CapRL:用强化学习突破Image Captioning训练瓶颈,3B模型性能媲美72B
近日,上海人工智能实验室联合团队发布了 Dense Image Captioning 领域的最新成果——这是首个将 DeepSeek-R1 强化学习策略成功应用于 Image Captioning 这类开放视觉任务的工作,创新地以实用性重新定义了 Image Captioning 的 reward。训练得到的,在图像描述任务上能,是 Image Captioning 领域的重要突破,也为提供了新的
近日,上海人工智能实验室联合团队发布了 Dense Image Captioning 领域的最新成果——CapRL(Captioning Reinforcement Learning)。这是首个将 DeepSeek-R1 强化学习策略成功应用于 Image Captioning 这类开放视觉任务的工作,创新地以实用性重新定义了 Image Captioning 的 reward。
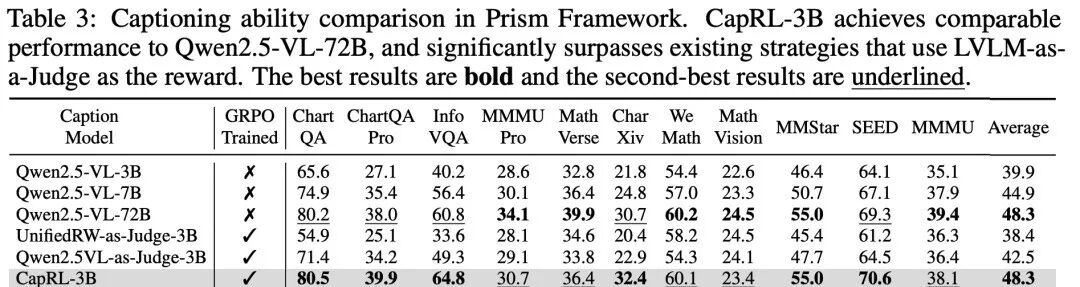
训练得到的 CapRL-3B 模型,在图像描述任务上能媲美 Qwen2.5-VL-72B,是 Image Captioning 领域的重要突破,也为 GRPO 策略在开放任务中的应用提供了新的思路。
目前,CapRL 已开源,模型与数据集总下载量突破 6K,研究团队正在持续迭代更强基座模型与优化训练方案,欢迎使用。

HuggingFace Space试用 :
https://huggingface.co/spaces/yuhangzang/caprl
