文生音---阿里百炼文生音的介绍、以及参照官方文档
同步调用:提交文本后,服务端立即处理并返回完整的语音合成结果。整个过程是阻塞式的,客户端需要等待服务端完成处理后才能继续下一步操作。流式调用:将文本逐步发送到服务端并实时接收语音合成结果,允许将长文本分段发送,服务端在接收到部分文本后便立即开始处理。适合实时性要求高的长文本语音合成场景。提交文本后,服务端立即处理并返回完整的语音合成结果。整个过程是阻塞式的,客户端需要等待服务端完成处理后才能继续下

1.语音合成-CosyVoice:
2.语音合成CosyVoice Java SDK
3.SpeechSynthesizer的三种调用方式
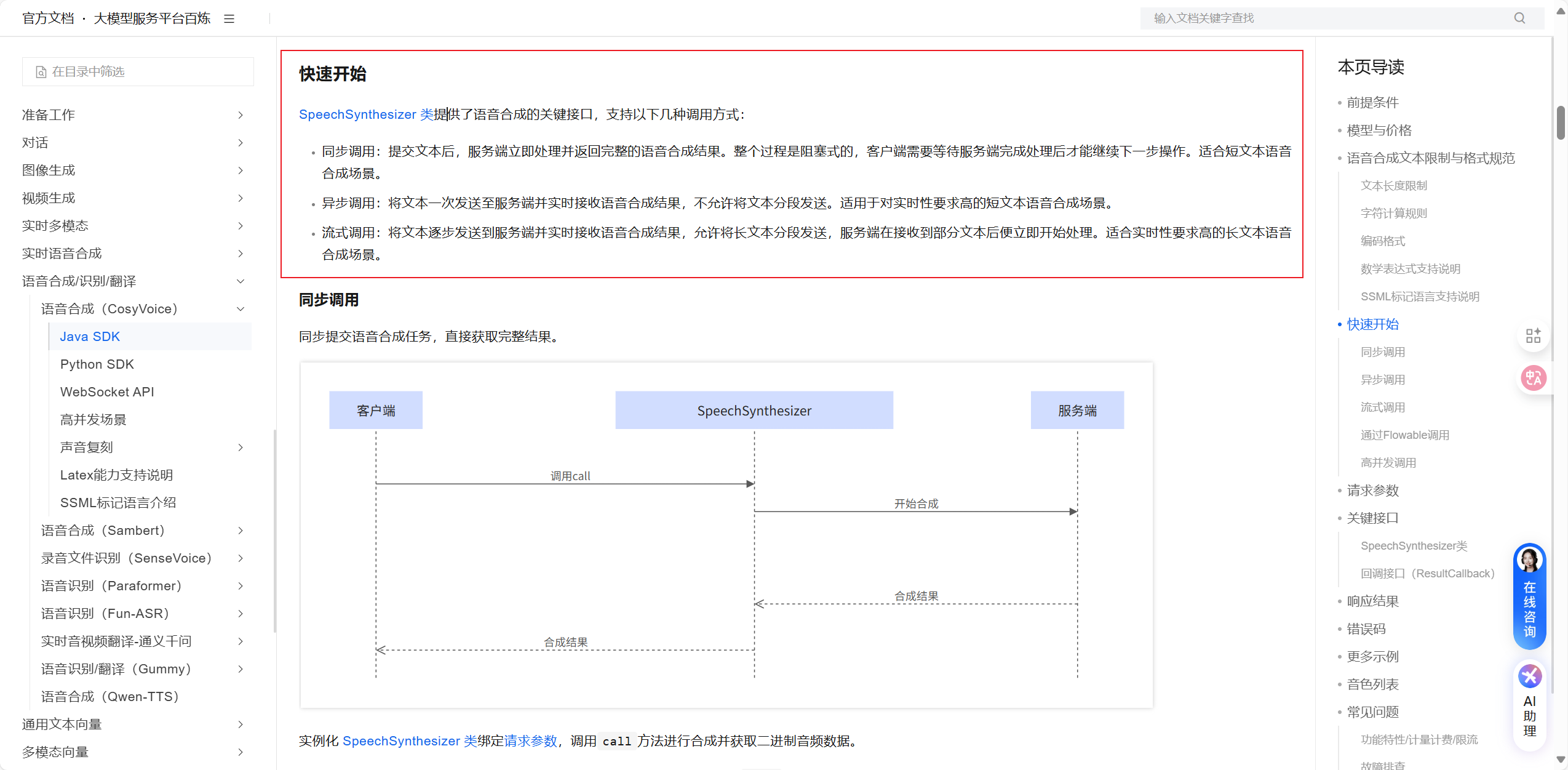
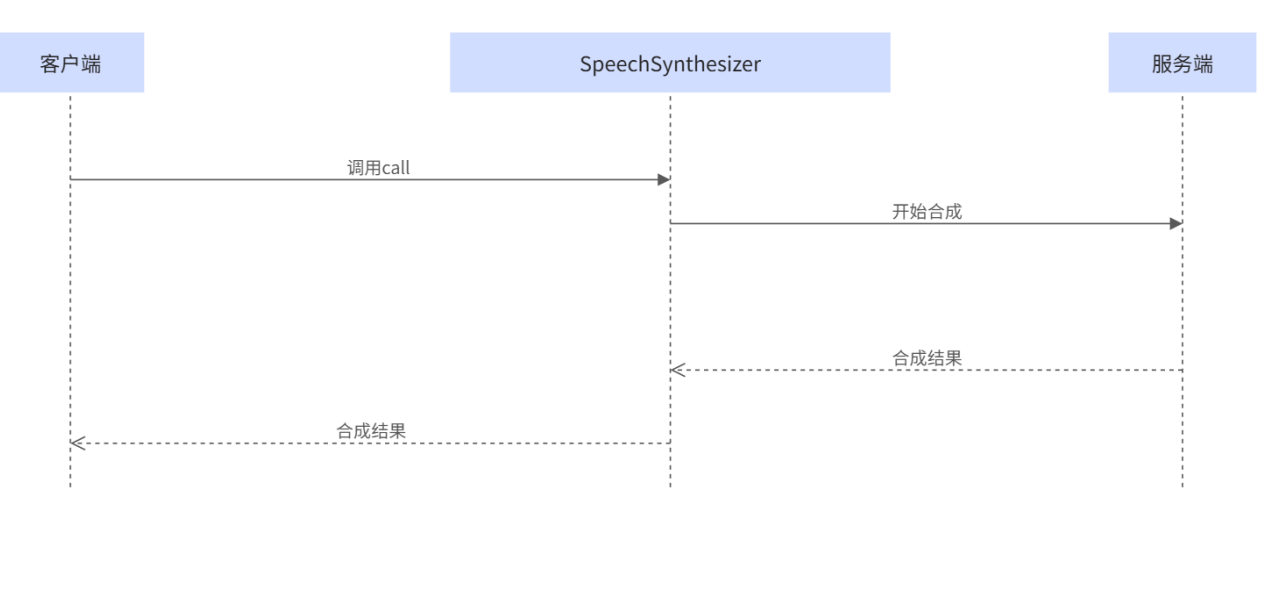
SpeechSynthesizer类提供了语音合成的关键接口,支持以下几种调用方式:
