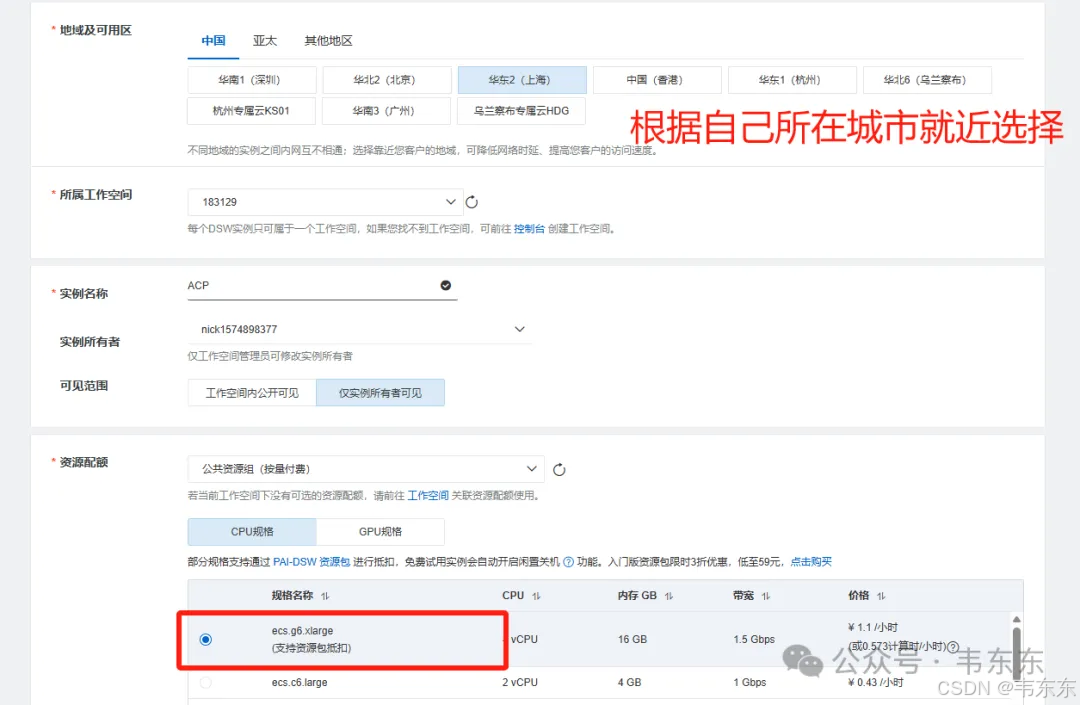
资源规格选择免费试用页签中的ecs.gn7i-c8g1.2xlarge(该规格有一个 A10 GPU,显存 30GB),镜像选择 modelscope:1.21.0-pytorch2.4.0-gpu-py310-cu124-ubuntu22.04(需要将“镜像配置”->”芯片类型“切换为 GPU)
# 需要安装以下依赖
%pip install accelerate==1.0.1 rouge-score==0.1.2 nltk==3.9.1 ms-swift[llm]==2.4.2.post2 evalscope==0.5.5rc1
注:实际安装依赖花了 48 分钟
2、明确训练状态
老规矩,正式开始介绍前,明确一些重要概念。最基础的损失函数、神经网络和各个超参数的概念本篇不再做赘述,不熟悉的盆友记得先去翻下上一篇。这部分明确下后续的训练和测试内容。
模型训练和人的学习考试过程非常像,前后需要经过三套题目的考验,来确定模型训练所处于的状态:
2.1、训练集
课程练习册,带详细答案解析,模型会反复练习,并基于损失函数产生训练损失。训练损失越小,说明模型在你给定的练习册上表现更好。
训练损失不变,甚至变大说明训练失败。可以理解为模型在训练集(练习册)上没有学习到知识,说明模型的学习方法有问题。
2.2、验证集
模拟考试题,模型每学习一段时间,就会测试一次,并基于损失函数产生验证损失。验证损失就是用于评估模型训练的效果。验证损失越小,说明模型在模拟考试中表现越好。
训练损失和验证损失都在下降说明模型欠拟合。可以想象成模型在训练集(练习册)上的学习有进步,验证集(模拟考试)的表现也变好了,但还有更多的进步空间。这时候应该让模型继续学习。
2.3、测试集
相当于考试真题,模型在测试集上的准确率用于评估最终的模型表现。训练损失下降但验证损失上升说明模型过拟合。
可以理解为模型只是背下了训练集(练习册),在模型考试中遇到了没背过的题反而做不来了。这种场景需要通过一些方法去抑制模型的背题倾向,比如再给它 20 本练习册,让它记不住所有的题,而是逼它去学习题目里面的规律。
3、模型下载与基准测试
本篇微调的基座模型选择的是小参数的开源qwen2.5-1.5b-instruct,首先下载模型并把它加载到内存中。
3.1、模型下载(42 分钟)
# 下载模型参数到 ./model 目录下
!mkdir ./model
!modelscope download --model qwen/Qwen2.5-1.5B-Instruct --local_dir './model'
from swift.llm import (
get_model_tokenizer, get_template, ModelType,
get_default_template_type
)
import torch
#你可以根据你的需要修改query(模型输入)
# 获得模型信息
model_type = ModelType.qwen2_5_1_5b_instruct
template_type = get_default_template_type(model_type)
# 设置模型本地位置
model_id_or_path = "./model"
# 初始化模型和输入输出格式化模板
kwargs = {}
model, tokenizer = get_model_tokenizer(model_type, torch.float32, model_id_or_path=model_id_or_path, model_kwargs={'device_map': 'cpu'}, **kwargs)
