Dify 入门系列(四):RAG 实战 -> 构建你的第一个“数据治理”知识库
这是我们大数据工程师的“本行”,用 AI 来学习我们自己的专业文档,没有比这更酷的了。这就是“文本分块”的“硬科学”。如果 Retrieval(检索)这一步返回的“原文”都是垃圾,那 Generation(生成)那一端的 LLM 再聪明,也是“垃圾进,垃圾出”。我们利用 Dify 的“知识库”产线,把“数据治理”这个专业领域的“私有知识”,成功“注入”到了 Dify 的向量库中。这是 Dify 的

大家好,我是独孤风,「大数据流动」的主理人。
前三篇,我们一路“披荆斩棘”,完成了 Dify 的“厂房”搭建和“大脑”安装:
-
Dify 是什么? 明白了它的“AI 工厂”定位。
-
本地部署: 在自己电脑上跑通了。
-
模型配置: 成功接入了“AI 大脑”(如DeepSeek、Ollama)。
模型已就位,我们马上开始“喂数据”。
今天,我们将实战 Dify 最核心、最“值钱”的功能——RAG(检索增强生成)。
这是 Dify 的“杀手锏”实战,也是我们大数据工程师最关心的功能,是一个完美的、专业性极强的实战场景。
现在,万事俱备,只欠“原料”。
我们将亲手把“私有数据”喂给 Dify,构建一个“数据治理”专家知识库。这是我们大数据工程师的“本行”,用 AI 来学习我们自己的专业文档,没有比这更酷的了。
一、什么是RAG?
RAG,全称 Retrieval-Augmented Generation(检索增强生成),简单说就是“先查资料,再回答问题”的大模型应用模式。
它不会只靠模型记忆硬编,而是先从你的私有文档或数据库里检索出相关内容,再把这些结果连同问题一起交给大模型生成答案。
这样既能让模型用上最新、最专业的企业内部知识,又能降低幻觉率,让回答更可控、更可追溯,是目前企业级 AI 应用里最主流、也最容易落地的一种架构。
大家先简单理解即可,先动手,后面我们会详细的学习RAG的知识。
二、Dify 的“数据集”到底是什么?
在 Dify 的顶部导航栏,你会看到一个核心模块——“知识库”。
工程师请注意:
这绝不只是一个“上传文件的文件夹”。
