突破传统方法!强化学习结合自动化,效率狂提3倍!
2025年工业机器人已实现10分钟掌握新技能,大模型训练效率提升2倍。最新研究通过真机学习闭环(如智元机器人)、异步训练架构(阿里ROLL)和精准预测框架(Meta)三大突破,解决了传统强化学习依赖人工调参、训练效率低下的痛点。相关论文显示,自动化方法在18个数据集上最高提升22.4%性能,收敛速度加快2.3倍,且LLM智能引导策略可减少80%计算开销。关键技术包括:贝叶斯推断软引导(SoftPi
工业产线上的机器人十分钟就能学会新技能,大模型强化学习训练效率直接翻两倍,这不是科幻场景,而是2025年强化学习自动化技术的真实突破。如今NeurIPS、ICML等顶会论文里,自动化已成为强化学习的核心关键词,彻底告别了过去专家调参熬数周,换个场景全白费的窘境。传统强化学习有多依赖人工?工业机械臂调参曾需工程师蹲守产线改参数,大模型RL训练的GPU常因等待任务空转,这些问题让技术落地成本居高不下。而近期的突破性方案彻底逆转局面,智元机器人靠“真机学习闭环”,让产线机器人无需仿真训练,直接在真实环境中自主优化,新技能部署从数周缩至数十分钟,任务完成率100%;阿里ROLL团队的Async架构,让大模型RL训练效率提升2.72倍,百卡规模下仍能稳定提速;Meta的ScaleRL框架更实现训练效果精准预测,误差不足1%。
论文er盯紧真机学习、异步训练、训练预测建模这些方向准没错,我整理了相关顶会/顶刊核心论文,部分还附带复现代码打包免费送,感兴趣的同学工种号 沃的顶会 扫码回复 “强化自动” 领取。
SOFTPIPE:A SOFT-GUIDED REINFORCEMENT LEARNING FRAMEWORK FOR AUTOMATED DATA PREPARATION
文章解析
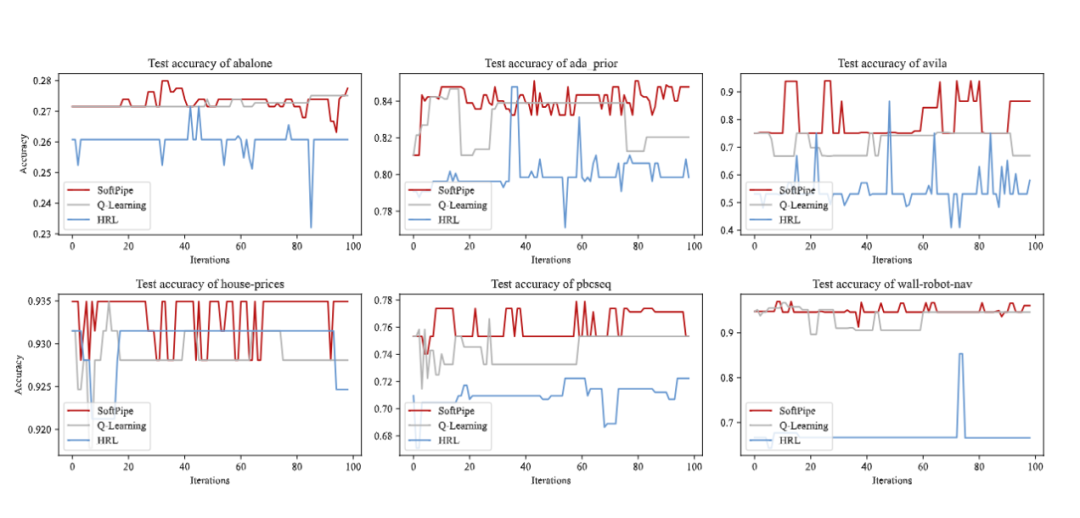
数据准备是机器学习流程中关键但极具挑战性的环节,面临巨大的组合搜索空间。现有基于强化学习(RL)的方法依赖“硬约束”来限制搜索空间,但这种刚性剪枝会排除最优解。本文提出SoftPipe,一种新颖的RL框架,用“软引导”替代硬约束。SoftPipe将动作选择建模为贝叶斯推断问题,利用大语言模型(LLM)生成高层策略先验,结合监督式Learning-to-Rank(LTR)模型的精细质量评分和智能体Q函数的长期价值估计,协同指导搜索。实验表明,SoftPipe在18个数据集上相比现有方法最高提升13.9%的管道质量,并实现2.8倍更快收敛。
创新点
指出当前自动化数据准备(AutoDP)方法的核心缺陷:依赖硬约束导致搜索空间过早剪枝,无法发现最优管道。
提出SoftPipe框架,首次将动作选择形式化为贝叶斯推断问题,实现软引导下的灵活探索。
引入大语言模型(LLM)作为战略先验,为数据准备任务提供高层语义指导。
设计协同融合机制,整合LLM先验、LTR细粒度评分与Q函数长期价值,平衡探索与利用。
实现对传统不可达的复合操作结构(如多个特征预处理算子串联)的有效探索,突破硬约束限制。