model.generation_config.max_new_tokens = 128
template = get_template(template_type, tokenizer, default_system='')
print("模型初始化完成")
3.2、基准模型测试(2 分钟)
在开始模型微调前,先来看看基准模型在测试集上的表现如何。
import json
from IPython.display import Markdown
sum, score = 0, 0
for line in open("./resources/2_7/test.jsonl"):
# 读取测试集中的问题
math_question = json.loads(line)
query = math_question["messages"][1]["content"]
# 使用基准模型推理
response, _ = inference(model, template, query)
# 获取正确答案
ans = math_question["messages"][2]["content"]
pos = ans.find("ans")
end_pos = ans[pos:].find('}}')
ans = ans[pos - 2: end_pos + pos + 2]
# 整理输出
print(("========================================================================================"))
print(query.split("#数学题#\n")[1])
print("问题答案是:" + ans)
print("-----------模型回答----------------")
display(Latex(response))
print("-----------回答结束----------------")
# 计算模型得分
if ans in response or ans[6:-2] in response:
score += 1
print("模型回答正确")
else: print("模型回答错误")
sum += 1
# 总结
display(Markdown("模型在考试中得分:**" + str(int(100*score/sum)) + "** 分"))
一共有十个测试问题,这里截取其中一个问答进行展示:
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": "#输出#\n输出要符合经过推理后将最终答案放在 {{ans:xxx}} 内。\n#数学题#\n鸡、鸭只数的比是5:3,鸡有25只,鸭有多少只."}, {"role": "assistant", "content": "鸡和鸭的比例为5:3,即鸡的数量为5份,鸭为3份。已知鸡有25只,对应5份,每份数量为 $25 \\div 5 = 5$ 只。因此,鸭的数量为 $3 \\times 5 = 15$ 只。\n\n验证:设鸭的数量为$x$,根据比例 $\\frac{25}{x} = \\frac{5}{3}$,交叉相乘得 $5x = 75$,解得 $x = 15$,与份数法一致。\n\n{{ans:15}}"}]}
========================================================================================
鸡、鸭只数的比是5:3,鸡有25只,鸭有多少只.
