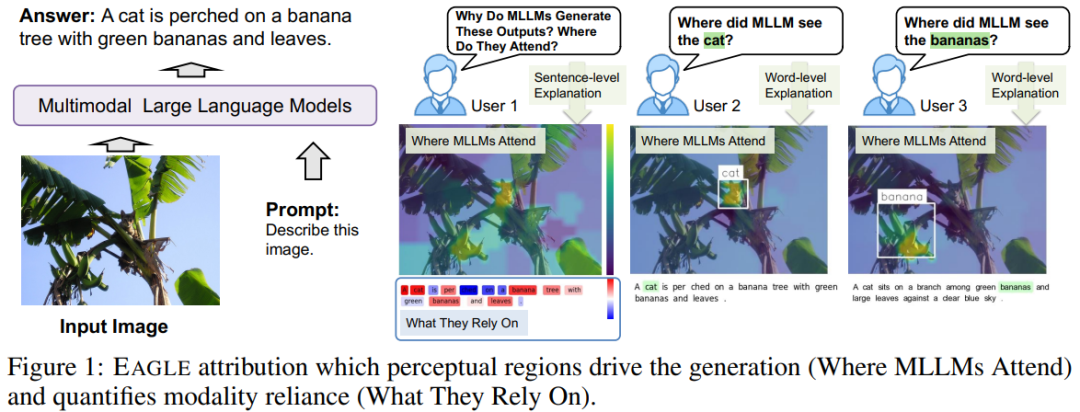
【ICLR26匿名投稿】EAGLE:让多模态大模型“说清楚自己在看啥、靠啥写字”
相比基于梯度的可解释方法(如 IGOS++、Grad-CAM), EAGLE 显存占用减少约 70%~80%, 在 Qwen2.5-VL 7B 上运行仅需。这意味着即使模型答对了,我们也不知道它是“真懂”还是“瞎蒙”。给多模态大模型装上了“显微镜”, 让我们第一次能看清:每一个词,是看图得出的,还是靠想象写出来的。—— 不知道生成内容到底是“看图得出的”还是“语言模型自己编的”。: 找出“最少的一
文章:Where MLLMs Attend and What They Rely On: Explaining Autoregressive Token Generation
代码:暂无
单位:暂无
一、问题背景:多模态大模型的“盲点”
随着 GPT-4V、Qwen-VL 等多模态大语言模型的出现,AI 已能“看图说话”, 但一个关键问题仍被忽略:
模型在生成每一个 token 时,到底在看哪里、又在靠什么?
目前的模型解释方法存在三大痛点:
-
🧩 解释粒度粗 —— 只能看整句注意力,无法追踪单词级别;
-
⚙️ 依赖梯度信息 —— 需要访问模型内部参数,不适合闭源模型;
-
🌀 无法区分模态依赖 —— 不知道生成内容到底是“看图得出的”还是“语言模型自己编的”。
这意味着即使模型答对了,我们也不知道它是“真懂”还是“瞎蒙”。 为此,作者提出了一个轻量、通用、黑盒可用的解释框架 —— EAGLE。
二、方法创新:EAGLE 框架登场
EAGLE(Explaining Autoregressive Generation by Language priors or Evidence)旨在解释 MLLM 在自回归生成过程中的“注意力来源”。
它能回答两个核心问题:
-
📍 Where MLLMs Attend —— 模型在看图的哪一块?
-
💬 What They Rely On —— 模型是在靠视觉证据还是语言先验生成?
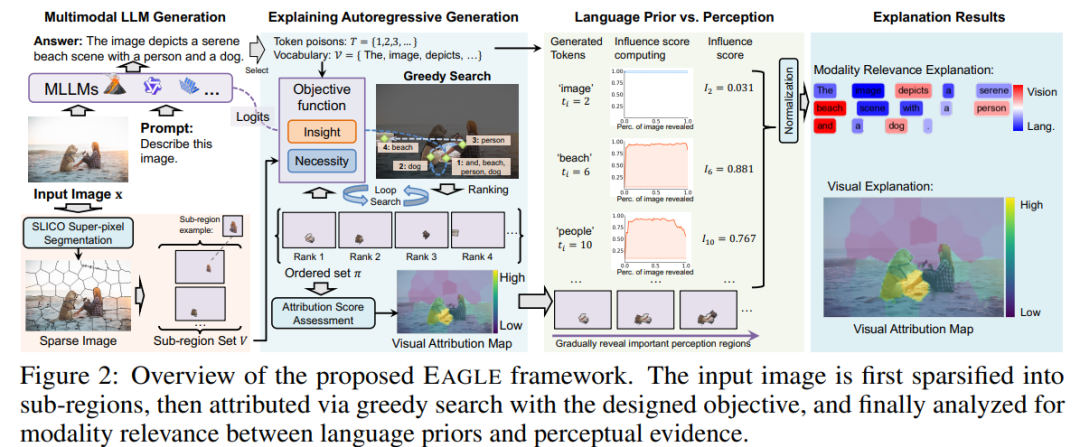
🧠 (1) 图像区域划分:视觉空间离散化
EAGLE 将输入图像通过 超像素分割(SLICO) 划分为语义区域。 每个区域对应一组潜在视觉特征,作为后续归因的基本单位。
这样模型不用处理像素级解释,而是聚焦在语义区域级别的注意力归因。
⚙️ (2) 双目标归因函数:Insight × Necessity
EAGLE 通过两个互补指标量化“哪个区域最重要”:
-
🔍 Insight Score(洞察度): 找出“最少的一组区域”就能最大化目标 token 的生成概率。