Dify 的“知识库”模块,是一整套“开箱即用”的 RAG 流水线。
你点几下鼠标,Dify 就在后台帮你完成了 LangChain/LlamaIndex 需要写几十上百行 Python 代码才能搞定的所有“脏活累活”:
-
数据提取 (Ingestion):自动解析 PDF、TXT、Markdown、DOCX、PPTX 等文件。
-
文本分块 (Chunking):把长文档切成“语义相关”的小块。
-
向量化 (Embedding):调用你配置的 Embedding 模型,把文本块变成“向量”。
-
数据索引 (Indexing):把这些向量存入 Dify 内置的向量数据库(如 Weaviate)。
-
数据检索 (Retrieval):提供检索接口,供 AI 应用调用。
我们今天的任务,就是走通这条流水线。
三、第一步:创建“知识库”
-
点击顶部“知识库”菜单。
-
点击“创建知识库”按钮。
可以先选择创建空白知识库,随后再设置。给它起个名字。我们就叫:“数据治理专家知识库”。
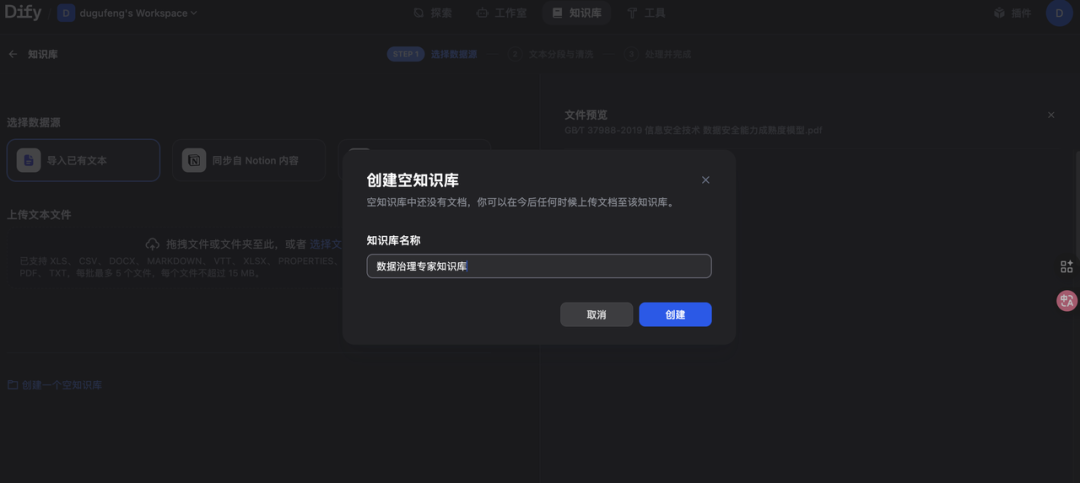
这样我们就有了一个自己的知识库了。
在设置里可以做权限的管理。
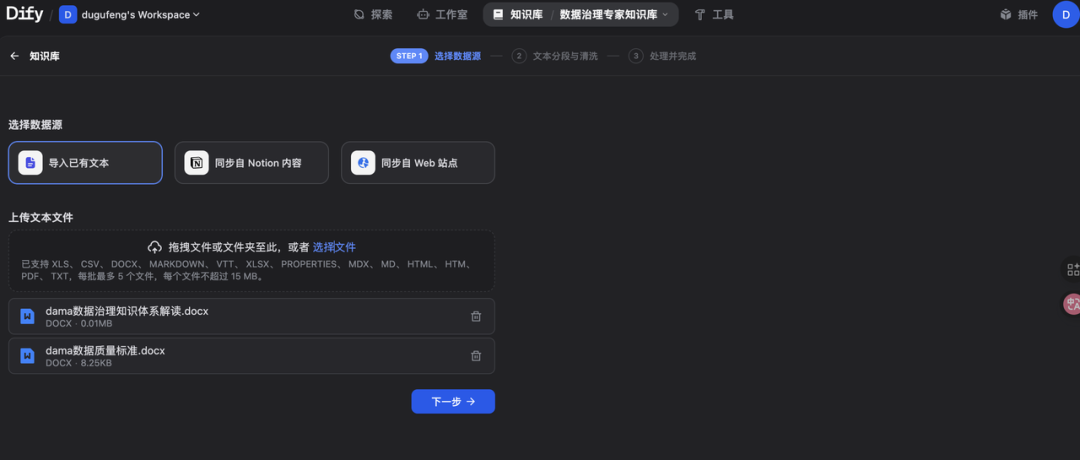
四、第二步:上传文档
你可以通过上传本地文件、同步Notion、导入在线数据的方式上传文档至知识库内。
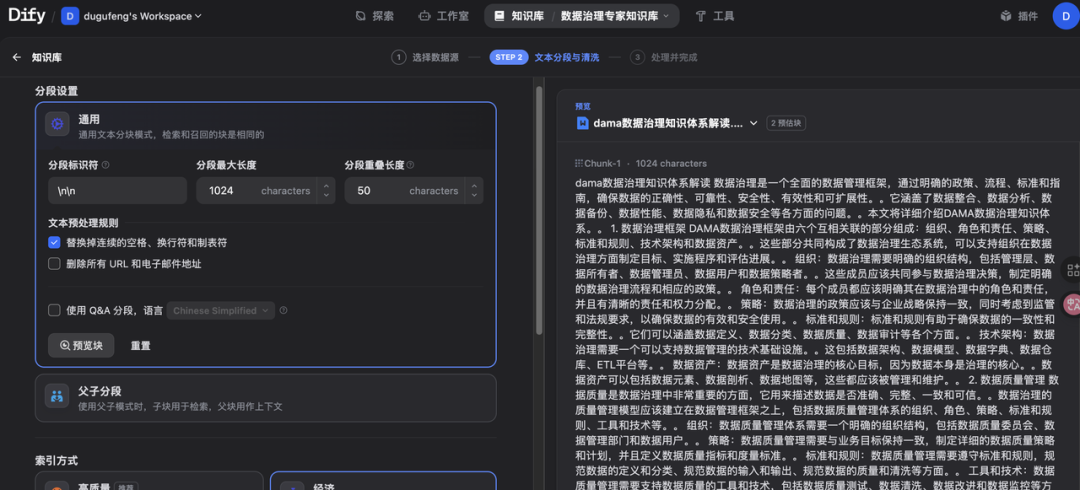
指定分段模式
将内容上传至知识库后,接下来需要对内容进行分段与数据清洗。该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。
知识库支持两种分段模式:通用模式与父子模式。
点击预览块,可以看到分段情况。
随后选择模型,做检索的设置,保存。
之后提示文档上传成功就可以了。
文档上传后,Dify 的 worker 服务(我们 docker-compose 里的 dify-worker 容器)开始在后台“疯狂运转”了。
当所有文档都显示“已完成”,并出现了“分段数”时,恭喜你!