问题答案是:{{ans:15}}
-----------模型回答----------------
设鸡和鸭的数量分别为 𝑥
和 𝑦
。根据题目信息,我们可以得到以下比例关系:
𝑥𝑦=53
已知鸡的数量 𝑥=25
。 代入上述比例关系求解鸭的数量 𝑦
:
25𝑦=53
通过交叉相乘来解这个方程:
25×3=5×𝑦
75=5𝑦
\[ y = \frac{7
-----------回答结束----------------
模型回答错误最终qwen2.5-1.5b-instruct模型在考试中得了60 分。
4、五次微调过程
这里使用 ms-swift(Modelscope Scalable lightWeight Infrastructure for Fine-Tuning)框架,它是阿里魔搭社区专门为模型训练开发的开源框架,在每次计算验证损失的时候,框架会自动保存当前训练阶段的模型参数,并在训练结束时自动保存训练过程中验证损失最小的参数。
在接下来的多次实验中,将重点调整学习率、LoRA 的秩、数据集学习次数三个参数,并替换数据集,展示如何进行 LoRA 微调,其它的参数的调整是为了方便实验效果呈现,如增加批大小从而缩短训练时间,可以不用过多关注。
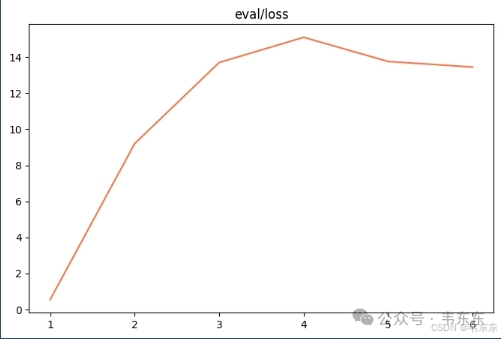
4.1、第一次实验(26 秒)
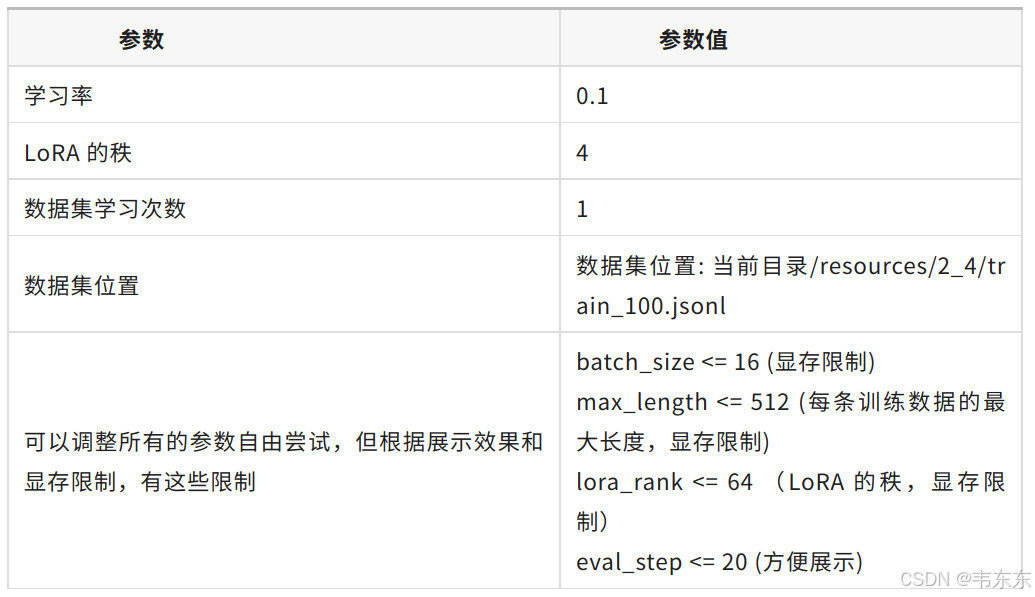
注:ms-swift 框架的微调模块默认使用 LoRA 微调所以实验中不需要显式地声明微调方法。同时框架会在训练过程中智能地减少实际学习率,保证模型不会总是跳过最优解。
%env CUDA_VISIBLE_DEVICES=0
%env LOG_LEVEL=INFO
!swift sft \
--learning_rate '0.1' \
--lora_rank 4 \
--num_train_epochs 1 \
--dataset './resources/2_7/train_100.jsonl' \
--batch_size '8' \
--max_length 512 \
--eval_step 1 \
--model_type 'qwen2_5-1_5b-instruct' \
--model_id_or_path './model'
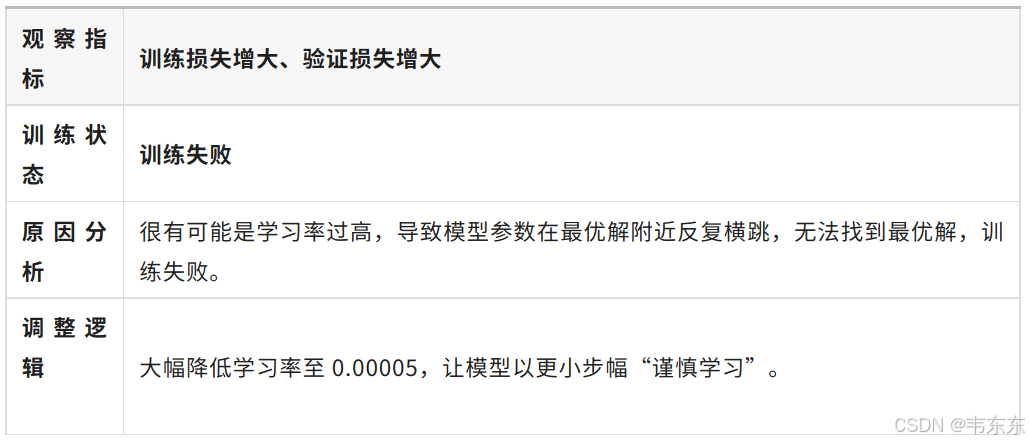
4.2、第二次实验(22 秒)

%env CUDA_VISIBLE_DEVICES=0