论文链接:
https://arxiv.org/abs/2509.22647
仓库链接:
https://github.com/InternLM/CapRL
模型链接:
https://huggingface.co/internlm/CapRL-3B
数据链接:
https://huggingface.co/datasets/internlm/CapRL-2M
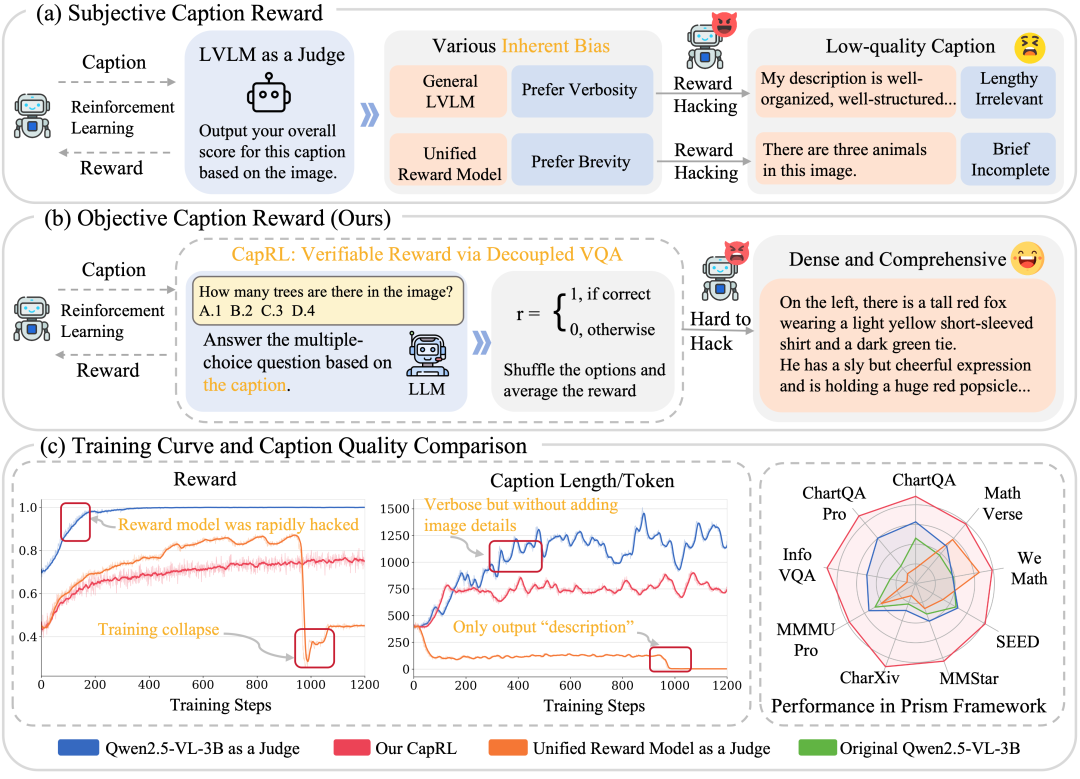
从 SFT captioner 到 RL captioner: Reward 设计重大难点
Image Captioning 旨在为给定图像生成自然语言描述,弥合视觉与语言世界之间的鸿沟,是目前 ViT 训练以及 LVLM 预训练重要的训练语料。目前大多数 Image Captioning 模型都是基于 LVLMs 并采用监督微调(SFT)方法进行训练,但是这种训练方式有两大问题,数据方面依赖大量由人工或闭源模型标注的数据集,成本高昂且难以扩展,效果方面因为死记硬背的训练方式导致泛化与多样性不足。
SFT 的局限性促使研究者转向一种新的范式——基于可验证奖励的强化学习(RLVR)。RLVR 这种训练范式在visual grounding、detection 这种包含标准答案的视觉任务上已经得到广泛应用,然而,将 RLVR 应用于 Image Captioning 等开放性任务仍然非常具有挑战性,其关键在于如何设计一个客观可靠的 reward 函数。“什么是一个好的图片描述?”,这个问题带有很强的主观性,大家往往看法不一,同一张图片可能会存在多种不同的合理描述,这就给 verifiable reward 设计带来很大的困难。