-
同步调用:提交文本后,服务端立即处理并返回完整的语音合成结果。整个过程是阻塞式的,客户端需要等待服务端完成处理后才能继续下一步操作。适合短文本语音合成场景。
-
异步调用:将文本一次发送至服务端并实时接收语音合成结果,不允许将文本分段发送。适用于对实时性要求高的短文本语音合成场景。
-
流式调用:将文本逐步发送到服务端并实时接收语音合成结果,允许将长文本分段发送,服务端在接收到部分文本后便立即开始处理。适合实时性要求高的长文本语音合成场景。
同步提交语音合成任务,直接获取完整结果
例如支付宝的“支付宝到账XXX元”
SpeechSynthesizer作为了中间件
提交文本后,服务端立即处理并返回完整的语音合成结果。整个过程是阻塞式的,客户端需要等待服务端完成处理后才能继续下一步操作。适合短文本语音合成场景
清晰的音频或者长音频适合流式调用,高清图片也适合流式调用
请求参数,也就是调用大模型所需要的参数
SpeechSynthesisParam param = SpeechSynthesisParam.builder()
.model("cosyvoice-v2") // 模型
.voice("longxiaochun_v2") // 音色
.format(SpeechSynthesisAudioFormat.WAV_8000HZ_MONO_16BIT) // 音频编码格式、采样率
.volume(50) // 音量,取值范围:[0, 100]