%env LOG_LEVEL=INFO
!swift sft \
--learning_rate '0.00005' \
--lora_rank 4 \
--num_train_epochs 1 \
--dataset './resources/2_7/train_100.jsonl' \
--batch_size '8' \
--max_length 512 \
--eval_step 1 \
--model_type 'qwen2_5-1_5b-instruct' \
--model_id_or_path './model'
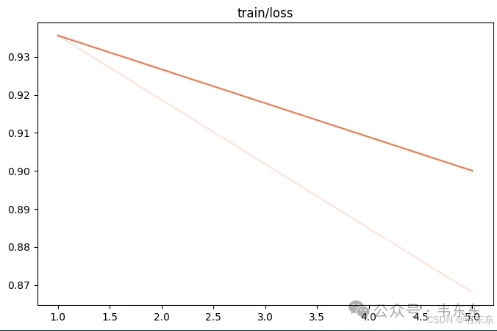
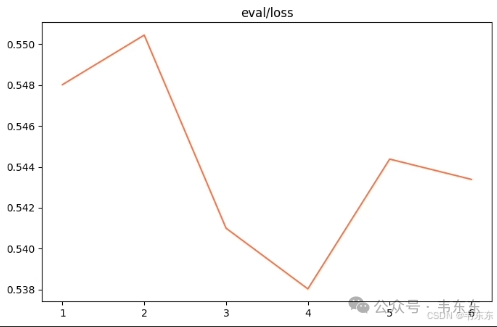

4.3、第三次实验(7 分钟)
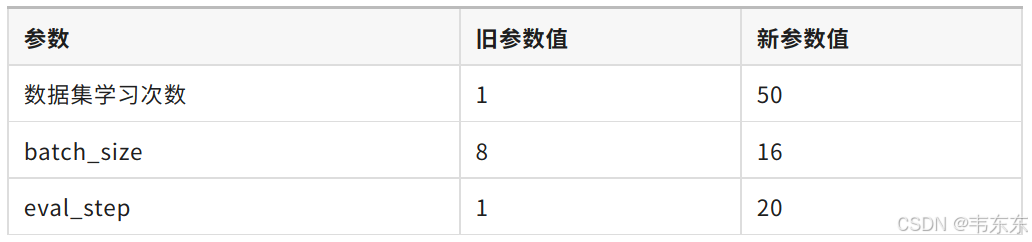

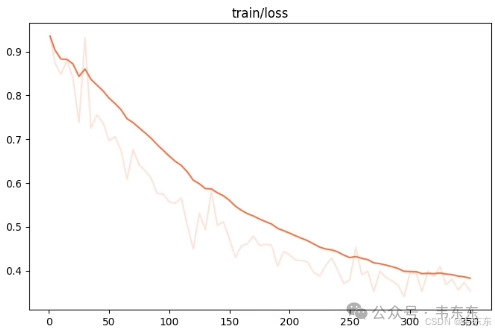
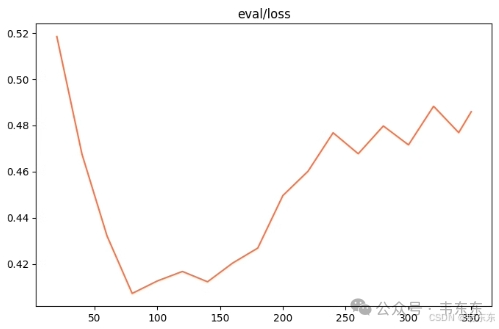

一般来说,微调至少需要1000+条优质的训练集数据。低于此数量级时,模型多学几遍就开始“背题”而非学习数据中的知识。
4.4、第四次实验(5 分钟)
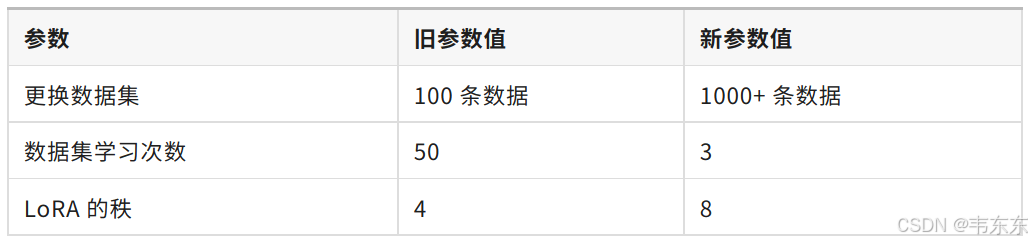
%env CUDA_VISIBLE_DEVICES=0
%env LOG_LEVEL=INFO
!swift sft \
--learning_rate '0.00005' \
--lora_rank 8 \
--num_train_epochs 3 \
--dataset './resources/2_7/train_1k.jsonl' \
--batch_size '16' \
--max_length 512 \
--eval_step 20 \
--model_type 'qwen2_5-1_5b-instruct' \
--model_id_or_path './model'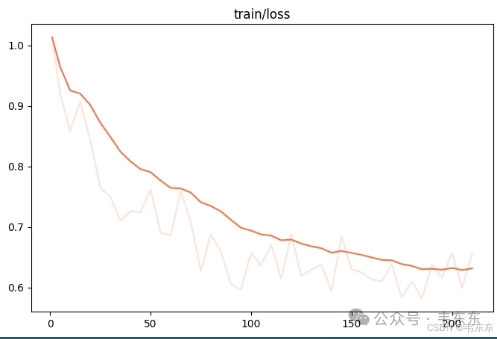
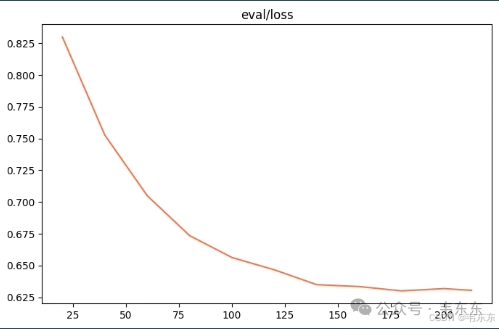


4.5、第五次实验(23 分钟)

%env CUDA_VISIBLE_DEVICES=0
%env LOG_LEVEL=INFO
!swift sft \