研究方法
将数据准备流程建模为马尔可夫决策过程(MDP),使用强化学习进行序列决策。
采用大语言模型(LLM)分析数据集特征并生成操作选择的策略先验概率分布。
训练一个Learning-to-Rank(LTR)模型,对局部操作序列进行精细化质量评估。
通过贝叶斯更新公式融合LLM先验、LTR得分和Q值估计,动态计算每个动作的选择概率。
在多个真实数据集上进行端到端实验,对比主流AutoML工具与RL基线方法性能。
研究结论
硬约束严重限制了现有AutoDP方法的搜索能力,导致次优解和早收敛。
SoftPipe通过软引导机制显著提升了数据准备管道的质量和搜索效率。
LLM提供的战略先验能有效引导搜索方向,而LTR与Q函数确保经验反馈的融入。
SoftPipe在18个数据集上平均优于现有方法,最高提升13.9%准确率。
该框架实现了更灵活、自适应的搜索过程,支持发现非常规但高性能的管道结构。
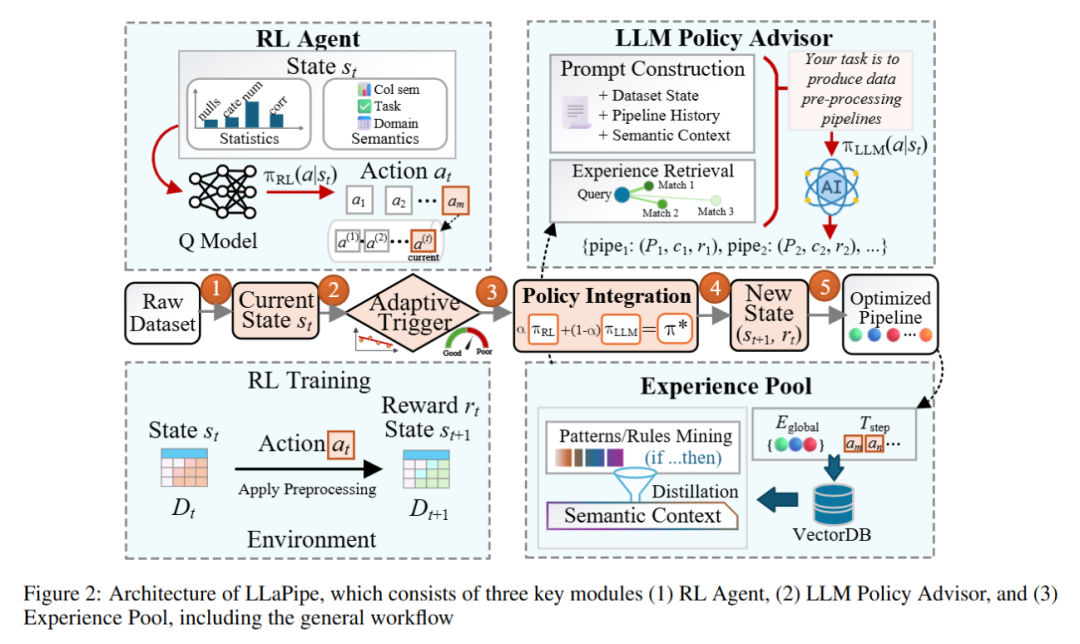
LLAPIPE:LLM-GUIDED REINFORCEMENT LEARNING FOR AUTOMATED DATA PREPARATION PIPELINE CONSTRUCTION
文章解析
本文提出LLaPipe,一种结合大语言模型(LLM)与强化学习(RL)的新型框架,旨在解决现有自动化数据准备方法在巨大预处理管道搜索空间中探索效率低下的问题。LLaPipe利用LLM的语义理解能力,为RL智能体提供上下文相关的探索指导,从而提升搜索质量与收敛速度。通过引入经验蒸馏、自适应触发机制等策略,在仅使用19.0%探索步骤调用LLM的情况下,实现了比当前最先进方法最高22.4%的性能提升和2.3倍更快的收敛。
创新点
提出LLM Policy Advisor,利用大语言模型分析数据集语义和历史管道,生成有前景的预处理操作建议。
设计Experience Distillation机制,从过往成功管道中提取有效模式并迁移知识以指导新任务的探索。
提出Adaptive Advisor Triggering策略(Advisor+),动态决定何时启用LLM干预,平衡探索效果与计算开销。
研究方法
将数据准备建模为马尔可夫决策过程(MDP),采用强化学习进行序列化操作选择。
集成大语言模型作为智能策略顾问,在关键决策点提供语义驱动的操作建议。
通过离线蒸馏历史成功经验构建先验知识库,并结合在线反馈持续优化探索策略。
设计自适应触发机制,仅在传统探索策略不确定性高时激活LLM,控制计算成本。
研究结论
LLaPipe在18个跨领域数据集上显著优于现有RL-based方法,最大提升达22.4%的管道质量。
相比传统方法,LLaPipe实现2.3倍更快的收敛速度,验证了LLM引导的有效性。
通过选择性调用LLM(平均仅19.0%步骤),框架在性能提升的同时保持了良好的计算效率。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)