.speechRate(1.0f) // 语速,取值范围:[0.5, 2]
.pitchRate(1.0f) // 语调,取值范围:[0.5, 2]
.build();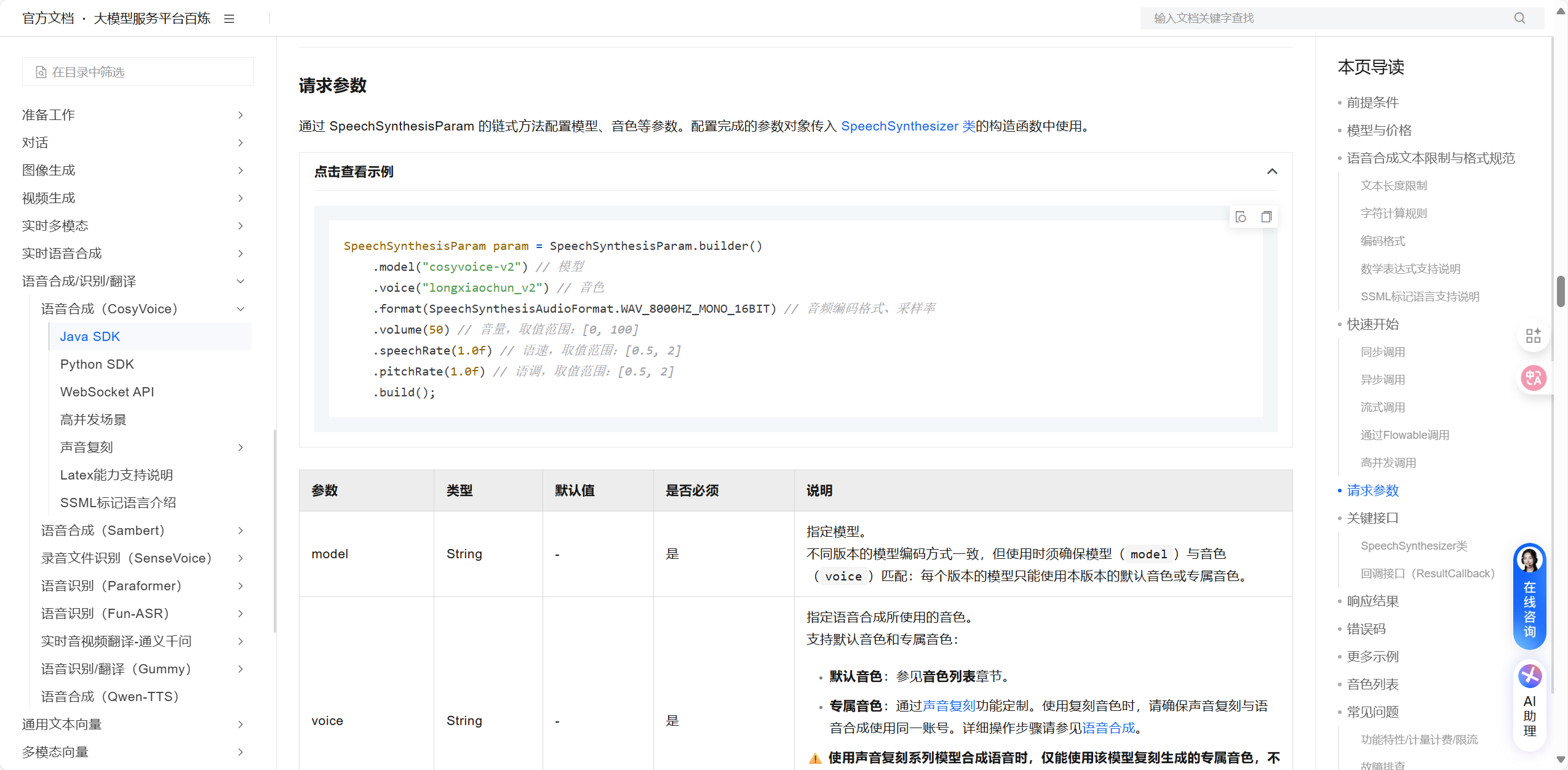
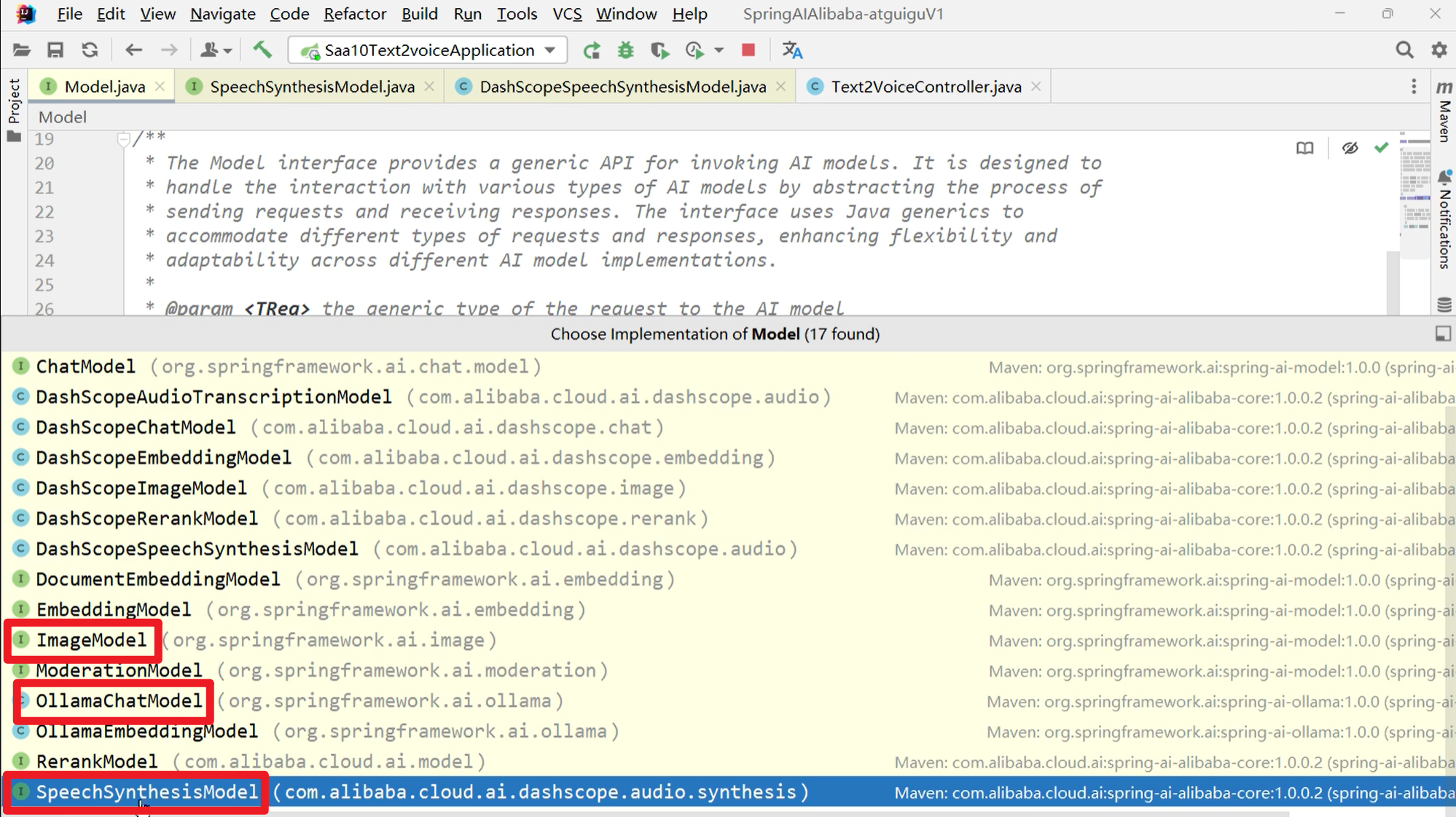
对于SAA框架,最重要的就是各种模型Model
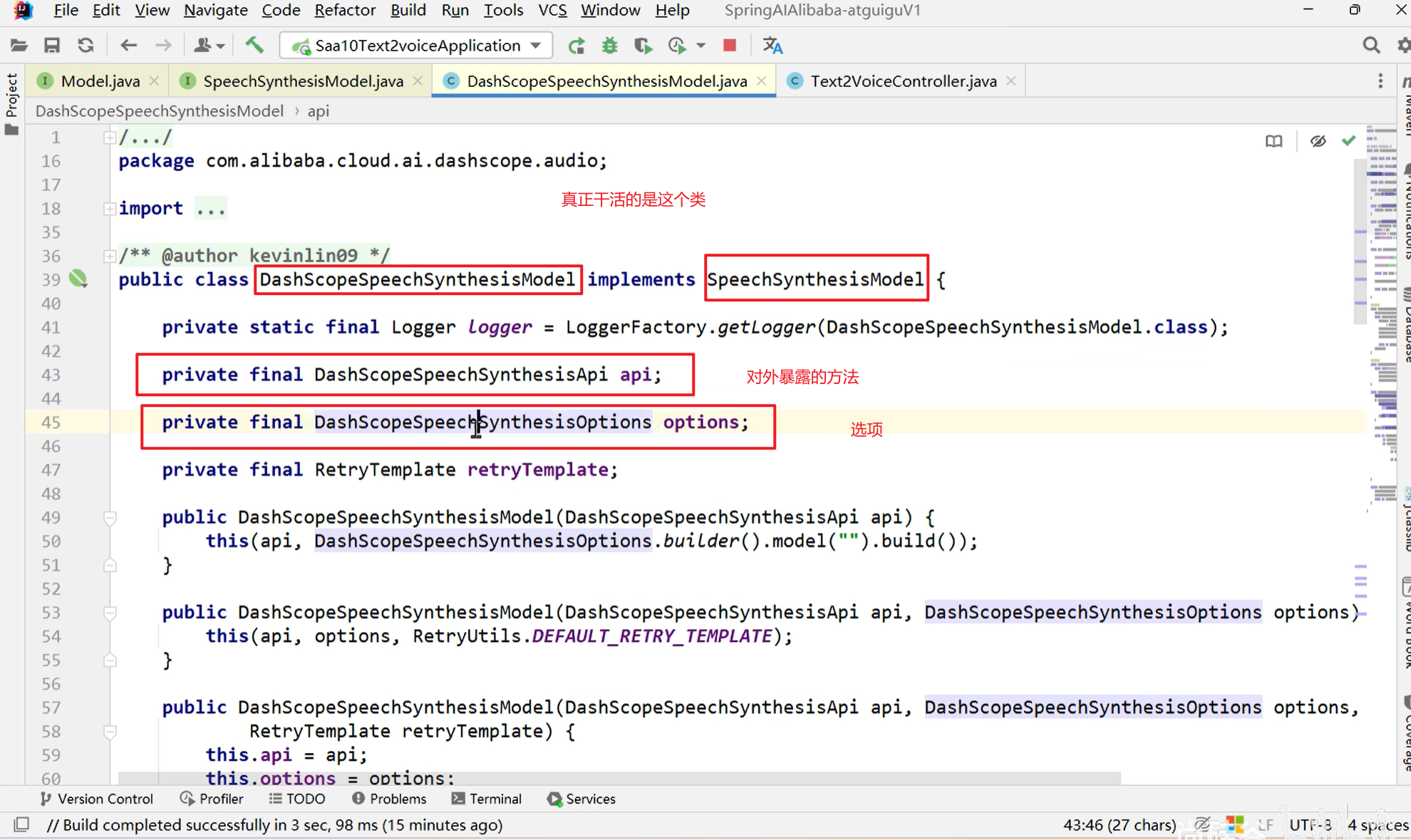