你的“数据治理”知识已经 100% 被 Dify “消化”和“吸收”,并存入了它自己的私有向量数据库。你的“金矿”已经备好了。
五、第三步:RAG调试
上传成功后,可以对文档做进一步管理。
这里有两个决定 RAG 效果的“命门”:
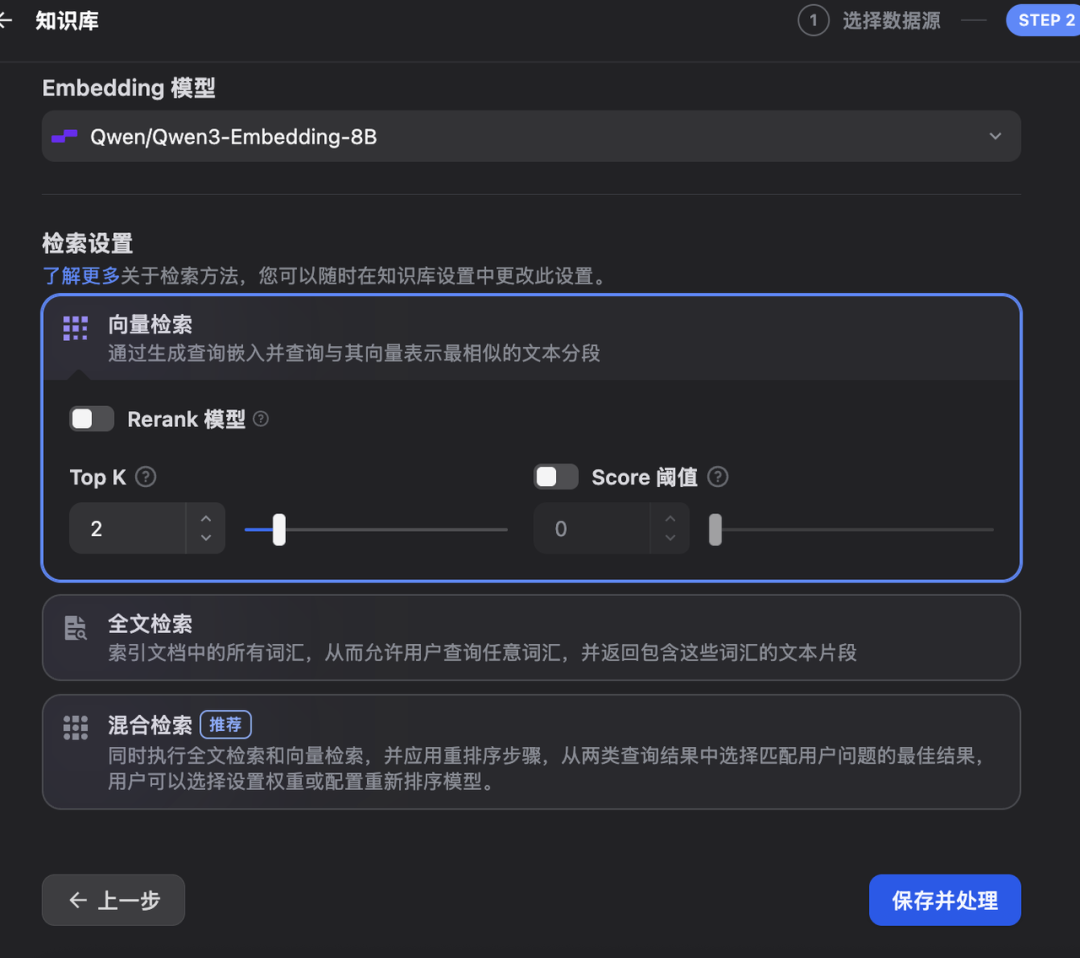
1. Embedding 模型(向量化的“标尺”)
-
这里就是我们上一篇“注入灵魂”的成果体现。
-
你必须在这里指定一个 Embedding 模型。Dify 会用这个模型,把你所有的“中文文档”转换成“数学向量”。
-
建议: 如果你接入了智谱,就选 embedding-2;如果用的是本地 Ollama,就选你下载好的中文 Embedding 模型(如 bge-base-zh-v1.5)。选错了(比如用一个英文模型去处理中文),RAG 效果会一塌糊涂。
2. 分段设置(文本“切块”的刀法)
-
文本分段器: 我们选择“通用分段器”。
-
工程师看这里: “通用分段器”下面有两个核心参数:
-
-
分段大小 (Chunk Size):比如 1000。代表 AI 一次“阅读”的“上下文”最大长度(Token 数)。
-
分段重叠 (Chunk Overlap):比如 200。代表两“块”数据之间重叠的 Token 数,这是为了防止“语义”被硬生生切断(比如一句话的后半句在下一块)。
-
这就是“文本分块”的“硬科学”。对于 PDF、长 TXT 来说,合理的配置(如 1000/200)是保证“召回率”和“精召率”的基础。我们暂时保持默认。
六、工程师的“自检”:召回测试
作为一个严谨的工程师,AI 应用还没建,我怎么知道 RAG 到底好不好使?