现有的一些方法尝试使用奖励模型(reward models)或 LVLM-as-a-judge 来提供 reward,如图1(a)所示,但是这种方法非常容易受到奖励欺骗(reward hacking)的影响。模型可能学会利用奖励模型的漏洞(偏好冗长或简短的输出形式)来获得更高分数,而非真正生成高质量的描述,这种不可靠的奖励信号很容易导致在 GRPO 训练过程中出现异常,图1(c)中展示了训练过程中出现了caption 过长以及过短的情况,最终导致模型的表现不及预期甚至出现训练崩溃。
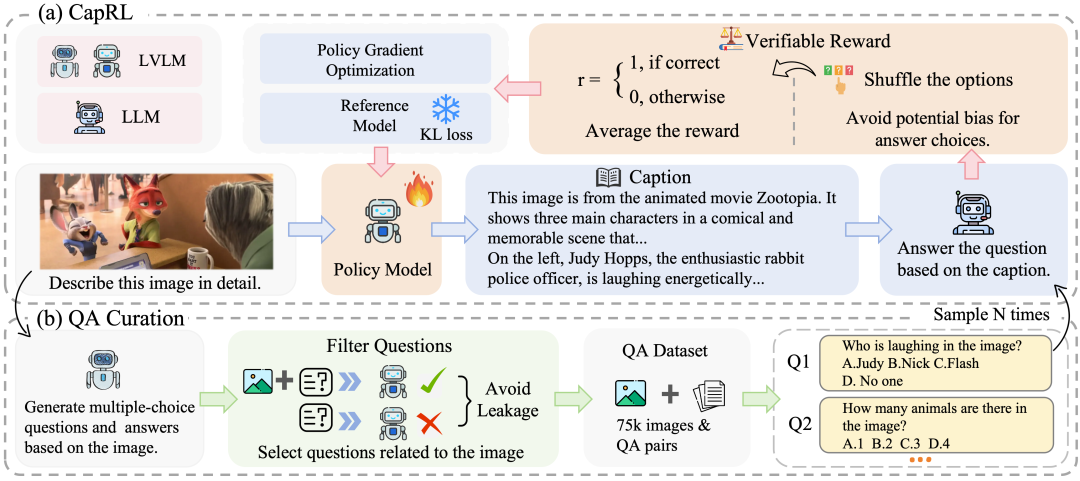
Reward 设计新思路:好的 caption 应当能让纯语言模型正确回答视觉问题
为了解决主观图像描述任务中 RLVR 奖励函数缺乏客观性的难题,研究团队提出了一种全新的视角:caption quality 与其实用性成正比。当图像描述足够详细且准确时,即使一个纯语言模型无法直接“看到”图像,也能回答与图像相关的视觉问答。
例如图2中,对于问题“图片里面谁在大笑?”,当描述中包含“兔子警官Judy正在开怀大笑”,LLM 即可正确回答“Judy”。基于这一动机,研究团队提出了一个高效的两阶段解耦式训练框架,称为 CapRL(Captioning Reinforcement Learning)。在 CapRL 框架中,研究团队让一个纯语言模型根据 caption 去回答与原图像相关的多项选择题,LLM 的回答准确率即作为 RLVR 训练的客观奖励信号。基于 CapRL 训练之后,输出的描述如图3所示,会在准确率、细节覆盖等方面大幅度提升。