--learning_rate '0.00005' \
--lora_rank 8 \
--num_train_epochs 15 \
--dataset './resources/2_7/train_1k.jsonl' \
--batch_size '16' \
--max_length 512 \
--eval_step 20 \
--model_type 'qwen2_5-1_5b-instruct' \
--model_id_or_path './model'
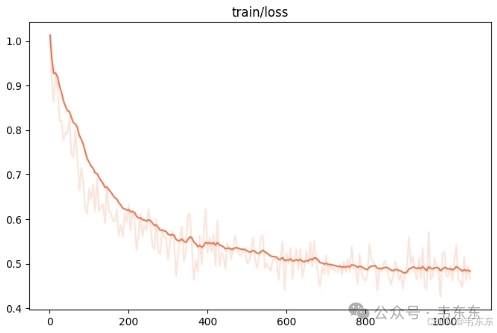
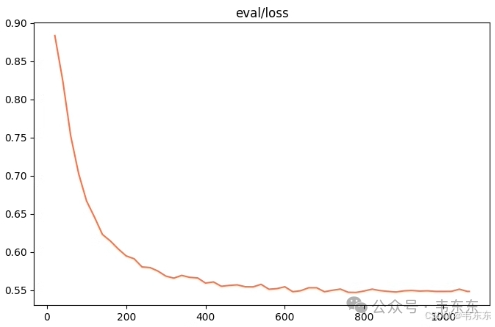

5、微调后测试
微调后一般会保存两个 checkpoint 文件,分别是 best_model_checkpoint(在验证集表现最佳的模型参数)与 last_model_checkpoint(微调任务完成时的模型参数)。这里选取 best_model_checkpoint 地址替换下面代码中的 ckpt_dir,就能调用微调后的模型。
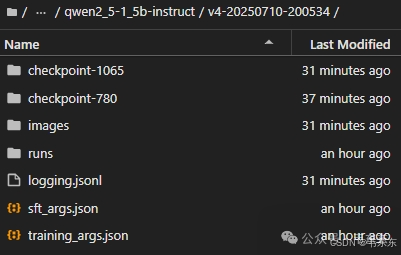
先加载模型到内存中:
from swift.tuners import Swift
# 请在运行前修改ckpt_dir到正确的位置
ckpt_dir = 'output/qwen2_5-1_5b-instruct/qwen2_5-1_5b-instruct/v4-20250710-200534/checkpoint-1065'
# 加载模型
ft_model = Swift.from_pretrained(model, ckpt_dir, inference_mode=True)来看看微调后的模型在考试中的表现:
import json
from IPython.display import Markdown
sum, score = 0, 0.0
for line in open("./resources/2_7/test.jsonl"):
# 读取测试集中的问题
math_question = json.loads(line)
query = math_question["messages"][1]["content"]
# 使用微调成功的模型推理
response, _ = inference(ft_model, template, query)