DashScopeSpeechSynthesisOptions里面的可选择有
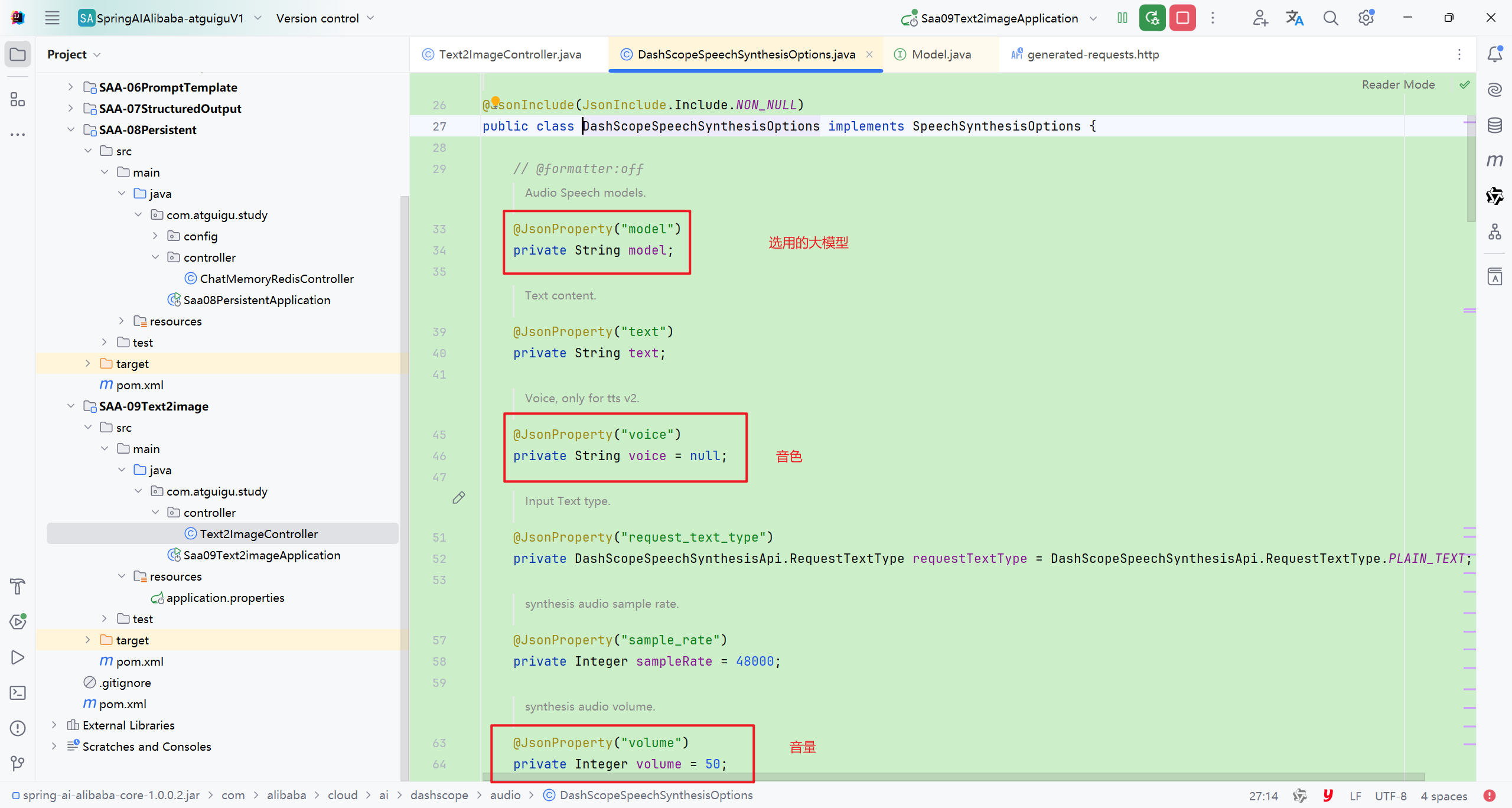
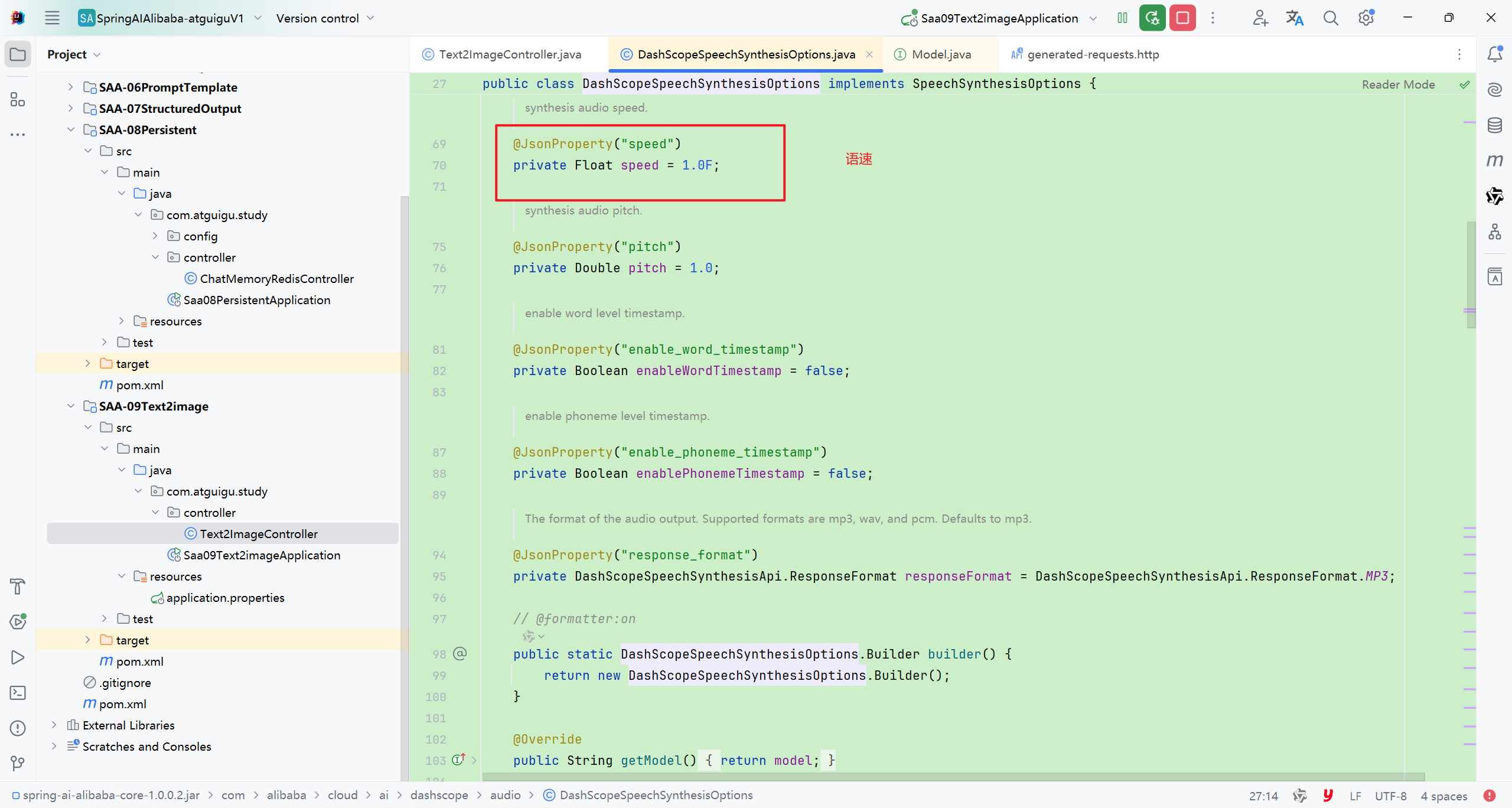
这些内容具体的配置可以参照官方文档

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)