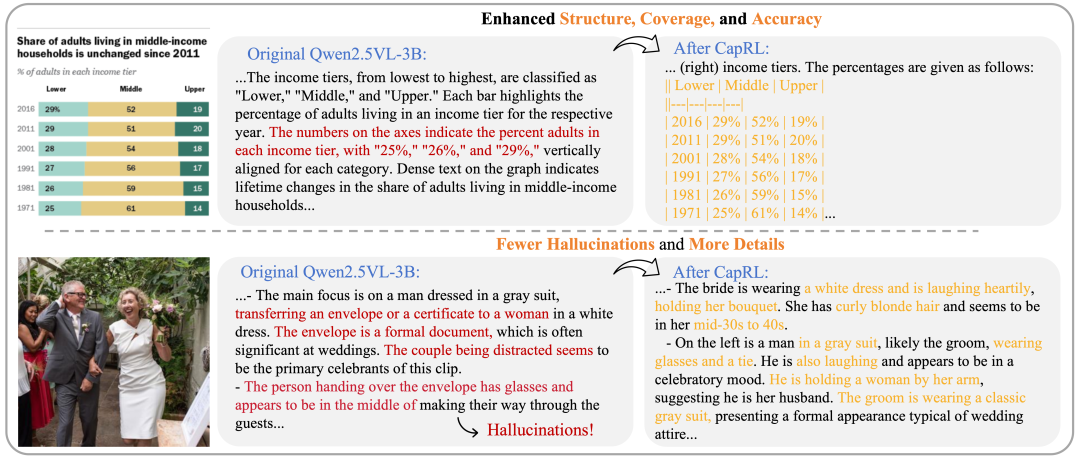
CapRL 实验结果
研究团队对 CapRL 框架带来的优势进行了全面评估。
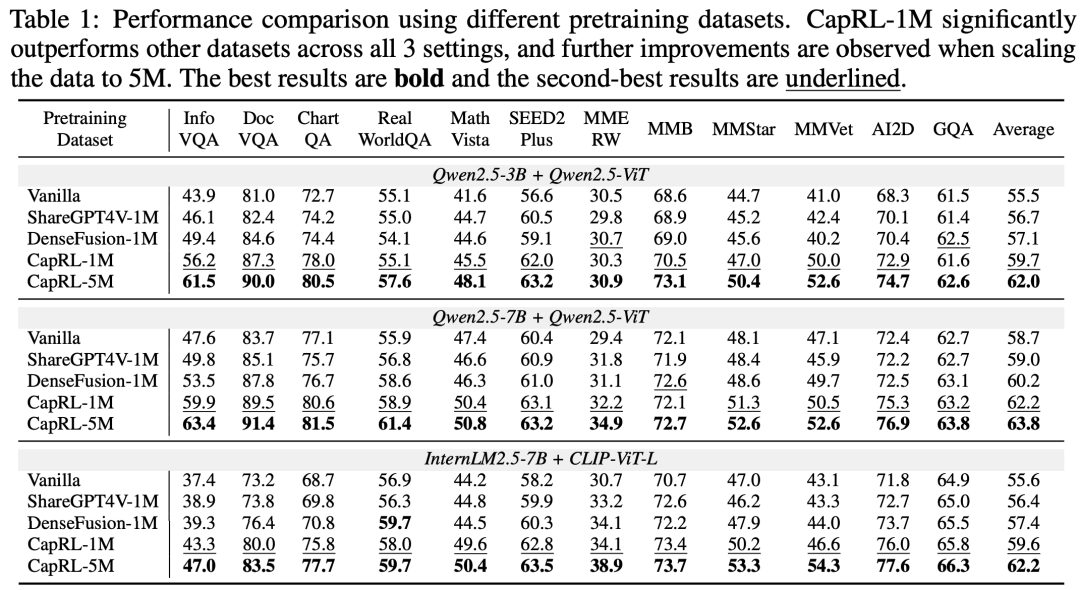
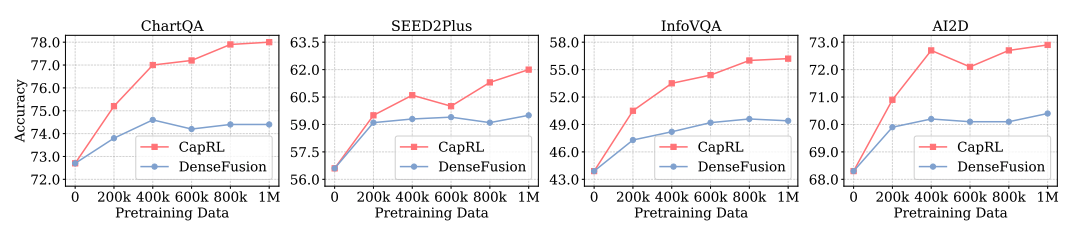
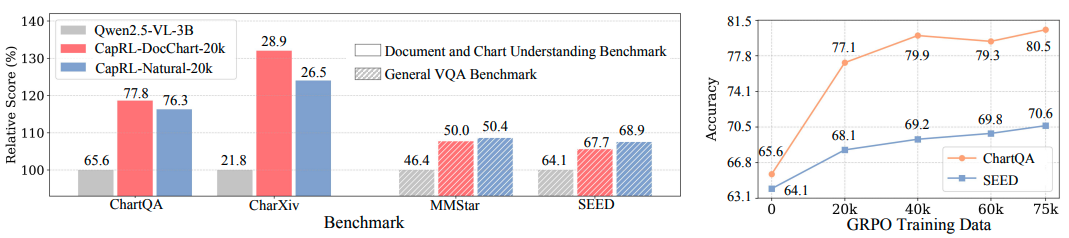
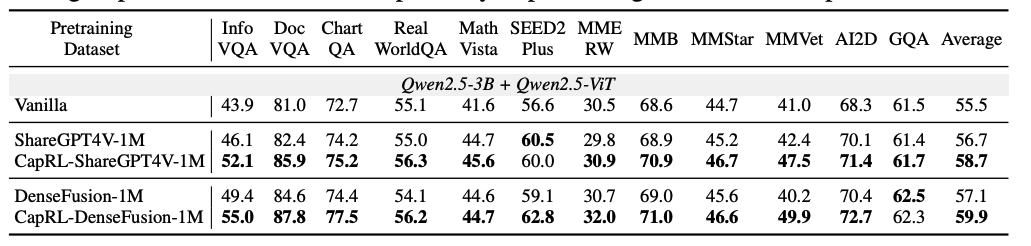
(i)使用 CapRL-3B 标注图片产生了 CapRL-5M 数据集,并在该数据集上对 LVLM 进行预训练,在全部 12 项基准测试中均取得了显著性能提升,与以往的 ShareGPT4V、DenseFusion dataset 的对比中展示出了巨大优势,效果如图4所示。
(ii)此外,借助 Prism Framework 对描述质量进行直接的评估,研究团队观察到 CapRL-3B 的性能与 Qwen2.5-VL-72B 模型相当,并在平均水平上超越基线模型 8.4%,详见图5。

目前研究团队开源了论文中的模型、数据集和 QA 构造的代码,提供了试用 demo,且在持续迭代中,欢迎使用!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)