-
🚫 Necessity Score(必要度): 移除这些区域后,生成概率会显著下降。
二者结合后,EAGLE 就能判断出——哪些区域真正决定了模型输出。
🔄 (3) 贪心子集搜索:高效黑盒优化
由于 MLLM 通常闭源、参数庞大,EAGLE 不使用梯度, 而是通过多轮前向推理(Forward Pass)贪心搜索最具影响力的区域组合。
这一点让 EAGLE 能直接用于现成模型,如 Qwen2.5-VL、InternVL 等,无需改结构。
💬 (4) 模态依赖度分析:看图 vs 背稿
在归因结果上,EAGLE 进一步定义了 Influence Score:
-
若 token 的生成概率随视觉变化显著 → 视觉驱动(Evidence-based);
-
若几乎不受影响 → 语言先验(Language-driven)。
这让我们首次能量化每个词是“看图写的”还是“凭语言推的”。
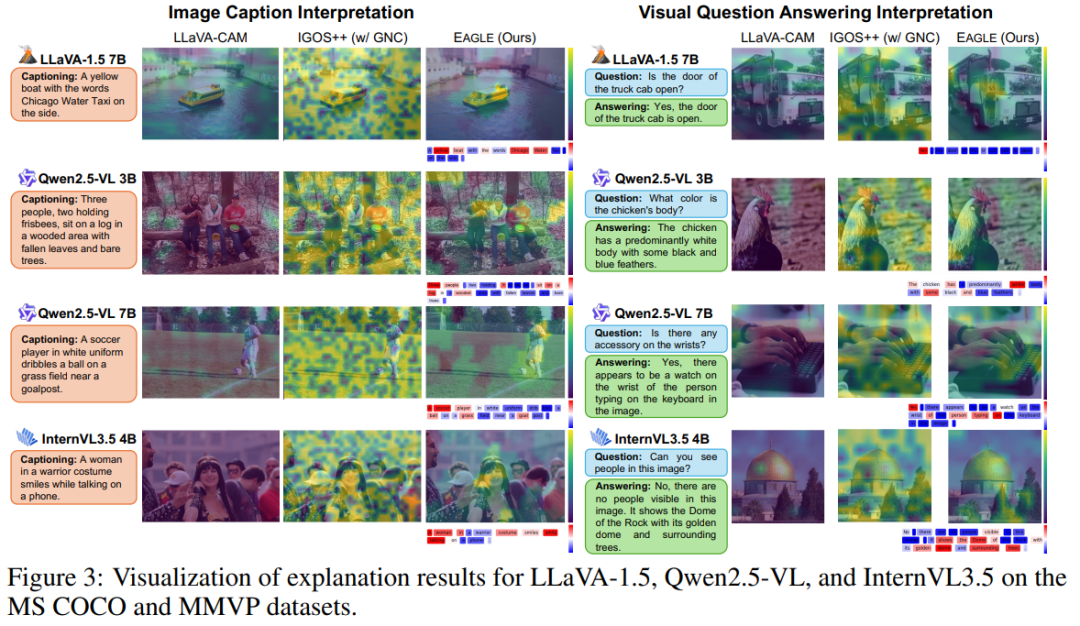
三、实验结果:解释更精准、效率更高
EAGLE 在多个多模态任务上验证了有效性: 包括 图像描述(COCO)、视觉问答(VQA)、幻觉检测(RePOPE)。
|
任务 |
指标 |
传统方法 |
EAGLE |
提升 |
|---|---|---|---|---|
|
图像描述 |
Insertion↑ |
0.56 |
0.67 |
+19.6% |
|
图像描述 |
Deletion↓ |
0.33 |
0.29 |
-12.1% |
|
VQA |
Faithfulness↑ |
0.71 |
0.79 |
+8% |
|
幻觉检测 |
Correction Rate↑ |
0.22 |
0.45 |
+104% |
📉 效率表现
相比基于梯度的可解释方法(如 IGOS++、Grad-CAM), EAGLE 显存占用减少约 70%~80%, 在 Qwen2.5-VL 7B 上运行仅需 17GB 显存,推理速度显著提升。
四、优势与局限
✅ 优势
-
🔍 双层解释:同时说明“模型看哪儿”和“靠啥生成”;
-
⚫ 黑盒适配性强:无需修改模型结构或访问梯度;
-
🧩 细粒度可视化:支持 token 级解释;
-
🚫 幻觉检测能力:能指出哪些词是“瞎编”的。
⚠️ 局限
-
区域贪心搜索带来一定计算开销;
-
解释质量依赖初始区域划分;
-
暂未支持视频或长时多帧输入;
-
只能解释“已生成行为”,无法直接指导训练优化。
📝 一句话总结
EAGLE 给多模态大模型装上了“显微镜”, 让我们第一次能看清:每一个词,是看图得出的,还是靠想象写出来的。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)