Dify 提供了“召回测试”功能。
-
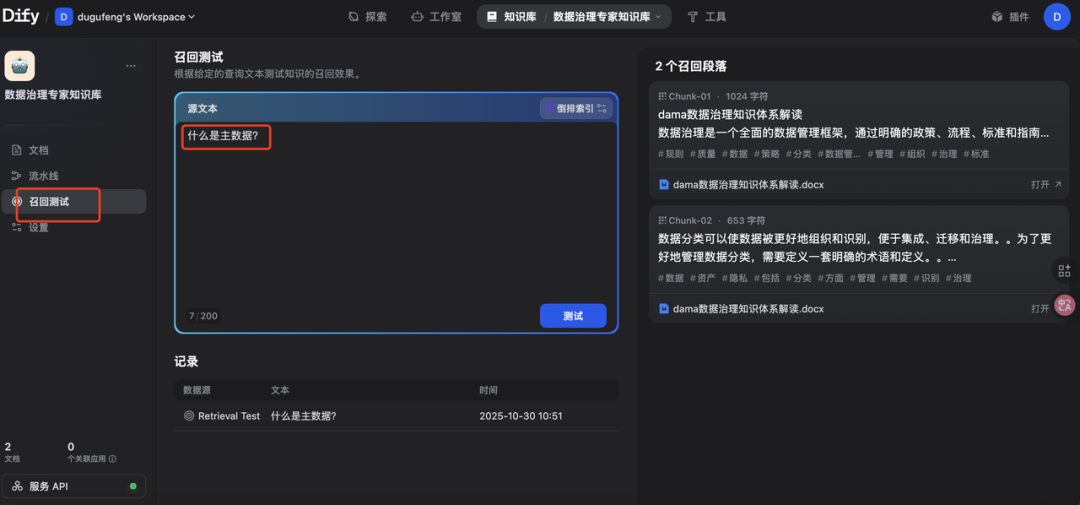
在“知识库”里,切换到“召回测试”选项卡。
-
在搜索框里,输入一个你文档里才有的“黑话”,比如:“什么是主数据?”
-
查看结果: Dify 不会给你“答案”,而是会返回它从向量库里“检索”到的“原始文本块”。
为什么这个功能对我们至_关重要?_
“RAG = Retrieval + Generation”。
如果 Retrieval(检索)这一步返回的“原文”都是垃圾,那 Generation(生成)那一端的 LLM 再聪明,也是“垃圾进,垃圾出”。
“召回测试”让我们有能力独立调试 RAG 的“检索”环节,确保 AI 在“思考”之前,拿到的“参考资料”是对的。
总结与预告
今天,我们干了件大事。
我们利用 Dify 的“知识库”产线,把“数据治理”这个专业领域的“私有知识”,成功“注入”到了 Dify 的向量库中。
-
“工厂”有了(Docker 部署)。
-
“大脑”有了(模型配置)。
-
“原料”也有了(“数据治理”知识库)。
一切准备就绪。
下一篇,就是把“大脑”和“原料”连接起来,亲手创建第一个“AI 聊天机器人”,并让它成为一个“上知公司数据治理规范、下知数据质量考核标准”的 AI 专家。
一起折腾 Dify
如果你已经在用 Dify 做知识库、RAG 或者 Agent 应用,肯定还会遇到一堆非常具体的工程问题。
我这边在搭一个「AI工程化学习群」,主要会做三件事:
-
一起交流 Dify 的升级与运维经验。
-
拆解多模态知识库、RAG 工作流在真实业务里的架构设计。
-
不定期更新我在实际工作中沉淀的工作流模板和踩坑记录,方便大家直接拿去改。
当然Dify只是开始。过去,我做了10年的数据工程化。未来,我准备再做10年的AI工程化!
加入大数据流动,和我们一起~
想进群的同学,可以在公众号「大数据流动」后台回复【dify】两个字,自动获取进群方式。
也欢迎在评论区简单介绍一下你现在用 Dify 做什么场景,我会优先拉一些典型案例进群,一起对着实际业务做优化。
我是独孤风,我们下期见。
👇 戳左下角「阅读原文」,访问我们的开源仓库点个小星星吧 ⭐️

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)