# 获取正确答案
ans = math_question["messages"][2]["content"]
pos = ans.find("ans")
end_pos = ans[pos:].find('}}')
ans = ans[pos - 2: end_pos + pos + 2]
# 整理输出
print(("========================================================================================"))
print(query.split("#数学题#\n")[1])
print("问题答案是:" + ans)
print("-----------模型回答----------------")
display(Latex(response))
print("-----------回答结束----------------")
# 计算模型得分
if ans in response:
score += 1
print("模型回答正确")
elif ans[6 : -2] in response:
score += 0.5
print("模型回答正确但输出格式错误")
else: print("模型回答错误")
sum += 1
# 总结
display(Markdown("微调后的模型在考试中得分:**" + str(int(100*score/sum)) + "** 分"))
6、写在最后
这篇只是个过程演示,在实际生产中,是否微调需综合考虑算力成本、数据规模和数据质量等因素。一般经验是,能靠提示词工程、RAG 、工作流编排能解决的先做工程优化为好。
最后留个彩蛋:一道多选题。(答案公众号聊天页面发送“微调”两个字看正确答案和解释)
你正在使用 Swift 微调一个 Qwen 模型,发现模型在验证集上的 loss 出现了明显的上升趋势,以下哪些操作可以帮助你缓解或解决这个问题❓
A. 增大 --learning_rate
B. 减小 --learning_rate
C. 增大 --num_train_epochs
D. 减小 --num_train_epochs
项目脚本、训练数据与训练结果文件已发布至知识星球中,按需加入自取。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 32
32 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)